別再用雪花算法生成ID了!試試這個吧!
今天聊聊服務(wù)器中唯一ID生成。唯一ID生成中雪花算法大家都比較熟,那如果加一個要求呢:
盡量短的數(shù)字ID
背景
之前的項目有個需求:為用戶賬號生成賬號ID。最開始用的是UUID(長字符串ID),但是字符串賬號相對于數(shù)字賬號,存儲和傳輸性能都稍遜,也不利于記憶和傳播。
因此,生成一套業(yè)務(wù)內(nèi)的數(shù)字賬號,并且盡量簡短就是當(dāng)務(wù)之急。
初步版本
我們最開始考慮的是雪花算法方案,使用的是經(jīng)典的 twitter開源的算法 snowflake。這個算法非常強大,生成的是 64bit 的數(shù)字id,天然支持分布式。
雪花算法看起來無懈可擊,但是唯一的問題就是生成的64位 ID 太長了。賬號ID希望能控制的盡量短,個人理解有以下原因:
- 賬號id一般顯示在個人設(shè)置里,會暴露給用戶,需要便于輸入 + 記憶,這樣客服查詢起來更方便;
- 賬號id短并且有序能提高賬號庫的寫入性能;
于是著手改進。
改進版本
一個比較可行的方案是利用數(shù)據(jù)庫的自增 ID 特性。
為了便于理解,我們先來看一下業(yè)務(wù)里的賬號登錄流程:
- 客戶端上傳第三方openid及token來登錄,登錄服拿到openid后需要查詢是否已經(jīng)注冊賬號
- 如果能查到賬號ID,表明已經(jīng)注冊,再根據(jù)查到的數(shù)字賬號來做后續(xù)登錄邏輯
- 如果查不到,則需要新注冊一個賬號到賬號表
- 新建賬號首先需要生成一個數(shù)字的賬號ID,在目前的機制中,通過一張專門的ID生成表來做的。
OK,先來看我們?nèi)绾卧趍ysql中存儲賬號相關(guān)信息的:
賬號表,accid就是我們說的數(shù)字賬號。考慮到賬號數(shù)量級可能到千萬甚至上億,單表的性能肯定不理想,因此我們分了10張表。其表結(jié)構(gòu)為:
CREATETABLE`tbl_global_user_map_00` (
`account`varchar(32) NOTNULL,
`accid`bigint(20) NOTNULL,
`created_at` datetime DEFAULTNULL,
PRIMARY KEY (`account`) USING BTREE
) ENGINE=InnoDBDEFAULTCHARSET=utf8賬號ID生成表,其表結(jié)構(gòu)為:
CREATETABLE`tbl_accid` (
`id`bigint(20) NOTNULL AUTO_INCREMENT,
`stub`char(1) NOTNULLDEFAULT'',
PRIMARY KEY (`id`) USING BTREE,
UNIQUEKEY`UQE_tbl_accid_stub` (`stub`) USING BTREE
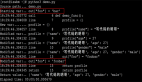
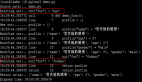
) ENGINE=InnoDBDEFAULTCHARSET=utf8數(shù)據(jù)為:
 圖片
圖片
整個表只有一行數(shù)據(jù),id列為自增列,它的值就是最新生成的賬號ID值。這個ID生成的原理是:
- 設(shè)置id列為自增,這樣每插入一列id值就會自動遞增
- 如果沒有其他限制,這張表的數(shù)據(jù)就會隨著insert的次數(shù)越來越多,假如賬號有幾千萬,這張表就有幾千萬行數(shù)據(jù)
- 為此,我們增加了一列 stub,設(shè)置其為 unique key,并且每次insert其值都是一樣的(例如設(shè)置為 'a'),這樣就保證整個表只有一行數(shù)據(jù),而id會隨著每次insert自動遞增。
- 如果直接用 insert into 語句來做插入,肯定每次都返回錯誤(除了第1次),因為 stub 為 ‘a(chǎn)’ 的記錄已經(jīng)存在了,每次插入都會失敗。
- 我們改用 MySQL 擴展的 SQL 語句 replace into 來實現(xiàn)。replace 必須要配合唯一索引來使用。
于是 SQL 語句就是:
REPLACEINTO tbl_accid(`stub`) VALUES('a');它的效果如下:
- 如果 stub 為 'a' 的記錄不存在,則插入,類似 insert 操作
- 如果 stub 為 'a' 的記錄已經(jīng)存在,則先 delete 該條記錄,再 insert 新記錄。由于刪除已有的記錄時,表的自增值不會變化,再新增記錄時 id 會在老的自增值基礎(chǔ)上繼續(xù)遞增
有同學(xué)可能要問了,為什么要搞一個單獨的ID生成表來生成自增id?將自增字段直接放到賬號表中不行么?
