MySQL性能飛躍:揭秘高效數(shù)據(jù)庫優(yōu)化的黃金法則

MySQL數(shù)據(jù)庫性能優(yōu)化是一個涉及多個層面的復(fù)雜過程,需要根據(jù)具體的應(yīng)用場景、數(shù)據(jù)結(jié)構(gòu)和查詢模式等因素來定制優(yōu)化方案。以下是針對不同場景下MySQL數(shù)據(jù)庫性能優(yōu)化的詳細(xì)指南。
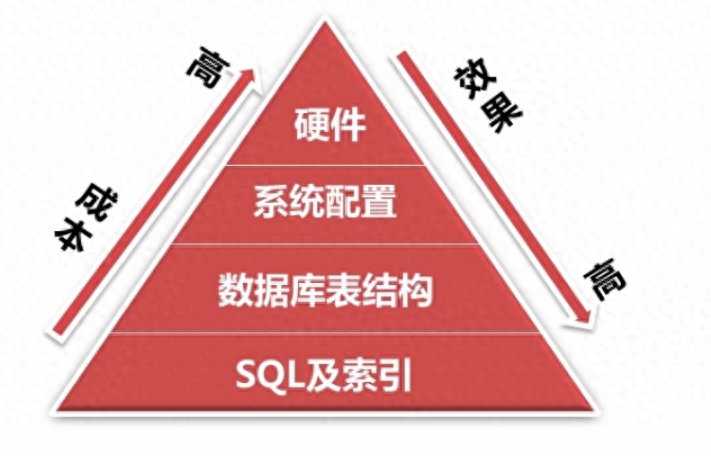
建庫建表階段的優(yōu)化
1.存儲引擎的合理選擇
在創(chuàng)建數(shù)據(jù)庫時,選擇合適的存儲引擎是至關(guān)重要的。InnoDB因其支持事務(wù)處理、行級鎖定和外鍵約束而被廣泛推薦。它提供了高性能和數(shù)據(jù)完整性的保證,適合需要處理大量短期事務(wù)的應(yīng)用。MyISAM提供高速緩存索引,對讀取操作優(yōu)化良好;支持全文搜索,適合需要進行文本搜索的應(yīng)用
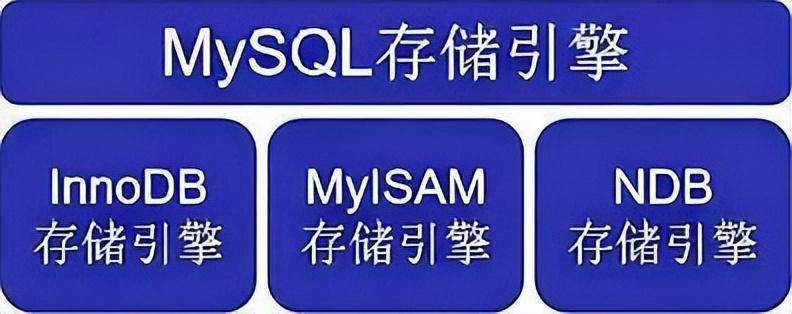
如果應(yīng)用需要支持事務(wù)、高并發(fā)寫入和復(fù)雜操作,InnoDB可能是更好的選擇。如果應(yīng)用需要進行大量讀取操作和文本搜索,同時對事務(wù)處理要求不高,MyISAM可能更合適。
2.表結(jié)構(gòu)設(shè)計的優(yōu)化
表結(jié)構(gòu)設(shè)計應(yīng)遵循簡潔高效的原則。在設(shè)計表結(jié)構(gòu)時,應(yīng)避免不必要的字段和冗余數(shù)據(jù),這有助于減少存儲空間的占用和提高數(shù)據(jù)檢索效率。同時,合理的字段類型選擇也能避免數(shù)據(jù)類型轉(zhuǎn)換帶來的性能損耗。
- 選擇合適的字段類型:為每個字段選擇最合適的數(shù)據(jù)類型是優(yōu)化的第一步。例如,對于存儲整數(shù)的字段,應(yīng)使用INT類型;對于存儲文本的字段,應(yīng)根據(jù)文本長度選擇VARCHAR或TEXT等。選擇合適的字段類型可以減少存儲空間的占用,提高查詢效率。
- 避免使用NULL值:在設(shè)計表結(jié)構(gòu)時,應(yīng)盡量避免使用NULL值。NULL值會占用額外的索引空間,并且在查詢時需要特殊處理。如果某個字段的NULL值是有意義的,可以考慮使用一個默認(rèn)值(如0)來代替NULL。
- 控制字段長度:對于變長類型的字段(如VARCHAR),應(yīng)合理設(shè)置字段長度。過長的字段會占用更多的存儲空間,而過短的字段可能無法滿足實際需求。同時,字段長度的設(shè)置也應(yīng)考慮到索引的建立,因為過長的字段可能會影響索引的性能。
- 使用合適的索引:索引可以顯著提高查詢效率,但過多的索引會影響寫操作的性能。因此,在設(shè)計表結(jié)構(gòu)時,應(yīng)根據(jù)查詢需求合理設(shè)置索引。對于經(jīng)常作為查詢條件的字段,應(yīng)建立索引;而對于數(shù)據(jù)變化頻繁的字段,應(yīng)謹(jǐn)慎考慮是否需要索引。
- 避免使用復(fù)雜的數(shù)據(jù)類型:復(fù)雜的數(shù)據(jù)類型(如JSON、BLOB等)雖然提供了更多的靈活性,但同時也會增加數(shù)據(jù)庫的維護成本。在可能的情況下,應(yīng)盡量使用簡單的數(shù)據(jù)類型,并在應(yīng)用層面處理復(fù)雜的數(shù)據(jù)結(jié)構(gòu)。
