一種基于布隆過濾器的大表計算優化方法
問題背景
在大數據行業內,尤其是數倉建設中,一直有一個繞不開的難題,就是大表的分析計算(這里的大表指億級以上)。特別是大表之間的 Join 分析,對任何公司數據部門都是一個挑戰!
主要有以下挑戰:
- 由于數據量大,分析計算時會耗費更多 CPU、內存和 IO,占用大量的集群資源。
- 由于數據量大,分析計算過程緩慢,擠占其它任務資源使用,從而影響數倉整體任務產出時間。
- 由于數據量大,長時間占用資源,會造成該任務在時間、資源和財務各方面成本巨大。
當前業內流行的優化方案
1.增加集群資源
優點:簡單粗暴,對業務和數據開發人員友好,不用調整。
缺點:費錢,看你公司是否有錢。
2.采用增量計算
優點:可以在不大幅增加計算集群成本的情況下,完成日常計算任務。
缺點:對數據和業務都有一定要求,數據一般要求是日志類數據。或者具有一定的生命周期數據(歷史數據可歸檔)。
問題場景和 Spark 算法分析
Spark 經典算法 SortMergeJoin(以大表間的 Join 分析為例)。
- 對兩張表分別進行 Shuffle 重分區,之后將相同Key的記錄分到對應分區,每個分區內的數據在 Join 之前都要進行排序,這一步對應 Exchange 節點和 Sort 節點。也就是 Spark 的 Sort Merge Shuffle 過程。
- 遍歷流式表,對每條記錄都采用順序查找的方式從查找表中搜索,每遇到一條相同的 Key 就進行 Join 關聯。每次處理完一條記錄,只需從上一次結束的位置開始繼續查找。
該算法也可以簡化流程為: Map 一> Shuffle 一> Sort 一> Merge 一> Reduce

該算法的性能瓶頸主要在 Sort Merge Shuffle 階段(紅色流程部分),數據量越大,資源要求越高,性能越低。
大表問題思考
大數據計算優化思路,核心無非就三條:增加計算資源;減少被計算數據量;優化計算算法。其中前兩條是我們普通人最常用的方法。
兩個大表的 Join ,是不是真的每天都有大量的數據有變更呢?如果是的話,那我們的業務就應該思考一下是否合理了。
其實在我們的日常實踐場景中,大部分是兩個表里面的數據每天只有少量(十萬百萬至千萬級)數據隨機變化,大部分數據是不變的。
說到這里,很多人的第一想法是,我們增加分區,按數據是否有變化進行區分,計算有變化的(今日有更新的業務數據),合并未變化的(昨日計算完成的歷史數據),不就可以解決問題了。其實這個想法存在以下問題:
- 由于每個表的數據是隨機變化的,那就存在,第一個表中變化的數據在第二個表中是未變的,反之亦然(見圖片示例)。并且可能后續計算還有第三個表、第四個表等等呢?這種分區是難以構建的。
- 變化的數據如果是百萬至千萬級,那這里也是一個較大規模的數據量了,既要關聯計算變化的,也要關聯計算未變化的,這里的計算成本也很大。
 圖片
圖片
問題讀到這里,如果我們分別把表 A、表 B 的有變化記錄的關聯主鍵取出來合并在一起,形成一個數組變量。計算的時候用這個變量分別從表 A 和表 B 中過濾出有變化的數據進行計算,并從未變化的表(昨日計算完成的歷史數據)中過濾出不存在的(即未變化歷史結果數據)。這樣兩份數據簡單合并到一起,不就是表 A 和表 B 全量 Join 計算的結果了嗎!
那什么樣的數組可以輕易的存下這百萬千萬級的數據量呢?我們第一個想到的答案: 布隆過濾器!
使用布隆過濾器的優化方案
- 構建布隆過濾器:分別讀取表 A 和表 B 中有變化的數據的關聯主鍵。
- 使用布隆過濾器:分別過濾表 A 和表 B 中的數據(即關聯主鍵命中布隆過濾器),然后進行 join 分析。
- 使用布隆過濾器:從未變化的表(昨日計算完成的歷史數據)中過濾出數據(即沒有命中布隆過濾器)。
- 合并 2、 3 步驟的數據結果。
也許這里有人會有疑惑,不是說布隆過濾器是命中并不代表一定存在,不命中才代表一定不存在!其實這個命中不代表一定存在,是一個極少量概率問題,即極少量沒有更新的數據也會命中布隆過濾器,從而參與了接下來的數據計算,實際上只要所有變化的數據能命中即可。這個不影響它已經幫我買過濾了絕大部分不需要計算的數據。
回看我們的 Spark 經典算法 SortMergeJoin,我們可以看出,該方案是在 Map 階段就過濾了數據,大大減少了數據量的,提升了計算效率,減少了計算資源使用!
