破解gh-ost變更導致MySQL表膨脹之謎
一、問題背景
二、索引結構
1. B+tree
2. 頁(page)
3. 溢出頁
4. 頁面分裂
三、當前DDL變更機制
四、變更后,表為什么膨脹?
1. 原因說明
2. 流程復現
3. 排查過程
五、變更后,統計信息為什么差異巨大?
六、統計信息與慢SQL之間的關聯關系?
七、如何臨時解決該問題?
八、如何長期解決該問題?
九、總結
一、問題背景
業務同學在 OneDBA 平臺進行一次正常 DDL 變更完成后(變更內容跟此次問題無關),發現一些 SQL 開始出現慢查,同時變更后的表比變更前的表存儲空間膨脹了幾乎 100%。經過分析和流程復現完整還原了整個事件,發現了 MySQL 在平衡 B+tree 頁分裂方面遇到單行記錄太大時的一些缺陷,整理分享。
為了能更好的說明問題背后的機制,會進行一些關鍵的“MySQL原理”和“當前DDL變更流程”方面的知識鋪墊,熟悉的同學可以跳過。
本次 DDL 變更后帶來了如下問題:
- 變更后,表存儲空間膨脹了幾乎 100%;
- 變更后,表統計信息出現了嚴重偏差;
- 變更后,部分有排序的 SQL 出現了慢查。
現在來看,表空間膨脹跟統計信息出錯是同一個問題導致,而統計信息出錯間接導致了部分SQL出現了慢查,下面帶著這些問題開始一步步分析找根因。
二、索引結構
B+tree
InnoDB 表是索引組織表,也就是所謂的索引即數據,數據即索引。索引分為聚集索引和二級索引,所有行數據都存儲在聚集索引,二級索引存儲的是字段值和主鍵,但不管哪種索引,其結構都是 B+tree 結構。
一棵 B+tree 分為根頁、非葉子節點和葉子節點,一個簡單的示意圖(from Jeremy Cole)如下:
 圖片
圖片
由于 InnoDB B+tree 結構高扇區特性,所以每個索引高度基本在 3-5 層之間,層級(Level)從葉子節點的 0 開始編號,沿樹向上遞增。每層的頁面節點之間使用雙向鏈表,前一個指針和后一個指針按key升序排列。
最小存儲單位是頁,每個頁有一個編號,頁內的記錄使用單向鏈表,按 key 升序排列。每個數據頁中有兩個虛擬的行記錄,用來限定記錄的邊界;其中最小值(Infimum)表示小于頁面上任何 key 的值,并且始終是單向鏈表記錄列表中的第一個記錄;最大值(Supremum)表示大于頁面上任何 key 的值,并且始終是單向鏈表記錄列表中的最后一條記錄。這兩個值在頁創建時被建立,并且在任何情況下不會被刪除。
非葉子節點頁包含子頁的最小 key 和子頁號,稱為“節點指針”。
現在我們知道了我們插入的數據最終根據主鍵順序存儲在葉子節點(頁)里面,可以滿足點查和范圍查詢的需求。
頁(page)
默認一個頁 16K 大小,且 InnoDB 規定一個頁最少能夠存儲兩行數據,這里需要注意規定一個頁最少能夠存儲兩行數據是指在空間分配上,并不是說一個頁必須要存兩行,也可以存一行。
怎么實現一個頁必須要能夠存儲兩行記錄呢? 當一條記錄 <8k 時會存儲在當前頁內,反之 >8k 時必須溢出存儲,當前頁只存儲溢出頁面的地址,需 20 個字節(行格式:Dynamic),這樣就能保證一個頁肯定能最少存儲的下兩條記錄。
溢出頁
當一個記錄 >8k 時會循環查找可以溢出存儲的字段,text類字段會優先溢出,沒有就開始挑選 varchar 類字段,總之這是 InnoDB 內部行為,目前無法干預。
