HBase詳細(xì)介紹及原理解析!

基本介紹
HBase官網(wǎng):https://hbase.apache.org/。
Apache HBase 是 Hadoop中一個(gè)支持分布式的、可擴(kuò)展的大數(shù)據(jù)存儲(chǔ)的數(shù)據(jù)庫(kù)。
當(dāng)需要對(duì)大數(shù)據(jù)進(jìn)行隨機(jī)、實(shí)時(shí)讀/寫(xiě)訪問(wèn)時(shí),可以用 Apache HBase。
HBase特點(diǎn)
列式存儲(chǔ):
HBase是面向列族的非關(guān)系型數(shù)據(jù)庫(kù),每行數(shù)據(jù)列都可以不同,并且列可以按照需求進(jìn)行動(dòng)態(tài)增加。
因此在開(kāi)始創(chuàng)建HBase表時(shí),可以只創(chuàng)建列族,等需要時(shí)再創(chuàng)建相應(yīng)的列。
數(shù)據(jù)壓縮:
列式存儲(chǔ)意味著數(shù)據(jù)往往類型相同,可以采用某種壓縮算法進(jìn)行統(tǒng)一的壓縮存儲(chǔ)。
海量存儲(chǔ):
HDFS支持的海量存儲(chǔ),存儲(chǔ)PB級(jí)數(shù)據(jù)仍能有百毫秒內(nèi)的響應(yīng)速度。
基本操作
Shell操作
進(jìn)入HBase客戶端命令操作界面:
hbase shell查看幫助命令:
hbase(main):001:0> help查看當(dāng)前數(shù)據(jù)庫(kù)中有哪些表:
hbase(main):006:0> list創(chuàng)建一張表:
創(chuàng)建user表, 包含base_info、extra_info兩個(gè)列族。
hbase(main):007:0> create 'user', 'base_info', 'extra_info'create 'user', {NAME => 'base_info', VERSIONS => '3'},{NAME => 'extra_info'}添加數(shù)據(jù)操作:
向user表中插入信息,row key為 rk0001,列族base_info中添加name列標(biāo)示符,值為zhangsan。
hbase(main):008:0> put 'user', 'rk0001', 'base_info:name', 'zhangsan'向user表中插入信息,row key為rk0001,列族base_info中添加age列標(biāo)示符,值為20。
hbase(main):010:0> put 'user', 'rk0001', 'base_info:age', 20查詢數(shù)據(jù):
通過(guò)rowkey進(jìn)行查詢:
- 獲取user表中row key為rk0001的所有信息。
hbase(main):006:0> get 'user', 'rk0001'查看rowkey下面的某個(gè)列族的信息:
- 獲取user表中row key為rk0001,base_info列族的所有信息。
hbase(main):007:0> get 'user', 'rk0001', 'base_info'查看rowkey指定列族指定字段的值:
- 獲取user表中row key為rk0001,base_info列族的name、age列標(biāo)示符的信息。
hbase(main):008:0> get 'user', 'rk0001', 'base_info:name', 'base_info:age'查看rowkey指定多個(gè)列族的信息
- 獲取user表中row key為rk0001,base_info、extra_info列族的信息。
hbase(main):010:0> get 'user', 'rk0001', 'base_info', 'extra_info'hbase(main):011:0> get 'user', 'rk0001', {COLUMN => ['base_info', 'extra_info']}hbase(main):012:0> get 'user', 'rk0001', {COLUMN => ['base_info:name', 'extra_info:address']}指定rowkey與列值查詢:
- 獲取user表中row key為rk0001,cell的值為zhangsan的信息。
hbase(main):013:0> get 'user', 'rk0001', {FILTER => "ValueFilter(=, 'binary:zhangsan')"}指定rowkey與列值模糊查詢:
- 獲取user表中row key為rk0001,列標(biāo)示符中含有a的信息。
hbase(main):015:0> get 'user', 'rk0001', {FILTER => "(QualifierFilter(=,'substring:a'))"}插入一批數(shù)據(jù):
