OLAP技術的選擇,進化和思考

引言
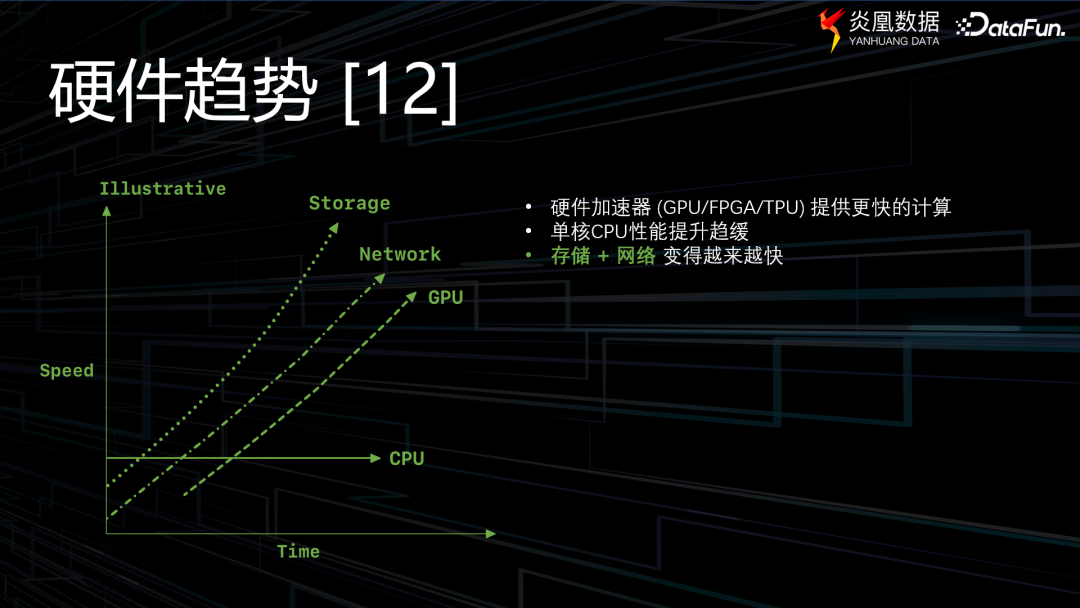
企業數字化的進程,由數據庫的發展軌跡主導,而數據庫本身的演進又受制于硬件的技術瓶頸。簡單來說,數據庫需要一個強大的計算機來支撐,但單塊CPU顯然沒有這個能力,因此通過網絡連接多塊CPU、磁盤的分布式技術成為數據庫發展的主要推動力,但相關硬件技術的發展速度有所差異,“在多年以前,數據庫的硬件瓶頸主要在于磁盤和網絡帶寬,隨著磁盤讀寫速度和網絡帶寬的提升,也就是IO不會成為數據庫的明顯瓶頸。”炎凰數據研發工程師吳立表示,“如今,CPU成為了數據庫執行效率上的新的瓶頸。”
炎凰數據在數據庫開發過程中,最重要的原則就是順應新的場景需求,以及具體的硬件發展現狀,進行技術演進決策。
一、列存儲:數以類聚
炎凰數據在數據庫技術演進中有幾個關鍵節點,列存儲技術的引入在早期非常關鍵。
炎凰數據的核心創始團隊均來源于全球大數據分析引擎領軍企業Splunk,吳立也不例外,“Splunk成立的時間比較早,在大約二十年前,Splunk的產品在業內是非常先進的,但他們實際上采用了行存的存儲形式,在當時還是可以解決用戶問題的,比如日志索引、搜索等。”
比如在做數據聚合搜索的時候,對于行存,就是同一行數據存在一個數據塊或者一個連續的存儲空間里面,而列存就是同一列數據存在一個連續的存儲空間里面。聚合操作一般只針對某一列數據,也就是某一個字段,比如計算某一列數值的和。數據計算通常是針對同一個字段的數據。有了列存之后,可以一次性把所需數據提取出來,相比之下,如果是行存,則需要不斷進行尋址才能找到對應的某列數據,因為它們分散在不同的數據塊里面。
行存的邏輯是存儲每個實體的多維度信息,而列存則是存儲每個維度包含的所有實體的信息。在大數據場景下,列存相比行存有很明顯的優勢。“此外,列存儲的另外一個優勢是,由于數據性質相同,列式數據可以很好地做數據壓縮,進一步提升效率。”
在具體落地中,通過調研很多產品的優缺點,炎凰數據進一步確認了列式存儲的數據格式,“我們調研了很多列存的數據格式,比如Parquet、Avro等,最終,基于內存設計、標準化、語言無關、平鋪和層級數據結構支持、硬件感知等方面的優秀特性,認為Arrow是一個非常通用并且可被廣泛接受的數據格式。我們在應用中,結合具體的使用場景使數據的處理和交換更加高效。”
這項技術可以給OLAP應用帶來很大的體驗提升,但吳立在親身經歷中體會到,雖然技術是為產品服務的,但是技術演進隨時可能面臨風險。因為技術改造終究是很漫長的過程,工程量極大,在真正落地之前并不能100%確定能夠應對未來兩三年的技術發展要求。“除了列存儲,還有比如實時搜索這樣的功能,具體落地時,都存在各種各樣的難題,包括學習曲線、框架支撐等等。”
