譯者 | 朱先忠
審校 | 重樓
背景
到目前為止,我們已經(jīng)看到了ChatGPT的能力及其所能提供的強大功能。然而,對于企業(yè)應(yīng)用來說,像ChatGPT這樣的封閉源代碼模型可能會帶來風(fēng)險,因為企業(yè)自身無法控制他們的數(shù)據(jù)。盡管OpenAI公司聲稱用戶數(shù)據(jù)不會被存儲或用于訓(xùn)練模型,但是這并不能保證數(shù)據(jù)不會以某種方式泄露。
為了解決與封閉源代碼模型相關(guān)的一些問題,研究人員正急于構(gòu)建與ChatGPT等模型競爭的開源大型語言模型(LLM)。有了開源模型,企業(yè)可以在安全的云環(huán)境中托管模型,從而降低數(shù)據(jù)泄露的風(fēng)險。最重要的是,你可以完全透明地了解模型的內(nèi)部工作,這有助于用戶與人工智能系統(tǒng)建立更多的信任關(guān)系。
隨著開源LLM的最新進展,人們很想嘗試新的模型,看看它們與ChatGPT等封閉源代碼模型的對比。
然而,如今運行開源模型還存在著巨大的障礙。例如,調(diào)用ChatGPT API要比了解如何運行開源LLM要容易得多。
在這篇文章中,我的目標是通過展示如何在類似生產(chǎn)的環(huán)境中在云中運行Falcon-7B模型這樣的開源模型來克服上述困難。最終,我們將能夠通過類似于ChatGPT的API端點方式來訪問這些模型。
挑戰(zhàn)
運行開源模型的一個重大挑戰(zhàn)是缺乏計算資源。即使是像Falcon-7B這樣的“小”模型也需要GPU才能運行。
為了解決這個問題,我們可以利用云中的GPU。但是,這又帶來了另一個挑戰(zhàn)。我們?nèi)绾螌LM進行容器化封裝呢?我們?nèi)绾螁⒂肎PU支持?啟用GPU支持可能很棘手,因為它需要CUDA的知識。使用CUDA可能會很痛苦,因為您必須弄清楚如何安裝正確的CUDA依賴項以及哪些版本是兼容的。
【譯者注】CUDA(Compute Unified Device Architecture),是顯卡廠商NVIDIA推出的運算平臺。CUDA?是一種由NVIDIA推出的通用并行計算架構(gòu),它包含了CUDA指令集架構(gòu)(ISA)以及GPU內(nèi)部的并行計算引擎。開發(fā)人員可以使用C、C++和FORTRAN語言來為CUDA?架構(gòu)編寫程序。
因此,為了避開CUDA的死亡陷阱,許多公司已經(jīng)創(chuàng)建了解決方案,可以在支持GPU的同時輕松地將模型容器化封裝。在這篇博客文章中,我們將使用一個名為Truss的開源工具來幫助我們輕松地將LLM容器化,而不會帶來太多麻煩。
Truss允許開發(fā)人員輕松地將使用任何框架構(gòu)建的模型進行容器化封裝。
為什么使用Truss?
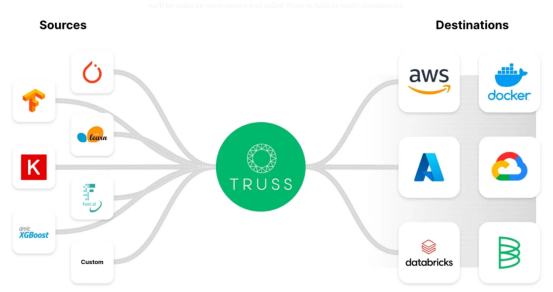 Truss — https://truss.baseten.co/e2e。
Truss — https://truss.baseten.co/e2e。
Truss有很多現(xiàn)成的有用功能,例如:
- 將Python模型轉(zhuǎn)換為具有生產(chǎn)就緒API端點的微服務(wù)
- 通過Docker凍結(jié)依賴關(guān)系
- 支持GPU推理
- 模型的簡單預(yù)處理和后處理
- 輕松安全的秘密管理
我以前用過Truss來部署機器學(xué)習(xí)模型,這個過程非常順利和簡單。Truss自動創(chuàng)建dockerfile并管理Python依賴項。我們所要做的就是為我們的模型提供代碼。
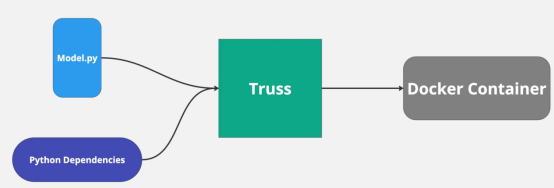
其實,我們想使用像Truss這樣的工具的主要原因是,借助GPU支持可以使部署我們的模型變得更加容易。
計劃
以下是我將在這篇博客文章中介紹的主要內(nèi)容:
- 使用Truss在本地設(shè)置Falcon 7B
- 如果你有GPU(我有RTX 3080),請在本地運行模型
- 容器化模型并使用Docker運行它
- 在谷歌云中創(chuàng)建一個支持GPU的Kubernetes集群來運行我們的模型
不過,不要擔(dān)心,如果步驟2沒有GPU,您仍然可以在云端運行模型。
以下是Github代碼倉庫地址,其中包含本文后面描述中所有有關(guān)代碼(如果您想繼續(xù)閱讀的話):
https://github.com/htrivedi99/falcon-7b-truss
讓我們開始吧!