hbase(main):016:0> put 'user', 'rk0002', 'base_info:name', 'fanbingbing'
hbase(main):017:0> put 'user', 'rk0002', 'base_info:gender', 'female'
hbase(main):018:0> put 'user', 'rk0002', 'base_info:birthday', '2000-06-06'
hbase(main):019:0> put 'user', 'rk0002', 'extra_info:address', 'Shanghai'查詢所有數(shù)據(jù):
- 查詢user表中的所有信息。
hbase(main):020:0> scan 'user'列族查詢:
- 查詢user表中列族為 base_info 的信息。
Scan:
- 設(shè)置是否開(kāi)啟Raw模式,開(kāi)啟Raw模式會(huì)返回包括已添加刪除標(biāo)記但是未實(shí)際刪除的數(shù)據(jù)。
- VERSIONS指定查詢的最大版本數(shù)。
hbase(main):021:0> scan 'user', {COLUMNS => 'base_info'}
hbase(main):022:0> scan 'user', {COLUMNS => 'base_info', RAW => true, VERSIONS => 5}多列族查詢:
- 查詢user表中列族為info和data的信息。
hbase(main):023:0> scan 'user', {COLUMNS => ['base_info', 'extra_info']}
hbase(main):024:0> scan 'user', {COLUMNS => ['base_info:name', 'extra_info:address']}指定列族與某個(gè)列名查詢:
- 查詢user表中列族為base_info、列標(biāo)示符為name的信息。
hbase(main):025:0> scan 'user', {COLUMNS => 'base_info:name'}指定列族與列名以及限定版本查詢:
- 查詢user表中列族為base_info、列標(biāo)示符為name的信息,并且版本最新的5個(gè)。
hbase(main):026:0> scan 'user', {COLUMNS => 'base_info:name', VERSIONS => 5}指定多個(gè)列族與按照數(shù)據(jù)值模糊查詢:
- 查詢user表中列族為 base_info 和 extra_info且列標(biāo)示符中含有a字符的信息。
hbase(main):027:0> scan 'user', {COLUMNS => ['base_info', 'extra_info'], FILTER => "(QualifierFilter(=,'substring:a'))"}rowkey的范圍值查詢:
- 查詢user表中列族為info,rk范圍是[rk0001, rk0003)的數(shù)據(jù)。
hbase(main):028:0> scan 'user', {COLUMNS => 'base_info', STARTROW => 'rk0001', ENDROW => 'rk0003'}指定rowkey模糊查詢:
- 查詢user表中row key以rk字符開(kāi)頭的。
hbase(main):029:0> scan 'user',{FILTER=>"PrefixFilter('rk')"}更新數(shù)據(jù)值:
- 把user表中rowkey為rk0001的base_info列族下的列name修改為zhangsansan。
hbase(main):030:0> put 'user', 'rk0001', 'base_info:name', 'zhangsansan'指定rowkey以及列名進(jìn)行刪除:
- 刪除user表row key為rk0001,列標(biāo)示符為 base_info:name 的數(shù)據(jù)。
hbase(main):032:0> delete 'user', 'rk0001', 'base_info:name'指定rowkey,列名以及字段值進(jìn)行刪除:
- 刪除user表row key為rk0001,列標(biāo)示符為base_info:name,timestamp為1392383705316的數(shù)據(jù)。
hbase(main):033:0> delete 'user', 'rk0001', 'base_info:age', 1564745324798刪除 base_info 列族。
hbase(main):034:0> alter 'user', NAME => 'base_info', METHOD => 'delete'hbase(main):035:0> alter 'user', 'delete' => 'base_info'刪除user表數(shù)據(jù):
