容器下在 Triton Server 中使用 TensorRT-LLM 進行推理
1. TensorRT-LLM 編譯模型
1.1 TensorRT-LLM 簡介
使用 TensorRT 時,通常需要將模型轉換為 ONNX 格式,再將 ONNX 轉換為 TensorRT 格式,然后在 TensorRT、Triton Server 中進行推理。
但這個轉換過程并不簡單,經常會遇到各種報錯,需要對模型結構、平臺算子有一定的掌握,具備轉換和調試能力。而 TensorRT-LLM 的目標就是降低這一過程的復雜度,讓大模型更容易跑在 TensorRT 引擎上。
需要注意的是,TensorRT 針對的是具體硬件,不同的 GPU 型號需要編譯不同的 TensorRT 格式模型。這與 ONNX 模型格式的通用性定位顯著不同。
同時,TensortRT-LLM 并不支持全部 GPU 型號,僅支持 H100、L40S、A100、A30、V100 等顯卡。
1.2 配置編譯環境
docker run --gpus device=0 -v $PWD:/app/tensorrt_llm/models -it --rm hubimage/nvidia-tensorrt-llm:v0.7.1 bash--gpus device=0 表示使用編號為 0 的 GPU 卡,這里的 hubimage/nvidia-tensorrt-llm:v0.7.1 對應的就是 TensorRT-LLM v0.7.1 的 Release 版本。
由于自行打鏡像非常麻煩,這里提供幾個可選版本的鏡像:
- hubimage/nvidia-tensorrt-llm:v0.7.1
- hubimage/nvidia-tensorrt-llm:v0.7.0
- hubimage/nvidia-tensorrt-llm:v0.6.1
1.3 編譯生成 TensorRT 格式模型
在上述容器環境下,執行命令:
python examples/baichuan/build.py --model_version v2_7b \
--model_dir ./models/Baichuan2-7B-Chat \
--dtype float16 \
--parallel_build \
--use_inflight_batching \
--enable_context_fmha \
--use_gemm_plugin float16 \
--use_gpt_attention_plugin float16 \
--output_dir ./models/Baichuan2-7B-trt-engines生成的文件主要有三個:
- baichuan_float16_tp1_rank0.engine,嵌入權重的模型計算圖文件
- config.json,模型結構、精度、插件等詳細配置信息文件
- model.cache,編譯緩存文件,可以加速后續編譯速度
1.4 推理測試
python examples/run.py --input_text "世界上第二高的山峰是哪座?" \
--max_output_len=200 \
--tokenizer_dir ./models/Baichuan2-7B-Chat \
--engine_dir=./models/Baichuan2-7B-trt-engines[02/03/2024-10:02:58] [TRT-LLM] [W] Found pynvml==11.4.1. Please use pynvml>=11.5.0 to get accurate memory usage
Input [Text 0]: "世界上第二高的山峰是哪座?"
Output [Text 0 Beam 0]: "
珠穆朗瑪峰(Mount Everest)是地球上最高的山峰,海拔高度為8,848米(29,029英尺)。第二高的山峰是喀喇昆侖山脈的喬戈里峰(K2),海拔高度為8,611米(28,251英尺)。"1.5 驗證是否嚴重退化
模型推理優化,可以替換算子、量化、裁剪反向傳播等手段,但有一個基本線一定要達到,那就是模型不能退化很多。
在精度損失可接受的范圍內,模型的推理優化才有意義。TensorRT-LLM 項目提供的 summarize.py 可以跑一些測試,給模型打分,rouge1、rouge2 和 rougeLsum 是用于評價文本生成質量的指標,可以用于評估模型推理質量。
- 獲取原格式模型的 Rouge 指標
pip install datasets nltk rouge_score -i https://pypi.tuna.tsinghua.edu.cn/simple由于目前 optimum 不支持 Baichuan 模型,因此,需要編輯 examples/summarize.py 注釋掉 model.to_bettertransformer(),這個問題在最新的 TensorRT-LLM 代碼中已經解決,我使用的是當前最新的 Release 版本 (v0.7.1)。
python examples/summarize.py --test_hf \
--hf_model_dir ./models/Baichuan2-7B-Chat \
--data_type fp16 \
--engine_dir ./models/Baichuan2-7B-trt-engines輸出結果:
[02/03/2024-10:21:45] [TRT-LLM] [I] Hugging Face (total latency: 31.27020287513733 sec)
[02/03/2024-10:21:45] [TRT-LLM] [I] HF beam 0 result
[02/03/2024-10:21:45] [TRT-LLM] [I] rouge1 : 28.847385241217726
[02/03/2024-10:21:45] [TRT-LLM] [I] rouge2 : 9.519352831698162
[02/03/2024-10:21:45] [TRT-LLM] [I] rougeL : 20.85486489462602
[02/03/2024-10:21:45] [TRT-LLM] [I] rougeLsum : 24.090111126907733- 獲取 TensorRT 格式模型的 Rouge 指標