建表時無論是使用 text 類型,還是 varchar 類型,當大小 <8k 時都是存儲在當前頁,也就是在 B+tree 結構中,只有 >8k 時才會進行溢出存儲。
頁面分裂
隨著表數據的變化,對記錄的新增、更新、刪除;那么如何在 B+tree 中高效管理動態數據也是一項核心挑戰。
MySQL InnoDB 引擎通過頁面分裂和頁面合并兩大關鍵機制來動態調整存儲結構,不僅能確保數據的邏輯完整性和邏輯順序正確,還能保證數據庫的整體性能。這些機制發生于 InnoDB 的 B+tree 索引結構內部,其具體操作是:
- 頁面分裂:當已滿的索引頁無法容納新記錄時,創建新頁并重新分配記錄。
- 頁面合并:當頁內記錄因刪除/更新低于閾值時,與相鄰頁合并以優化空間。
深入理解上述機制至關重要,因為頁面的分裂與合并將直接影響存儲效率、I/O模式、加鎖行為及整體性能。其中頁面的分裂一般分為兩種:
- 中間點(mid point)分裂:將原始頁面中50%數據移動到新申請頁面,這是最普通的分裂方法。
- 插入點(insert point)分裂:判斷本次插入是否遞增 or 遞減,如果判定為順序插入,就在當前插入點進行分裂,這里情況細分較多,大部分情況是直接插入到新申請頁面,也可能會涉及到已存在記錄移動到新頁面,有有些特殊情況下還會直接插入老的頁面(老頁面的記錄被移動到新頁面)。
表空間管理
InnoDB的B+tree是通過多層結構映射在磁盤上的,從它的邏輯存儲結構來看,所有數據都被有邏輯地存放在一個空間中,這個空間就叫做表空間(tablespace)。表空間由段(segment)、區(extent)、頁(page)組成,搞這么多手段的唯一目的就是為了降低IO的隨機性,保證存儲物理上盡可能是順序的。
三、當前DDL變更機制
在整個數據庫平臺(OneDBA)構建過程中,MySQL 結構變更模塊是核心基礎能力,也是研發同學在日常業務迭代過程中使用頻率較高的功能之一,主要圍繞對表加字段、加索引、改屬性等操作,為了減少這些操作對線上數據庫或業務的影響,早期便為 MySQL 結構變更開發了一套基于容器運行的無鎖變更程序,核心采用的是全量數據復制+增量 binlog 回放來進行變更,也是業界通用做法(內部代號:dw-osc,基于 GitHub 開源的 ghost 工具二次開發),主要解決的核心問題:
- 實現無鎖化的結構變更,變更過程中不會阻擋業務對表的讀寫操作。
- 實現變更不會導致較大主從數據延遲,避免業務從庫讀取不到數據導致業務故障。
- 實現同時支持大規模任務變更,使用容器實現使用完即銷毀,無變更任務時不占用資源。
變更工具工作原理簡單描述(重要):
 圖片
圖片
重點:
簡單理解工具進行 DDL 變更過程中為了保證數據一致性,對于全量數據的復制與 binlog 回放是并行交叉處理,這種機制它有一個特點就是【第三步】會導致新插入的記錄可能會先寫入到表中(主鍵 ID 大的記錄先寫入到了表),然后【第二步】中復制數據后寫入到表中(主鍵 ID 小的記錄后寫入表)。
這里順便說一下當前得物結構變更整體架構:由于變更工具的工作原理需消費大量 binlog 日志保證數據一致性,會導致在變更過程中會有大量的帶寬占用問題,為了消除帶寬占用問題,開發了 Proxy 代理程序,在此基礎之上支持了多云商、多區域本地化變更。
目前整體架構圖如下:
 圖片
圖片
四、變更后,表為什么膨脹?