步驟1:使用Truss進行Falcon 7B本地設(shè)置
首先,我們需要創(chuàng)建一個Python版本≥3.8的項目。
然后,我們將從HuggingFace官網(wǎng)下載模型,并使用Truss進行包裝。以下是我們需要安裝的依賴項:
pip install truss然后,在Python項目中創(chuàng)建一個名為main.py的腳本。這是一個臨時腳本,我們將使用它來處理Truss。
接下來,我們將通過在終端中運行以下命令來設(shè)置Truss軟件包:
truss init falcon_7b_truss如果提示您創(chuàng)建新的Truss,請按“y”。完成后,您應(yīng)該會看到一個名為falcon_7b_truss的新目錄。在該目錄中,將有一些自動生成的文件和文件夾。我們需要填寫以下幾項:model.py,它位于model文件夾下,也被文件config.yaml所引用。

正如我之前提到的,Truss只需要我們模型的代碼,它會自動處理所有其他事情。我們將在model.py中編寫代碼,但它必須以特定的格式編寫。
Truss希望每個模型至少支持三個功能:__init__、load和predict。
- __init__主要用于創(chuàng)建類變量
- load是我們從HuggingFace官網(wǎng)下載模型的地方
- predict是我們調(diào)用模型的地方以下是model.py的完整代碼:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from typing import Dict
MODEL_NAME = "tiiuae/falcon-7b-instruct"
DEFAULT_MAX_LENGTH = 128
class Model:
def __init__(self, data_dir: str, config: Dict, **kwargs) -> None:
self._data_dir = data_dir
self._config = config
self.device = "cuda" if torch.cuda.is_available() else "cpu"
print("THE DEVICE INFERENCE IS RUNNING ON IS: ", self.device)
self.tokenizer = None
self.pipeline = None
def load(self):
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model_8bit = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
device_map="auto",
load_in_8bit=True,
trust_remote_code=True)
self.pipeline = pipeline(
"text-generation",
model=model_8bit,
tokenizer=self.tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
def predict(self, request: Dict) -> Dict:
with torch.no_grad():
try:
prompt = request.pop("prompt")
data = self.pipeline(
prompt,
eos_token_id=self.tokenizer.eos_token_id,
max_length=DEFAULT_MAX_LENGTH,
**request
)[0]
return {"data": data}
except Exception as exc:
return {"status": "error", "data": None, "message": str(exc)}這里發(fā)生了什么:
- MODEL_NAME是我們將要使用的模型,在我們的案例中是falcon-7b-instruct模型
- 在load內(nèi)部,我們從HuggingFace官網(wǎng)下載8位的模型。我們想要8位的原因是,當量化時,該模型在GPU上使用的內(nèi)存明顯更少。
- 此外,如果您想在低于13GB VRAM的GPU上本地運行模型,則需要以8位加載模型。
- predict函數(shù)接受JSON請求作為參數(shù),并使用self.pipeline調(diào)用模型。torch.no_grad告訴Pytorch我們處于推理模式,而不是訓(xùn)練模式。很酷吧!這就是我們設(shè)置模型所需要的全部內(nèi)容。
步驟2:在本地運行模型(可選)
如果你有一個擁有超過8GB VRAM的英偉達GPU,那么,你能夠在本地運行該模型。
如果沒有,請繼續(xù)下一步。