- 合理設(shè)計主鍵:主鍵是表中每一行記錄的唯一標(biāo)識,其性能直接影響到數(shù)據(jù)庫的整體性能。應(yīng)選擇具有唯一性和穩(wěn)定性的字段作為主鍵,避免使用過長的字段作為主鍵,以減少索引的存儲空間和提高查詢效率。
- 使用分區(qū)表:對于大型表,可以考慮使用分區(qū)表來提高查詢和管理的效率。分區(qū)可以根據(jù)特定的規(guī)則(如日期、地區(qū)等)將數(shù)據(jù)分散存儲在不同的分區(qū)中,從而減少查詢時需要掃描的數(shù)據(jù)量。
- 規(guī)范化設(shè)計:規(guī)范化設(shè)計可以減少數(shù)據(jù)冗余,提高數(shù)據(jù)的一致性。在設(shè)計表結(jié)構(gòu)時,應(yīng)遵循數(shù)據(jù)庫規(guī)范化理論,合理劃分表和字段,確保數(shù)據(jù)的邏輯獨立性和完整性。
- 考慮數(shù)據(jù)的擴展性:在設(shè)計表結(jié)構(gòu)時,應(yīng)考慮到未來可能的數(shù)據(jù)擴展需求。例如,可以預(yù)留一些字段用于存儲未來可能需要的數(shù)據(jù),或者設(shè)計可擴展的數(shù)據(jù)結(jié)構(gòu),以便在未來可以輕松地添加新的數(shù)據(jù)類型或字段。
3.恰當(dāng)使用索引
在MySQL數(shù)據(jù)庫優(yōu)化中,索引的恰當(dāng)應(yīng)用是提升查詢性能的關(guān)鍵因素之一。索引可以顯著加快數(shù)據(jù)檢索的速度,但并不是所有情況下都需要建立索引,也不是索引越多越好。
- 為常用的查詢條件創(chuàng)建索引:對于那些經(jīng)常作為WHERE子句中條件的列,建立索引可以大大提高查詢效率。例如,如果你經(jīng)常查詢某個表中特定年齡段的用戶,那么在年齡字段上建立索引將非常有用。
- 避免對低選擇性的列創(chuàng)建索引:低選擇性意味著列中的值重復(fù)程度高。對于這樣的列,索引并不能提供太大的幫助,因為索引需要在多個重復(fù)值中查找。例如,一個存儲性別信息的字段(男或女)就不需要建立索引。
- 考慮使用復(fù)合索引:復(fù)合索引是指在多個列上同時創(chuàng)建的索引。當(dāng)查詢條件經(jīng)常涉及多個列時,復(fù)合索引可以提供更好的性能。但是,復(fù)合索引也會占用更多的存儲空間,并且在更新表時可能會增加維護成本。
- 索引并不是越多越好:雖然索引可以提高查詢速度,但是過多的索引會增加數(shù)據(jù)庫的維護成本,尤其是在數(shù)據(jù)更新頻繁的情況下。因此,在創(chuàng)建索引時需要進行權(quán)衡,考慮查詢性能和更新性能之間的平衡。
- 定期評估索引的性能:通過工具如EXPLAIN語句,可以分析查詢的執(zhí)行計劃,查看是否有效地使用了索引。定期評估索引的性能,并根據(jù)實際情況進行調(diào)整,可以幫助維護數(shù)據(jù)庫的查詢效率。
- 考慮部分索引:在某些情況下,可能只需要對表中的一部分?jǐn)?shù)據(jù)建立索引。例如,如果一個表中大部分?jǐn)?shù)據(jù)都是未處理的狀態(tài),而你只關(guān)心已處理的數(shù)據(jù),那么可以為處理狀態(tài)的列創(chuàng)建一個部分索引。
- 避免對經(jīng)常變化的列創(chuàng)建索引:對于經(jīng)常發(fā)生變化的列,索引的維護成本會很高。因為每次數(shù)據(jù)更新都可能需要更新索引,這會增加寫操作的開銷。在這種情況下,可以考慮其他優(yōu)化策略,如延遲更新索引或使用其他數(shù)據(jù)結(jié)構(gòu)。
SQL語法優(yōu)化
1.查詢語句的精確化
