又一個防緩存擊穿、穿透和雪崩的新項目開擼!支持高并發,性能也是嘎嘎強!
一、項目背景
記得在《【高并發】Redis如何助力高并發秒殺系統?看完這篇我徹底懂了!!》一文中,我們以高并發秒殺系統中扣減庫存的場景為例,說明了Redis是如何助力秒殺系統的。
那么,說到Redis,往往更多的場景是被用作系統的緩存,說到緩存,尤其是分布式緩存系統,在實際高并發場景下,稍有不慎,就會造成緩存穿透、緩存擊穿和緩存雪崩的問題。
為此,有不少小伙伴問我:什么是緩存穿透?什么是緩存擊穿,什么是緩存雪崩呢?它們是如何造成的?又該如何解決呢?能不能帶著我們寫一個徹底解決緩存擊穿、穿透和雪崩問題的項目呢?以便后續使用到自己的實際業務項目中。
所以,冰河開始籌劃帶著大家從零開始手搓一個徹底解決緩存擊穿、穿透和雪崩問題的高性能Redis組件,這個項目不僅僅是從理論上來闡述這些內容。
更是要帶著大家一起手搓生產級高并發場景下緩存擊穿、穿透和雪崩問題解決方案的落地代碼,讓大家掌握的不僅僅是理論知識,更是落地到代碼的解決方案。
二、適用場景
高性能Redis組件旨在徹底解決緩存擊穿、穿透和雪崩問題,支持各種高并發、高性能場景,支持各種靈活多變的復雜Redis讀寫場景。
既然高性能Redis組件要徹底解決緩存擊穿、穿透和雪崩問題,那到底什么是緩存擊穿、穿透和雪崩問題,理論上又有哪些解決方案呢?
2.1 緩存擊穿
如果我們為緩存中的大部分數據設置了相同的過期時間,則到了某一時刻,緩存中的數據就會批量過期。
2.1.1 什么是緩存擊穿?
如果緩存中的數據在某個時刻批量過期,導致大部分用戶的請求都會直接落在數據庫上,這種現象就叫作緩存擊穿。
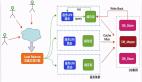
可以使用下圖來表示緩存擊穿的線程。
 圖片
圖片
造成緩存擊穿的主要原因就是:我們為緩存中的數據設置了過期時間。如果在某個時刻從數據庫獲取了大量的數據,并設置了相同的過期時間,這些緩存的數據就會在同一時刻失效,造成緩存擊穿問題。
2.1.2 如何解決緩存擊穿問題?
對于比較熱點的數據,我們可以在緩存中設置這些數據永不過期;也可以在訪問數據的時候,在緩存中更新這些數據的過期時間;如果是批量入庫的緩存項,我們可以為這些緩存項分配比較合理的過期時間,避免同一時刻失效。
還有一種解決方案就是:使用分布式鎖,保證對于每個Key同時只有一個線程去查詢后端的服務,某個線程在查詢后端服務的同時,其他線程沒有獲得分布式鎖的權限,需要進行等待。不過在高并發場景下,這種解決方案對于分布式鎖的訪問壓力比較大。
2.2 緩存穿透
緩存穿透問題在一定程度上與緩存命中率有關。如果我們的緩存設計的不合理,緩存的命中率非常低,那么,數據訪問的絕大部分壓力都會集中在后端數據庫層面。
2.2.1 什么是緩存穿透?
如果在請求數據時,在緩存層和數據庫層都沒有找到符合條件的數據,也就是說,在緩存層和數據庫層都沒有命中數據,那么,這種情況就叫作緩存穿透。
可以使用下圖來表示緩存穿透的現象。
 圖片
圖片
造成緩存穿透的主要原因就是:查詢某個Key對應的數據,Redis緩存中沒有相應的數據,則直接到數據庫中查詢。數據庫中也不存在要查詢的數據,則數據庫會返回空,而Redis也不會緩存這個空結果。
這就造成每次通過這樣的Key去查詢數據都會直接到數據庫中查詢,Redis不會緩存空結果。這就造成了緩存穿透的問題。
2.2.2 如何解決緩存穿透問題?
既然我們知道了造成緩存穿透的主要原因就是緩存中不存在相應的數據,直接到數據庫查詢,數據庫返回空結果,緩存中不存儲空結果。
那我們就自然而然的想到了第一種解決方案:就是把空對象緩存起來。當第一次從數據庫中查詢出來的結果為空時,我們就將這個空對象加載到緩存,并設置合理的過期時間,這樣,就能夠在一定程度上保障后端數據庫的安全。
第二種解決緩存穿透問題的解決方案:就是使用布隆過濾器,布隆過濾器可以針對大數據量的、有規律的鍵值進行處理。一條記錄是不是存在,本質上是一個Bool值,只需要使用 1bit 就可以存儲。我們可以使用布隆過濾器將這種表示是、否等操作,壓縮到一個數據結構中。比如,我們最熟悉的用戶性別這種數據,就非常適合使用布隆過濾器來處理。
2.3 緩存雪崩
如果緩存系統出現故障,所有的并發流量就會直接到達數據庫。
2.3.1 什么是緩存雪崩?