我們需要下載更多的依賴項才能在本地運行模型。在下載依賴項之前,您需要確保安裝了CUDA和正確的CUDA驅(qū)動程序。
因為我們試圖在本地運行模型,所以Truss無法幫助我們管理CUDA的強大功能。
pip install transformers
pip install torch
pip install peft
pip install bitsandbytes
pip install einops
pip install scipy 接下來,在falcon_7b_truss目錄外創(chuàng)建的腳本main.py中,我們需要加載我們的Truss。
以下是main.py的代碼:
import truss
from pathlib import Path
import requests
tr = truss.load("./falcon_7b_truss")
output = tr.predict({"prompt": "Hi there how are you?"})
print(output)這里發(fā)生了什么:
- 如果您還記得的話,falcon_7b_truss目錄是由Truss自動創(chuàng)建的。我們可以使用truss.load加載整個包,包括模型和依賴項
- 一旦我們加載了我們的包,我們就可以簡單地調(diào)用predict方法來獲得模型輸出運行main.py即可從模型中獲取輸出。此模型文件的大小約為15 GB,因此下載該模型可能需要5-10分鐘。運行腳本后,您應(yīng)該會看到這樣的輸出:
? {'data': {'generated_text': "Hi there how are you?\nI'm doing well. I'm in the middle of a move, so I'm a bit tired. I'm also a bit overwhelmed. I'm not sure how to get started. I'm not sure what I'm doing. I'm not sure if I'm doing it right. I'm not sure if I'm doing it wrong. I'm not sure if I'm doing it at all.\nI'm not sure if I'm doing it right. I'm not sure if I'm doing it wrong. I"}}步驟3:使用Docker封裝模型
通常,當人們將模型容器化封裝時,他們會獲取模型二進制文件和Python依賴項,并使用Flask或Fast API服務(wù)器將其打包。
很多都是樣板化操作,我們不必自己費事。Truss會自動處理這些任務(wù)。我們已經(jīng)提供了模型,Truss將創(chuàng)建服務(wù)器,所以剩下的唯一要做的就是提供Python依賴項。
config.yaml保存了我們模型的配置。這就是我們可以為模型添加依賴項的地方。配置文件已經(jīng)提供了我們需要的大部分內(nèi)容,但我們還需要添加一些內(nèi)容。
以下是您需要添加到config.yaml中的內(nèi)容:
apply_library_patches: true
bundled_packages_dir: packages
data_dir: data
description: null
environment_variables: {}
examples_filename: examples.yaml
external_package_dirs: []
input_type: Any
live_reload: false
model_class_filename: model.py
model_class_name: Model
model_framework: custom
model_metadata: {}
model_module_dir: model
model_name: Falcon-7B
model_type: custom
python_version: py39
requirements:
- torch
- peft
- sentencepiece
- accelerate
- bitsandbytes
- einops
- scipy
- git+https://github.com/huggingface/transformers.git
resources:
use_gpu: true
cpu: "3"
memory: 14Gi
secrets: {}
spec_version: '2.0'
system_packages: []所以,我們添加的主要內(nèi)容都圍繞著需求進行。所有列出的依賴項都是下載和運行模型所必需的。
我們增加的另一件重要的事情是資源(resources)。use_gpu:true非常重要,因為這告訴Truss在啟用GPU支持的情況下為我們創(chuàng)建一個Dockerfile。這是用于配置任務(wù)的。