Spark 函數 Java 代碼實現
大家可以根據需要參考、修改和優化,有更好的實現方式歡迎大家分享交流。
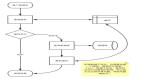
程序流程圖
 圖片
圖片
Spark 函數 Java 代碼實現。
package org.example;
import org.apache.curator.shaded.com.google.common.hash.BloomFilter;
import org.apache.curator.shaded.com.google.common.hash.Funnels;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.spark.sql.api.java.*;
import org.apache.spark.SparkConf;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.util.concurrent.ConcurrentHashMap;
import org.apache.lucene.util.RamUsageEstimator;
/**
* add by chengwansheng
*/
class MyBloomFilter {
private BloomFilter bloomFilter;
public MyBloomFilter(BloomFilter b) {
bloomFilter = b;
}
public BloomFilter getBloomFilter() {
return bloomFilter;
}
}
public class BloomUdf implements UDF2<Object, String, Boolean> {
//最大記錄限制,安全起見
private static int maxSize = 50000000;
//布隆過濾器是否開啟配置, 1 開啟,0 關閉
private static int udfBloomFilterEnable;
//布隆過濾器是否開啟參數,默認開啟
private static String bloomFilterConfKey = "spark.myudf.bloom.enable";
//加配置配置參數,目前不起作用??
static {
SparkConf sparkConf = new SparkConf();
udfBloomFilterEnable = sparkConf.getInt(bloomFilterConfKey, 1);
System.out.println("the spark.myudf.bloom.enable value " + udfBloomFilterEnable);
}
//布隆過濾器列表,支持多個布隆過濾器
private static ConcurrentHashMap<String, MyBloomFilter> bloomFilterMap = new ConcurrentHashMap<>();
/**
* 布隆過濾器核心構建方法
* 通過讀取表的 hdfs 文件信息,構建布隆過濾器
* 一個 jvm 只加載一次
* @param key
* @param path
* @throws IOException
*/
private synchronized static void buildBloomFilter(String key, String path) throws IOException {
if (!bloomFilterMap.containsKey(key)) {
BloomFilter bloomFilter;
Configuration cnotallow=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path pathDf=new Path(path);
FileStatus[] stats=hdfs.listStatus(pathDf);
//獲取記錄總數
long sum = 0;
for (int i=0; i<stats.length; i++){
InputStream inputStream=hdfs.open(stats[i].getPath());
InputStreamReader inputStreamReader= new InputStreamReader(inputStream);
BufferedReader reader=new BufferedReader(inputStreamReader);
sum = sum + reader.lines().count();
}
if(sum > maxSize) {
//如果數據量大于期望值,則將布隆過濾器置空(即布隆過濾器不起作用)
System.out.println("the max number is " + maxSize + ", but target num is too big, the " + key + " bloom will be invalid");
bloomFilter = null;
} else {
//默認 1000 W,超過取樣本數據 2 倍的量。這里取 2 倍是為了提高布隆過濾器的效果, 2 倍是一個比較合適的值
long exceptSize = sum*2>10000000?sum*2:10000000;
bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), (int) exceptSize);
for (int i=0; i<stats.length; i++){
//打印每個文件路徑
System.out.println(stats[i].getPath().toString());
//讀取每個文件
InputStream inputStream=hdfs.open(stats[i].getPath());
InputStreamReader inputStreamReader= new InputStreamReader(inputStream);
BufferedReader reader=new BufferedReader(inputStreamReader);
String line="";
while((line=reader.readLine())!=null){
bloomFilter.put(line);
}
}
}
MyBloomFilter myBloomFilter = new MyBloomFilter(bloomFilter);
bloomFilterMap.put(key, myBloomFilter);
System.out.println("the bloom " + key + " size is " + RamUsageEstimator.humanSizeOf(bloomFilter) + " num " + sum);
}
}
/**
* 核心調用方法
* 參數 s :被過濾的參數
* 參數 key :需要構建的布隆過濾器,此處是庫名 + 表名稱,即 db_name.table_name
* @param s
* @param key
* @return
* @throws Exception
*/
@Override
public Boolean call(Object s, String key) throws Exception {
//如果 spark.myudf.bloom.enable 參數配置為 0 ,則布隆過濾器失效,直接返回 true
if (udfBloomFilterEnable == 0) {
return true;
}
if (!bloomFilterMap.containsKey(key)) {
String[] table_array = key.split("\\.");
if (table_array.length != 2) {
String msg = "the key is invalid: " + key + ", must like db_name.table_name";