關(guān)鍵的問題在于業(yè)務(wù)要分表。假如賬號表分了10張,要合并自增id列的話,需要劃分好每張表的生成范圍。
例如我們設(shè)計每張表可以生成 100w 個id,那 10 張表的起始id 分別是 1, 1000001,2000001, ...
跨度非常大,和我們當(dāng)初的設(shè)計:簡短并盡量連續(xù)的要求違背。
因此,專門的賬號ID生成表是必要的。
問題暴露
上述方案完成之后,我就去吃火鍋唱歌去了。
然后,就出現(xiàn)了一個比較棘手的問題。某天晚上QA同事反饋壓力測試有報錯,登錄服會間歇性返回db錯誤,如下:
ERROR : Deadlock found when trying to get lock; try restarting transaction登錄服收到該返回后打印了錯誤日志,提示客戶端服務(wù)器發(fā)生錯誤。很明顯,這個方案有死鎖問題。
google了一下 replace 在并發(fā)情況下的死鎖問題,大致和 replace 被分解成 delete + insert 有關(guān),而 innodb又是行鎖機制。詳細(xì)的原因非常復(fù)雜,有關(guān)資料為
- https://yq.aliyun.com/articles/41190
- https://techlog.cn/article/list/10183451#l
- http://blog.itpub.net/7728585/viewspace-2141409
很多博客也給出了建議:
通過幾個死鎖案例,我們強烈建議在生產(chǎn)環(huán)境中盡量避免使用REPLACE INTO和INSERT INTO ON DUPLICATE UPDATE語句,改用普通INSERT操作,并對INSER操作部分代碼加入異常加查,當(dāng)INSERT失敗時改為UPDATE操作。
為了再驗證一次死鎖的并非語言或者API的bug,我用了 mysql 自帶的壓測工具 mysqlslap 做了個簡單測試:
mysqlslap -uroot -p --create-schema="db_global_200" --cnotallow=2 --iteratinotallow=5 --number-of-queries=500 --query="replace_innodb.sql"
mysqlslap: Cannot run query REPLACE INTO tbl_yptest_innodb(`stub`) VALUES('a'); ERROR : Deadlock found when trying to get lock; try restarting transaction結(jié)果顯示并發(fā)數(shù)為 2 時就出現(xiàn)了死鎖問題。然后我又嘗試將表引擎改為 myisam,再次壓測,雖然沒有出現(xiàn)死鎖問題,但是MYISAM引擎更新數(shù)據(jù)的效率比較低。因此我們不得不放棄了mysql自增ID的方案,再想其他方案。
其他方案1
繼續(xù)嘗試其他方案。其實,我們最新的ID生成方案參考了美團技術(shù)團隊的一篇文章,有興趣的可以查閱:https://tech.meituan.com/2017/04/21/mt-leaf.html
文中提到了一種Flickr團隊的改進方案:
 圖片
圖片
即:使用 N 個mysqlserver,來提高可用性,降低每個 mysqlserver的壓力和并發(fā)數(shù)。如果 replace into 不支持并發(fā),那就部署盡可能多的 mysqlserver,每次 replace into 時串行。
然而這種方式部署限制和消耗都太大,而且我們的登錄服是多開的,即使在單登錄服內(nèi)控制串行,多個進程也不好控制,因此這個初始的方案只能被pass。
回到開始的思路,能不能將自增id合并到 賬號表_xx 中,從而放棄 replace 呢?
我們可以將每個 tbl_global_user_map 分表類比成上圖中的 mysql-01, mysql-02, ...
然后自增時,采取 間隔步長N 的方式(默認(rèn)的自增步長是1,每次自增加1)
舉例:
- tbl_global_user_map_00 表,起始id 20000,每次加10,其生成的 id 每次是 20000, 20010, 20020, 20030...
- tbl_global_user_map_01 表,起始id 20001,也是每次加10,其生成的 id 每次是 20001, 20011, 20021, 20031...
