













嵌入和矢量數據庫實操指南
譯文譯者 | 布加迪
審校 | 重樓
這場革命的核心是矢量數據庫概念,這一突破性發展正在重塑我們處理復雜數據的方式。與傳統的關系數據庫不同,這種數據庫具有管理和處理高維矢量數據的獨特功能,這種數據是許多AI 和機器學習應用所固有的。隨著我們更深入研究先進AI時代,矢量數據庫正在成為一種關鍵的工具,在處理生成式AI模型生成的龐大復雜的數據集方面提供了無與倫比的效率和準確性。

本文旨在探索矢量數據庫在生成式AI界的關鍵作用,著重介紹其功能、工作方式、用例和實操教程。
矢量數據庫的定義
矢量數據庫是一種用于存儲、索引和檢索多維數據點的數據庫,這些多維通常稱為矢量。不同于數據庫處理表中組織的數據(如數字和字符串),矢量數據庫是專門為管理多維矢量空間中表示的數據而設計的。這使得它們非常適合AI和機器學習應用,這類應用中的數據通常采用矢量的形式,比如圖像嵌入、文本嵌入或其他類型的特征矢量。
這些數據庫利用索引和搜索算法進行相似性搜索,使它們能夠快速識別數據集中最相似的矢量。這種功能對于推薦系統、圖像和語音識別以及自然語言處理等任務至關重要,因為有效地理解和處理高維數據起著至關重要的作用。因此,矢量數據庫代表了數據庫技術的進步,可以滿足嚴重依賴大量數據的AI應用的需求。
矢量嵌入
我們談論矢量數據庫時,一定要知道什么是矢量嵌入——數據最終如何存儲在矢量數據庫中。矢量嵌入充當數字代碼,封裝了對象(比如音樂流媒體應用程序中的歌曲)的關鍵特征。通過分析和提取關鍵特征(比如節奏和流派),每首歌曲通過嵌入模型轉換成矢量嵌入。
這個過程確保具有相似屬性的歌曲具有相似的矢量代碼。矢量數據庫存儲這些嵌入,并在查詢時比較這些矢量,以查找和推薦匹配特征最接近的歌曲,有助于為用戶提供高效、相關的搜索體驗。
矢量數據庫的工作原理
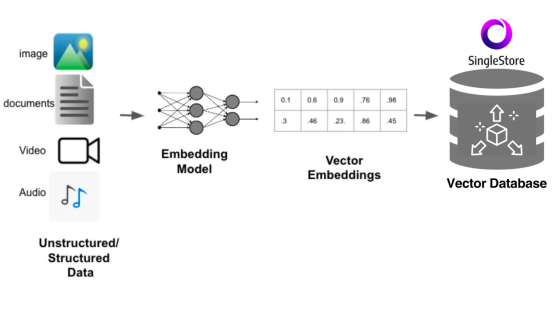
執行用戶查詢時,涉及各種類型的原始數據,包括圖像、文檔、視頻和音頻。所有這些數據可能是非結構化數據,也可能是結構化數據,先通過嵌入模型進行處理。該模型通常是一個復雜的神經網絡,將數據轉換成高維數值矢量,并有效地將數據的特征編碼成矢量嵌入,然后將其存儲到SingleStoreDB之類的矢量數據庫中。
需要檢索時,矢量數據庫執行操作(比如相似性搜索),以查找和檢索與查詢最相似的矢量,從而有效地處理復雜的查詢,并向用戶提供相關的結果。這整個過程支持在需要高速搜索和檢索功能的應用中快速準確地管理大量不同類型的數據。
矢量數據庫與傳統數據庫有何不同?