列式存儲相當于在空間上將查詢、分析與計算所需的重要元素進行匯集或提前過濾,這是加速的重要原則。而這些元素的同質性自然能帶來另一項計算加速優勢,也就是SIMD并行計算,其對列式數據的每一項同時進行相同的運算。
“如果對性能要求很高,SIMD是很自然的選擇。我們希望在產品特別是內核執行的各個階段都能進行優化,并利用好硬件帶來的優勢。在落地過程中,有一個關鍵問題是,SIMD對CPU架構的適配性要求很高,每次適應新的CPU架構,都可能面臨不支持SIMD指令的情況。我們會選擇對SIMD支持更友好的library來對數據結構進行解析,從而實現CPU的適配。比如為了適配ARM的CPU架構,有一些功能組件會采用架構支持的指令集進行編譯,使產品在新的架構上能高效運行。
二、JIT即時編譯:開源的力量
即時編譯是一種通用技術,與任何具體執行策略都不關聯,從而在編譯層面的優化將有很大的自由度。編譯優化也是相對于向量化計算的一種典型加速方式,兩者各有優劣。
“我們在搜索的過程中發現,在簡單的表達式求值場景中,性能沒有完全達到期望值。因為炎凰數據打造的是Schema on Read(讀時建模)產品,應用中會涉及到大量的數據讀取之后在計算層面的過濾。“
Schema on Read也就是讀時建模是炎凰數據的產品核心關注點,主要是為了適應當下大數據場景中常見的異構數據分析面臨的挑戰。
“在搜索過程中還涉及到投影計算,過濾和投影是計算非常重的,如果這兩個計算的性能不好,就會影響整個SQL語句執行的效率。“
為此,炎凰數據決定在編譯優化層面應用JIT即時編譯技術,JIT的主要思想是程序在運行時被編譯成代碼,不需要提前編譯,雖然會犧牲一定的編譯速度,但也降低了鏈接的額外開銷。
在SQL查詢執行的不同步驟中,執行引擎需要計算表達式,表達式以DAG的形式表示,而JIT編譯可以提高表達式在計算時的效率。

在經過調研和選型之后,炎凰數據發現,正好Arrow也提供了表達式優化的工具——Gandiva,“一方面,Gandiva提供了很多內置的表達式庫,同時對投影和過濾計算過程都有良好的支持;另外一方面Gandiva在編譯優化表達式的時候有優化,進一步計算的效率。”
但Gandiva并不是一個很完美的產品,為此,炎凰數據在這個工具的基礎上,對于不滿足特定場景的需求進一步進行完善和補全。“比如想在這個library里面添加一個自定義函數接口的時候,相關的注冊機制沒有完善,就會遇到問題。通常的做法是把這一部分代碼建立一個分支,完善后patch到我們的產品里面。但這種做法帶來的后果是,經常會隨著項目往前發展,帶來一些沖突。”
炎凰數據借用了開源的力量,把這部分代碼貢獻給Arrow開源項目,再從項目的上流分支做一些改進增強,從而解決了這個問題。
JIT即時編譯帶來的優勢非常明顯,大大減少了表達式計算在過濾和投影階段的時間,使得用戶查詢特別是在涉及大量表達式的時候變得更快。