下一步,我們將對我們的模型進行容器化封裝。如果您不知道如何使用Docker將模型封裝,不要擔(dān)心,Truss已經(jīng)為您提供了服務(wù)。
在main.py文件中,我們將告訴Truss將所有內(nèi)容打包在一起。以下是您需要的代碼:
import truss
from pathlib import Path
import requests
tr = truss.load("./falcon_7b_truss")
command = tr.docker_build_setup(build_dir=Path("./falcon_7b_truss"))
print(command)發(fā)生了什么:
- 首先,我們加載falcon_7b_truss。
- 接下來,docker_build_setup函數(shù)處理所有復(fù)雜的事情,比如創(chuàng)建Dockerfile和設(shè)置Fast API服務(wù)器。
- 如果您查看您的falcon_7b_truss目錄,您會看到生成了更多的文件。我們不需要擔(dān)心這些文件是如何工作的,因為它們都將在幕后進行管理。
- 在運行結(jié)束時,我們得到一個Docker命令來構(gòu)建我們的Docker映像:
docker build falcon_7b_truss -t falcon-7b-model:latest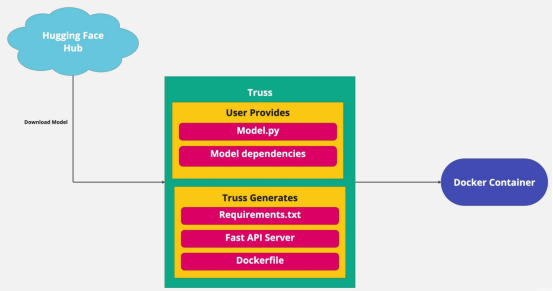
如果您想構(gòu)建Docker鏡像,請繼續(xù)運行build命令。該映像的大小約為9 GB,因此可能需要一段時間才能構(gòu)建完成。如果你不想構(gòu)建它,但想一直閱讀下去的話,你可以詳細觀察我提供的圖片:
htrivedi05/truss-falcon-7b:latest .如果您自己構(gòu)建映像的話,則需要對其進行標記并將其推送到dockerhub,以便我們在云中的容器可以提取圖像。以下是構(gòu)建映像后需要運行的命令:
docker tag falcon-7b-model <docker_user_id>/falcon-7b-model
docker push <docker_user_id>/falcon-7b-model令人驚嘆的是,到目前我們已經(jīng)準備好在云中運行我們的模型了!
【說明】以下可選步驟(到步驟4前)用于使用GPU在本地運行圖像。
如果您有Nvidia GPU,并且希望在本地運行帶有GPU支持的容器化模型,則需要確保Docker配置為使用您的GPU。
為此,只需要您打開終端并運行以下命令:
distributinotallow=$(. /etc/os-release;echo $ID$VERSION_ID) && curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
apt-get update
apt-get install -y nvidia-docker2
sudo systemctl restart docker現(xiàn)在,您的Docker已配置為訪問GPU,下面是如何運行容器的命令:
docker run --gpus all -d -p 8080:8080 falcon-7b-model同樣,下載該模型需要一段時間。為了確保一切正常工作,你可以檢查容器日志,你應(yīng)該看到“設(shè)備推理正在is:cuda上運行(THE DEVICE INFERENCE IS RUNNING ON IS: cuda)”。
您可以通過API端點對模型進行調(diào)用,如下所示:
import requests
data = {"prompt": "Hi there, how's it going?"}
res = requests.post("http://127.0.0.1:8080/v1/models/model:predict", jsnotallow=data)
print(res.json())步驟4:將模型部署到生產(chǎn)環(huán)境中
我在這里使用“生產(chǎn)”這個詞算是相當松散的表達方式。我們將在Kubernetes中運行我們的模型,因為在此環(huán)境里可以輕松地擴展和處理可變數(shù)量的流量。
話雖如此,Kubernetes提供了很多配置,如網(wǎng)絡(luò)策略、存儲、配置映射、負載平衡、機密管理等。
盡管Kubernetes是為“擴展”和運行“生產(chǎn)”工作負載而構(gòu)建的,但您需要的許多生產(chǎn)級配置并不是現(xiàn)成可用的。涵蓋那些高級的Kubernetes主題的討論超出了本文的范圍,也偏離了我們在這里試圖實現(xiàn)的目標。因此,對于這篇博客文章,我們將創(chuàng)建一個基礎(chǔ)類型的最小集群。
事不宜遲,讓我們抓緊著手創(chuàng)建我們的集群!
