千萬級大表如何刪除數據?
前言
今天我們來聊聊一個讓很多DBA和開發者頭疼的話題——千萬級大表的數據刪除。
有些小伙伴在工作中,一遇到大表數據刪除就手足無措,要么直接DELETE導致數據庫卡死,要么畏手畏腳不敢操作。
我見過太多因為大表刪除操作不當導致的"血案":數據庫長時間鎖表、業務系統癱瘓、甚至主從同步延遲。
今天跟大家一起專門聊聊千萬級大表數據刪除的話題,希望對你會有所幫助。
一、為什么大表刪除這么難?
在深入技術方案之前,我們先搞清楚為什么千萬級大表的數據刪除會如此困難。
有些小伙伴可能會想:"不就是個DELETE語句嗎,有什么難的?"
其實這里面大有學問。
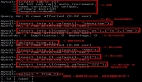
數據庫刪除操作的底層原理
為了更直觀地理解數據庫刪除操作的工作原理,我畫了一個刪除操作的底層流程圖:
 圖片
圖片
從這張圖可以看出,一個簡單的DELETE語句背后隱藏著這么多復雜的操作。
讓我們詳細分析每個環節的挑戰:
1. 事務和鎖的挑戰
-- 一個看似簡單的刪除操作
DELETE FROM user_operation_log
WHERE create_time < '2023-01-01';
-- 實際上MySQL會這樣處理:
-- 1. 獲取表的寫鎖
-- 2. 逐行掃描10,000,000條記錄
-- 3. 對每條匹配的記錄:
-- - 寫入undo log(用于回滾)
-- - 寫入redo log(用于恢復)
-- - 更新所有相關索引
-- - 標記記錄為刪除狀態
-- 4. 事務提交后才真正釋放空間2. 資源消耗問題
- 磁盤I/O:undo log、redo log、數據文件、索引文件的大量寫入
- CPU:索引維護、條件判斷、事務管理
- 內存:Buffer Pool管理、鎖信息維護
- 網絡:主從同步數據量巨大
3. 業務影響風險
- 鎖等待超時:其他查詢被阻塞
- 主從延遲:從庫同步跟不上
- 磁盤空間:undo log暴增導致磁盤寫滿
- 性能下降:數據庫整體性能受影響
有些小伙伴可能會問:"我們用的是云數據庫,這些問題還存在嗎?"
我的經驗是:云數據庫只是降低了運維復雜度,但底層原理和限制依然存在。
二、方案一:分批刪除(最常用)
分批刪除是最基礎也是最常用的方案,核心思想是"化整為零",將大操作拆分成多個小操作。
實現原理
 圖片
圖片
具體實現
方法1:基于主鍵分批
-- 存儲過程實現分批刪除
DELIMITER $$
CREATE PROCEDURE batch_delete_by_id()
BEGIN
DECLARE done INTDEFAULTFALSE;
DECLARE batch_size INTDEFAULT1000;
DECLARE max_id BIGINT;
DECLARE min_id BIGINT;
DECLARE current_id BIGINTDEFAULT0;
-- 獲取需要刪除的數據范圍
SELECTMIN(id), MAX(id) INTO min_id, max_id
FROM user_operation_log
WHERE create_time < '2023-01-01';
WHILE current_id < max_id DO
-- 每次刪除一個批次
DELETEFROM user_operation_log
WHEREidBETWEEN current_id AND current_id + batch_size - 1
AND create_time < '2023-01-01';
-- 提交事務,釋放鎖
COMMIT;
-- 休眠一下,讓數據庫喘口氣
DOSLEEP(0.1);
-- 更新進度
SET current_id = current_id + batch_size;
-- 記錄日志(可選)
INSERTINTO delete_progress_log
VALUES (NOW(), current_id, batch_size);
ENDWHILE;
END$$
DELIMITER ;方法2:基于時間分批
// Java代碼實現基于時間的分批刪除
@Service
@Slf4j
public class BatchDeleteService {
@Autowired
private JdbcTemplate jdbcTemplate;
/**
* 基于時間范圍的分批刪除
*/
public void batchDeleteByTime(String tableName, String timeColumn,
Date startTime, Date endTime,
int batchDays) {
Calendar calendar = Calendar.getInstance();
calendar.setTime(startTime);
int totalDeleted = 0;
long startMs = System.currentTimeMillis();
while (calendar.getTime().before(endTime)) {
Date batchStart = calendar.getTime();
calendar.add(Calendar.DAY_OF_YEAR, batchDays);
Date batchEnd = calendar.getTime();
// 確保不超過結束時間
if (batchEnd.after(endTime)) {
batchEnd = endTime;
}
String sql = String.format(
"DELETE FROM %s WHERE %s BETWEEN ? AND ? LIMIT 1000",
tableName, timeColumn
);
int deleted = jdbcTemplate.update(sql, batchStart, batchEnd);
totalDeleted += deleted;
log.info("批次刪除完成: {}-{}, 刪除{}條, 總計{}條",
batchStart, batchEnd, deleted, totalDeleted);
// 控制刪除頻率,避免對數據庫造成過大壓力
if (deleted > 0) {
try {
Thread.sleep(500); // 休眠500ms
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
} else {
// 沒有數據可刪,跳到下一個時間段
continue;
}
// 每刪除10000條記錄一次進度
if (totalDeleted % 10000 == 0) {