hbase(main):036:0> truncate 'user'刪除user表:
#先disable 再drop
hbase(main):036:0> disable 'user'
hbase(main):037:0> drop 'user'
#如果不進(jìn)行disable,直接drop會(huì)報(bào)錯(cuò)
ERROR: Table user is enabled. Disable it first.數(shù)據(jù)模型
邏輯結(jié)構(gòu):

物理架構(gòu):
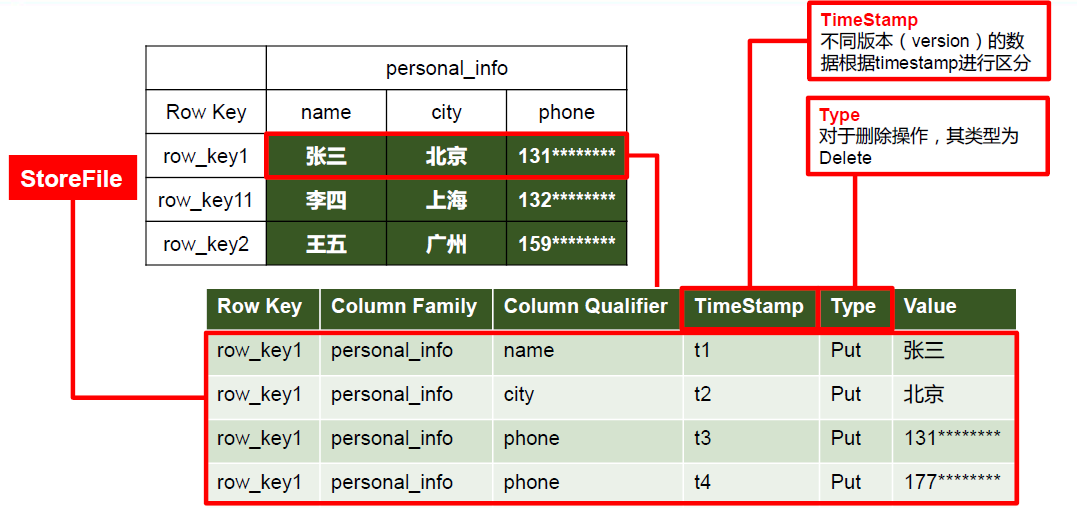

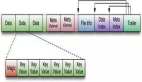
Rowkey(行鍵):
- Table 的主鍵,Table 中的記錄按照 Rowkey 的字典序進(jìn)行排序。
Column Family(列族):
- 表中的每個(gè)列,都?xì)w屬與某個(gè)列族。
- 列族是表的 Schema 的一部分,必須在使用表之前定義。
Timestamp(時(shí)間戳):
- 每次數(shù)據(jù)操作對(duì)應(yīng)的時(shí)間戳,可以看作是數(shù)據(jù)的 Version 版本號(hào)。
Column(列):
- 列族下面的具體列。
- 屬于某一個(gè) ColumnFamily,類似于 MySQL 當(dāng)中創(chuàng)建的具體的列。
Cell(單元格):
- 由{rowkey, column, version} 唯一確定的單元。
- Cell 中的數(shù)據(jù)沒(méi)有類型,全部是以字節(jié)數(shù)組進(jìn)行存儲(chǔ)。
基本原理
如何支持海量數(shù)據(jù)的隨機(jī)存取
利用了HDFS的分布式存儲(chǔ)和Hadoop的分布式計(jì)算能力:
- 將數(shù)據(jù)存儲(chǔ)在HDFS上,并利用Hadoop的MapReduce框架進(jìn)行分布式計(jì)算,從而實(shí)現(xiàn)了高可擴(kuò)展性和高并發(fā)性。
將數(shù)據(jù)按照行和列族的方式存儲(chǔ)在HDFS上:
- 這種數(shù)據(jù)存儲(chǔ)方式使得HBase能夠?qū)崿F(xiàn)高速的隨機(jī)讀寫(xiě)功能。
利用了LSM(Log-Structured Merge-Tree)算法:
- 該算法通過(guò)內(nèi)存和順序?qū)懘疟P(pán)的方式,使得隨機(jī)寫(xiě)入成為可能,同時(shí)還能保證讀取效率。
支持?jǐn)?shù)據(jù)的自動(dòng)分片和負(fù)載均衡:
- 可以支持PB級(jí)別的數(shù)據(jù)存儲(chǔ)和處理,從而滿足大規(guī)模數(shù)據(jù)的實(shí)時(shí)處理需求。
整體結(jié)構(gòu)
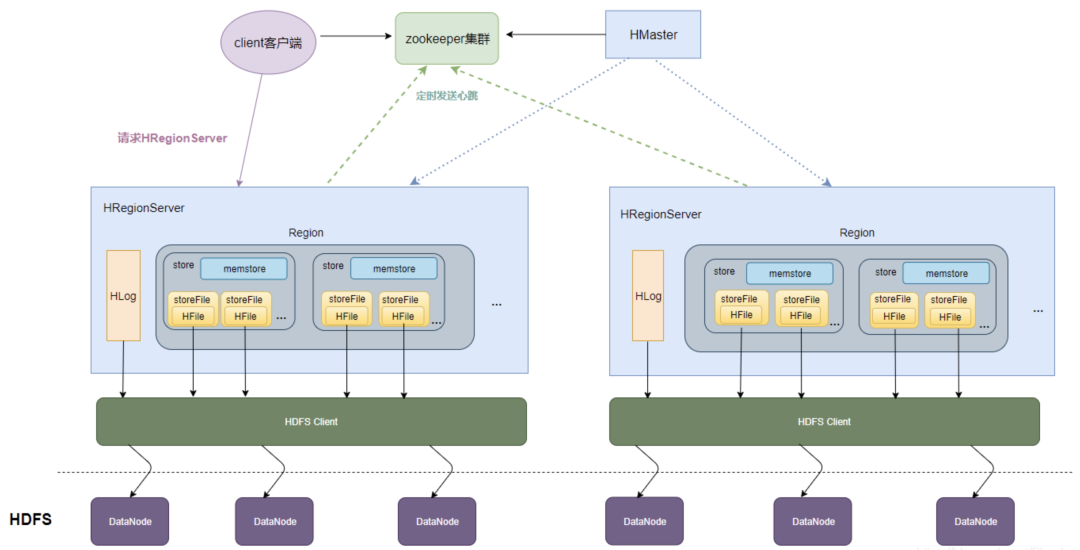
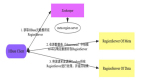
HMaster:
- HBase集群的主節(jié)點(diǎn),負(fù)責(zé)監(jiān)控RegionServer,處理Region分配和負(fù)載均衡。
HRegionServer:
- 管理 Region,處理對(duì)所分配Region的IO請(qǐng)求,Region是表的分片,由多個(gè)Store組成。
Zookeeper:
- 維護(hù)HBase的運(yùn)行狀態(tài)信息,如Region分布信息等。
- HMaster和RegionServer都依賴Zookeeper。
HRegion:
- HBase表的分片,由一個(gè)或者多個(gè)Store組成,存儲(chǔ)實(shí)際的表數(shù)據(jù)。
Store:
- Store以Column Family為單位存儲(chǔ)數(shù)據(jù),主要組成是MemStore和StoreFile(HFile)。
- 1個(gè)Column Family的數(shù)據(jù)存放在一個(gè)Store中,一個(gè)Region包含多個(gè)Store。
MemStore:
- 內(nèi)存存儲(chǔ),用于臨時(shí)存放寫(xiě)數(shù)據(jù),達(dá)到閾值后刷入StoreFile。
- 數(shù)據(jù)會(huì)先寫(xiě)入到 MemStore 進(jìn)行緩沖,然后再把數(shù)據(jù)刷到磁盤(pán)。
- 通過(guò)內(nèi)存,也加快了讀寫(xiě)速度。
StoreFile(HFile):
- 磁盤(pán)上面真正存放數(shù)據(jù)的文件。
HDFS:
- 用來(lái)持久化存儲(chǔ)HFiles。
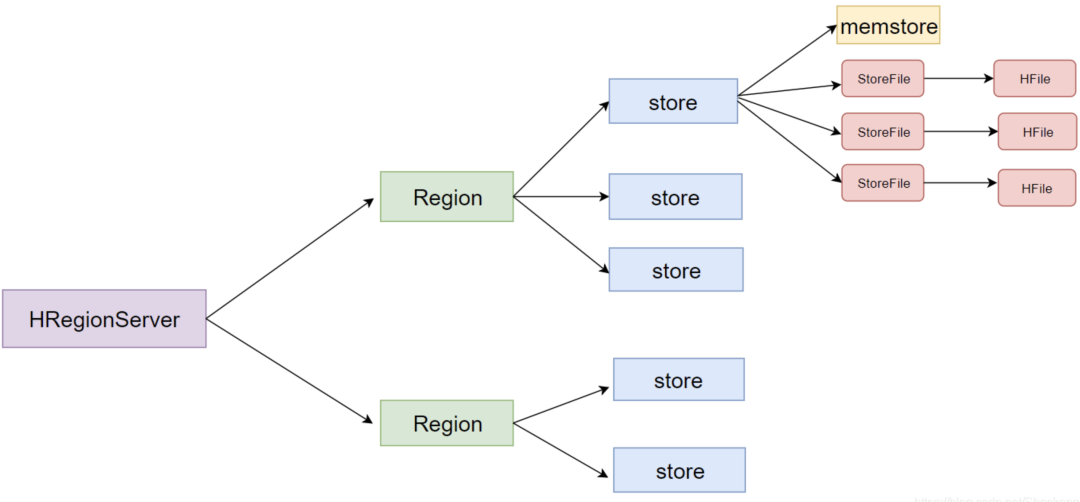
一個(gè)列族就劃分成一個(gè) Store,如果一個(gè)表中只有 1 個(gè)列族,那么每一個(gè) Region 中只有一個(gè) Store。
