Node.js的performance鉤子和測(cè)量 API

當(dāng)你完成了編寫和部署了項(xiàng)目,下一步就是去改進(jìn)、消除瓶頸、提高執(zhí)行速度和優(yōu)化性能,得先了解項(xiàng)目現(xiàn)有的性能瓶頸和邏輯慢的地方。但是,沒有人喜歡猜測(cè)哪些部分可能更慢的試錯(cuò)過程。
Node.js 提供了各種內(nèi)置性能鉤子函數(shù)來衡量執(zhí)行速度,找出代碼的哪些部分值得優(yōu)化,并收集應(yīng)用程序代碼執(zhí)行的精細(xì)視圖。
在本文中,您將學(xué)習(xí)如何使用 Node.js 性能鉤子函數(shù)和測(cè)量 API 來識(shí)別瓶頸并增強(qiáng)應(yīng)用程序的性能,從而加快響應(yīng)時(shí)間并提高資源效率。
Node.js的Performance API 概述
首先要了解為什么以及何時(shí)應(yīng)該使用 Node 提供的 Performance API以及它提供的各種選項(xiàng),考慮這樣一種情況:您想要測(cè)量特定代碼塊的執(zhí)行時(shí)間。
為此,您可能已經(jīng)使用了 Date 對(duì)象,如下所示:
let start = Date.now();
for (let i = 0; i < 10000; i++) { } // stand-in for some complex calculation
let end = Date.now();
console.log(end - start);但是,如果您運(yùn)行上述操作并觀察,您會(huì)注意到這還不夠精確。
例如,像上面這樣的空循環(huán)會(huì)將 0 或 1 記錄為差值,并且不會(huì)給我們足夠的粒度。Date 類只能提供毫秒級(jí)的粒度,如果代碼以 100 納秒的順序運(yùn)行,這不會(huì)給我們正確的測(cè)量結(jié)果。
為此,我們可以改用 Performance API 來獲得更好的測(cè)量結(jié)果:
const {performance} = require('node:perf_hooks');
let start = performance.now()
for (let i = 0; i < 10000; i++) {}
let end = performance.now()
console.log(end - start);這樣,我們就可以得到一個(gè)更精細(xì)的值,在我的系統(tǒng)上,該值在 0.18 到 0.21 毫秒的范圍內(nèi),精度高達(dá) 15-16 位小數(shù)。這是我們可以使用 Node Performance API 更好地測(cè)量執(zhí)行時(shí)間的一種簡(jiǎn)單方法。
該 API 還提供了一種在程序運(yùn)行期間精確標(biāo)記時(shí)間點(diǎn)的方法。我們可以使用performance.mark方法獲取高精度事件的時(shí)間戳,例如循環(huán)迭代的開始時(shí)間。
運(yùn)行下面代碼:
let start_mark = performance.mark("loop_start",
{detail:"starting loop of 1000 iterations"}
);
for (let i = 0; i < 10000; i++) {}
let end_mark = performance.mark("loop_end",
{detail:"ending loop of 1000 iterations"}
);
console.log( start_mark, end_mark );輸出:
PerformanceMark {
name: 'loop_start',
entryType: 'mark',
startTime: 27.891528000007384,
duration: 0,
detail: 'starting loop of 1000 iterations'
}
PerformanceMark {
name: 'loop_end',
entryType: 'mark',
startTime: 28.996093000052497,
duration: 0,
detail: 'ending loop of 1000 iterations'
}mark 函數(shù)將標(biāo)記的名稱作為第一個(gè)參數(shù)。第二個(gè)參數(shù)對(duì)象中的detail允許提供有關(guān)該標(biāo)記的額外詳細(xì)信息,例如運(yùn)行的迭代次數(shù)、數(shù)據(jù)庫查詢參數(shù)等。
然后,可以使用 mark 函數(shù)返回的對(duì)象通過 Prometheus exporter sdk 將計(jì)時(shí)數(shù)據(jù)導(dǎo)出到 Prometheus 之類的東西。這允許我們?cè)趹?yīng)用程序外部查詢和可視化耗時(shí)信息。由于 mark 是一個(gè)瞬時(shí)時(shí)間點(diǎn),因此返回對(duì)象中的 duration 字段始終為零。
