分布式基礎(chǔ) - ZAB協(xié)議&負載均衡策略
ZAB協(xié)議
- ZAB協(xié)議是為分布式協(xié)調(diào)服務(wù)Zookeeper專門設(shè)計的一種支持崩潰恢復(fù)的原子廣播協(xié)議,實現(xiàn)分布式數(shù)據(jù)一致性
- 所有客戶端的請求都是寫入到Leader進程中,然后,由Leader同步到其他節(jié)點,稱為Follower。在集群數(shù)據(jù)同步的過程中,如果出現(xiàn)Follower節(jié)點崩潰或者Leader進程崩潰時,都會通過Zab協(xié)議來保證數(shù)據(jù)一致性
ZAB協(xié)議的兩種模式
ZAB協(xié)議包括兩種基本的模式:消息廣播和崩潰恢復(fù)
消息廣播:
- 集群中所有的事務(wù)請求都由Leader節(jié)點來處理,其他服務(wù)器為Follower,Leader將客戶端的事務(wù)請求轉(zhuǎn)換為事務(wù)Proposal,并且將Proposal分發(fā)給集群中其他所有的Follower。
- 完成廣播之后,Leader等待Follwer反饋,當(dāng)有過半數(shù)的Follower反饋信息后,Leader將再次向集群內(nèi)Follower廣播Commit信息,Commit信息就是確認將之前的Proposal提交。
- Leader節(jié)點的寫入是一個兩步操作,第一步是廣播事務(wù)操作,第二步是廣播提交操作,其中過半數(shù)指的是反饋的節(jié)點數(shù)>=N/2+1,N是全部的Follower節(jié)點數(shù)量。
崩潰恢復(fù)
- 初始化集群,剛剛啟動的時候
- Leader崩潰,因為故障宕機的時候
- Leader失去了半數(shù)的機器支持,與集群中超過一半的節(jié)點斷連的時候
此時開啟新一輪Leader選舉,選舉產(chǎn)生的Leader會與過半的Follower進行同步,使數(shù)據(jù)一致,當(dāng)與過半的機器同步完成后,就退出恢復(fù)模式,然后進入消息廣播模式。
整個ZooKeeper集群的一致性保證就是在上面兩個狀態(tài)之前切換,當(dāng)Leader服務(wù)正常時,就是正常的消息廣播模式;當(dāng)Leader不可用時,則進入崩潰恢復(fù)模式,崩潰恢復(fù)階段會進行數(shù)據(jù)同步,完成以后,重新進入消息廣播階段。
Zxid是Zab協(xié)議的一個事務(wù)編號,Zxid是一個64位的數(shù)字,其中低32位是一個簡單的單調(diào)遞增計數(shù)器,針對客戶端每一個事務(wù)請求,計數(shù)器加1;而高32位則代表Leader周期年代的編號。
Leader周期(epoch),可以理解為當(dāng)前集群所處的年代或者周期,每當(dāng)有一個新的Leader選舉出現(xiàn)時,就會從這個Leader服務(wù)器上取出其本地日志中最大事務(wù)的Zxid,并從中讀取epoch值,然后加1,以此作為新的周期ID。高32位代表了每代Leader的唯一性,低32位則代表了每代Leader中事務(wù)的唯一性。
Zab節(jié)點的三種狀態(tài)
- following:服從leader的命令
- leading:負責(zé)協(xié)調(diào)事務(wù)
- election/looking:選舉狀態(tài)
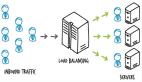
負載均衡策略有哪些
- 輪詢法
將請求按順序輪流地分配到后端服務(wù)器上,它均衡地對待后端的每一臺服務(wù)器,而不關(guān)心服務(wù)器實際的連接數(shù)和當(dāng)前的系統(tǒng)負載。
- 加權(quán)輪詢法
不同的后端服務(wù)器可能機器的配置和當(dāng)前系統(tǒng)的負載并不相同,因此它們的抗壓能力也不相同。給配置高、負載低的機器配置更高的權(quán)重,讓其處理更多的請;而配置低、負載高的機器,給其分配較低的權(quán)重,降低其系統(tǒng)負載,加權(quán)輪詢能很好地處理這一問題,并將請求順序且按照權(quán)重分配到后端。
- 隨機法
通過系統(tǒng)的隨機算法,根據(jù)后端服務(wù)器的列表大小值來隨機選取其中的一臺服務(wù)器進行訪問。由概率統(tǒng)計理論可以得知,隨著客戶端調(diào)用服務(wù)端的次數(shù)增多,其實際效果越來越接近于平均分配調(diào)用量到后端的每一臺服務(wù)器,也就是輪詢的結(jié)果。
- 加權(quán)隨機法
與加權(quán)輪詢法一樣,加權(quán)隨機法也根據(jù)后端機器的配置,系統(tǒng)的負載分配不同的權(quán)重。不同的是,它是按照權(quán)重隨機請求后端服務(wù)器,而非順序。
- 源地址哈希法
源地址哈希的思想是根據(jù)獲取客戶端的IP地址,通過哈希函數(shù)計算得到的一個數(shù)值,用該數(shù)值對服務(wù)器列表的大小進行取模運算,得到的結(jié)果便是客服端要訪問服務(wù)器的序號。采用源地址哈希法進行負載均衡,同一IP地址的客戶端,當(dāng)后端服務(wù)器列表不變時,它每次都會映射到同一臺后端服務(wù)器進行訪問。
- 最小連接數(shù)法
最小連接數(shù)算法比較靈活和智能,由于后端服務(wù)器的配置不盡相同,對于請求的處理有快有慢,它是根據(jù)后端服務(wù)器當(dāng)前的連接情況,動態(tài)地選取其中當(dāng)前積壓連接數(shù)最少的一臺服務(wù)器來處理當(dāng)前的請求,盡可能地提高后端服務(wù)的利用效率,將負責(zé)合理地分流到每一臺服務(wù)器。
分布式系統(tǒng)的設(shè)計目標(biāo)(分布式的好處)
- 可擴展性:通過對服務(wù)、存儲的擴展,來提高系統(tǒng)的處理能力,通過對多臺服務(wù)器協(xié)同工作,來完成單臺服務(wù)器無法處理的任務(wù),尤其是高并發(fā)或者大數(shù)據(jù)量的任務(wù)。
- 高可用:單點不影響整體,單點故障指系統(tǒng)中某個組件一旦失效,會讓整個系統(tǒng)無法工作
- 無狀態(tài):無狀態(tài)的服務(wù)才能滿足部分機器宕機不影響全部,可以隨時進行擴展的需求。
- 可管理:便于運維,出問題能不能及時發(fā)現(xiàn)定位
- 高可靠:同樣的請求返回同樣的數(shù)據(jù);更新能夠持久化;數(shù)據(jù)不會丟失