一個(gè) Store 里面只有一個(gè) MemStore。
一個(gè) Store 里面有很多個(gè) StoreFile, 最后數(shù)據(jù)是以很多個(gè) HFile 文件保存在 HDFS 上。
- StoreFile是HFile的抽象對(duì)象。
- 每次 MemStore 刷寫(xiě)數(shù)據(jù)到磁盤(pán),就生成對(duì)應(yīng)的一個(gè)新的 HFile 文件出來(lái)。

負(fù)載均衡
HBase 官方目前支持兩種負(fù)載均衡策略:
- SimpleLoadBalancer 策略和 StochasticLoadBalancer 策略。
SimpleLoadBalancer 策略:
這種策略能夠保證每個(gè) RegionServer 的 Region 個(gè)數(shù)基本相等。
假設(shè)集群中一共有 n 個(gè) RegionServer,m 個(gè) Region ,那么集群的平均負(fù)載就是 average = m/n。
- 這種策略能夠保證所有 RegionServer 上的 Region 個(gè)數(shù)都在 [floor(average),ceil(average)]之間。
因此, SimpleLoadBalancer 策略中負(fù)載就是 Region 個(gè)數(shù),集群負(fù)載遷移計(jì)劃就是 Region 從個(gè)數(shù)較多的 RegionServer 上遷移到個(gè)數(shù)較少的 RegionServer 上。
雖然集群中每個(gè) RegionServer 的 Region 個(gè)數(shù)都基本相同,但如果某臺(tái) RegionServer 上的 Region 全部都是熱點(diǎn)數(shù)據(jù),導(dǎo)致 90 %的讀寫(xiě)請(qǐng)求還是落在了這臺(tái) RegionServer 上,這樣沒(méi)有達(dá)到負(fù)載均衡的目的。
StochasticLoadBalancer 策略:
它對(duì)于負(fù)載的定義不再是 Region 個(gè)數(shù)這么簡(jiǎn)單,而是由多種獨(dú)立負(fù)載加權(quán)計(jì)算的復(fù)合值,這些獨(dú)立負(fù)載包括:
- Region 個(gè)數(shù),Region 負(fù)載,讀請(qǐng)求數(shù),寫(xiě)請(qǐng)求數(shù),Storefile 大小,MemStore 大小,數(shù)據(jù)本地率,移動(dòng)代價(jià)。
這些獨(dú)立負(fù)載經(jīng)過(guò)加權(quán)計(jì)算會(huì)得到一個(gè)代價(jià)值,系統(tǒng)使用這個(gè)代價(jià)值來(lái)評(píng)估當(dāng)前 Region 分布是否均衡,越均衡代價(jià)值越低。
- HBase 通過(guò)不斷隨機(jī)挑選迭代來(lái)找到一組 Region 遷移計(jì)劃,使得代價(jià)值最小。
Flush機(jī)制
MemStore的大小超過(guò)某個(gè)值的時(shí)候,會(huì)Flush到磁盤(pán),默認(rèn)為128M。
MemStore中的數(shù)據(jù)時(shí)間超過(guò)1小時(shí),會(huì)Flush到磁盤(pán)。
HRegionServer的全局MemStore的大小超過(guò)某大小會(huì)觸發(fā)Flush到磁盤(pán),默認(rèn)是堆大小的40%。
Compact機(jī)制
HBase需要在必要的時(shí)候?qū)⑿〉腟tore File合并成相對(duì)較大的Store File,這個(gè)過(guò)程為Compaction。
- 為了防止小文件過(guò)多,以保證查詢效率。
在HBase中主要存在兩種類型的Compaction合并。
Minor Compaction 小合并:
- 在將Store中多個(gè)HFile合并為一個(gè)HFile。
- 這個(gè)過(guò)程中,達(dá)到TTL(記錄保留時(shí)間)會(huì)被移除,刪除和更新的數(shù)據(jù)僅僅只是做了標(biāo)記,并沒(méi)有物理移除。
- 這種合并的觸發(fā)頻率很高。
Major Compaction 大合并:
- 合并Store中所有的HFile為一個(gè)HFile。
- 這個(gè)過(guò)程有刪除標(biāo)記的數(shù)據(jù)會(huì)被真正移除,同時(shí)超過(guò)單元格maxVersion的版本記錄也會(huì)被刪除。
- 合并頻率比較低,默認(rèn)7天執(zhí)行一次,并且性能消耗非常大,建議生產(chǎn)關(guān)閉(設(shè)置為0),在應(yīng)用空閑時(shí)間手動(dòng)觸發(fā)。
- 一般可以是手動(dòng)控制進(jìn)行合并,防止出現(xiàn)在業(yè)務(wù)高峰期。