logProgress(totalDeleted, startMs);
}
}
log.info("刪除任務完成! 總計刪除{}條記錄, 耗時{}秒",
totalDeleted, (System.currentTimeMillis() - startMs) / 1000);
}
private void logProgress(int totalDeleted, long startMs) {
long costMs = System.currentTimeMillis() - startMs;
double recordsPerSecond = totalDeleted * 1000.0 / costMs;
log.info("刪除進度: {}條, 速率: {}/秒, 耗時: {}秒",
totalDeleted, String.format("%.2f", recordsPerSecond), costMs / 1000);
}
}方法3:使用LIMIT分批刪除
-- 簡單的LIMIT分批刪除
DELIMITER $$
CREATE PROCEDURE batch_delete_with_limit()
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE batch_size INT DEFAULT 1000;
DECLARE total_deleted INT DEFAULT 0;
WHILE done = 0 DO
-- 每次刪除1000條
DELETE FROM user_operation_log
WHERE create_time < '2023-01-01'
LIMIT batch_size;
-- 檢查是否還有數據
SET done = ROW_COUNT() = 0;
SET total_deleted = total_deleted + ROW_COUNT();
-- 提交釋放鎖
COMMIT;
-- 休眠控制頻率
DOSLEEP(0.1);
-- 每刪除10000條輸出日志
IF total_deleted % 10000 = 0 THEN
SELECT CONCAT('已刪除: ', total_deleted, ' 條記錄') AS progress;
END IF;
END WHILE;
SELECT CONCAT('刪除完成! 總計: ', total_deleted, ' 條記錄') ASresult;
END$$
DELIMITER ;分批刪除的最佳實踐
- 批次大小選擇
- 小表:1000-5000條/批次
- 大表:100-1000條/批次
- 需要根據實際情況調整
- 休眠時間控制
- 業務高峰期:休眠1-2秒
- 業務低峰期:休眠100-500毫秒
- 夜間維護:可不休眠或短暫休眠
- 監控和調整
- 監控數據庫負載
- 觀察主從同步延遲
- 根據實際情況動態調整參數
三、方案二:創建新表+重命名
當需要刪除表中大部分數據時,創建新表然后重命名的方式往往更高效。
實現原理
 圖片
圖片
具體實現
-- 步驟1: 創建新表(結構同原表)
CREATE TABLE user_operation_log_new LIKE user_operation_log;
-- 步驟2: 導入需要保留的數據
INSERT INTO user_operation_log_new
SELECT * FROM user_operation_log
WHERE create_time >= '2023-01-01';
-- 步驟3: 創建索引(在數據導入后創建,效率更高)
ALTER TABLE user_operation_log_new ADDINDEX idx_create_time(create_time);
ALTER TABLE user_operation_log_new ADDINDEX idx_user_id(user_id);
-- 步驟4: 數據驗證
SELECT
(SELECT COUNT(*) FROM user_operation_log_new) as new_count,
(SELECT COUNT(*) FROM user_operation_log WHERE create_time >= '2023-01-01') as expected_count;
-- 步驟5: 原子切換(需要很短的表鎖)
RENAME TABLE
user_operation_log TO user_operation_log_old,
user_operation_log_new TO user_operation_log;
-- 步驟6: 刪除舊表(可選立即刪除或延后刪除)
DROP TABLE user_operation_log_old;Java代碼輔助實現
@Service
@Slf4j
public class TableRebuildService {
@Autowired
private JdbcTemplate jdbcTemplate;
/**
* 重建表方式刪除數據
*/
public void rebuildTableForDeletion(String sourceTable, String condition) {
String newTable = sourceTable + "_new";
String oldTable = sourceTable + "_old";
try {
// 1. 創建新表
log.info("開始創建新表: {}", newTable);
jdbcTemplate.execute("CREATE TABLE " + newTable + " LIKE " + sourceTable);
// 2. 導入需要保留的數據
log.info("開始導入保留數據");
String insertSql = String.format(
"INSERT INTO %s SELECT * FROM %s WHERE %s",
newTable, sourceTable, condition
);
int keptCount = jdbcTemplate.update(insertSql);
log.info("成功導入{}條保留數據", keptCount);
// 3. 創建索引(可選,在導入后創建索引效率更高)
log.info("開始創建索引");
createIndexes(newTable);
// 4. 數據驗證
log.info("開始數據驗證");
if (!validateData(sourceTable, newTable, condition)) {
throw new RuntimeException("數據驗證失敗");
}
// 5. 原子切換
