Google如何能搜出一分鐘之前的新聞
頁加載和信息檢索對速度要求極高,Google 為何能快速呈現(xiàn) 1 分鐘內(nèi)的最新內(nèi)容?
答案在于它采用了多層次分桶技術(shù),通過科學(xué)的設(shè)計平衡時效性與處理效率,具體邏輯如下:
核心前提:拒絕全量實時轉(zhuǎn)存
為了保障數(shù)據(jù)的高時效性,Google 并未采用 “實時全量轉(zhuǎn)存” 的方式處理所有數(shù)據(jù)。全量轉(zhuǎn)存不僅資源消耗巨大,還會嚴(yán)重拖慢響應(yīng)速度,因此它僅對部分關(guān)鍵數(shù)據(jù)進(jìn)行針對性處理,核心依靠兩種分桶設(shè)計解決 “快速獲取最新內(nèi)容” 的難題。
兩大核心分桶設(shè)計
1. 按時間分桶:分層存儲,聚焦最新
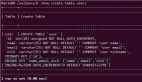
按時間分桶是將分區(qū)數(shù)據(jù)以 “時間索引” 為依據(jù)進(jìn)行拆分存儲,具體分為日索引和小時索引兩個層級。
- 最新 1 小時內(nèi)的數(shù)據(jù),會單獨存入 “小時庫”,這部分?jǐn)?shù)據(jù)專門對應(yīng) “尚未完成日級轉(zhuǎn)存” 的最新內(nèi)容,也是實時檢索的核心目標(biāo)。
 圖片
圖片
- 近期數(shù)據(jù)會按 “天” 進(jìn)行切片整理,形成 “天表” 存入 “天庫”,天庫數(shù)據(jù)量適中,整理和查詢速度更快。
- 全量數(shù)據(jù)則存入 “全量庫”,作為基礎(chǔ)數(shù)據(jù)支撐。
- 關(guān)鍵優(yōu)勢在于,小時庫的數(shù)據(jù)量最小,操作起來更便捷、成功率更高,能直接滿足 “快速提取最新內(nèi)容” 的需求。
 圖片
圖片
2. dump&merge:定時合并,保障時效銜接
dump&merge 是實現(xiàn) “各級數(shù)據(jù)同步更新” 的關(guān)鍵,它由 “dump(數(shù)據(jù)轉(zhuǎn)儲)” 和 “merge(數(shù)據(jù)合并)” 兩個獨立環(huán)節(jié)組成,專門解決 “小時庫、天庫、全量庫如何高效銜接” 的問題。
- dumpl 負(fù)責(zé)按日期對數(shù)據(jù)進(jìn)行定向轉(zhuǎn)存,確保數(shù)據(jù)按時間維度有序歸類。
- merge 負(fù)責(zé)將低層級庫的基礎(chǔ)數(shù)據(jù),合并到對應(yīng)高層級的索引中,形成完整的數(shù)據(jù)鏈。
 圖片
圖片
- 具體執(zhí)行節(jié)奏為:每小時將 “小時庫” 的數(shù)據(jù)合并至 “天庫”,每天再將 “天庫” 的數(shù)據(jù)合并至 “全量庫”。這樣既能保證各級庫的數(shù)據(jù)始終是最新的,又能控制小時庫、天庫的容量,避免因數(shù)據(jù)堆積導(dǎo)致處理變慢。
實時請求的處理流程
1. 實時搜索新聞:精準(zhǔn)定位頂層數(shù)據(jù)
當(dāng)用戶發(fā)起新聞搜索請求時,系統(tǒng)會遵循 “聚焦最新” 的原則,僅對 “小時庫” 這一最頂層的索引進(jìn)行操作。無需遍歷海量全量數(shù)據(jù),直接提取小時庫內(nèi) 1 分鐘內(nèi)的最新內(nèi)容,快速返回結(jié)果。
2. 實時更新網(wǎng)頁:多庫聯(lián)動,合并整合
當(dāng)用戶請求網(wǎng)頁檢索時,系統(tǒng)會采用 “多級別索引聯(lián)動” 的方式。同時查詢 “小時庫” 的最新內(nèi)容、“天庫” 的近期內(nèi)容以及 “全量庫” 的基礎(chǔ)內(nèi)容,通過標(biāo)簽合并技術(shù)整合所有數(shù)據(jù),最終輸出包含最新信息的完整結(jié)果,既保證速度又不遺漏關(guān)鍵內(nèi)容。
核心總結(jié)
面對超大容量數(shù)據(jù)表和海量檢索請求,Google 實現(xiàn)實時搜索的核心特質(zhì)有兩個:
一是通過 “按時間分桶” 實現(xiàn)數(shù)據(jù)的分層存儲,聚焦最新內(nèi)容、減少無效操作;
二是通過 “dump&merge” 完成各級數(shù)據(jù)的定時轉(zhuǎn)存與合并,保障數(shù)據(jù)時效銜接且控制庫容量。
這兩大設(shè)計共同支撐起 Google 快速響應(yīng) 1 分鐘內(nèi)最新內(nèi)容的能力,滿足高效檢索需求。