MySQL 行級鎖:加鎖機制、核心規則與實踐指南
前言
在高并發MySQL場景中,行級鎖是保障數據一致性、減少鎖沖突的關鍵技術。與表級鎖(如MyISAM引擎)相比,行級鎖僅鎖定操作涉及的行數據,能顯著提升并發讀寫效率。
行級鎖的兩種核心類型
InnoDB的行級鎖基于鎖類型 + 鎖范圍劃分,核心類型分為共享鎖(S鎖)和排他鎖(X鎖),二者的兼容性直接影響事務并發:
鎖類型 | 作用 | 與其他鎖的兼容性 |
共享鎖( | 允許事務讀取一行數據( | 與 |
排他鎖( | 允許事務修改 / 刪除一行數據( | 與 |
- 共享鎖又稱讀鎖,是讀取操作創建的鎖。其他用戶可以并發讀取數據,但任何事務都不能對數據進行修改(獲取數據上的排他鎖),直到已釋放所有共享鎖。
- 排他鎖又稱寫鎖,如果事務
T對數據A加上排他鎖后,則其他事務不能再對A加任何類型的鎖。獲得排他鎖的事務既能讀數據,又能修改數據。
意向鎖
除了S鎖和X鎖之外,Innodb還有兩種鎖,是IX鎖和IS鎖,這里的I是Intention的意思,即意向鎖。
IS鎖: 表示事務打算在資源上設置共享鎖(讀鎖)。這通常用于表示事務計劃讀取資源,并不希望在讀取時有其他事務設置排它鎖。IX鎖: 表示事務打算在資源上設置排它鎖(寫鎖)。這表示事務計劃修改資源,并不希望有其他事務同時設置共享或排它鎖。
事務隔離級別
- 未提交讀(
Read uncommitted)是最低的隔離級別。通過名字我們就可以知道,在這種事務隔離級別下,一個事務可以讀到另外一個事務未提交的數據。這種隔離級別下會存在幻讀、不可重復讀和臟讀的問題。 - 提交讀(
Read committed)也可以翻譯成讀已提交,通過名字也可以分析出,在一個事務修改數據過程中,如果事務還沒提交,其他事務不能讀該數據。所以,這種隔離級別是可以避免臟讀的發生的。 - 可重復讀(
Repeatable reads),由于提交讀隔離級別會產生不可重復讀的讀現象。所以,比提交讀更高一個級別的隔離級別就可以解決不可重復讀的問題。這種隔離級別就叫可重復讀。但是這種隔離級別沒辦法徹底解決幻讀。 - 可串行化(
Serializable)是最高的隔離級別,前面提到的所有的隔離級別都無法解決的幻讀,在可串行化的隔離級別中可以解決。
擴展
- 臟讀又稱無效數據的讀出,是指在數據庫訪問中,事務
T1將某一值修改,然后事務T2讀取該值,此后T1因為某種原因撤銷對該值的修改,這就導致了T2所讀取到的數據是無效的。 - 不可重復讀是指在數據庫訪問中,一個事務范圍內兩個相同的查詢卻返回了不同數據。這是由于查詢時系統中其他事務修改的提交而引起的。比如事務
T1讀取某一數據,事務T2讀取并修改了該數據,T1為了對讀取值進行檢驗而再次讀取該數據,便得到了不同的結果。 - 幻讀是指當事務不是獨立執行時發生的一種現象,例如第一個事務對一個表中的數據進行了修改,比如這種修改涉及到表中的全部數據行。同時,第二個事務也修改這個表中的數據,這種修改是向表中插入一行新數據。那么以后就會發生操作第一個事務的用戶發現表中還有沒有修改的數據行,就好象發生了幻覺一樣。
MySQL的行級鎖鎖的到底是什么?
