













避免業務中斷,K8s節點故障排查攻略,速來圍觀!
Kubernetes是一個強大的容器編排系統,但在運行過程中,節點故障可能會發生。本教程將引導您深入了解和排查K8S節點故障的常見問題,以確保集群的可靠性和穩定性。

步驟一:檢查節點狀態
首先,通過以下命令檢查節點的整體狀態:
kubectl get nodes執行上述命令,輸入結果如下圖:

確認所有節點都處于Ready狀態。如果有節點處于NotReady狀態,可以運行以下命令查看詳細信息:
kubectl describe node <node-name>例如,現在要查看node01節點詳細信息,如下圖:
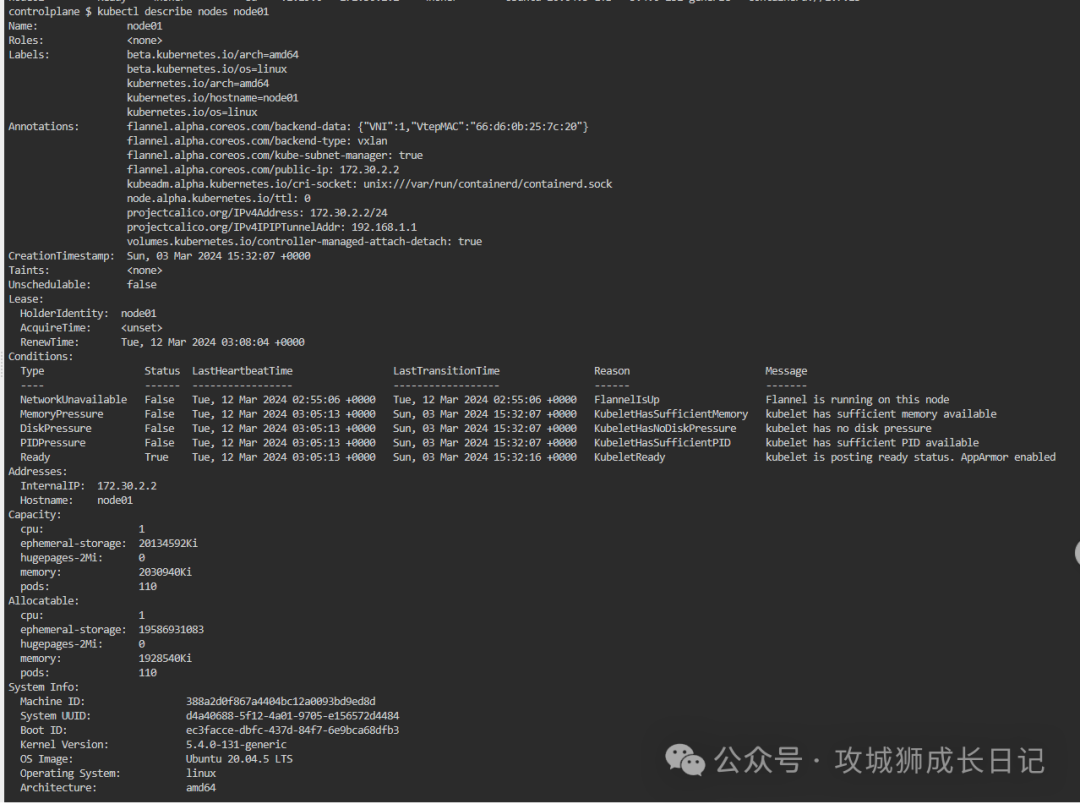
步驟二:查看事件
使用以下命令查看集群中的事件,以了解任何異常情況:
kubectl get events執行上述命令,輸入結果如下圖:
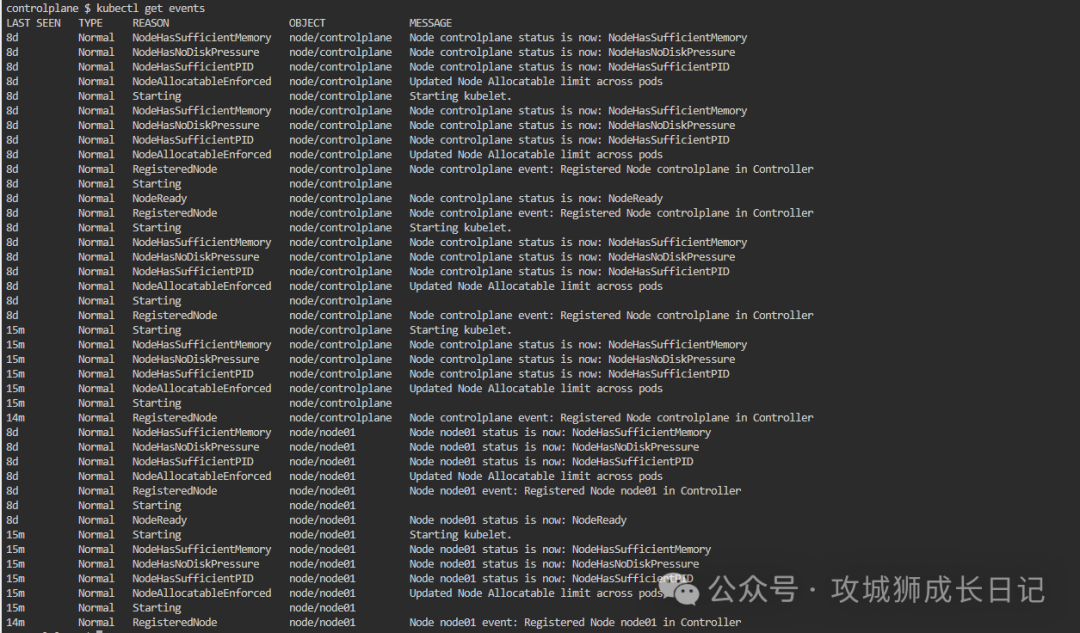
步驟三:系統資源檢查
確保節點上的系統資源(CPU、內存、磁盤空間)足夠。可以通過以下命令檢查:
kubectl describe node <node-name> | grep Allocated -A 5執行上述命令,輸入結果如下圖:

步驟四:網絡排查
(1) 確認網絡插件狀態
檢查網絡插件是否正常運行。常見的網絡插件有Flannel、Calico等。使用以下命令檢查:
kubectl get pods -n kube-system執行上述命令,輸入結果如下圖:
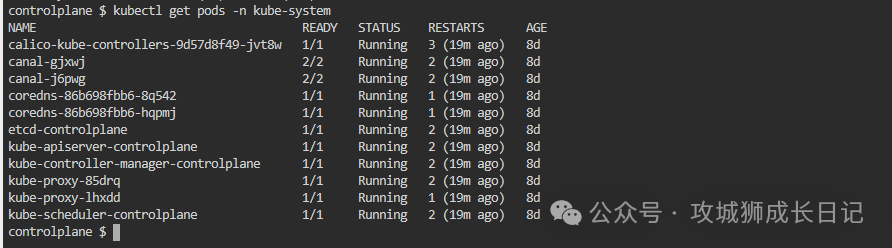
(2) 檢查節點之間的網絡連通性
確認節點之間的網絡通信是否正常。使用工具如ping、traceroute等檢查節點間的連通性。例如,下圖是從node01節點ping控制節點controlplane

步驟五:檢查容器運行時狀態
如果使用Docker作為容器運行時,請檢查Docker容器的狀態:
docker ps
docker logs <container-id>如果使用了containerd為容器運行時,請檢查containerd容器的狀態,如下圖:
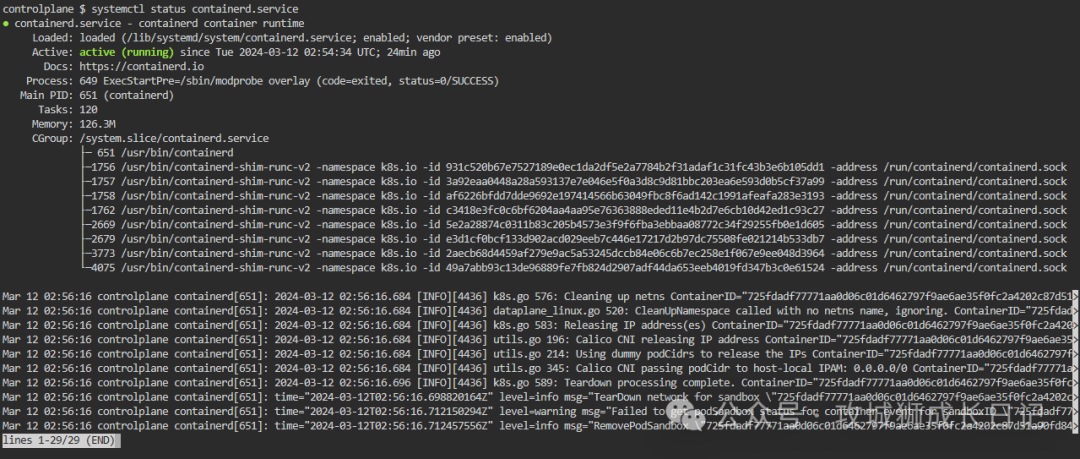
步驟六:檢查kubelet服務狀態
確保kubelet服務在節點上正常運行。運行以下命令:
systemctl status kubelet檢查輸出以確保kubelet服務處于激活(active)狀態。如果kubelet服務未激活,運行以下命令重啟kubelet服務:
sudo systemctl restart kubelet步驟七:重啟故障節點
在確保不影響生產負載的情況下,可以嘗試重啟故障的節點。使用以下命令:
kubectl drain <node-name> --ignore-daemonsets
kubectl delete node <node-name>結論
通過以上步驟,您應該能夠診斷并解決Kubernetes節點故障的常見問題。請注意,在進行操作之前,確保已經了解操作的潛在風險,并在非生產環境中進行測試。保持對K8S集群的定期監控,以及學習并熟練使用K8S提供的工具,將有助于更好地管理和維護您的容器化應用程序。
9CKA真題
(1) 真題截圖:
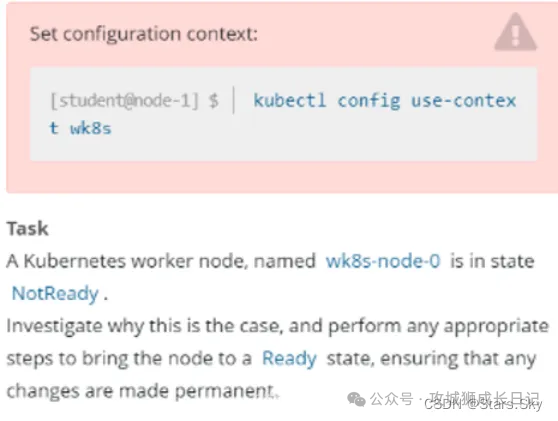
(2) 中文解析
切換 k8s 集群環境: kubectl config use-context wk8sTask:一個名為 wk8s-node-0 的節點狀態為 NotReady,讓其他恢復至正常狀態,并確認所有的更改開機自動完成。
- 可以使用以下命令,通過 ssh 連接到 wk8s-node-0 節點:ssh wk8s-node-0
- 可以使用以下命令,在該節點上獲取更高權限:sudo -i
(3) 官方參考文檔
安全地清空一個節點:https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/safely-drain-node/
(4) 做題解答
切換k8s集群環境:
kubectl config use-context wk8sSSH登錄到wk8s-node-0 的節點,并獲取最高權限:
ssh wk8s-node-0
sudo -i檢查kubelet的狀態:
systemctl status kubelet重啟kubelet,并設置開機自啟動:
systemctl enable kubelet
systemctl status kubelet

