Region拆分機(jī)制
Region 中存儲(chǔ)的是大量的 Rowkey 數(shù)據(jù),當(dāng) Region 中的數(shù)據(jù)條數(shù)過(guò)多的時(shí)候,直接影響查詢效率。
- 當(dāng) Region 過(guò)大的時(shí)候,HBase 會(huì)拆分 Region。
HBase 的 Region Split 策略一共有以下幾種。
ConstantSizeRegionSplitPolicy:
0.94版本前默認(rèn)切分策略。
當(dāng)Region大小大于某個(gè)閾值之后就會(huì)觸發(fā)切分,一個(gè)Region等分為2個(gè)Region。
- 在生產(chǎn)線上這種切分策略有相當(dāng)大的弊端:切分策略對(duì)于大表和小表沒(méi)有明顯的區(qū)分。
閾值設(shè)置較大對(duì)大表比較友好,但是小表就有可能不會(huì)觸發(fā)分裂,極端情況下可能就1個(gè)。
如果設(shè)置較小則對(duì)小表友好,但一個(gè)大表就會(huì)在整個(gè)集群產(chǎn)生大量的Region,這對(duì)于集群的管理、資源使用、Failover不好。
IncreasingToUpperBoundRegionSplitPolicy:
0.94版本~2.0版本默認(rèn)切分策略。
總體看和ConstantSizeRegionSplitPolicy思路相同,一個(gè)Region大小大于設(shè)置閾值就會(huì)觸發(fā)切分。
- 但這個(gè)閾值并不是一個(gè)固定的值。
- 而是會(huì)在一定條件下不斷調(diào)整,調(diào)整規(guī)則和Region所屬表在當(dāng)前RegionServer上的Region個(gè)數(shù)有關(guān)系。
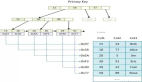
Region Split的計(jì)算公式是:
- RegionCount^3 * 128M * 2,當(dāng)Region達(dá)到該size的時(shí)候進(jìn)行split。
例如:
- 第一次split:1^3 * 256 = 256MB
- 第二次split:2^3 * 256 = 2048MB
- 第三次split:3^3 * 256 = 6912MB
- 第四次split:4^3 * 256 = 16384MB > 10GB,取較小的值10GB
后面每次split的size都是10GB了。
SteppingSplitPolicy:
- 2.0版本默認(rèn)切分策略。
- 依然和待分裂Region所屬表在當(dāng)前RegionServer上的Region個(gè)數(shù)有關(guān)系。
- 如果Region個(gè)數(shù)等于1,切分閾值為flush size * 2,否則為MaxRegionFileSize。
- 這種切分策略對(duì)于大集群中的大表。
- 小表會(huì)比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不會(huì)再產(chǎn)生大量的小Region,而是適可而止。
KeyPrefixRegionSplitPolicy:
- 根據(jù)RowKey的前綴對(duì)數(shù)據(jù)進(jìn)行分組,這里是指定RowKey的前多少位作為前綴,比如RowKey都是16位的,指定前5位是前綴。
- 那么前5位相同的RowKey在進(jìn)行region split的時(shí)候會(huì)分到相同的Region中。
DelimitedKeyPrefixRegionSplitPolicy:
- 保證相同前綴的數(shù)據(jù)在同一個(gè)Region中,例如RowKey的格式為:userid_eventtype_eventid,指定的delimiter為_(kāi)。
- 則split的的時(shí)候會(huì)確保userid相同的數(shù)據(jù)在同一個(gè)Region中。
DisabledRegionSplitPolicy:
不啟用自動(dòng)拆分,需要指定手動(dòng)拆分。
預(yù)分區(qū)
當(dāng)一個(gè)table剛被創(chuàng)建的時(shí)候,HBase默認(rèn)的分配一個(gè)Region給table。
- 這時(shí)所有的讀寫(xiě)請(qǐng)求都會(huì)訪問(wèn)到同一個(gè)RegionServer的同一個(gè)Region中。
- 這個(gè)時(shí)候就達(dá)不到負(fù)載均衡的效果了,集群中的其他RegionServer就可能會(huì)處于比較空閑的狀態(tài)。
解決辦法:
- 可以用預(yù)分區(qū)(pre-splitting),在創(chuàng)建table的時(shí)候就配置好,生成多個(gè)Region。
如何預(yù)分區(qū)?