如果在某一時刻緩存集中失效,或者緩存系統出現故障,所有的并發流量就會直接到達數據庫。數據存儲層的調用量就會暴增,用不了多長時間,數據庫就會被大流量壓垮,這種級聯式的服務故障,就叫作緩存雪崩。
可以用下圖來表示緩存雪崩的現象。
 圖片
圖片
造成緩存雪崩的主要原因就是緩存集中失效,或者緩存服務發生故障,瞬間的大并發流量壓垮了數據庫。
2.3.2 如何解決緩存雪崩問題?
解決緩存雪崩問題最常用的一種方案就是保證Redis的高可用,將Redis緩存部署成高可用集群(必要時候做成異地多活),可以有效的防止緩存雪崩問題的發生。
為了緩解大并發流量,我們也可以使用限流降級的方式防止緩存雪崩。例如,在緩存失效后,通過加鎖或者使用隊列來控制讀數據庫寫緩存的線程數量。具體點就是設置某些Key只允許一個線程查詢數據和寫緩存,其他線程等待。則能夠有效的緩解大并發流量對數據庫打來的巨大沖擊。
另外,我們也可以通過數據預熱的方式將可能大量訪問的數據加載到緩存,在即將發生大并發訪問的時候,提前手動觸發加載不同的數據到緩存中,并為數據設置不同的過期時間,讓緩存失效的時間點盡量均勻,不至于在同一時刻全部失效。
至此,我們已經了解了什么是緩存擊穿、穿透和雪崩,也了解了如何解決這些問題。那落地到代碼該如何實現呢?這就是我們手寫的高性能Redis組件要解決的核心問題。
三、適應人群
大廠向來注重性能,并且在高并發、大流量場景下是絕對不允許出現緩存擊穿、穿透和雪崩問題。
否則,一旦出現這些問題,大量流量打向數據庫,數據庫由于根本扛不住這么大的流量而被瞬間擊垮,導致整個系統都可能陷入癱瘓和宕機,那勢必為大廠帶來巨大的經濟損失。所以,大廠是絕對不允許出現緩存擊穿、穿透和雪崩問題的。
所以,熟練掌握緩存擊穿、穿透和雪崩問題的基本概念和常用的解決方案,已經是進大廠必備的基礎技能。如果小伙伴們現在已經在大廠,亦或是想要進入大廠,那高性能Redis組件是你必須要掌握的。
如果小伙伴們已經在大廠,不了解緩存擊穿、穿透和雪崩問題的處理方案,或者想要進入大廠,亦或是一直突破不了自己的技術瓶頸,平時受如下問題困擾,可以跟冰河一起學習手寫高性能Redis組件,從根本上突破自己的技術瓶頸,積累更多大廠處理實際問題的經驗。
- 剛畢業,想快速提升自己,快速積累緩存相關問題的處理方案經驗,但不知從何學起。
- 校招、社招沒什么拿的出手的項目,簡歷上寫的項目沒啥含金量,投出的簡歷石沉大海。
- 一直在小公司做CRUD,數據量也不多,公司規范不健全,根本不知道還有緩存擊穿、穿透和雪崩這回事。
- 公司項目沒什么并發,在線人數也不多,系統并發量不高,只是簡單的CRUD就能滿足需求。
- 學了一些緩存相關的知識,也知道一些基本概念,能說出一些簡單的方案,但是沒實際項目經驗。
- 自我感覺掌握了一些緩存擊穿、穿透和雪崩問題的處理方案,但是在真正做項目時,還是不知道如何下手,面試時也是一臉懵逼。
- 想做一些緩存處理相關的中間件和業務項目,根本不知道怎么做,更別提架構設計和研發了。
- 簡歷上寫了了解或熟悉緩存擊穿、穿透和雪崩問題的處理方案,在面試過程中,面試官一般會基于簡歷循序漸進深入發問,不知道怎么回答。
- 在大廠工作多年,參與了一些系統的建設與研發,但是也沒機會參與緩存問題處理方案的整個建設過程,很難積累系統性處理緩存問題的方案知識。
- 其他問題。。。
從各位小伙伴的反饋來看,小公司的小伙伴受限于業務,接觸不到高并發、大流量的業務場景,也不會涉及到緩存擊穿、穿透和雪崩問題。
大廠的小伙伴由于某些原因接觸不到緩存問題處理方案的整個建設過程,很難積累緩存擊穿、穿透和雪崩問題處理方案的知識。沒有系統性落地成實際項目的經驗,很難成體系的積累處理緩存問題方案的編程經驗。
所以,如果你正在被如上問題所困擾,不妨跟冰河一起學習下手寫高性能Redis組件項目,向前邁出一小步,或許困擾你的問題就能迎刃而解。
四、技術選型
這次帶著大家一起手寫的高性能Redis組件,在代碼結構上非常精簡,核心功能就是解決緩存擊穿、穿透和雪崩問題。主要的技術選型如下:
- 容器框架:Spring(不強制依賴)
- Redis框架:Redisson(不強制依賴)
- 單元測試:Junit(不強制依賴)
- 基準性能測試:JMH(不強制依賴)