python examples/summarize.py --test_trt_llm \
--hf_model_dir ./models/Baichuan2-7B-Chat \
--data_type fp16 \
--engine_dir ./models/Baichuan2-7B-trt-engines輸出結果:
[02/03/2024-10:23:16] [TRT-LLM] [I] TensorRT-LLM (total latency: 28.360705375671387 sec)
[02/03/2024-10:23:16] [TRT-LLM] [I] TensorRT-LLM beam 0 result
[02/03/2024-10:23:16] [TRT-LLM] [I] rouge1 : 26.557043897453102
[02/03/2024-10:23:16] [TRT-LLM] [I] rouge2 : 8.28672928021811
[02/03/2024-10:23:16] [TRT-LLM] [I] rougeL : 19.13639628365737
[02/03/2024-10:23:16] [TRT-LLM] [I] rougeLsum : 22.0436013250798TensorRT-LLM 編譯之后的模型,rougeLsum 從 24 降到了 22,說明能力會有退化,但只要在可接受的范圍之內,還是可以使用的,因為推理速度會有較大的提升。
完成這步之后,就可以退出容器了,推理是在另外一個容器中進行。
2. Triton Server 配置說明
2.1 Triton Server 簡介
Triton Server 是一個推理框架,提供用戶規模化進行推理的能力。具體包括:
- 支持多種后端,tensorrt、onnxruntime、pytorch、python、vllm、tensorrtllm 等,還可以自定義后端,只需要相應的 shared library 即可。
- 對外提供 HTTP、GRPC 接口
- batch 能力,支持批量進行推理,而開啟 Dynamic batching 之后,多個 batch 可以合并之后同時進行推理,實現更高吞吐量
- pipeline 能力,一個 Triton Server 可以同時推理多個模型,并且模型之間可以進行編排,支持 Concurrent Model Execution 流水線并行推理
- 觀測能力,提供有 Metrics 可以實時監控推理的各種指標
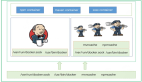
 圖片
圖片
上面是 Triton Server 的架構圖,簡單點說 Triton Server 是一個端(模型)到端(應用)的推理框架,提供了圍繞推理的生命周期過程管理,配置好模型之后,就能直接對應用層提供服務。
2.2 Triton Server 使用配置
在 Triton 社區的示例中,通常會有這樣四個目錄:
.
├── ensemble
│ ├── 1
│ └── config.pbtxt
├── postprocessing
│ ├── 1
│ │ └── model.py
│ └── config.pbtxt
├── preprocessing
│ ├── 1
│ │ └── model.py
│ └── config.pbtxt
└── tensorrt_llm
├── 1
└── config.pbtxt
9 directories, 6 files對于 Triton Server 來說,上面的目錄格式實際上是定義了四個模型,分別是 preprocessing、tensorrt_llm、postprocessing、ensemble,只不過 ensemble 是一個組合模型,定義多個模型來融合。
ensemble 存在的原因在于 tensorrt_llm 的推理并不是 text2text ,借助 Triton Server 的 Pipeline 能力,通過 preprocessing 對輸入進行 Tokenizing,postprocessing 對輸出進行 Detokenizing,就能夠實現端到端的推理能力。否則,在客戶端直接使用 TensorRT-LLM 時,還需要自行處理詞與索引的雙向映射。
這四個模型具體作用如下:
- preprocessing, 用于輸入文本的預處理,包括分詞、詞向量化等,實現類似 text2vec 的預處理。
- tensorrt_llm, 用于 TensorRT 格式模型的 vec2vec 的推理
- postprocessing,用于輸出文本的后處理,包括生成文本的后處理,如對齊、截斷等,實現類似 vec2text 的后處理。
- ensemble,將上面的是三個模型進行融合,提供 text2text 的推理
上面定義的模型都有一個 1 目錄表示版本 1 ,在版本目錄中放置模型文件,在模型目錄下放置 config.pbtxt 描述推理的參數 input、output、version 等。
2.3 模型加載的控制管理
Triton Server 通過參數 --model-control-mode 來控制模型加載的方式,目前有三種加載模式:
- none,加載目錄下的全部模型
- explicit,加載目錄下的指定模型,通過參數 --load-model 加載指定的模型
- poll,定時輪詢加載目錄下的全部模型,通過參數 --repository-poll-secs 配置輪詢周期
2.4 模型版本的控制管理
Triton Server 在模型的配置文件 config.pbtxt 中提供有 Version Policy,每個模型可以有多個版本共存。默認使用版本號為 1 的模型,目前有三種版本策略:
- 所有版本同時使用
version_policy: { all: {}}- 只使用最近 n 個版本
version_policy: { latest: { num_versions: 3}}- 只使用指定的版本
version_policy: { specific: { versions: [1, 3, 5]}}3. Triton Server 中使用 TensorRT-LLM
3.1 克隆配置文件
本文示例相關的配置已經整理了一份到 GitHub 上,拷貝模型到指定的目之后,就可以直接進行推理了。
git clone https://github.com/shaowenchen/modelops3.2 組織推理目錄