不妨探討一下矢量數據庫與傳統數據庫之間的區別。
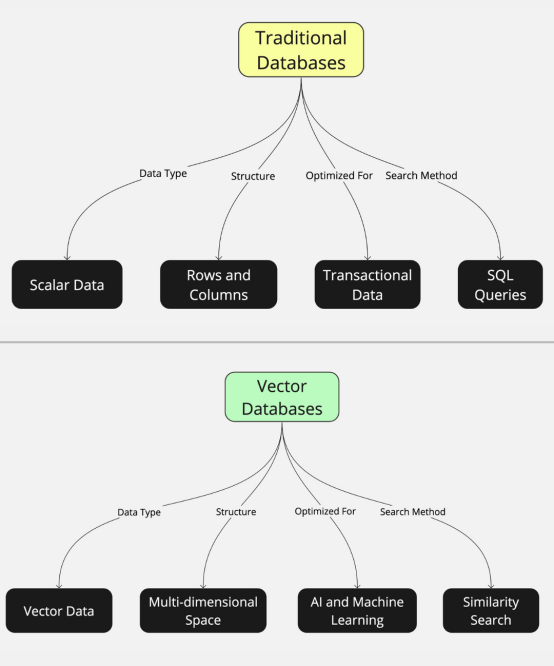
矢量數據庫在數據組織和檢索方法上與傳統數據庫大不相同。傳統數據庫的結構是處理離散的標量數據類型,比如數字和字符串,將它們組織成行和列。
這種結構對于事務性數據來說很理想,但對于AI和機器學習中通常使用的復雜高維數據來說效率較低。相比之下,矢量數據庫旨在存儲和管理矢量數據——即代表多維空間中點的數字數組。
這使得它們天生就適合于涉及相似性搜索的任務,其目標是在高維空間中找到最接近的數據點,這是圖像和語音識別、推薦系統和自然語言處理等AI應用的一個常見要求。通過利用為高維矢量空間優化的索引和搜索算法,矢量數據庫提供了一種更高效、更有效的方法來處理在先進AI和機器學習時代下日益盛行的那種數據。
矢量數據庫的用例
矢量數據庫在企業推薦系統中起著至關重要的作用。比如說,它們可以根據用戶的瀏覽或購買行為向用戶推薦商品。即使在欺詐檢測系統中也大放異彩,它們可以通過比較交易嵌入與欺詐活動的已知概況來檢測異常模式,從而實現實時欺詐檢測。人臉識別是另外的用例,其中矢量數據庫存儲臉部特征嵌入,有助于安全地實施監視。
它們甚至可以通過使用預先確定的或不同的答復來響應類似的查詢,從而幫助組織做好客戶支持。市場研究是矢量數據庫擅長的另一個領域,它通過分析客戶反饋和社交媒體帖子,將它們轉換成文本嵌入來分析情緒和發現趨勢,從而獲得更強大的商業洞察力。
SingleStoreDB作為矢量數據庫
SingleStoreDB強大的矢量數據庫功能可以順暢地服務于AI驅動的應用、聊天機器人和圖像識別系統等。有了SingleStoreDB,就不需要為矢量密集型工作負載維護專用的矢量數據庫了。
與傳統的矢量數據庫方法不同,SingleStoreDB采用了一種新穎的方法,將矢量數據與不同類型的數據類型一起放在關系表中。這種創新的合并使您能夠輕松地訪問與矢量數據相關的全面的元數據和額外屬性,同時利用SQL廣泛的查詢功能。
SingleStoreDB采用可擴展的框架精心構建,確保始終支持快速增長的數據需求。告別限制,擁抱隨數據需求而進化的解決方案。
使用SingleStoreDB的矢量數據庫教程
先決條件
- 注冊免費的SingleStoreDB Cloud試用版。我們將使用SingleStore作為矢量數據庫。