這個id看起來間隔很小,看起來非常理想。
需要做的事情就是設(shè)置 auto_increment_increment 和 auto_increment_offset 兩個mysql中的變量。
然后很可惜,這兩個變量屬于 全局 或者 session(連接會話) 級別,沒有 table 級別的設(shè)置。
如果我們設(shè)置了這兩個變量,很容易影響其他表,產(chǎn)生其他錯誤。
其他方案2
再想其他方案。
仔細(xì)整理一下我們的需求,就會發(fā)現(xiàn)我們的賬號表一般只有新增,沒有刪除和修改。能不能利用讀寫分離的思想,在插入新映射關(guān)系(同時生成自增賬號ID)時,只有一張表可寫,自增id可以每次只加1;
而查詢時,屬于讀,讀的數(shù)據(jù)可以分布在10張表中。我們要做的就是定期將可寫表中已有的一些數(shù)據(jù)遷移到只讀的這10張表中(根據(jù)賬號ID做shard),控制可寫表的數(shù)量級不能太大。
賬號ID在寫表中自增,相當(dāng)于自動分配賬號ID。
 圖片
圖片
這個機制有點類似于我們的日志滾動,當(dāng)前正在寫的日志文件不停被寫入(插入日志),當(dāng)超過一定大小或者日期切換時會滾動成只讀的文件。
這個方案理論上可行,但是有運維復(fù)雜性:需要配合運維來做數(shù)據(jù)遷移,維護成本比較高,因此組內(nèi)討論后我們決定pass掉。
其他方案3(最終方案)
我之前所在的成熟項目也用過上述【其他方案1】中類似美團的方案,即預(yù)申請一批ID的方式。
對比來看,我們之前申請ID都是一次自增1,而這種預(yù)申請一批的方式,是一次申請N個ID,自增N,可以減少請求量和并發(fā)。當(dāng)請求量明顯下降后,之前方案里擔(dān)憂的問題:ID生成表插入行數(shù)過多也就不存在了。
唯一的問題是:預(yù)申請的ID可能會被浪費。如果申請了一段區(qū)間的id,但是沒有用完,服務(wù)器停服再啟動后會再申請一段新的,原來未使用的ID就被浪費了。
因此我們著手優(yōu)化這種算法,目的很明顯:
減少浪費的ID,去除空洞號段,并自動兼容登錄服擴容與容災(zāi)的情況。
如果這個目的能達成,那就完美契合了我們當(dāng)初的需求。
短ID方案細(xì)節(jié)
設(shè)計發(fā)號表 tbl_account_freeid
 圖片
圖片
每個登陸服要申請一批賬號ID時,就來表中插入一行,規(guī)定每次申請1000個,由于segment自增,相當(dāng)于申請了 [(segment - 1) * 1000, segment * 1000) 這段區(qū)間,申請時候默認(rèn) left 是 0。
登錄服正常停服維護時將剩余未用完的數(shù)量寫入 left,防止浪費,下次啟動時候還可以再利用。
以下分析各種case:
a) 初始 tbl_account_freeid 沒有數(shù)據(jù),假如 loginsvr 開3個實例,實例編號分別是1,2,3。
服務(wù)器啟動時候需要做一次查找,要找對應(yīng) 實例編號的segment。如果找到了,且 left 不為 0,則說明該號段還可以用;如果找不到,或者left為0,則需要新申請(新插入一行記錄)。
于是第一次啟服后數(shù)據(jù)為:
 圖片
圖片
b) 如果loginsvr發(fā)現(xiàn)內(nèi)存中號段用完了,就不用再查找,直接申請,往數(shù)據(jù)庫插入一行數(shù)據(jù),假定實例編號 1 和 3 的 號段用完了,新申請。
然后各個登錄服正常停服,left 回寫。可能的數(shù)據(jù)情況如下:
 圖片
圖片
c) 再次起服時,查找到各個編號的實例都有號段可用。無需新插入數(shù)據(jù),但是對應(yīng)的 left 要改為0(相當(dāng)于申請了 left 個)。
 圖片
圖片
d) 如果此時 loginsvr 擴容,新增編號 4 - 10 的 svr,和初始情況類似,需要先查找,沒有則申請。此時數(shù)據(jù)可能為:
 圖片
圖片
這種方式的特點就是,登錄服服務(wù)過程中,對應(yīng)數(shù)據(jù)庫里的 left 為 0,如果停了,數(shù)據(jù)庫里 left 為號段內(nèi)剩余的可用數(shù)量。
如果登錄服宕機,則沒有回寫 left 的過程,則對應(yīng)號段內(nèi)沒有用完的(最多1000)會浪費。