- 拷貝 TensorRT 格式模型
cp Baichuan2-7B-trt-engines/* modelops/triton-tensorrtllm/Baichuan2-7B-Chat/tensorrt_llm/1/- 拷貝源模型
cp -r Baichuan2-7B-Chat modelops/triton-tensorrtllm/downloads此時文件的目錄結構是:
tree modelops/triton-tensorrtllm
modelops/triton-tensorrtllm
├── Baichuan2-7B-Chat
│ ├── end_to_end_grpc_client.py
│ ├── ensemble
│ │ ├── 1
│ │ └── config.pbtxt
│ ├── postprocessing
│ │ ├── 1
│ │ │ ├── model.py
│ │ │ └── __pycache__
│ │ │ └── model.cpython-310.pyc
│ │ └── config.pbtxt
│ ├── preprocessing
│ │ ├── 1
│ │ │ ├── model.py
│ │ │ └── __pycache__
│ │ │ └── model.cpython-310.pyc
│ │ └── config.pbtxt
│ └── tensorrt_llm
│ ├── 1
│ │ ├── baichuan_float16_tp1_rank0.engine
│ │ ├── config.json
│ │ └── model.cache
│ └── config.pbtxt
└── downloads
└── Baichuan2-7B-Chat
├── Baichuan2 模型社區許可協議.pdf
├── Community License for Baichuan2 Model.pdf
├── config.json
├── configuration_baichuan.py
├── generation_config.json
├── generation_utils.py
├── modeling_baichuan.py
├── pytorch_model.bin
├── quantizer.py
├── README.md
├── special_tokens_map.json
├── tokenization_baichuan.py
├── tokenizer_config.json
└── tokenizer.model
13 directories, 26 files3.3 啟動推理服務
docker run --gpus device=0 --rm -p 38000:8000 -p 38001:8001 -p 38002:8002 \
-v $PWD/modelops/triton-tensorrtllm:/models \
hubimage/nvidia-triton-trt-llm:v0.7.1 \
tritonserver --model-repository=/models/Baichuan2-7B-Chat \
--disable-auto-complete-config \
--backend-cnotallow=python,shm-region-prefix-name=prefix0_:如果一臺機器上運行了多個 triton server,那么需要用 shm-region-prefix-name=prefix0_ 區分一下共享內存的前綴,詳情可以參考 https://github.com/triton-inference-server/server/issues/4145 。
啟動日志:
I0129 10:27:31.658112 1 server.cc:619]
+-------------+-----------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Backend | Path | Config |
+-------------+-----------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| python | /opt/tritonserver/backends/python/libtriton_python.so | {"cmdline":{"auto-complete-config":"false","backend-directory":"/opt/tritonserver/backends","min-compute-capability":"6.000000","shm-region-prefix-name":"prefix0_:","default-max-batch-size":"4"}} |
| tensorrtllm | /opt/tritonserver/backends/tensorrtllm/libtriton_tensorrtllm.so | {"cmdline":{"auto-complete-config":"false","backend-directory":"/opt/tritonserver/backends","min-compute-capability":"6.000000","default-max-batch-size":"4"}} |
+-------------+-----------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
I0129 10:27:31.658192 1 server.cc:662]
+----------------+---------+--------+
| Model | Version | Status |
+----------------+---------+--------+
| ensemble | 1 | READY |
| postprocessing | 1 | READY |
| preprocessing | 1 | READY |
| tensorrt_llm | 1 | READY |
+----------------+---------+--------+
...