而不是手動(dòng)調(diào)用 performance.now 并計(jì)算兩個(gè)事件之間的差異,我們可以使用 marks 和 measure 函數(shù)執(zhí)行相同的操作。我們可以使用上面標(biāo)記的名稱來測(cè)量?jī)蓚€(gè)標(biāo)記之間的持續(xù)時(shí)間:
performance.mark("loop_start",
{detail:"starting loop of 1000 iterations"}
);
for (let i = 0; i < 10000; i++) {}
performance.mark("loop_end",
{detail:"ending loop of 1000 iterations"}
);
console.log(performance.measure("loop_time","loop_start","loop_end"));measure 的第一個(gè)參數(shù)是我們要為測(cè)量指定的名稱。然后,接下來的兩個(gè)參數(shù)分別指定要開始和結(jié)束測(cè)量的標(biāo)記的名稱。
這兩個(gè)參數(shù)都是可選的 — 如果兩者都沒有給出,則為 performance.measure 將返回應(yīng)用程序啟動(dòng)和測(cè)度調(diào)用之間經(jīng)過的時(shí)間。如果我們只提供第一個(gè)參數(shù),該函數(shù)將返回性能之間經(jīng)過的performance.mark替換為該名稱和 measure 調(diào)用。
如果兩者都提供,該函數(shù)將返回它們之間的高精度時(shí)間差。對(duì)于上面的示例,我們將得到如下輸出:
PerformanceMeasure {
name: 'loop_time',
entryType: 'measure',
startTime: 27.991639000130817,
duration: 1.019368999870494
}這可以再次與 Prometheus exporter 一起使用,以便導(dǎo)出自定義測(cè)量指標(biāo)。如果您的設(shè)置執(zhí)行藍(lán)綠或 Canary 部署,則可以比較舊版本和新版本的性能,以查看您的優(yōu)化是否按預(yù)期工作。
最后,需要注意的一點(diǎn)是,Performance API 在內(nèi)部使用固定大小的緩沖區(qū)來存儲(chǔ)標(biāo)記和度量,因此我們需要在使用完它們后對(duì)其進(jìn)行清理。這可以使用以下方法完成:
performance.clearMarks("mark_name");或者:
performance.clearMeasures("measure_name");這些函數(shù)將從相應(yīng)的緩沖區(qū)中刪除具有給定名稱的標(biāo)記/度量。如果在不提供任何參數(shù)的情況下調(diào)用這些函數(shù),它們將清除緩沖區(qū)中存在的所有標(biāo)記/度量,因此在沒有任何參數(shù)的情況下調(diào)用這些函數(shù)時(shí)要小心。
使用 Performance鉤子優(yōu)化您的應(yīng)用
現(xiàn)在讓我們看看如何使用這個(gè) API 來優(yōu)化我們的應(yīng)用程序。在我們的示例中,我們將考慮從數(shù)據(jù)庫中獲取一些數(shù)據(jù),然后手動(dòng)排序并將其返回給用戶的情況。
我們想了解每個(gè)操作需要多少時(shí)間,以及首先優(yōu)化的最佳位置是什么。為此,我們將首先測(cè)量發(fā)生的各種事件:
async function main(){
const querySize = 10; // ideally this will come from user's request
performance.mark("db_query_start",{detail:`query size ${querySize}`});
const data = fetchData(querySize);
performance.mark("db_query_end",{detail:`query size ${querySize}`});
performance.mark("sort_start",{detail:`sort size ${querySize}`});
const sorted = sortData(data);
performance.mark("sort_end",{detail:`sort size ${querySize}`});
console.log(performance.measure("db_time","db_query_start","db_query_end"));
console.log(performance.measure("sort_time","sort_start","sort_end"));
// clear the marks...