System.out.println(msg);
throw new IOException(msg);
}
String dbName = table_array[0];
String tableName = table_array[1];
String path = "/hive/" + dbName + ".db/" + tableName;
System.out.println(path);
//構建布隆過濾器
buildBloomFilter(key, path);
}
if (!bloomFilterMap.containsKey(key)) {
String msg = "not found bloom filter " + key;
System.out.println(msg);
throw new IOException(msg);
}
BloomFilter bloomFilter = bloomFilterMap.get(key).getBloomFilter();
if (bloomFilter == null) {
//如果數據量大于期望值,則直接返回真,即布隆過濾器不起作用
return true;
} else {
return bloomFilter.mightContain(String.valueOf(s));
}
}
}使用示例演示
表信息和數據準備。
--建表數據
create table default.A (
item_id bigint comment '商品ID',
item_name string comment '商品名稱',
item_price bigint comment '商品價格',
create_time timestamp comment '創建時間',
update_time timestamp comment '創建時間'
)
create table default.B (
item_id bigint comment '商品ID',
sku_id bigint comment 'skuID',
sku_price bigint comment '商品價格',
create_time timestamp comment '創建時間',
update_time timestamp comment '創建時間'
)
create table default.ot (
item_id bigint comment '商品ID',
sku_id bigint comment 'skuID',
sku_price bigint comment '商品價格',
item_price bigint comment '商品價格'
) PARTITIONED BY (pt string COMMENT '分區字段')
--準備數據
insert overwrite table default.A
values
(1,'測試1',101,'2023-03-25 08:00:00','2023-03-25 08:00:00'),
(2,'測試2',102,'2023-03-25 08:00:00','2023-03-25 08:00:00'),
(3,'測試2',103,'2023-03-25 08:00:00','2023-03-25 08:00:00'),
(4,'測試2',104,'2023-03-25 08:00:00','2023-04-22 08:00:00'),
(5,'測試2',105,'2023-03-25 08:00:00','2023-04-22 08:00:00');
insert overwrite table default.B
values
(1,11,201,'2023-03-25 08:00:00','2023-03-25 08:00:00'),
(1,12,202,'2023-03-25 08:00:00','2023-03-25 08:00:00'),
(1,13,203,'2023-04-22 08:00:00','2023-04-22 08:00:00'),
(2,21,211,'2023-03-25 08:00:00','2023-03-25 08:00:00'),
(2,22,212,'2023-03-25 08:00:00','2023-03-25 08:00:00'),
(4,42,212,'2023-03-25 08:00:00','2023-03-25 08:00:00'),
(5,51,251,'2023-03-25 08:00:00','2023-03-25 08:00:00'),
(5,52,252,'2023-04-22 08:00:00','2023-04-22 08:00:00'),
(5,53,253,'2023-04-22 08:00:00','2023-04-22 08:00:00');
insert overwrite table default.ot partition(pt='20230421')
values
(1,11,201,101),
(1,12,202,101),
(2,21,211,102),
(2,22,212,102),
(4,42,212,114),
(5,51,251,110);原來處理的 SQL 語句。
insert overwrite table default.ot partition(pt='20230422')
select B.item_id
,B.sku_id
,B.sku_price
,A.item_price
from B
left join A on(A.item_id=B.item_id)使用布隆過濾器的 SQL(Java 函數導入 Spark,函數名為 “bloom_filter”)。
--構建布隆過濾器
drop table if exists tmp.tmp_primary_key;
create table tmp.tmp_primary_key stored as TEXTFILE as
select item_id
from (
select item_id
from default.A
where update_time>='2023-04-22'
union all
select item_id
from default.B
where update_time>='2023-04-22'
) where length(item_id)>0
group by item_id;
--增量數據計算
insert overwrite table default.ot partition(pt='20230422')
select B.item_id
,B.sku_id
,B.sku_price
,A.item_price
from default.B
left join default.A on(A.item_id=B.item_id and bloom_filter(A.item_id, "tmp.tmp_primary_key"))
where bloom_filter(B.item_id, "tmp.tmp_primary_key")
union all
--合并歷史未變更數據
select item_id
,sku_id
,sku_price
,item_price
from default.ot
where not bloom_filter(item_id, "tmp.tmp_primary_key")
and pt='20230421'從上面代碼可以看出,使用布隆過濾器的 SQL,核心業務邏輯代碼只是在原來全量計算的邏輯中增加了過濾條件而已,使用起來還是比較方便的。
實測效果
以我司的 “dim.dim_itm_sku_info_detail_d” 和 “dim.dim_itm_info_detail_d” 任務為例,使用引擎 Spark2。
 圖片
圖片
總結
從理論分析和實測效果來看,使用布隆過濾器的解決方案可以大幅提升任務的性能,并減少集群資源的使用。
該方案不僅適用大表間 Join 分析計算,也適用大表相關的其它分析計算需求,核心思想就是計算有必要的數據,排除沒必要數據,減小無效的計算損耗。