先決條件:
- 擁有創(chuàng)建了一個項目的對應(yīng)的谷歌云端賬戶
- 在您的計算機上安裝成功gcloud CLI
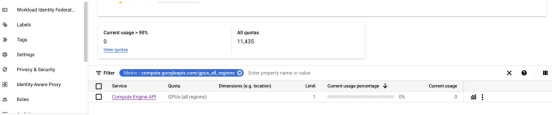
- 請確保您有足夠的配額來運行啟用GPU的計算機。您可以在“IAM & Admin”命令組下檢查您的配額。
創(chuàng)建我們的GKE集群
我們將使用谷歌的Kubernetes引擎來創(chuàng)建和管理我們的集群。下面了解一些重要信息:
谷歌的Kubernetes引擎不是免費的。谷歌不會允許我們免費使用功能強大的GPU。話雖如此,我們正在創(chuàng)建一個功能較弱的GPU的單節(jié)點集群。這個實驗的花費不應(yīng)該超過1到2美元。
以下是我們將要運行的Kubernetes集群的配置:
- 1個節(jié)點,標準Kubernetes集群
- 1個Nvidia T4 GPU
- n1-standard-4機器(4 vCPU,15GB內(nèi)存)
- 所有這些都將在一個Spot實例上運行
注意:如果您在另一個地區(qū),并且無法訪問完全相同的資源,請隨時進行修改。
創(chuàng)建集群的步驟:
1.前往谷歌云控制臺,搜索名為Kubernetes Engine的服務(wù):
2.單擊“創(chuàng)建(CREATE)”按鈕:
- 確保您正在創(chuàng)建一個標準集群,而不是自動駕駛(autopilot)型集群。它應(yīng)該在頁面頂部顯示“創(chuàng)建一個Kubernetes集群(Create a kubernetes cluster)”。
3.集群基礎(chǔ):
- 在“集群基礎(chǔ)(Cluster basics)”選項卡中,我們不想做太多更改。只需給集群一個名稱。您不需要更改區(qū)域或控制平面。
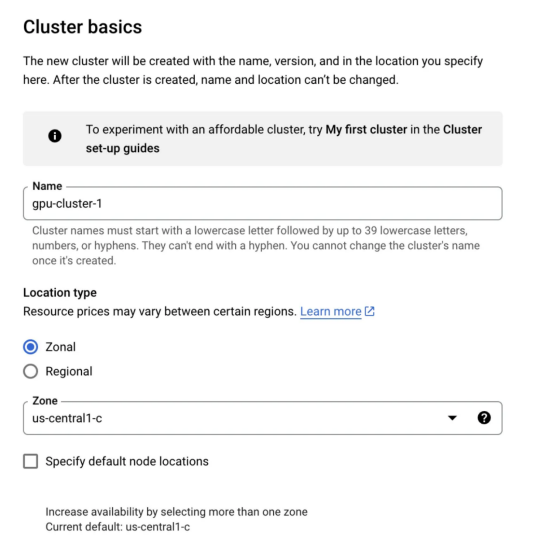
4.單擊“默認池(default-pool)”選項卡并將節(jié)點數(shù)更改為1。
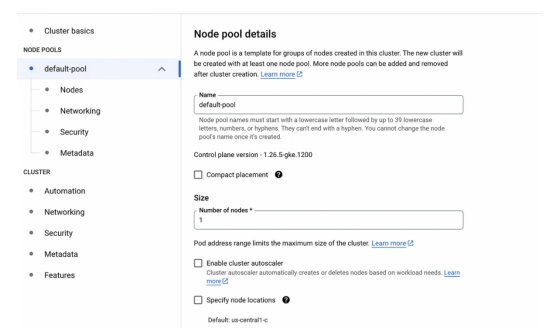
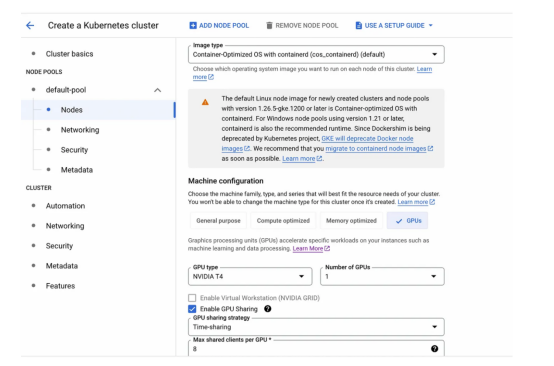
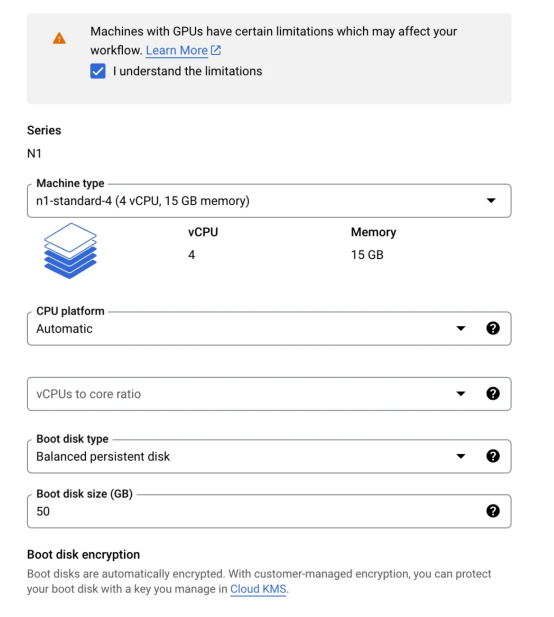
5.在“默認池(default-pool)”選項卡下,單擊左側(cè)邊欄中的“節(jié)點(Nodes)”選項卡:
- 將機器配置(General purpose)從通用更改為GPU
- 選擇英偉達T4作為GPU類型,并將數(shù)量設(shè)置1
- 啟用GPU分時消費(Time-sharing)方式(即使我們不會使用此功能)
- 將每個GPU的最大共享客戶端數(shù)設(shè)置為8
- 對于機器類型,選擇n1-standard-4(4 vCPU,15 GB內(nèi)存)
- 將引導(dǎo)磁盤大小更改為50
- 向下滾動到最底部,選中上面寫著:啟用現(xiàn)場虛擬機上的節(jié)點(Enable nodes on spot VMs)
配置好集群后,繼續(xù)往下進行,創(chuàng)建此群集。
谷歌需要幾分鐘的時間來設(shè)置一切。在您的集群啟動并運行后,我們需要連接到此群集。為此,打開您的終端并運行以下命令:
gcloud config set compute/zone us-central1-c
gcloud container clusters get-credentials gpu-cluster-1如果您使用了不同的集群名稱區(qū)域,請相應(yīng)地更新這些區(qū)域。要檢查我們是否已連接,請運行以下命令:
kubectl get nodes您應(yīng)該看到1個節(jié)點出現(xiàn)在您的終端中。盡管我們的集群有GPU,但它缺少一些我們必須安裝的Nvidia驅(qū)動程序。值得慶幸的是,安裝它們是一件很容易的事情。運行以下命令即可安裝驅(qū)動程序:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml慶祝一下吧,我們終于準備好部署我們的模型了。
部署模型
為了將我們的模型部署到集群上,我們需要創(chuàng)建一個Kubernetes部署。Kubernetes部署允許我們管理容器化模型的實例。在此,我不會深入討論Kubernetes或如何編寫yaml文件,因為這超出了本文主題的范圍。