原因說明
上面幾個關鍵點鋪墊完了,回到第一個問題,這里先直接說明根本原因,后面會闡述一下排查過程(有同學感興趣所以分享一下,整個過程還是耗費不少時間)。
在『結構變更機制』介紹中,我們發現這種變更機制它有一個特點,就是【第三步】會導致新插入的記錄可能會先寫入到表中(主鍵 ID 大的記錄先寫入到了表),然后【第二步】中復制數據后寫入到表中(主鍵 ID 小的記錄)。這種寫入特性疊加單行記錄過大的時候(業務表單行記錄大小 5k 左右),會碰到 MySQL 頁分裂的一個瑕疵(暫且稱之為瑕疵,或許是一個 Bug),導致了一個頁只存儲了 1 條記錄(16k 的頁只存儲了 5k,浪費 2/3 空間),放大了存儲問題。
流程復現
下面直接復現一下這種現象下導致異常頁分裂的過程:
CREATE TABLE `sbtest` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`pad` varchar(12000),
PRIMARY KEY (`id`)
) ENGINE=InnoDB;然后插入兩行 5k 大小的大主鍵記錄(模擬變更時 binlog 回放先插入數據):
insert into sbtest values (10000, repeat('a',5120));
insert into sbtest values (10001, repeat('a',5120));這里寫了一個小工具打印記錄對應的 page 號和 heap 號。
# ./peng
[pk:10000] page: 3 -> heap: 2
[pk:10001] page: 3 -> heap: 3可以看到兩條記錄都存在 3 號頁,此時表只有這一個頁。
繼續開始順序插入數據(模擬變更時 copy 全量數據過程),插入 rec-1:
insert into sbtest values (1, repeat('a',5120));# ./peng
[pk:1] page: 3 -> heap: 4
[pk:10000] page: 3 -> heap: 2
[pk:10001] page: 3 -> heap: 3插入 rec-2:
insert into sbtest values (2, repeat('a',5120));# ./peng
[pk:1] page: 4 -> heap: 2
[pk:2] page: 4 -> heap: 3
[pk:10000] page: 5 -> heap: 2
[pk:10001] page: 5 -> heap: 3可以看到開始分裂了,page 3 被提升為根節點了,同時分裂出兩個葉子節點,各自存了兩條數據。此時已經形成了一棵 2 層高的樹,還是用圖表示吧,比較直觀,如下:
 圖片
圖片
插入 rec-3:
insert into sbtest values (3, repeat('a',5120));# ./peng
[pk:1] page: 4 -> heap: 2
[pk:2] page: 4 -> heap: 3
[pk:3] page: 5 -> heap: 4
[pk:10000] page: 5 -> heap: 2
[pk:10001] page: 5 -> heap: 3示意圖如下:
 圖片
圖片
插入 rec-4:
insert into sbtest values (4, repeat('a',5120));# ./peng
[pk:1] page: 4 -> heap: 2
[pk:2] page: 4 -> heap: 3
[pk:3] page: 5 -> heap: 4
[pk:4] page: 5 -> heap: 3
[pk:10000] page: 5 -> heap: 2
[pk:10001] page: 6 -> heap: 2這里開始分裂一個新頁 page 6,開始出現比較復雜的情況,同時也為后面分裂導致一個頁只有 1 條數據埋下伏筆:
 圖片
圖片
這里可以看到把 10001 這條記錄從 page 5 上面遷移到了新建的 page 6 上面(老的 page 5 中會刪除 10001 這條記錄,并放入到刪除鏈表中),而把當前插入的 rec-4 插入到了原來的 page 5 上面,這個處理邏輯在代碼中是一個特殊處理,向右分裂時,當插入點頁面前面有大于等于兩條記錄時,會設置分裂記錄為 10001,所以把它遷移到了 page 6,同時會把當前插入記錄插入到原 page 5。具體可以看 btr_page_get_split_rec_to_right 函數。
/* 這里返回true表示將行記錄向右分裂:即分配的新page的hint_page_no為原page+1 */
ibool btr_page_get_split_rec_to_right(
/*============================*/
btr_cur_t* cursor,
rec_t** split_rec)
{
page_t* page;
rec_t* insert_point;
// 獲取當前游標頁和insert_point
page = btr_cur_get_page(cursor);
insert_point = btr_cur_get_rec(cursor);
/* 使用啟發式方法:如果新的插入操作緊跟在同一頁面上的前一個插入操作之后,
我們假設這里存在一個順序插入的模式。 */
// PAGE_LAST_INSERT代表上次插入位置,insert_point代表小于等于待插入目標記錄的最大記錄位置
// 如果PAGE_LAST_INSERT=insert_point意味著本次待插入的記錄是緊接著上次已插入的記錄,
// 這是一種順序插入模式,一旦判定是順序插入,必然反回true,向右分裂
if (page_header_get_ptr(page, PAGE_LAST_INSERT) == insert_point) {
// 1. 獲取當前insert_point的page內的下一條記錄,并判斷是否是supremum記錄
// 2. 如果不是,繼續判斷當前insert_point的下下條記錄是否是supremum記錄
// 也就是說,會向后看兩條記錄,這兩條記錄有一條為supremum記錄,
// split_rec都會被設置為NULL,向右分裂