- 創建嵌入的Postman帳戶。
- 獲取OpenAI API密鑰的OpenAI帳戶。
一旦您登錄到OpenAI帳戶,進入到這里所示的API選項卡。

接下來,轉到嵌入選項卡。

我們將從嵌入的API請求開始入手。為此,我們需要進入到API References頁面。進入到API References頁面下的“嵌入”選項卡,查看如何創建嵌入。
現在,不妨為嵌入創建API請求。為此,我們需要像Postman這樣的工具。您可以注冊,并在Postman帳戶中創建一個工作區。
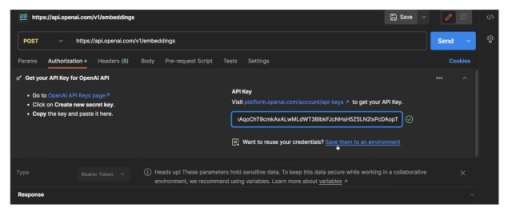
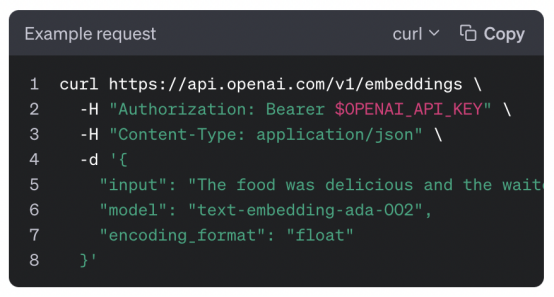
現在,獲取我們的API URL ' https://api.openai.com/v1/embeddings ',并將其粘貼到Postman URL部分中,使用OpenAI API密鑰對其進行授權。
是時候創建我們的第一個嵌入了。我們只需要一個模型和輸入參數,如OpenAI文檔頁面所示。
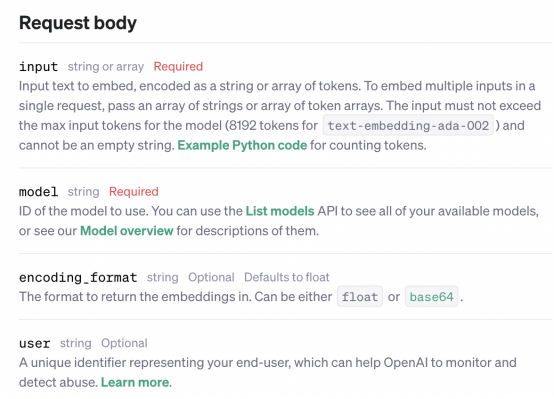
對于該模型,我們將使用“text-embedding-ada-002”和任何文本作為輸入。
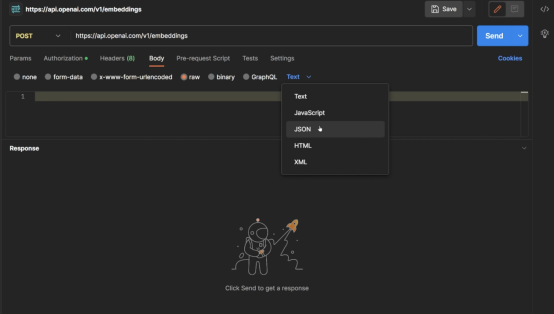
不妨這么做。進入到Postman儀表板,創建一個“body”請求。在主體下,選擇“raw”,然后選擇“JSON”,以傳遞JSON對象。
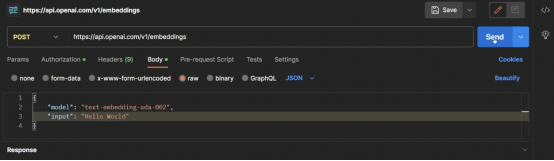
提到模型和輸入。
向OpenAI發送post請求。您會看到如下所示的類似響應。
您看到的數字是嵌入的矢量。為了存儲這些矢量嵌入,您需要一個健壯的數據庫,這是SingleStoreDB的亮點所在。不妨創建一個免費的SingleStoreDB Cloud帳戶。
接下來,創建一個工作區,如下所示。
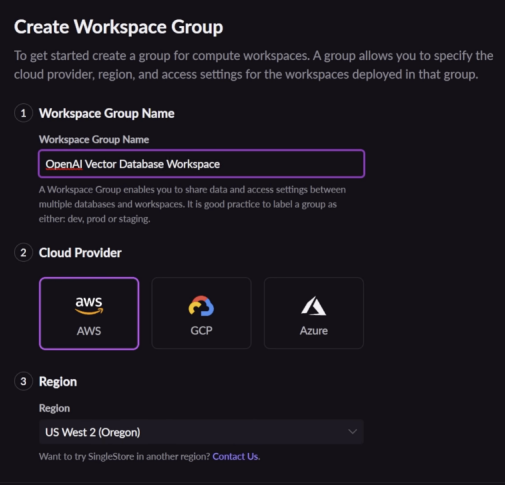
您可以看到已創建的工作區和附加的示例/默認數據庫。
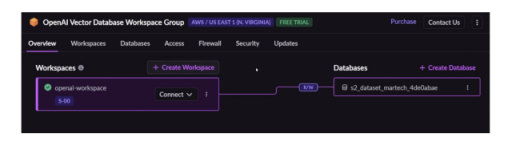
不妨創建一個數據庫。