log.info("開始表切換");
switchTables(sourceTable, newTable, oldTable);
// 6. 刪除舊表(可選立即或延后)
log.info("開始刪除舊表");
dropTableSafely(oldTable);
log.info("表重建刪除完成!");
} catch (Exception e) {
log.error("表重建過程發生異常", e);
// 清理臨時表
cleanupTempTable(newTable);
throw e;
}
}
private void createIndexes(String tableName) {
// 根據業務需要創建索引
String[] indexes = {
"CREATE INDEX idx_create_time ON " + tableName + "(create_time)",
"CREATE INDEX idx_user_id ON " + tableName + "(user_id)"
};
for (String sql : indexes) {
jdbcTemplate.execute(sql);
}
}
private boolean validateData(String sourceTable, String newTable, String condition) {
// 驗證新表數據量是否正確
Integer newCount = jdbcTemplate.queryForObject(
"SELECT COUNT(*) FROM " + newTable, Integer.class);
Integer expectedCount = jdbcTemplate.queryForObject(
"SELECT COUNT(*) FROM " + sourceTable + " WHERE " + condition, Integer.class);
return newCount.equals(expectedCount);
}
private void switchTables(String sourceTable, String newTable, String oldTable) {
// 原子性的表重命名操作
String sql = String.format(
"RENAME TABLE %s TO %s, %s TO %s",
sourceTable, oldTable, newTable, sourceTable
);
jdbcTemplate.execute(sql);
}
private void dropTableSafely(String tableName) {
try {
jdbcTemplate.execute("DROP TABLE " + tableName);
} catch (Exception e) {
log.warn("刪除表失敗: {}, 需要手動清理", tableName, e);
}
}
private void cleanupTempTable(String tableName) {
try {
jdbcTemplate.execute("DROP TABLE IF EXISTS " + tableName);
} catch (Exception e) {
log.warn("清理臨時表失敗: {}", tableName, e);
}
}
}適用場景
- 需要刪除表中超過50%的數據
- 業務允許短暫的寫停頓(重命名時需要)
- 有足夠的磁盤空間存儲新舊兩個表
四、方案三:分區表刪除
如果表已經做了分區,或者可以改造為分區表,那么刪除數據就會變得非常簡單。
實現原理
 圖片
圖片
具體實現
方法1:使用現有分區表
-- 查看表的分區情況
SELECT table_name, partition_name, table_rows
FROM information_schema.partitions
WHERE table_name = 'user_operation_log';
-- 直接刪除整個分區(秒級完成)
ALTER TABLE user_operation_log DROPPARTITION p202201, p202202;
-- 定期刪除過期分區的存儲過程
DELIMITER $$
CREATE PROCEDURE auto_drop_expired_partitions()
BEGIN
DECLARE expired_partition VARCHAR(64);
DECLARE done INT DEFAULT FALSE;
-- 查找需要刪除的分區(保留最近12個月)
DECLARE cur CURSOR FOR
SELECT partition_name
FROM information_schema.partitions
WHERE table_name = 'user_operation_log'
AND partition_name LIKE'p%'
AND STR_TO_DATE(REPLACE(partition_name, 'p', ''), '%Y%m') < DATE_SUB(NOW(), INTERVAL12MONTH);
DECLARE CONTINUE HANDLER FOR NOT FOUNDS ET done = TRUE;
OPEN cur;
read_loop: LOOP
FETCH cur INTO expired_partition;
IF done THEN
LEAVE read_loop;
ENDIF;
-- 刪除過期分區
SET @sql = CONCAT('ALTER TABLE user_operation_log DROP PARTITION ', expired_partition);
PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
-- 記錄日志
INSERT INTO partition_clean_log
VALUES (NOW(), expired_partition, 'DROPPED');
END LOOP;
CLOSE cur;
END$$
DELIMITER ;方法2:改造普通表為分區表
-- 將普通表改造成分區表
-- 步驟1: 創建分區表
CREATE TABLE user_operation_log_partitioned (
id BIGINT AUTO_INCREMENT,
user_id BIGINT,
operation VARCHAR(100),
create_time DATETIME,