rec_t* next_rec;
next_rec = page_rec_get_next(insert_point);
if (page_rec_is_supremum(next_rec)) {
split_at_new:
/* split_rec為NULL表示從新插入的記錄開始分裂,插入到新頁 */
*split_rec = nullptr;
} else {
rec_t* next_next_rec = page_rec_get_next(next_rec);
if (page_rec_is_supremum(next_next_rec)) {
goto split_at_new;
}
/* 如果不是supremum記錄,則設置拆分記錄為下下條記錄 */
/* 這樣做的目的是,如果從插入點開始向上有 >= 2 條用戶記錄,
我們在該頁上保留 1 條記錄,因為這樣后面的順序插入就可以使用
自適應哈希索引,因為它們只需查看此頁面上的記錄即可對正確的
搜索位置進行必要的檢查 */
*split_rec = next_next_rec;
}
return true;
}
return false;
}插入 rec-5:
insert into sbtest values (5, repeat('a',5120));# ./peng
[pk:1] page: 4 -> heap: 2
[pk:2] page: 4 -> heap: 3
[pk:3] page: 5 -> heap: 4
[pk:4] page: 5 -> heap: 3
[pk:5] page: 7 -> heap: 3
[pk:10000] page: 7 -> heap: 2
[pk:10001] page: 6 -> heap: 2開始分裂一個新頁 page 7,新的組織結構方式如下圖:
 圖片
圖片
此時是一個正常的插入點右分裂機制,把老的 page 5 中的記錄 10000 都移動到了 page 7,并且新插入的 rec-5 也寫入到了 page 7 中。到此時看上去一切正常,接下來再插入記錄在當前這種結構下就會產生異常。
插入 rec-6:
insert into sbtest values (5, repeat('a',5120));# ./peng
[pk:1] page: 4 -> heap: 2
[pk:2] page: 4 -> heap: 3
[pk:3] page: 5 -> heap: 4
[pk:4] page: 5 -> heap: 3
[pk:5] page: 7 -> heap: 3
[pk:6] page: 8 -> heap: 3
[pk:10000] page: 8 -> heap: 2
[pk:10001] page: 6 -> heap: 2 圖片
圖片
此時也是一個正常的插入點右分裂機制,把老的 page 7 中的記錄 10000 都移動到了 page 8,并且新插入的 rec-6 也寫入到了 page 8 中,但是我們可以發現 page 7 中只有一條孤零零的 rec-5 了,一個頁只存儲了一條記錄。
按照代碼中正常的插入點右分裂機制,繼續插入 rec-7 會導致 rec-6 成為一個單頁、插入 rec-8 又會導致 rec-7 成為一個單頁,一直這樣循環下去。
目前來看就是在插入 rec-4,觸發了一個內部優化策略(具體優化沒太去研究),進行了一些特殊的記錄遷移和插入動作,當然跟記錄過大也有很大關系。
排查過程
有同學對這個問題排查過程比較感興趣,所以這里也整理分享一下,簡化了一些無用信息,僅供參考。
表總行數在 400 百萬,正常情況下的大小在 33G 左右,變更之后的大小在 67G 左右。
- 首先根據備份恢復了一個數據庫現場出來。
- 統計了業務表行大小,發現行基本偏大,在 4-7k 之間(一個頁只存了2行,浪費1/3空間)。
- 分析了變更前后的表數據頁,以及每個頁存儲多少行數據。
a.發現變更之前數據頁大概 200 百萬,變更之后 400 百萬,解釋了存儲翻倍。
b.發現變更之前存儲 1 行的頁基本沒有,變更之后存儲 1 行的頁接近 400 百萬。
基于現在這些信息我們知道了存儲翻倍的根本原因,就是之前一個頁存儲 2 條記錄,現在一個頁只存儲了 1 條記錄,新的問題來了,為什么變更后會存儲 1 條記錄,繼續尋找答案。
- 我們首先在備份恢復的實例上面進行了一次靜態變更,就是變更期間沒有新的 DML 操作,沒有復現。但說明了一個問題,異常跟增量有關,此時大概知道跟變更過程中的 binlog 回放特性有關【上面說的回放會導致主鍵 ID 大的記錄先寫入表中】。
- 寫了個工具把 400 百萬數據每條記錄分布在哪個頁里面,以及頁里面的記錄對應的 heap 是什么都記錄到數據庫表中分析,慢長等待跑數據。
 圖片
圖片
- 數據分析完后通過分析發現存儲一條數據的頁對應的記錄的 heap 值基本都是 3,正常應該是 2,意味著這些頁并不是一開始就存一條數據,而是產生了頁分裂導致的。
- 開始繼續再看頁分裂相關的資料和代碼,列出頁分裂的各種情況,結合上面的信息構建了一個復現環境。插入數據頁分裂核心函數。
btr_cur_optimistic_insert:樂觀插入數據,當前頁直接存儲
btr_cur_pessimistic_insert:悲觀插入數據,開始分裂頁
btr_root_raise_and_insert:單獨處理根節點的分裂
btr_page_split_and_insert:分裂普通頁,所有流程都在這個函數
btr_page_get_split_rec_to_right:判斷是否是向右分裂
btr_page_get_split_rec_to_left:判斷是否是向左分裂
heap
heap 是頁里面的一個概念,用來標記記錄在頁里面的相對位置,頁里面的第一條用戶記錄一般是 2,而 0 和 1 默認分配給了最大最小虛擬記錄,在頁面創建的時候就初始化好了,最大最小記錄上面有簡單介紹。
解析 ibd 文件
更快的方式還是應該分析物理 ibd 文件,能夠解析出頁的具體數據,以及被分裂刪除的數據,分裂就是把一個頁里面的部分記錄移動到新的頁,然后刪除老的記錄,但不會真正刪除,而是移動到頁里面的一個刪除鏈表,后面可以復用。
五、變更后,統計信息為什么差異巨大?