編寫查詢語句時,應(yīng)盡量避免使用SELECT *,而是明確指定所需的列名。這不僅減少了數(shù)據(jù)傳輸量,還能減少不必要的索引掃描。另外,使用JOIN代替子查詢可以提高查詢效率,尤其是在處理復(fù)雜的數(shù)據(jù)關(guān)聯(lián)時。
在MySQL數(shù)據(jù)庫優(yōu)化中,查詢語句的精確化是一個重要的環(huán)節(jié),它可以顯著提高數(shù)據(jù)庫操作的效率和性能。精確化的查詢語句能夠減少不必要的數(shù)據(jù)掃描,加快檢索速度,并降低系統(tǒng)資源的消耗。以下是一些關(guān)于查詢語句精確化的關(guān)鍵點和建議:
- 使用具體的字段:在SELECT語句中,盡量指定需要查詢的具體字段,而不是使用SELECT *。這樣可以減少數(shù)據(jù)傳輸量,提高查詢速度,并且減少不必要的資源消耗。
- 優(yōu)化WHERE子句:WHERE子句是查詢語句中最關(guān)鍵的部分,它決定了查詢的效率。確保WHERE子句中的條件是精確的,并且能夠充分利用已經(jīng)建立的索引。避免在WHERE子句中使用復(fù)雜的函數(shù)或計算,這可能會導(dǎo)致索引失效。
- 使用索引友好的操作符:某些操作符可能會導(dǎo)致索引失效,如LIKE '%value%'。盡量使用索引友好的操作符,如=, >=, <=, IN等。如果需要使用LIKE,可以嘗試使用LIKE 'value%',這樣如果可能的話,索引還能被部分利用。
- 避免全表掃描:全表掃描會導(dǎo)致查詢效率低下,尤其是在數(shù)據(jù)量大的情況下。通過精確的WHERE子句條件和合理的索引使用,可以避免全表掃描。
- 使用JOIN的策略:在涉及多個表的查詢中,合理使用JOIN可以提高查詢效率。盡量在具有相關(guān)性的小表上建立連接,并且使用索引來加速JOIN操作。
- 分頁查詢:對于返回大量數(shù)據(jù)的查詢,可以使用分頁技術(shù)來提高性能。使用LIMIT和OFFSET來限制返回的數(shù)據(jù)量,這樣可以減少數(shù)據(jù)傳輸和處理的時間。
- 合理使用聚合函數(shù):聚合函數(shù)(如COUNT, SUM, AVG等)在統(tǒng)計數(shù)據(jù)時非常有用,但是它們可能會導(dǎo)致大量的計算。在可能的情況下,預(yù)先計算并存儲聚合數(shù)據(jù),或者使用索引來加速聚合操作。
- 減少子查詢的使用:子查詢可能會導(dǎo)致查詢效率降低,尤其是在子查詢被多次執(zhí)行的情況下。可以考慮使用JOIN或臨時表來替代子查詢。
- 使用EXPLAIN分析查詢:使用EXPLAIN語句來分析查詢的執(zhí)行計劃,可以幫助你理解查詢是如何執(zhí)行的,哪些地方可以使用索引,哪些地方需要優(yōu)化。
- 避免在索引列上使用函數(shù)或計算:在索引列上使用函數(shù)或計算會導(dǎo)致索引失效。確保在WHERE子句中直接使用列名,而不是對列進行函數(shù)操作或計算。
通過精確化的查詢語句,可以有效地提高MySQL數(shù)據(jù)庫的查詢性能,減少系統(tǒng)資源的消耗,提升用戶體驗。在實際工作中,應(yīng)根據(jù)具體的業(yè)務(wù)需求和數(shù)據(jù)特點,不斷調(diào)整和優(yōu)化查詢語句。
2.使用預(yù)處理語句
預(yù)處理語句(Prepared Statements)在MySQL中是一種提高查詢效率和安全性的技術(shù)。它們允許客戶端為執(zhí)行SQL語句準(zhǔn)備一個模板,然后在執(zhí)行時傳遞具體的參數(shù)值。這種方式對于處理具有相同結(jié)構(gòu)但不同數(shù)據(jù)的多次執(zhí)行的SQL語句特別有用