在具體開發中,炎凰數據實現了很多改造,包括數據類型、高階函數等方面的支持,以及緩存復用、外部函數注冊等機制,這些成果全部貢獻給了Arrow項目。
三、push mode:改頭換面
數據庫的性能優化點不僅在于硬件層面的適配,也在于軟件架構中的參與方,也就是數據何時被消費。如果是用戶主動,則在用戶有消費需求的時候從系統拉取數據進行處理,這被稱為pull mode;如果是供應方主動,則不需要關心用戶消費時間點,可以提前提取數據、處理數據,把數據以推送的形式提供給用戶,這被稱為push mode。
pull mode和push mode之間沒有說哪個更好,需要結合具體場景來比較。pull mode在查詢引擎中是一個很經典的模式,接口簡單,從而可以很容易地擴展新功能。但是對于push mode,其技術復雜性更高,不過在新場景支持和效率提升特別是流式數據處理、緩存效率等方面,push mode更加有優勢。
”為了實現技術改造,炎凰數據把pull mode相關的所有執行引擎的算子都替換成了push mode的算子,在整個項目中做了大量的臟活累活。“push mode帶來了進一步的查詢性能提升,“收益非常明顯,雖然程度不一,但對查詢的提升基本是全面的。”
全方位提升的結果凝聚炎凰數據整個團隊的努力,團隊也踩了不少坑,“整體模式切換是比較痛苦的過程,因為要去協調整個整個團隊的資源,不能影響正常產品功能的發布,也要考慮用戶的新需求,同時讓用戶在老的引擎和新的引擎里面都能夠工作。比如有些issue是在產品發布之后才發現的,這就提醒我們在工程排期上多留一些buffer,從而提高容錯率。”
四、產品追求:始終如一
列式存儲、JIT即時編譯以及push mode,一系列的技術優化,最終都是為了用戶查詢體驗的提升,極致的產品追求,反映的是炎凰數據成熟的產品思維,“從終端用戶的角度來看,他們不會關心技術具體是怎么做的,只關心查詢結果是否能夠盡快提供,特別是在大數據量的情況下,這是我們所有產品的落腳點。”
炎凰數據的核心優勢在于異構數據的處理,從數據的采集到存儲、搜索、可視化都能夠有非常好的體驗。在產品開發的關鍵節點也就是核心引擎研發中,炎凰數據始終關注技術發展趨勢以及技術生態的支持,并堅持一個原則,“我們在開發的過程中,不同的階段要給到用戶一個相對完整的產品體驗,同時也不損耗我們對產品的長遠規劃。”
炎凰數據當下的技術演進和產品更新的選擇,順應了OLAP技術不斷趨同、走向標準化,以及數據平臺一體化的趨勢。在這個背景下,炎凰數據對競爭優勢的理解有著自己的執著,“我們始終如一的追求,都在于對異構化的數據更高效的處理,以及為用戶在從采集到可視化的各個層面提供給更好的體驗,存儲要保證安全,分析要保證快速,可視化要滿足分析的需求。只要在各個層面都做的足夠優秀,當作為一個一體化產品呈現給用戶的時候,它才能夠在業內占據一席之地。”