- 每一個(gè)Region維護(hù)著startRow與endRowKey。
- 如果加入的數(shù)據(jù)符合某個(gè)Region維護(hù)的RowKey范圍,則該數(shù)據(jù)交給這個(gè)Region維護(hù)。
手動(dòng)指定預(yù)分區(qū):
create 'person','info1','info2',SPLITS => ['1000','2000','3000','4000']Region定位
HBase 支持 put , get , delete 和 scan 等基礎(chǔ)操作,所有這些操作的基礎(chǔ)是 region 定位。
region 定位基本步驟:
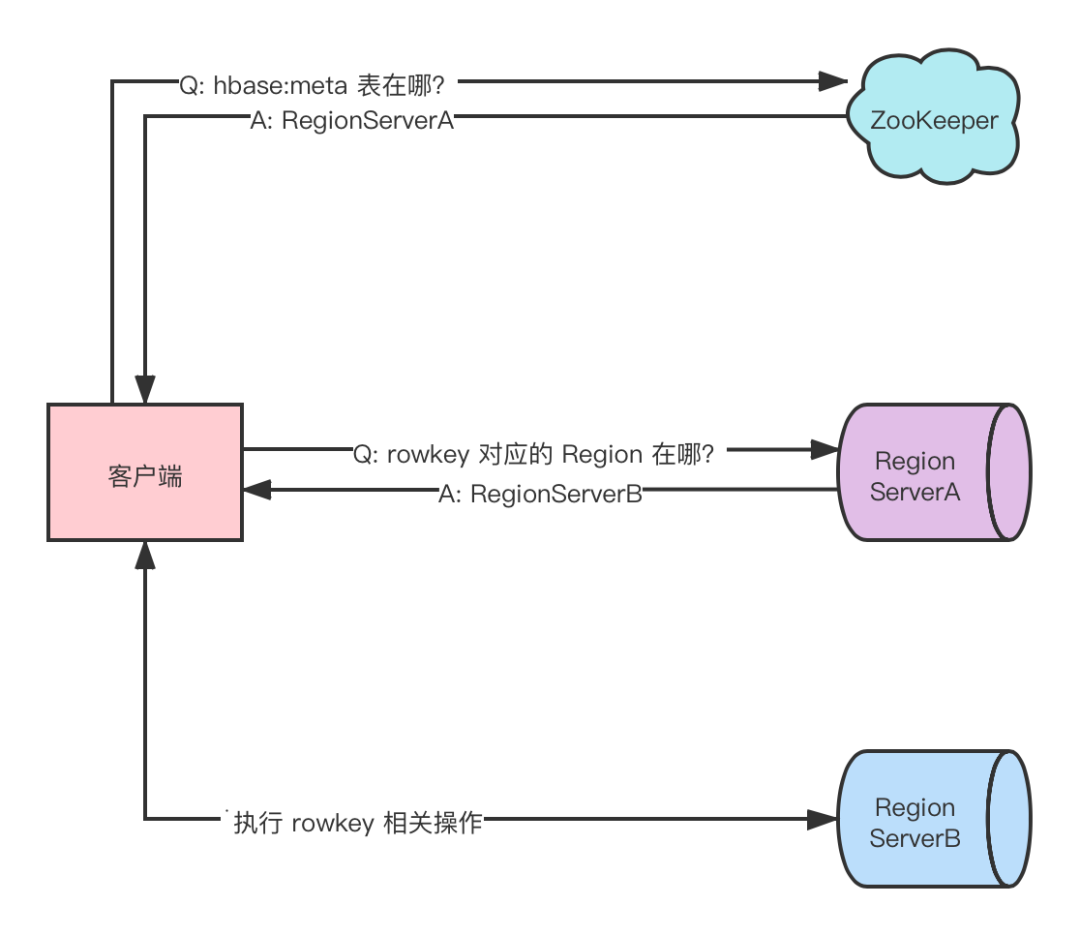
客戶端與 ZooKeeper 交互,查找 hbase:meta 系統(tǒng)表所在的 Regionserver。
hbase:meta 表維護(hù)了每個(gè)用戶表中 rowkey 區(qū)間與 Region 存放位置的映射關(guān)系,具體如下:
- rowkey : table name,start key,region id。
- value : RegionServer 對(duì)象(保存了 RegionServer 位置信息等)。
客戶端與 hbase:meta 系統(tǒng)表所在 RegionServer 交互,獲取 rowkey 所在的 RegionServer。
客戶端與 rowkey 所在的 RegionServer 交互,執(zhí)行該 rowkey 相關(guān)操作。
需要注意:
- 客戶端首次執(zhí)行讀寫(xiě)操作時(shí)才需要定位 hbase:meta 表的位置。
- 之后會(huì)將其緩存到本地,除非因 region 移動(dòng)導(dǎo)致緩存失效,客戶端才會(huì)重新讀取 hbase:meta 表位置,并更新緩存。
讀寫(xiě)流程
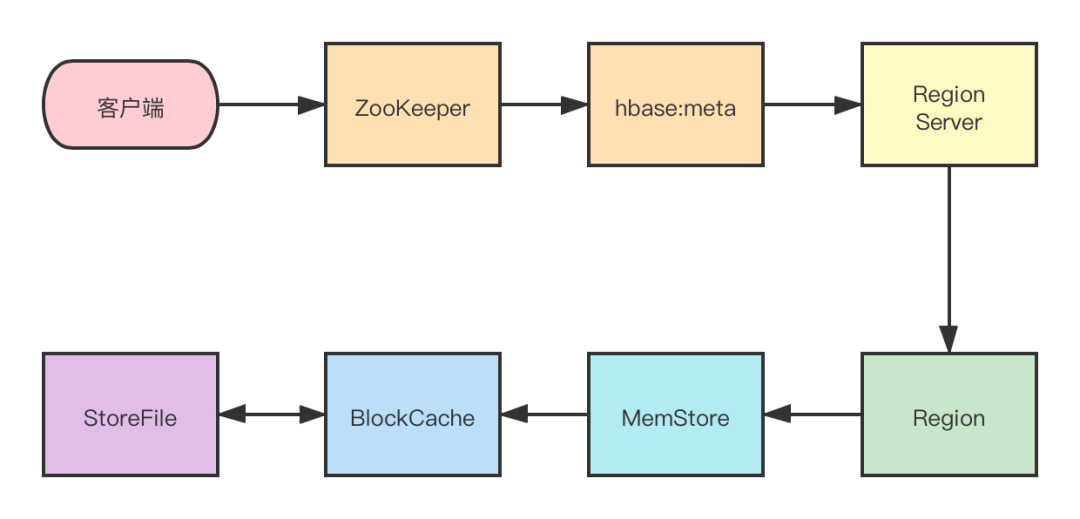
讀操作:
首先從 ZooKeeper 找到 meta 表的 region 位置,然后讀取hbase:meta 表中的數(shù)據(jù),hbase:meta 表中存儲(chǔ)了用戶表的 region 信息。
根據(jù)要查詢的 namespace 、表名和 rowkey 信息,找到寫(xiě)入數(shù)據(jù)對(duì)應(yīng)的 Region 信息。
找到這個(gè) Region 對(duì)應(yīng)的 RegionServer ,然后發(fā)送請(qǐng)求。