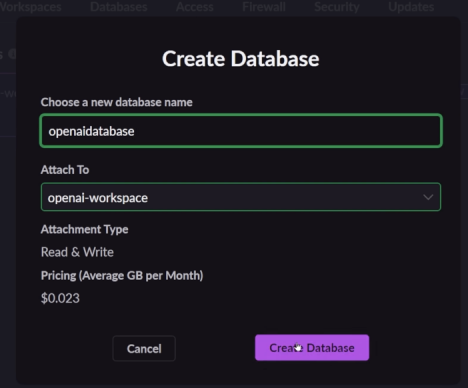
在儀表板中可以看到新創建的數據庫。
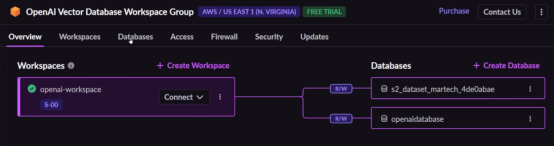
您可以進入該數據庫查看其內容。在本例中,由于我們還沒有提供任何數據,因此您將看不到任何內容。
不妨在數據庫中創建一些表。進入到“SQL編輯器”,如圖所示。您可以運行一些簡單的SQL命令來創建表。
確保在“選擇數據庫”選項卡下選擇數據庫。選擇剛才創建的那個數據庫。
編寫一個簡單的SQL查詢來創建表和數據類型。

現在,不妨將矢量數據插入這個數據庫。我們將在這里輸入從Postman接收到的嵌入數據。返回到SQL編輯器,編寫以下SQL查詢。
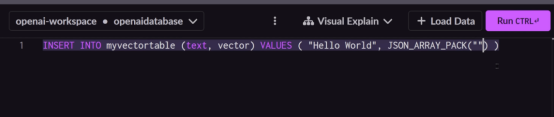
我們使用的值將引用來自Postman的“Hello World”輸入。在JSON_ARRAY_PACK中插入從Postman接收到的巨大的數字塊。
從Postman拷貝這些數字。將這個巨大的數字塊粘貼到值中,然后運行命令。
您可以看到結果被輸入到數據庫中。
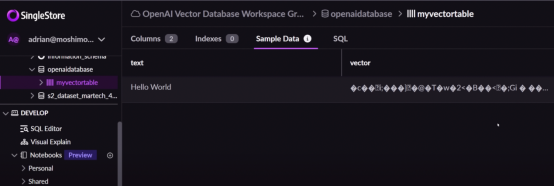
這就是如何使用Postman從不同的輸入創建不同的嵌入,并將生成的矢量嵌入添加到新創建的數據庫中。
使用與前面相同的方法將它們存儲在數據庫中。添加您自己的輸入和內容,將其轉換成矢量。正如您在這里所見,我們添加了不同的輸入,并將生成的矢量嵌入存儲到數據庫中。
現在不妨搜索一些特定的詞語,并從數據庫中檢索相關數據,做一番試驗。不妨回到Postman儀表板,為“OpenAI”這個詞語創建一個嵌入。
接下來,我們將針對現有嵌入在數據庫中執行搜索。這應該會返回結果,最接近的相似性列表在頂部。不妨進入到SQL編輯器,運行這個查詢,如下所示。
將嵌入(巨大的數字塊)粘貼到JSON_ARRAY_PACK中,并運行命令。
在上圖中,您可以看到關鍵詞“OpenAI”的相似性得分和排名。同樣,您可以看到任何關鍵字的相似性得分。這樣,SingleStoreDB就可以用作貴公司的一種有效的矢量數據庫。
原文標題:Embeddings and Vector Databases: A Hands-On Guide!,作者:Pavan Belagatti