表統計信息主要涉及索引基數統計(也就是唯一值的數量),主鍵索引的基數統計也就是表行數,在優化器進行成本估算時有些 SQL 條件會使用索引基數進行抉擇索引選擇(大部分情況是 index dive 方式估算掃描行數)。
InnoDB 統計信息收集算法簡單理解就是采樣葉子節點 N 個頁(默認 20 個頁),掃描統計每個頁的唯一值數量,N 個頁的唯一值數量累加,然后除以N得到單個頁平均唯一值數量,再乘以表的總頁面數量就估算出了索引總的唯一值數量。
但是當一個頁只有 1 條數據的時候統計信息會產生嚴重偏差(上面已經分析出了表膨脹的原因就是一個頁只存儲了 1 條記錄),主要是代碼里面有個優化邏輯,對單個頁的唯一值進行了減 1 操作,具體描述如下注釋。本來一個頁面就只有 1 條記錄,再進行減 1 操作就變成 0 了,根據上面的公式得到的索引總唯一值就偏差非常大了。
static bool dict_stats_analyze_index_for_n_prefix(
...
// 記錄頁唯一key數量
uint64_t n_diff_on_leaf_page;
// 開始進行dive,獲取n_diff_on_leaf_page的值
dict_stats_analyze_index_below_cur(pcur.get_btr_cur(), n_prefix,
&n_diff_on_leaf_page, &n_external_pages);
/* 為了避免相鄰兩次dive統計到連續的相同的兩個數據,因此減1進行修正。
一次是某個頁面的最后一個值,一次是另一個頁面的第一個值。請考慮以下示例:
Leaf level:
page: (2,2,2,2,3,3)
... 許多頁面類似于 (3,3,3,3,3,3)...
page: (3,3,3,3,5,5)
... 許多頁面類似于 (5,5,5,5,5,5)...
page: (5,5,5,5,8,8)
page: (8,8,8,8,9,9)
我們的算法會(正確地)估計平均每頁有 2 條不同的記錄。
由于有 4 頁 non-boring 記錄,它會(錯誤地)將不同記錄的數量估計為 8 條
*/
if (n_diff_on_leaf_page > 0) {
n_diff_on_leaf_page--;
}
// 更新數據,在所有分析的頁面上發現的不同鍵值數量的累計總和
n_diff_data->n_diff_all_analyzed_pages += n_diff_on_leaf_page;
)可以看到PRIMARY主鍵異常情況下統計數據只有 20 萬,表有 400 百萬數據。正常情況下主鍵統計數據有 200 百萬,也與表實際行數差異較大,同樣是因為單個頁面行數太少(正常情況大部分也只有2條數據),再進行減1操作后,導致統計也不準確。
MySQL> select table_name,index_name,stat_value,sample_size from mysql.innodb_index_stats where database_name like 'sbtest' and TABLE_NAME like 'table_1' and stat_name='n_diff_pfx01';
+-------------------+--------------------------------------------+------------+-------------+
| table_name | index_name | stat_value | sample_size |
+-------------------+--------------------------------------------+------------+-------------+
| table_1 | PRIMARY | 206508 | 20 |
+-------------------+--------------------------------------------+------------+-------------+
11 rows in set (0.00 sec)優化
為了避免相鄰兩次dive統計到連續的相同的兩個數據,因此減1進行修正。
這里應該是可以優化的,對于主鍵來說是不是可以判斷只有一個字段時不需要進行減1操作,會導致表行數統計非常不準確,畢竟相鄰頁不會數據重疊。
最低限度也需要判斷單個頁只有一條數據時不需要減1操作。
六、統計信息與慢SQL之間的關聯關系?