查找對(duì)應(yīng)的 Region。
先從 MemStore 查找數(shù)據(jù),如果沒(méi)有,再?gòu)?BlockCache 上讀取。
- HBase 上 RegionServer 的內(nèi)存分為兩個(gè)部分:
- 一部分作為 MemStore,主要用來(lái)寫(xiě)。
- 另外一部分作為 BlockCache,主要用于讀數(shù)據(jù)。
如果 BlockCache 中也沒(méi)有找到,再到 StoreFile(HFile) 上進(jìn)行讀取。
- 從 StoreFile 中讀取到數(shù)據(jù)之后,不是直接把結(jié)果數(shù)據(jù)返回給客戶端,而是把數(shù)據(jù)先寫(xiě)入到 BlockCache 中,目的是為了加快后續(xù)的查詢,然后在返回結(jié)果給客戶端。
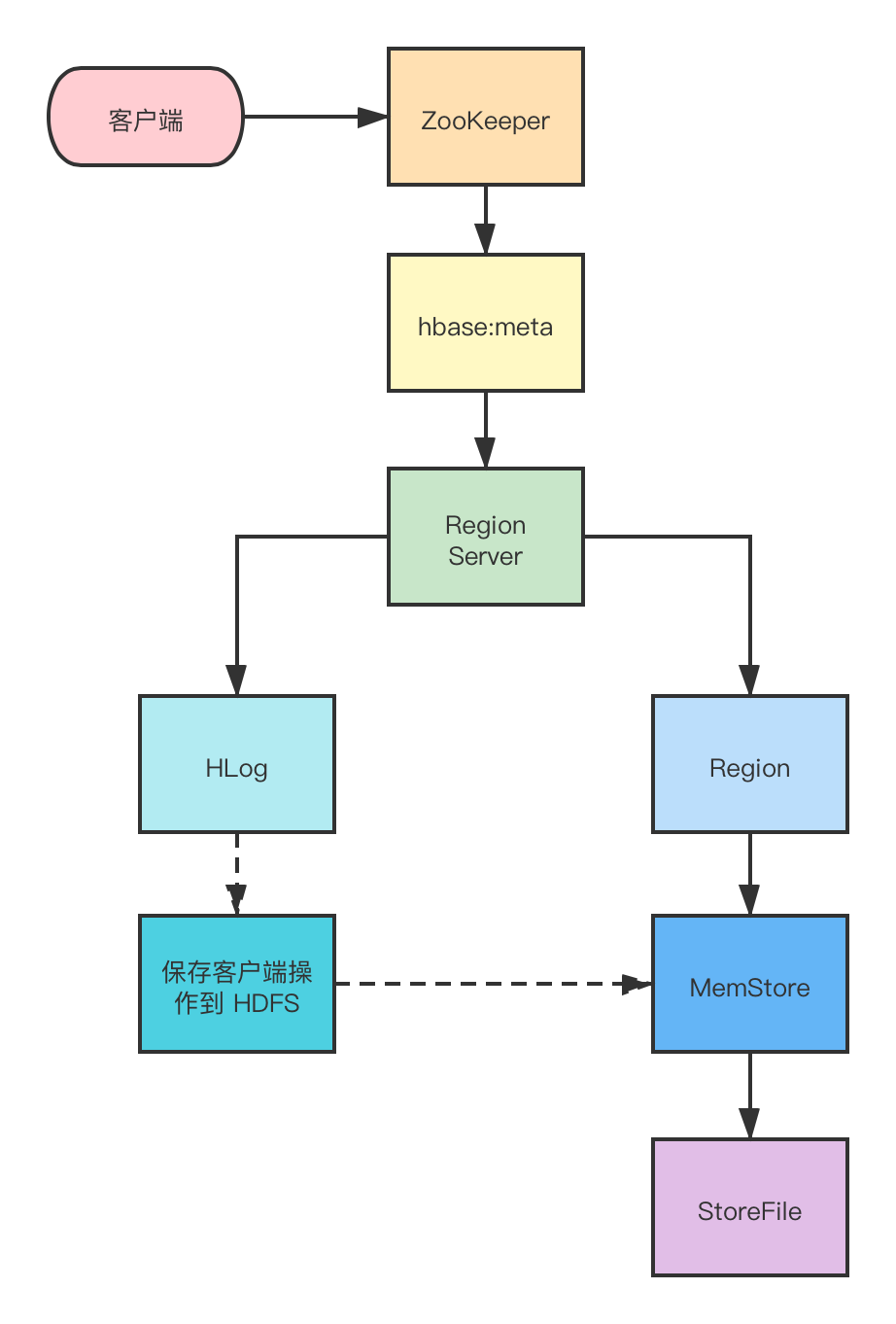
寫(xiě)操作:
首先從 ZooKeeper 找到 hbase:meta 表的 Region 位置,然后讀取 hbase:meta表中的數(shù)據(jù),hbase:meta 表中存儲(chǔ)了用戶表的 Region 信息。
根據(jù) namespace 、表名和 rowkey 信息找到寫(xiě)入數(shù)據(jù)對(duì)應(yīng)的 Region 信息。
找到這個(gè) Region 對(duì)應(yīng)的 RegionServer ,然后發(fā)送請(qǐng)求。
把數(shù)據(jù)分別寫(xiě)到 HLog (WriteAheadLog)和 MemStore 各一份。
MemStore 達(dá)到閾值后把數(shù)據(jù)刷到磁盤(pán),生成 StoreFile 文件。
刪除 HLog 中的歷史數(shù)據(jù)。
BulkLoad機(jī)制
用戶數(shù)據(jù)位于 HDFS 中,業(yè)務(wù)需要定期將這部分海量數(shù)據(jù)導(dǎo)入 HBase 系統(tǒng),以執(zhí)行隨機(jī)查詢更新操作。
這種場(chǎng)景如果調(diào)用寫(xiě)入 API 進(jìn)行處理,極有可能會(huì)給 RegionServer 帶來(lái)較大的寫(xiě)人壓力。
- 引起 RegionServer 頻繁 flush,進(jìn)而不斷 compact、split,影響集群穩(wěn)定性。