PRIMARY KEY (id, create_time) -- 分區鍵必須包含在主鍵中
) PARTITION BY RANGE (YEAR(create_time)*100 + MONTH(create_time)) (
PARTITION p202201 VALUES LESS THAN (202202),
PARTITION p202202 VALUES LESS THAN (202203),
PARTITION p202203 VALUES LESS THAN (202204),
PARTITION p202204 VALUES LESS THAN (202205),
PARTITION pfuture VALUES LESS THAN MAXVALUE
);
-- 步驟2: 導入數據
INSERTINTO user_operation_log_partitioned
SELECT * FROM user_operation_log;
-- 步驟3: 切換表
RENAME TABLE
user_operation_log TO user_operation_log_old,
user_operation_log_partitioned TO user_operation_log;
-- 步驟4: 定期維護:添加新分區
ALTER TABLE user_operation_log REORGANIZE PARTITION pfuture INTO (
PARTITION p202205 VALUESLESSTHAN (202206),
PARTITION p202206 VALUESLESSTHAN (202207),
PARTITION pfuture VALUESLESSTHAN MAXVALUE
);Java代碼實現分區管理
@Service
@Slf4j
public class PartitionManagerService {
@Autowired
private JdbcTemplate jdbcTemplate;
/**
* 自動管理分區
*/
@Scheduled(cron = "0 0 2 * * ?") // 每天凌晨2點執行
public void autoManagePartitions() {
log.info("開始分區維護任務");
try {
// 1. 刪除過期分區(保留最近12個月)
dropExpiredPartitions();
// 2. 創建未來分區
createFuturePartitions();
log.info("分區維護任務完成");
} catch (Exception e) {
log.error("分區維護任務失敗", e);
}
}
private void dropExpiredPartitions() {
String sql = "SELECT partition_name " +
"FROM information_schema.partitions " +
"WHERE table_name = 'user_operation_log' " +
"AND partition_name LIKE 'p%' " +
"AND STR_TO_DATE(REPLACE(partition_name, 'p', ''), '%Y%m') < DATE_SUB(NOW(), INTERVAL 12 MONTH)";
List<String> expiredPartitions = jdbcTemplate.queryForList(sql, String.class);
for (String partition : expiredPartitions) {
try {
jdbcTemplate.execute("ALTER TABLE user_operation_log DROP PARTITION " + partition);
log.info("成功刪除分區: {}", partition);
// 記錄操作日志
logPartitionOperation("DROP", partition, "SUCCESS");
} catch (Exception e) {
log.error("刪除分區失敗: {}", partition, e);
logPartitionOperation("DROP", partition, "FAILED: " + e.getMessage());
}
}
}
private void createFuturePartitions() {
// 創建未來3個月的分區
for (int i = 1; i <= 3; i++) {
LocalDate futureDate = LocalDate.now().plusMonths(i);
String partitionName = "p" + futureDate.format(DateTimeFormatter.ofPattern("yyyyMM"));
int partitionValue = futureDate.getYear() * 100 + futureDate.getMonthValue();
int nextPartitionValue = partitionValue + 1;
try {
String sql = String.format(
"ALTER TABLE user_operation_log REORGANIZE PARTITION pfuture INTO (" +
"PARTITION %s VALUES LESS THAN (%d), " +
"PARTITION pfuture VALUES LESS THAN MAXVALUE)",
partitionName, nextPartitionValue
);
jdbcTemplate.execute(sql);
log.info("成功創建分區: {}", partitionName);
logPartitionOperation("CREATE", partitionName, "SUCCESS");
} catch (Exception e) {
log.warn("創建分區失敗(可能已存在): {}", partitionName, e);
}
}
}
private void logPartitionOperation(String operation, String partition, String status) {
jdbcTemplate.update(
"INSERT INTO partition_operation_log(operation, partition_name, status, create_time) VALUES (?, ?, ?, NOW())",