當前 MySQL 對大部分 SQL 在評估掃描行數時都不再依賴統計信息數據,而是通過一種 index dive 采樣算法實時獲取大概需要掃描的數據,這種方式的缺點就是成本略高,所以也提供有參數來控制某些 SQL 是走 index dive 還是直接使用統計數據。
另外在SQL帶有 order by field limit 時會觸發MySQL內部的一個關于 prefer_ordering_index 的 ORDER BY 優化,在該優化中,會比較使用有序索引和無序索引的代價,誰低用誰。
當時業務有問題的慢 SQL 就是被這個優化干擾了。
# where條件
user_id = ? and biz = ? and is_del = ? and status in (?) ORDER BY modify_time limit 5
# 表索引
idx_modify_time(`modify_time`)
idx_user_biz_del(`user_id`,`biz`, `is_del`)正常走 idx_user_biz_del 索引為過濾性最好,但需要對 modify_time 字段進行排序。
這個優化機制就是想嘗試走 idx_modify_time 索引,走有序索引想避免排序,然后套了一個公式來預估如果走 idx_modify_time 有序索引大概需要掃描多少行?公式非常簡單直接:表總行數 / 最優索引的掃描行數 * limit。
- 表總行數:也就是統計信息里面主鍵的 n_rows
- 最優索引的掃描行數:也就是走 idx_user_biz_del 索引需要掃描的行數
- limit:也就是 SQL 語句里面的 limit 值
使用有序索引預估的行數對比最優索引的掃描行數來決定使用誰,在這種改變索引的策略下,如果表的總行數估計較低(就是上面主鍵的統計值),會導致更傾向于選擇有序索引。
但一個最重要的因素被 MySQL 忽略了,就是實際業務數據分布并不是按它給的這種公式來,往往需要掃描很多數據才能滿足 limit 值,造成慢 SQL。
七、如何臨時解決該問題?
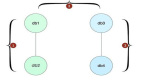
發現問題后,可控的情況下選擇在低峰期對表執行原生 alter table xxx engine=innodb 語句, MySQL 內部重新整理了表空間數據,相關問題恢復正常。但這個原生 DDL 語句,雖然變更不會產生鎖表,但該語句無法限速,同時也會導致主從數據較大延遲。
為什么原生 DDL 語句可以解決該問題?看兩者在流程上的對比區別。
alter table xxx engine=innodb變更流程 | 當前工具結構變更流程 |
|
|
可以看出結構變更唯一不同的就是增量 DML 語句是等全量數據復制完成后才開始應用,所以能修復表空間,沒有導致表膨脹。
八、如何長期解決該問題?
關于業務側的改造這里不做過多說明,我們看看從變更流程上面是否可以避免這個問題。
既然在變更過程中復制全量數據和 binlog 增量數據回放存在交叉并行執行的可能,那么如果我們先執行全量數據復制,然后再進行增量 binlog 回放是不是就可以繞過這個頁分裂問題(就變成了跟 MySQL 原生 DDL 一樣的流程)。
變更工具實際改動如下圖:
 圖片
圖片
這樣就不存在最大記錄先插入到表中的問題,丟棄的記錄后續全量復制也同樣會把記錄復制到臨時表中。并且這個優化還能解決需要大量回放 binlog 問題,細節可以看看 gh-ost 的 PR-1378。
九、總結
本文先介紹了一些關于 InnoDB 索引機制和頁溢出、頁分裂方面的知識;介紹了業界通用的 DDL 變更工具流程原理。
隨后詳細分析了變更后表空間膨脹問題根因,主要是當前變更流程機制疊加單行記錄過大的時候(業務表單行記錄大小 5k 左右),會碰到 MySQL 頁分裂的一個瑕疵,導致了一個頁只存儲了 1 條記錄(16k 的頁只存儲了 5k,浪費 2/3 空間),導致存儲空間膨脹問題。
最后分析了統計信息出錯的原因和統計信息出錯與慢 SQL 之間的關聯關系,以及解決方案。