- 性能提升:預(yù)處理語句可以重用執(zhí)行計劃,減少了數(shù)據(jù)庫為每次執(zhí)行相同查詢而重新編譯SQL語句的開銷。這在應(yīng)用程序中循環(huán)執(zhí)行相同查詢時尤其有用。
- 安全性:預(yù)處理語句可以有效防止SQL注入攻擊,因為參數(shù)值是在語句發(fā)送到服務(wù)器之后單獨傳遞的,攻擊者無法通過注入惡意代碼來破壞SQL語句的結(jié)構(gòu)。
- 易用性:預(yù)處理語句使得代碼更加清晰易讀,因為它將SQL邏輯與具體的參數(shù)值分離,使得代碼維護和調(diào)試更加容易。
3.避免全表掃描
全表掃描會導(dǎo)致查詢性能急劇下降。應(yīng)通過精確的WHERE條件和合理的索引使用來避免全表掃描的發(fā)生。同時,對于大表,可以考慮使用分區(qū)表或物化視圖等高級特性來進一步優(yōu)化查詢。
Java使用場景下的優(yōu)化
1.數(shù)據(jù)庫連接的管理
在MySQL優(yōu)化中,數(shù)據(jù)庫連接的管理是一個關(guān)鍵環(huán)節(jié),它直接影響到應(yīng)用程序的性能和數(shù)據(jù)庫服務(wù)器的負(fù)載。合理的連接管理可以減少資源消耗,提高連接的復(fù)用率,確保系統(tǒng)的穩(wěn)定性和高效性。
- 使用連接池:連接池是一種高效的數(shù)據(jù)庫連接管理技術(shù),它可以重用已經(jīng)創(chuàng)建的數(shù)據(jù)庫連接,避免了頻繁地創(chuàng)建和關(guān)閉連接所帶來的開銷。通過使用連接池,應(yīng)用程序可以從預(yù)先建立的連接中獲取一個連接,使用完畢后將其釋放回連接池,而不是直接關(guān)閉。這樣可以減少連接的創(chuàng)建次數(shù),提高資源利用率。
- 合理設(shè)置連接參數(shù):數(shù)據(jù)庫連接的參數(shù)設(shè)置對性能有重要影響。例如,設(shè)置合適的連接超時時間可以避免應(yīng)用程序長時間等待數(shù)據(jù)庫響應(yīng)。另外,根據(jù)應(yīng)用程序的特點和需求,合理配置如最大連接數(shù)、最小空閑連接數(shù)等參數(shù),可以有效避免資源浪費和連接不足的問題。
- 及時回收和重用連接:對于不再需要的數(shù)據(jù)庫連接,應(yīng)及時回收到連接池中,以便其他操作可以使用這些連接。這樣可以減少因為連接數(shù)不足而造成的等待時間,提高應(yīng)用程序的響應(yīng)速度。
- 避免連接泄露:連接泄露是指應(yīng)用程序在使用完數(shù)據(jù)庫連接后沒有正確關(guān)閉連接,導(dǎo)致連接一直占用系統(tǒng)資源。應(yīng)確保每次數(shù)據(jù)庫操作完成后,都正確關(guān)閉或回收連接,避免連接泄露。
- 監(jiān)控連接使用情況:定期監(jiān)控數(shù)據(jù)庫連接的使用情況,包括連接的創(chuàng)建、使用、回收和錯誤等,可以幫助及時發(fā)現(xiàn)并解決連接管理中的問題。通過監(jiān)控,可以調(diào)整連接池的配置,優(yōu)化連接的使用效率。
- 使用長連接:長連接是指在應(yīng)用程序和數(shù)據(jù)庫服務(wù)器之間建立的持久連接。與短連接相比,長連接可以減少連接建立和關(guān)閉的開銷,提高性能。但是,長連接也需要合理管理,避免因為連接長時間占用而導(dǎo)致資源不足。
2.盡量使用批量插入
盡量使用批量插入是一種提高數(shù)據(jù)插入效率和性能的有效方法。批量插入指的是一次性向數(shù)據(jù)庫中插入多行數(shù)據(jù),而不是逐條插入單行數(shù)據(jù)。這種方法可以顯著減少與數(shù)據(jù)庫的交互次數(shù),降低網(wǎng)絡(luò)延遲和系統(tǒng)開銷,從而提升整體的數(shù)據(jù)處理能力