數據庫的行級鎖根據鎖的粒度不同,可以分為:
Record Lock表示記錄鎖,鎖的是索引記錄,沒有定義主鍵,那么MySQL會默認選擇一個唯一的非空索引作為聚簇索引。如果沒有適合的非空唯一索引,則會創建一個隱藏的主鍵(row_id)作為聚簇索引Gap Lock是間隙鎖,鎖的是索引記錄之間的間隙,間隙鎖只有在Repeatable Reads這種隔離級別中才會起作用。Next-Key Lock是Record Lock和Gap Lock的組合,同時鎖索引記錄和間隙。他的范圍是左開右閉的。
加鎖原則
規則類型 | 適用場景 | 加鎖單位變化 | 關鍵特點 |
原則 1 | 所有行級鎖場景 | 始終是 | 行鎖 + 間隙鎖,防幻讀 |
原則 2 | 所有查詢 | 僅訪問到的對象加鎖 | 未訪問的行 / 間隙不鎖定 |
優化 1 | 索引等值查詢(唯一索引加鎖) |
→ 行鎖 | 無間隙鎖,鎖范圍最小 |
優化 2 | 索引等值查詢(右遍歷不滿足) |
→ 間隙鎖 | 無行鎖,僅鎖間隙 |
| 唯一索引范圍查詢 | 額外鎖定第一個不滿足條件的行 | 鎖范圍擴大,易導致不必要阻塞 |
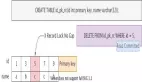
測試數據
-- 表結構:users表,id為主鍵(唯一索引),age為普通索引(非唯一)
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT, -- 唯一索引(主鍵)
age INT,
name VARCHAR(50),
KEY idx_age (age) -- 普通索引
);
-- 插入測試數據
INSERT INTO users (id, age, name) VALUES
(5, 20, 'A'),
(10, 25, 'B'),
(15, 30, 'C'),
(20, 35, 'D'),
(25, 40, 'E');案例一
當我們執行update users set age=age+1 where id = 7的時候,由于表中沒有id=7的記錄,所以:
- 根據原則 1,加鎖單位是
Next-Key Lock,加鎖范圍就是(5,10]; - 根據優化 2,這是一個等值查詢
id=7,而id=10不滿足查詢條件,Next-Key Lock退化成間隙鎖,因此最終加鎖的范圍是(5,10)。
案例二
當我們執行select * from users where id>=10 and id<11 for update的時候:
- 根據原則 1,加鎖單位是
Next-Key Lock,會給(5,10]加上Next-Key Lock,范圍查找就往后繼續找,找到id=15這一行停下來 - 根據優化 1,主鍵
id上的等值條件,退化成行鎖,只加了id=10這一行的行鎖。 - 根據原則 2,訪問到的都要加鎖,因此需要加
Next-Key Lock(10,15]。因此最終加的是行鎖id=10和Next-Key Lock(10,15]。
案例三
當我們執行select * from users where id>10 and id<=15 for update的時候:
- 根據原則 1,加鎖單位是
Next-Key Lock,會給(10,15]加上Next-Key Lock,并且因為id是唯一鍵,所以循環判斷到id=15這一行就應該停止了。 - 但是,
InnoDB會往前掃描到第一個不滿足條件的行為止,也就是id=20。而且由于這是個范圍掃描,因此索引id上的(15,20]這個Next-Key Lock也會被鎖上。
案例四
當我們執行select * from users where age>=25 and age<26 for update的時候:
- 根據原則 1,加鎖單位是
Next-Key Lock,會給(20,25]加上Next-Key Lock,范圍查找就往后繼續找,找到age=30這一行停下來 - 根據原則 2,訪問到的都要加鎖,因此需要加
Next-Key Lock(25,30]。 - 由于索引
age是非唯一索引,沒有優化規則,也就是說不會蛻變為行鎖,因此最終加的鎖是,索引age上的(20,25]和(25,30]這兩個Next-Key Lock。
總結
Record Lock表示記錄鎖,鎖的是索引記錄。Gap Lock是間隙鎖,鎖的是索引記錄之間的間隙。Next-Key Lock是Record Lock和Gap Lock的組合,同時鎖索引記錄和間隙。他的范圍是左開右閉的。
InnoDB的RR級別中,加鎖的基本單位是Next-Key Lock,只要掃描到的數據都會加鎖。唯一索引上的范圍查詢會訪問到不滿足條件的第一個值為止。
同時,為了提升性能和并發度,也有兩個優化點:
- 索引上的等值查詢,給唯一索引加鎖的時候,
Next-Key Lock退化為行鎖。 - 索引上的等值查詢,向右遍歷時且最后一個值不滿足等值條件的時候,
Next-Key Lock退化為間隙鎖。