I0129 10:27:31.745587 1 grpc_server.cc:2513] Started GRPCInferenceService at 0.0.0.0:8001
I0129 10:27:31.745810 1 http_server.cc:4497] Started HTTPService at 0.0.0.0:8000
I0129 10:27:31.787129 1 http_server.cc:270] Started Metrics Service at 0.0.0.0:8002四個模型都處于 READY 狀態,就可以正常推理了。
- 查看模型配置參數
curl localhost:38000/v2/models/ensemble/config
{"name":"ensemble","platform":"ensemble","backend":"","version_policy":{"latest":{"num_versions":1}},"max_batch_size":32,"input":[{"name":"text_input","data_type":"TYPE_STRING",...可以查看模型的推理參數。如果使用的是 auto-complete-config,那么這個接口可以用于導出 Triton Server 自動生成的模型推理參數,用于修改和調試。
- 查看 Triton 是否正常運行
curl -v localhost:38000/v2/health/ready
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain3.4 客戶端調用
- 安裝依賴
pip install tritonclient[grpc] -i https://pypi.tuna.tsinghua.edu.cn/simpleTriton GRPC 接口的性能顯著高于 HTTP 接口,同時在容器中,我也沒有找到 HTTP 接口的示例,這里就直接用 GRPC 了。
- 推理測試
wget https://raw.githubusercontent.com/shaowenchen/modelops/master/triton-tensorrtllm/Baichuan2-7B-Chat/end_to_end_grpc_client.pypython3 ./end_to_end_grpc_client.py -u 127.0.0.1:38001 -p "世界上第三高的山峰是哪座?" -S -o 128
珠穆朗瑪峰(Mount Everest)是世界上最高的山峰,海拔高度為8,848米(29,029英尺)。在世界上,珠穆朗瑪峰之后,第二高的山峰是喀喇昆侖山脈的喬戈里峰(K2,又稱K2峰),海拔高度為8,611米(28,251英尺)。第三高的山峰是喜馬拉雅山脈的坎欽隆加峰(Kangchenjunga),海拔高度為8,586米(28,169英尺)。</s>3.5 查看指標
Triton Server 已經提供了推理指標,監聽在 8002 端口。在本文的示例中,就是 38002 端口。
curl -v localhost:38002/metrics
nv_inference_request_success{model="ensemble",versinotallow="1"} 1
nv_inference_request_success{model="tensorrt_llm",versinotallow="1"} 1
nv_inference_request_success{model="preprocessing",versinotallow="1"} 1
nv_inference_request_success{model="postprocessing",versinotallow="1"} 128
# HELP nv_inference_request_failure Number of failed inference requests, all batch sizes
# TYPE nv_inference_request_failure counter
nv_inference_request_failure{model="ensemble",versinotallow="1"} 0
nv_inference_request_failure{model="tensorrt_llm",versinotallow="1"} 0
nv_inference_request_failure{model="preprocessing",versinotallow="1"} 0
nv_inference_request_failure{model="postprocessing",versinotallow="1"} 0在 Grafana 中可以導入面板 https://grafana.com/grafana/dashboards/18737-triton-inference-server/ 查看指標,如下圖:
 圖片
圖片
4. 總結
本文主要是在學習使用 TensorRT 和 Triton Server 進行推理過程的記錄,主要內容如下:
- TensorRT 是一種針對 Nvidia GPU 硬件更高效的模型推理引擎
- TensorRT-LLM 能讓大模型更快使用上 TensorRT 引擎
- Triton Server 是一個端到端的推理框架,支持大部分的模型框架,能幫助用戶快速實現規模化的推理服務
- Triton Server 下使用 TensorRT-LLM 進行推理的示例
5. 參考
- https://mmdeploy.readthedocs.io/zh-cn/latest/tutorial/03_pytorch2onnx.html
- https://docs.nvidia.com/deeplearning/tensorrt/container-release-notes/running.html#running
- https://github.com/NVIDIA/TensorRT-LLM
- https://github.com/triton-inference-server/triton-tensorrtllm
- https://zhuanlan.zhihu.com/p/663748373