}我們首先聲明查詢大小,在實(shí)際應(yīng)用程序中,它可能來自用戶的請(qǐng)求。
然后我們使用performance.mark 函數(shù)來標(biāo)記數(shù)據(jù)庫獲取和排序操作的開始和結(jié)束。最后,我們使用 performance 輸出這些事件之間的持續(xù)時(shí)間。量功能。我們得到這樣的輸出:
PerformanceMeasure {
name: 'db_time',
entryType: 'measure',
startTime: 27.811830999795347,
duration: 1.482880000025034
}
PerformanceMeasure {
name: 'sort_time',
entryType: 'measure',
startTime: 29.31366699980572,
duration: 0.09800400026142597
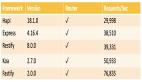
}要查看這兩個(gè)操作在查詢大小增加時(shí)的表現(xiàn),我們將更改查詢大小值并記下度量值。在我的系統(tǒng)上,我得到以下內(nèi)容:
正如我們?cè)谶@里看到的,隨著查詢大小的增加,排序時(shí)間會(huì)迅速增加,首先優(yōu)化它可能更有益。通過使用一些不同的排序算法,我們得到以下內(nèi)容:
雖然對(duì)于非常小的查詢大小,排序時(shí)間略短,但與原始測(cè)量值相比,時(shí)間增長緩慢。因此,如果我們期望經(jīng)常處理大型查詢,那么在此處更改排序算法將是有益的。
同樣,我們可以測(cè)量在查詢字段上創(chuàng)建索引之前和之后數(shù)據(jù)庫獲取時(shí)間的差異。然后我們可以決定索引創(chuàng)建是否有用,或者哪些字段在用于索引時(shí)提供更多好處。
使用后臺(tái)工作程序卸載任務(wù)
在創(chuàng)建基于 UI 的應(yīng)用程序時(shí),我們需要 UI 能夠響應(yīng),即使正在進(jìn)行一些繁重的處理任務(wù)也是如此。如果在處理大數(shù)據(jù)時(shí) UI 凍結(jié),則處理起來將是一種糟糕的用戶體驗(yàn)。在網(wǎng)站上,這可以使用 Web Worker 來完成。
對(duì)于直接使用 Node 運(yùn)行的應(yīng)用程序,我們可以使用 Node 的 worker_threads 模塊將計(jì)算密集型任務(wù)卸載到后臺(tái)線程。
請(qǐng)注意,僅當(dāng)任務(wù)是 CPU 密集型任務(wù)(例如排序或解析數(shù)據(jù))時(shí),這才有用。如果任務(wù)依賴于 I/O,例如讀取文件或獲取網(wǎng)絡(luò)資源,則使用 Node 的 async-await 比使用 worker 更有效。
我們可以按如下方式創(chuàng)建和使用 worker:
const { Worker, isMainThread, parentPort, workerData, } =
require("node:worker_threads");
async function main() {
const data = await fetchData(10);
let sorted = await new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: data,
});
worker.on("message", resolve);
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0)
reject(new Error(`Worker stopped with exit code ${code}`));
});
});
}
function worker() {
const data = workerData;
sortData(data);
parentPort.postMessage(data);
}
if (isMainThread) {
// we are in the main thread of our application
main().then(() => {
console.log("done");
});
} else {
// we are in the background thread spawned by the main thread
worker();
}我們首先從 worker_threads 模塊導(dǎo)入所需的函數(shù)和變量聲明。然后我們定義兩個(gè)函數(shù) —main(將在主線程中運(yùn)行)和 worker (將在 worker 線程中運(yùn)行)。
然后,我們檢查腳本是作為主線程還是作為 worker 線程執(zhí)行,并相應(yīng)地調(diào)用 main/worker 函數(shù)。為了簡(jiǎn)單起見,我們?cè)谝粋€(gè)文件中定義了所有這些函數(shù),但我們也可以在它們自己的文件中分離出 main 和 worker 函數(shù)。
在 main 函數(shù)中,我們像以前一樣獲取數(shù)據(jù)。然后我們創(chuàng)建一個(gè) Promise,并在其中創(chuàng)建一個(gè)新的 worker。Worker 構(gòu)造函數(shù)需要一個(gè)文件路徑,該路徑將作為Worker線程運(yùn)行。
這里我們使用 __filename builtin 給它相同的文件。在第二個(gè)參數(shù)中,我們將要排序的數(shù)據(jù)作為 workerData 傳遞。此 workerData 將由 Node 運(yùn)行時(shí)提供給 worker 線程。