operation, partition, status
);
}
}分區表的優勢
- 刪除效率極高:直接刪除分區文件
- 不影響業務:無鎖表風險
- 管理方便:可以自動化管理
- 查詢優化:分區裁剪提升查詢性能
五、方案四:使用臨時表同步
對于需要在線刪除且不能停止服務的場景,可以使用臨時表同步的方式。
實現原理
 圖片
圖片
具體實現
@Service
@Slf4j
public class OnlineTableMigrationService {
@Autowired
private JdbcTemplate jdbcTemplate;
/**
* 在線表遷移刪除
*/
public void onlineMigrationDelete(String sourceTable, String condition) {
String newTable = sourceTable + "_new";
String tempTable = sourceTable + "_temp";
try {
// 階段1: 準備階段
log.info("=== 階段1: 準備階段 ===");
prepareMigration(sourceTable, newTable, tempTable);
// 階段2: 雙寫階段
log.info("=== 階段2: 雙寫階段 ===");
enableDoubleWrite(sourceTable, newTable);
// 階段3: 數據同步階段
log.info("=== 階段3: 數據同步階段 ===");
syncExistingData(sourceTable, newTable, condition);
// 階段4: 驗證階段
log.info("=== 階段4: 驗證階段 ===");
if (!validateDataSync(sourceTable, newTable)) {
thrownew RuntimeException("數據同步驗證失敗");
}
// 階段5: 切換階段
log.info("=== 階段5: 切換階段 ===");
switchToNewTable(sourceTable, newTable, tempTable);
// 階段6: 清理階段
log.info("=== 階段6: 清理階段 ===");
cleanupAfterSwitch(sourceTable, tempTable);
log.info("在線遷移刪除完成!");
} catch (Exception e) {
log.error("在線遷移過程發生異常", e);
// 回滾雙寫
disableDoubleWrite();
throw e;
}
}
private void prepareMigration(String sourceTable, String newTable, String tempTable) {
// 備份原表
jdbcTemplate.execute("CREATE TABLE " + tempTable + " LIKE " + sourceTable);
jdbcTemplate.execute("INSERT INTO " + tempTable + " SELECT * FROM " + sourceTable);
// 創建新表
jdbcTemplate.execute("CREATE TABLE " + newTable + " LIKE " + sourceTable);
}
private void enableDoubleWrite(String sourceTable, String newTable) {
// 這里需要修改應用層代碼,實現雙寫
// 或者在數據庫層使用觸發器(不推薦,影響性能)
log.info("請配置應用層雙寫: 同時寫入 {} 和 {}", sourceTable, newTable);
// 等待雙寫配置生效
sleep(5000);
}
private void syncExistingData(String sourceTable, String newTable, String condition) {
log.info("開始同步存量數據");
// 同步符合條件的數據到新表
String syncSql = String.format(
"INSERT IGNORE INTO %s SELECT * FROM %s WHERE %s",
newTable, sourceTable, condition
);
int syncedCount = jdbcTemplate.update(syncSql);
log.info("存量數據同步完成: {} 條記錄", syncedCount);
// 等待雙寫追平增量數據
log.info("等待增量數據追平...");
sleep(30000); // 等待30秒,根據業務調整
// 檢查數據一致性
checkDataConsistency(sourceTable, newTable);
}
private void checkDataConsistency(String sourceTable, String newTable) {
// 檢查關鍵業務數據的一致性
Integer sourceCount = jdbcTemplate.queryForObject(
"SELECT COUNT(*) FROM " + sourceTable, Integer.class);
Integer newCount = jdbcTemplate.queryForObject(
"SELECT COUNT(*) FROM " + newTable, Integer.class);
log.info("數據一致性檢查: 原表{}條, 新表{}條", sourceCount, newCount);
// 這里可以添加更詳細的一致性檢查
}
private boolean validateDataSync(String sourceTable, String newTable) {
// 驗證數據同步的正確性
// 這里可以實現更復雜的驗證邏輯
log.info("數據同步驗證通過");
returntrue;
}
private void switchToNewTable(String sourceTable, String newTable, String tempTable) {
// 短暫停寫(根據業務情況,可能不需要)
log.info("開始停寫切換...");
sleep(5000); // 停寫5秒
// 原子切換
jdbcTemplate.execute("RENAME TABLE " +
