三個巧技,讓分庫分表 LIMIT 翻頁性能直接拉滿!
線上出了個離譜問題:運營同學在后臺導出近 3 個月訂單時,點擊分頁到第 100 頁,直接把數據庫查崩了。排查后發現,代碼里寫了 LIMIT 9900, 100,在分庫分表場景下,這行 SQL 相當于讓 8 個分片各查 1 萬條數據,再拉到應用層內存排序,直接把內存溢出了。
其實分庫分表的分頁查詢,藏著很多反常識的奇技淫巧,但這些技巧都有嚴格的適用邊界,用錯了反而會埋坑。我來分享 3 個實戰中驗證過的騷操作。
分庫分表 LIMIT 是性能殺手
單表分頁用 LIMIT offset, size 沒問題,但分庫分表后,數據散在多個分片里,比如你要查 LIMIT 10000, 10(第 1001 頁),會發生兩件離譜的事:
全分片掃描:每個分片都要執行 LIMIT 0, 10010(因為不知道其他分片的數據分布,只能把前 10010 條都查出來,避免漏數據);
內存爆炸排序:假設 8 個分片,每個返回 10010 條,共 8 萬多條數據,全拉到應用層排序,再截取第 10000-10010 條。內存和 CPU 直接飆紅,我之前見過最夸張的案例,offset=100000 時,一個分頁請求耗時 12 秒,直接觸發服務熔斷。
所以我們下邊要講的都是繞開全分片掃描 + 內存排序,但每個方案的適用場景天差地別,核心原則:不盲目追高性能,先看業務場景是否匹配。
錨點分頁
錨點分頁,性能最優,但僅限加載更多場景。
這是我最常用的技巧,核心思路是用數據本身的有序字段當錨點,替代 offset,比如按自增 ID 或時間戳分頁。但注意:不是所有有序字段都能用,必須滿足分片內 + 分片間都有序。
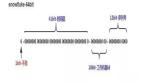
按 ID 范圍分片
假設訂單表按 ID 范圍分 3 個分片:
- 分片 1:ID 1-10000(分片內有序,且小于分片 2 的 ID);
- 分片 2:ID 10001-20000(同理);
- 分片 3:ID 20001-30000(同理);
要查第 2 頁(10 條 / 頁),步驟如下:
- 查第 1 頁時:執行
ORDER BY id DESC LIMIT 10,拿到最后一條數據的 ID 是last_id=100(這個 ID 就是錨點); - 查第 2 頁時:直接用
WHERE id < 100 ORDER BY id DESC LIMIT 10; - 查第 3 頁時:再用第 2 頁最后一條的 ID(比如 90)當錨點,執行
WHERE id < 90 ORDER BY id DESC LIMIT 10。
為什么性能高?
每個分片都能獨立執行 WHERE id < xxx LIMIT 10,只返回 10 條數據(不用查前 N 條)。比如查第 1001 頁,每個分片也只返回 10 條,匯總后排序取 10 條,網絡和內存開銷直接降為原來的 1/1000。
必避的 2 個坑:
- 別用哈希分片:如果按ID mod 3哈希分片,分片 1 的 ID 可能是 3、6、9...,分片 2 是 1、4、7...,此時 ID 全局有序但分片內無序,執行
WHERE id < 100仍需全量掃描分片內數據,退化為 “內存聚合”; - 不支持跳頁:只
加載更多(下一頁依賴上一頁的錨點),無法直接從第 1 頁跳到第 100 頁。但可以通過產品設計規避,比如抖音、小紅書的列表都是加載更多,用戶體驗反而更好。
分片標記法
剛才的錨點分頁不支持跳頁,但有些場景比如后臺管理系統,又必須要跳頁,怎么辦?我之前在電商后臺做訂單導出時,用過分片標記法,核心是給每個庫、表記錄數據范圍和總量,快速定位目標頁在哪個分片。
分片標記法支持跳頁,但必須控制元數據一致性。
用法示例
假設訂單表按用戶 ID 范圍分 2 庫,每庫按時間分 12 表(如庫 1 - 表 202401、庫 1 - 表 202402...),先在 Redis 里維護 庫、表級別的元數據:
庫 - 表 | 起始 ID | 結束 ID | 數據總量 |
庫 1 - 表 202401 | 1 | 5000 | 5000 |
庫 1 - 表 202402 | 5001 | 12000 | 7000 |
庫 2 - 表 202401 | 12001 | 18000 | 6000 |
.... | .... | ..18000 | 6000 |
現在要查 LIMIT 15000, 10(第 1501 頁),步驟如下:
- 查元數據定位庫、表:計算累計數據量,庫 1 - 表 202401(5000)+ 庫 1 - 表 202402(7000)= 12000 <15000,再加上庫 2 - 表 202401 的 6000,累計 18000>15000,所以目標在庫 2 - 表 202401;
- 計算表內偏移量:表內偏移量 = 15000 - 12000 = 3000,所以庫 2 - 表 202401 執行
LIMIT 3000, 10; - 直接返回結果:因為庫、表按 ID 有序,查詢結果就是全局第 15000-15010 條,不用匯總其他分片。
必避的 2 個坑:
1.元數據必須實時但不能強同步:
數據新增、刪除時,要同步更新 Redis 元數據,但高并發下不能加分布式鎖(會卡住業務),建議用定時 + 增量日志:每 5 分鐘全量統計一次,同時記錄增量(如新增 100 條、刪除 10 條),查詢時疊加增量;
若允許最終一致性(如后臺查詢允許誤差 10 條),這個方案很穩;若要強一致,只能放棄跳頁,用錨點分頁;
2.不支持非分片鍵排序:如果要按支付時間排序(分片鍵是用戶 ID),支付時間在 “庫 - 表” 內無序,元數據無法定位,仍需全分片掃描。
反向分頁
反向分頁,僅適用于查最后 1 頁,別亂用
這個技巧最反常識,但局限性也最大。如果要查最后幾頁數據(比如用戶查最早的訂單),用普通分頁會查 LIMIT 9990, 10,但可以反向查,避開大 offset。
僅查最后 1 頁
假設訂單表按 ID 范圍分片,總數據量 10000 條(1000 頁,10 條 / 頁),要查最后 1 頁(ID 9991-10000):
- 反向查錨點:執行
ORDER BY id ASC LIMIT 10,拿到最前面 10 條的 ID(1-10),取最大 ID 作為反向錨點(10); - 查最后 1 頁:執行
WHERE id > 10 ORDER BY id DESC LIMIT 10,拿到的就是 ID 10000-9991(最后 10 條); - 調整順序:如果需要正序展示,把結果再倒過來即可。
為什么能生效?
因為 LIMIT 0, 10 比 LIMIT 9990, 10 快 100 倍. 每個分片查前 10 條數據,匯總后取最大的 10 個 ID 作為錨點,再查大于錨點的數據,避免了大 offset 掃描。
必避的 2 個坑:
- 僅適用于最后 1 頁:如果要查倒數第 10 頁(第 991 頁),按這個邏輯無法定位錨點(需要知道第 9900 條數據的 ID),只能查倒數第 1 頁;
- 數據不能有大量刪除:如果中間有大量 ID 被刪除(如 ID 5000-8000 都被刪了),總數據量變為 7000 條,此時
WHERE id >10 ORDER BY id DESC LIMIT10拿到的是 7000-6991(正確),但如果刪除的是最后 100 條(ID 9901-10000),總數據量變為 9900 條,需要重新計算反向錨點,增加復雜度。
說在后邊
其實分庫分表分頁的核心不是炫技,而是在業務和技術之間找平衡。能通過產品設計規避跳頁(用加載更多),就優先用錨點分頁(性能最優),必須跳頁就用分片標記法(接受最終一致性);實在沒辦法才考慮中間件(如 ShardingSphere 的全局排序)。