最后,我們監(jiān)聽來自 worker 的事件 — 收到消息時(shí),我們解決 promise,如果出現(xiàn)錯(cuò)誤或非零退出代碼,我們拒絕 promise。
在 worker 線程中,我們從變量 workerData 中獲取從主線程傳遞的數(shù)據(jù),該變量是從 worker_threads 模塊導(dǎo)入的。在這里,我們對(duì)它進(jìn)行排序,并將一條消息發(fā)布到包含排序數(shù)據(jù)的主線程。
在主線程中,我們可以將其保存在隊(duì)列中或定期檢查它,而不是立即等待 promise。這樣,當(dāng)worker線程進(jìn)行排序計(jì)算時(shí),我們可以保持主線程的響應(yīng)性。我們還可以從 worker 線程發(fā)送中間消息,指示排序進(jìn)度。
優(yōu)化 Node 應(yīng)用程序的常見提示
雖然每個(gè)應(yīng)用程序都有自己的性能優(yōu)化方法,但Node.js應(yīng)用程序有一些常見的起點(diǎn)。
優(yōu)化前觀察
在開始優(yōu)化應(yīng)用程序之前,您必須檢測(cè)和測(cè)量應(yīng)用程序的性能,以便您可以準(zhǔn)確了解哪些函數(shù)或 API/DB 調(diào)用需要優(yōu)化。
嘗試進(jìn)行盲目?jī)?yōu)化可能會(huì)降低性能,這就是為什么使用 Node 提供的性能鉤子和 API 進(jìn)行測(cè)量是一個(gè)很好的起點(diǎn)。
有一種簡(jiǎn)單的方法來重復(fù)測(cè)量
要確定您的優(yōu)化是否有效,您應(yīng)該有一種方便的方法來衡量之前和之后的性能。
這可以通過擁有兩個(gè)構(gòu)建來完成 —--- 一個(gè)有更改,一個(gè)沒有更改,有一個(gè)運(yùn)行測(cè)試和測(cè)量的腳本,以及可以為您提供比較的東西。為更改提供明確的前后性能值可以幫助您確定這些更改是否值得。
嘗試為數(shù)據(jù)庫編制索引并緩存請(qǐng)求/響應(yīng)
如果您的應(yīng)用程序使用數(shù)據(jù)庫并頻繁查詢,則應(yīng)考慮在查詢的參數(shù)上創(chuàng)建索引,以提高檢索性能。
這將以可能增加存儲(chǔ)大小和可能增加插入/更新查詢時(shí)間為代價(jià),因此您應(yīng)該仔細(xì)衡量使用案例中的前后,并確定權(quán)衡是否良好。
提高性能的另一種方法是使用一些緩存方案,以便快速響應(yīng)數(shù)據(jù)庫或 API 查詢。如果您可以使用查詢參數(shù)緩存 API 響應(yīng),然后使用此緩存響應(yīng)以后的請(qǐng)求,則可以有效地使用它。
請(qǐng)注意,緩存是一把雙刃劍。您需要仔細(xì)評(píng)估保留緩存條目的時(shí)間、逐出條目的依據(jù)以及何時(shí)使緩存失效。錯(cuò)誤地執(zhí)行此操作不僅會(huì)降低您的性能,而且還有可能在用戶之間發(fā)送不正確的數(shù)據(jù)或泄露的數(shù)據(jù)。
減少依賴性
如果您曾經(jīng)查看 node_modules 或檢查過node_modules 所占用的磁盤大小,您就會(huì)知道 Node 項(xiàng)目中的依賴關(guān)系有多嚴(yán)重。
添加新的依賴項(xiàng)時(shí)需要小心,因?yàn)樗鼈兛赡軙?huì)添加更多的傳遞依賴項(xiàng),而解析所有這些依賴項(xiàng)可能會(huì)影響應(yīng)用程序的啟動(dòng)性能。您可以嘗試通過以下方法緩解此問題:
- 刪除未使用的軟件包 — 有時(shí)軟件包中有多個(gè)軟件包。JSON 格式這些 ID 不再在應(yīng)用程序中使用,可以刪除。這對(duì)于縮小依賴項(xiàng)的數(shù)量和軟件包的構(gòu)建大小非常有用
- 使用打包器對(duì)
tree-shaking并從最終構(gòu)建中刪除未使用的模塊 — 在捆綁和打包應(yīng)用程序時(shí),您可以使用捆綁器提供的功能從依賴項(xiàng)中刪除未使用的模塊。您只保留代碼使用的依賴項(xiàng)部分,而不將其余部分包含在最終構(gòu)建中 - 從依賴項(xiàng)中提供所需的特定代碼 — 當(dāng)您只需要代碼的一小部分時(shí),而不是將整個(gè)包添加為依賴項(xiàng),而是提供代碼的特定部分。執(zhí)行此操作時(shí),請(qǐng)務(wù)必檢查并遵守原始代碼的許可證
- 延遲加載依賴項(xiàng) — 您可以延遲加載依賴項(xiàng)以提高啟動(dòng)性能,并在不需要該依賴項(xiàng)的情況下減少內(nèi)存使用量
結(jié)論
Node 提供的Performance API 不僅可以幫助確定哪些部分速度較慢,還可以幫助確定它們需要多少時(shí)間。您可以通過將這些數(shù)據(jù)作為跟蹤或指標(biāo)導(dǎo)出到Jaeger或 Prometheus 之類的內(nèi)容來進(jìn)一步探索這些數(shù)據(jù)。
請(qǐng)記住 — 擁有大量數(shù)據(jù)只會(huì)使其更難探索,因此一個(gè)好的策略是首先只測(cè)量粗略事件的時(shí)間,例如函數(shù)調(diào)用甚至請(qǐng)求的端到端處理,然后為花費(fèi)最多時(shí)間的函數(shù)添加越來越多的細(xì)粒度測(cè)量。
原文地址:https://blog.logrocket.com/node-js-performance-hooks-measurement-apis-optimize-applications/
原文作者:Yashodhan Joshi
本文譯者:一川