- 引起 RegionServer 頻繁GC,影響集群穩(wěn)定性。
- 消耗大量 CPU 資源、帶寬資源、內(nèi)存資源以及 IO 資源,與其他業(yè)務(wù)產(chǎn)生資源競(jìng)爭(zhēng)。
- 在某些場(chǎng)景下,比如平均 KV 大小比較大的場(chǎng)景,會(huì)耗盡 RegionServer 的處理線程, 導(dǎo)致集群阻塞。
所以HBase提供了另一種將數(shù)據(jù)寫(xiě)入HBase集群的方法:BulkLoad。
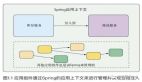
BulkLoad 首先使用 MapReduce 將待寫(xiě)入集群數(shù)據(jù)轉(zhuǎn)換為 HFile 文件,再直接將這些 HFile 文件加載到在線集群中。
BulkLoad 沒(méi)有將寫(xiě)請(qǐng)求發(fā)送給 RegionServer 處理,可以有效避免上述一系列問(wèn)題。
常見(jiàn)問(wèn)題
熱點(diǎn)問(wèn)題
什么是熱點(diǎn)?
檢索 HBase 的記錄首先要通過(guò)Row Key來(lái)定位數(shù)據(jù)行。
當(dāng)大量的 Client 訪問(wèn) HBase 集群的一個(gè)或少數(shù)幾個(gè)節(jié)點(diǎn),造成少數(shù) Region Server 的讀/寫(xiě)請(qǐng)求過(guò)多、負(fù)載過(guò)大,而其他Region Server 負(fù)載卻很小,就造成了 熱點(diǎn) 現(xiàn)象。
解決方案:
預(yù)分區(qū):
- 目的讓表的數(shù)據(jù)可以均衡的分散在集群中,而不是默認(rèn)只有一個(gè)Region分布在集群的一個(gè)節(jié)點(diǎn)上。
加鹽:
- 在Rowkey的前面增加隨機(jī)數(shù),具體就是給Rowkey分配一個(gè)隨機(jī)前綴以使得它和之前的Rowkey的開(kāi)頭不同。
哈希:
- 哈希會(huì)使同一行永遠(yuǎn)用一個(gè)前綴加鹽。
- 也可以使負(fù)載分散到整個(gè)集群,但是讀是可以預(yù)測(cè)的。
- 使用確定的哈希可以讓客戶端重構(gòu)完整的Rowkey,可以使用get操作準(zhǔn)確獲取某一個(gè)行數(shù)據(jù)。
反轉(zhuǎn):
- 反轉(zhuǎn)固定長(zhǎng)度或者數(shù)字格式的Rowkey。
- 這樣可以使得Rowkey中經(jīng)常改變的部分放在前面。