sourceTable + " TO " + sourceTable + "_backup, " +
newTable + " TO " + sourceTable);
log.info("表切換完成");
}
private void cleanupAfterSwitch(String sourceTable, String tempTable) {
// 關閉雙寫
disableDoubleWrite();
// 延遲刪除備份表(保留一段時間)
log.info("備份表保留: {}_backup", sourceTable);
log.info("臨時表已刪除: {}", tempTable);
jdbcTemplate.execute("DROP TABLE " + tempTable);
}
private void disableDoubleWrite() {
log.info("請關閉應用層雙寫配置");
}
private void sleep(long millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}六、方案五:使用專業工具
對于特別大的表或者復雜的刪除需求,可以使用專業的數據庫工具。
1. pt-archiver(Percona Toolkit)
# 安裝Percona Toolkit
# Ubuntu/Debian:
sudo apt-get install percona-toolkit
# 使用pt-archiver歸檔刪除數據
pt-archiver \
--source h=localhost,D=test,t=user_operation_log \
--where"create_time < '2023-01-01'" \
--limit 1000 \
--commit-each \
--sleep 0.1 \
--statistics \
--progress 10000 \
--why-not \
--dry-run # 先試運行,確認無誤后移除此參數
# 實際執行刪除
pt-archiver \
--source h=localhost,D=test,t=user_operation_log \
--where"create_time < '2023-01-01'" \
--limit 1000 \
--commit-each \
--sleep 0.1 \
--purge2. 自定義工具類
@Component
@Slf4j
public class SmartDeleteTool {
@Autowired
private JdbcTemplate jdbcTemplate;
/**
* 智能刪除決策
*/
public void smartDelete(String tableName, String condition) {
try {
// 1. 分析表狀態
TableAnalysisResult analysis = analyzeTable(tableName, condition);
// 2. 根據分析結果選擇最佳方案
DeleteStrategy strategy = chooseBestStrategy(analysis);
// 3. 執行刪除
executeDelete(strategy, tableName, condition);
} catch (Exception e) {
log.error("智能刪除失敗", e);
throw e;
}
}
private TableAnalysisResult analyzeTable(String tableName, String condition) {
TableAnalysisResult result = new TableAnalysisResult();
// 分析表大小
result.setTotalRows(getTableRowCount(tableName));
result.setDeleteRows(getDeleteRowCount(tableName, condition));
result.setDeleteRatio(result.getDeleteRows() * 1.0 / result.getTotalRows());
// 分析表結構
result.setHasPartition(isTablePartitioned(tableName));
result.setHasPrimaryKey(hasPrimaryKey(tableName));
result.setIndexCount(getIndexCount(tableName));
// 分析系統負載
result.setSystemLoad(getSystemLoad());
return result;
}
private DeleteStrategy chooseBestStrategy(TableAnalysisResult analysis) {
if (analysis.isHasPartition() && analysis.getDeleteRatio() > 0.3) {
return DeleteStrategy.PARTITION_DROP;
}
if (analysis.getDeleteRatio() > 0.5) {
return DeleteStrategy.TABLE_REBUILD;
}
if (analysis.getTotalRows() > 10_000_000) {
return DeleteStrategy.BATCH_DELETE_WITH_PAUSE;
}
return DeleteStrategy.BATCH_DELETE;
}
private void executeDelete(DeleteStrategy strategy, String tableName, String condition) {
switch (strategy) {
case PARTITION_DROP:
executePartitionDrop(tableName, condition);
break;
case TABLE_REBUILD:
executeTableRebuild(tableName, condition);
break;
case BATCH_DELETE_WITH_PAUSE:
executeBatchDeleteWithPause(tableName, condition);
break;
default:
executeBatchDelete(tableName, condition);
}
}
// 各種策略的具體實現...