- 減少事務(wù)開銷:批量插入可以將多條數(shù)據(jù)作為一個事務(wù)進行處理,減少了事務(wù)提交的次數(shù),從而降低了事務(wù)管理的開銷。
- 降低網(wǎng)絡(luò)開銷:通過批量插入,可以減少客戶端與數(shù)據(jù)庫服務(wù)器之間的通信次數(shù),這對于網(wǎng)絡(luò)延遲較高的環(huán)境尤其有益。
- 提高數(shù)據(jù)處理速度:批量插入可以減少數(shù)據(jù)庫操作的次數(shù),從而提高數(shù)據(jù)插入的速度和效率。
- 減輕數(shù)據(jù)庫壓力:批量插入減少了對數(shù)據(jù)庫的頻繁訪問,有助于減輕數(shù)據(jù)庫服務(wù)器的壓力,特別是在高并發(fā)場景下。
3.緩存機制的引入
引入緩存機制可以有效減輕數(shù)據(jù)庫的壓力。使用Memcached或Redis等緩存系統(tǒng),可以將頻繁訪問的數(shù)據(jù)緩存在內(nèi)存中,減少對數(shù)據(jù)庫的訪問次數(shù)。
運維管理層面的優(yōu)化
1.緩沖池大小的調(diào)整
InnoDB緩沖池是MySQL中非常重要的一個組件,它用于緩存數(shù)據(jù)和索引頁。合理調(diào)整緩沖池的大小,可以確保數(shù)據(jù)庫能夠高效地處理讀寫請求。
2.定期維護的執(zhí)行
定期使用ANALYZE TABLE命令來分析表的鍵值分布,以及使用OPTIMIZE TABLE命令來整理表的物理存儲結(jié)構(gòu),可以保持表的最優(yōu)狀態(tài)。
3.慢查詢?nèi)罩镜谋O(jiān)控
開啟慢查詢?nèi)罩究梢詭椭R別和優(yōu)化性能瓶頸。通過分析慢查詢?nèi)罩荆梢哉页鲂枰獌?yōu)化的SQL語句,并采取相應(yīng)的優(yōu)化措施。
4.硬件資源的優(yōu)化
數(shù)據(jù)庫的性能也受到硬件資源的限制。根據(jù)數(shù)據(jù)庫的工作負(fù)載,合理分配CPU、內(nèi)存、存儲和網(wǎng)絡(luò)資源,可以顯著提升數(shù)據(jù)庫的性能。
高級優(yōu)化技巧
1.分區(qū)表的運用
對于非常大的表,使用分區(qū)可以提高查詢效率。合理的分區(qū)策略可以將數(shù)據(jù)分布到不同的物理區(qū)域,使得查詢可以只掃描相關(guān)的分區(qū),而不是整個表。
2.事務(wù)隔離級別的調(diào)整
根據(jù)應(yīng)用的具體需求,合理設(shè)置事務(wù)隔離級別。較低的隔離級別可以減少鎖的開銷,提高并發(fā)性能,但可能會犧牲一定的數(shù)據(jù)一致性。
3.外鍵約束的謹(jǐn)慎使用
外鍵約束可以維護數(shù)據(jù)的引用完整性,但過多的外鍵會降低寫操作的性能。在不影響數(shù)據(jù)完整性的前提下,應(yīng)盡量減少外鍵的使用。
4.查詢重寫與執(zhí)行計劃分析
使用EXPLAIN命令分析查詢執(zhí)行計劃,可以幫助開發(fā)者理解查詢的執(zhí)行過程,找出性能瓶頸。通過查詢重寫,可以優(yōu)化查詢執(zhí)行計劃,提高查詢效率。
通過上述策略的綜合運用,可以全面提升MySQL數(shù)據(jù)庫的性能,確保數(shù)據(jù)庫在各種應(yīng)用場景下都能保持高效穩(wěn)定的運行。這些優(yōu)化措施需要根據(jù)實際情況靈活調(diào)整,持續(xù)優(yōu)化,以達(dá)到最佳的性能表現(xiàn)。