您需要創(chuàng)建一個名為truss-falcon-deployment.yaml的文件。打開該文件并粘貼以下內(nèi)容:
apiVersion: apps/v1
kind: Deployment
metadata:
name: truss-falcon-7b
namespace: default
spec:
replicas: 1
selector:
matchLabels:
component: truss-falcon-7b-layer
template:
metadata:
labels:
component: truss-falcon-7b-layer
spec:
containers:
- name: truss-falcon-7b-container
image: <your_docker_id>/falcon-7b-model:latest
ports:
- containerPort: 8080
resources:
limits:
nvidia.com/gpu: 1
---
apiVersion: v1
kind: Service
metadata:
name: truss-falcon-7b-service
namespace: default
spec:
type: ClusterIP
selector:
component: truss-falcon-7b-layer
ports:
- port: 8080
protocol: TCP
targetPort: 8080發(fā)生了什么:
- 我們告訴Kubernetes,我們想用我們的falcon-7b-model映像創(chuàng)建pods。確保將<your_docker_id>替換為實際id。如果您沒有創(chuàng)建自己的Docker映像,而想使用我的,請將其替換為以下內(nèi)容:htrivedi05/truss-falcon-7b:latest。
- 我們通過設(shè)置資源限制nvidia.com/GPU:1來啟用容器的GPU訪問。這告訴Kubernetes只為我們的容器請求一個GPU。
- 為了與我們的模型交互,我們需要創(chuàng)建一個將在8080端口上運行的Kubernetes服務(wù)。
通過在終端中運行以下命令來創(chuàng)建部署:
kubectl create -f truss-falcon-deployment.yaml如果運行該命令:
kubectl get deployments你應(yīng)該看到類似下面這樣的顯示內(nèi)容:
NAME READY UP-TO-DATE AVAILABLE AGE
truss-falcon-7b 0/1 1 0 8s部署將需要幾分鐘時間才能更改為就緒狀態(tài)。記住,每次容器重新啟動時,模型都必須從HuggingFace頁面下載。您可以通過運行以下命令來檢查容器的進度:
kubectl get pods
kubectl logs truss-falcon-7b-8fbb476f4-bggts相應(yīng)地更改吊艙名稱。
您需要在日志中查找以下內(nèi)容:
- 查找打印語句THE DEVICE INFERENCE IS RUNNING ON IS: cuda。這確認了我們的容器已正確連接到GPU。
接下來,您應(yīng)該看到一些關(guān)于正在下載的模型文件的打印語句。
Downloading (…)model.bin.index.json: 100%|██████████| 16.9k/16.9k [00:00<00:00, 1.92MB/s]
Downloading (…)l-00001-of-00002.bin: 100%|██████████| 9.95G/9.95G [02:37<00:00, 63.1MB/s]
Downloading (…)l-00002-of-00002.bin: 100%|██████████| 4.48G/4.48G [01:04<00:00, 69.2MB/s]
Downloading shards: 100%|██████████| 2/2 [03:42<00:00, 111.31s/it][01:04<00:00, 71.3MB/s]下載模型并創(chuàng)建微服務(wù)后,您應(yīng)該在日志末尾看到以下輸出:
{"asctime": "2023-06-29 21:40:40,646", "levelname": "INFO", "message": "Completed model.load() execution in 330588 ms"}根據(jù)此消息,我們可以確認模型已加載并準備好進行推理任務(wù)了。
模型推理
我們不能直接調(diào)用模型;相反,我們必須調(diào)用模型的服務(wù)。
運行以下命令即可獲取服務(wù)的名稱:
kubectl get svc輸出結(jié)果如下:
AME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.80.0.1 <none> 443/TCP 46m
truss-falcon-7b-service ClusterIP 10.80.1.96 <none> 8080/TCP 6m19s我們想調(diào)用的是truss-falcon-7b服務(wù)。為了使服務(wù)可訪問,我們需要使用以下命令將其端口轉(zhuǎn)發(fā):
kubectl port-forward svc/truss-falcon-7b-service 8080輸出如下:
Forwarding from 127.0.0.1:8080 -> 8080
Forwarding from [::1]:8080 -> 8080很漂亮,我們的模型在127.0.0.1:8080作為REST API端點提供。打開任何一個Python腳本,如main.py,并運行以下代碼:
import requests
data = {"prompt": "Whats the most interesting thing about a falcon?"}
res = requests.post("http://127.0.0.1:8080/v1/models/model:predict", jsnotallow=data)
print(res.json())輸出如下:
{'data': {'generated_text': 'Whats the most interesting thing about a falcon?\nFalcons are known for their incredible speed and agility in the air, as well as their impressive hunting skills. They are also known for their distinctive feathering, which can vary greatly depending on the species.'}}哇!我們已經(jīng)成功地將Falcon 7B模型容器化,并將其作為生產(chǎn)中的微服務(wù)成功部署!
您可以隨意使用不同的提示來查看模型返回的內(nèi)容。
關(guān)閉集群
一旦你在Falcon 7B上玩得很開心,你可以通過運行以下命令刪除你的部署:
kubectl delete -f truss-falcon-deployment.yaml接下來,轉(zhuǎn)到谷歌云中的Kubernetes引擎,刪除Kubernete集群。
注:除非另有說明;否則,本文中所有圖片均由作者本人提供。
結(jié)論
盡管運行和管理像ChatGPT這樣的生產(chǎn)級模型并不容易;但是,隨著時間的推移,開發(fā)人員可以更好地將自己的模型部署到云中。
在這篇博客文章中,我們談到了在基本層級上將LLM部署到生產(chǎn)中所需的所有內(nèi)容。歸納起來,我們首先需要使用Truss打包模型,然后使用Docker將其容器化,最后使用Kubernetes將其部署在云中。我知道要作詳細介紹會涉及到很多內(nèi)容,雖然這不是世界上最容易做的事情,但我們還是做到了。
最后,我希望你能從這篇博文中學(xué)到一些有趣的東西。感謝閱讀!
譯者介紹
朱先忠,51CTO社區(qū)編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Deploying Falcon-7B Into Production,作者:Het Trivedi