private long getTableRowCount(String tableName) {
String sql = "SELECT COUNT(*) FROM " + tableName;
return jdbcTemplate.queryForObject(sql, Long.class);
}
private long getDeleteRowCount(String tableName, String condition) {
String sql = "SELECT COUNT(*) FROM " + tableName + " WHERE " + condition;
return jdbcTemplate.queryForObject(sql, Long.class);
}
private boolean isTablePartitioned(String tableName) {
String sql = "SELECT COUNT(*) FROM information_schema.partitions " +
"WHERE table_name = ? AND partition_name IS NOT NULL";
Integer count = jdbcTemplate.queryForObject(sql, Integer.class, tableName);
return count != null && count > 0;
}
// 其他分析方法...
}
enum DeleteStrategy {
BATCH_DELETE, // 普通分批刪除
BATCH_DELETE_WITH_PAUSE, // 帶休眠的分批刪除
TABLE_REBUILD, // 重建表
PARTITION_DROP, // 刪除分區
ONLINE_MIGRATION // 在線遷移
}
@Data
class TableAnalysisResult {
private long totalRows;
private long deleteRows;
private double deleteRatio;
private boolean hasPartition;
private boolean hasPrimaryKey;
private int indexCount;
private double systemLoad;
}七、方案對比與選擇指南
為了幫助大家選擇合適的方案,我整理了詳細的對比表:
方案對比矩陣
方案 | 適用場景 | 優點 | 缺點 | 風險等級 |
分批刪除 | 小批量刪除, | 實現簡單, | 執行時間長, | 中 |
重建表 | 刪除比例>50%, | 執行速度快, | 需要停寫, | 高 |
分區刪除 | 表已分區或可分區 | 秒級完成, | 需要前期規劃, | 低 |
在線同步 | 要求零停機, | 業務無感知, | 實現復雜, | 中 |
專業工具 | 復雜場景, | 功能強大, | 學習成本, | 中 |
選擇決策流程圖
 圖片
圖片
實戰建議
- 測試環境驗證:任何刪除方案都要先在測試環境驗證
- 備份優先:刪除前一定要備份數據
- 業務低峰期:選擇業務低峰期執行刪除操作
- 監控告警:實時監控數據庫狀態,設置告警閾值
- 回滾預案:準備完善的回滾方案
總結
經過上面的詳細分析,我們來總結一下千萬級大表數據刪除的核心要點。
核心原則
- 安全第一:任何刪除操作都要確保數據安全
- 影響最小:盡量減少對業務的影響
- 效率優先:選擇最適合的高效方案
- 可監控:整個過程要可監控、可控制
技術選型口訣
根據多年的實戰經驗,我總結了一個簡單的選型口訣:
看分區,判比例,定方案
- 有分區:直接刪除分區最快
- 刪的少:分批刪除最穩妥
- 刪的多:重建表最高效
- 不能停:在線同步最安全
最后的建議
大表數據刪除是一個需要謹慎對待的操作,我建議大家:
- 預防優于治療:通過數據生命周期管理,定期清理數據
- 架構要合理:在設計階段就考慮數據清理策略
- 工具要熟練:掌握各種刪除工具的使用方法
- 經驗要積累:每次操作后都要總結經驗教訓
記住:沒有最好的方案,只有最適合的方案。