如何保證Mongodb和數(shù)據(jù)庫(kù)雙寫(xiě)數(shù)據(jù)一致性?
?前言
最近在我的技術(shù)群里,有位小伙伴問(wèn)了大家一個(gè)問(wèn)題:如何保證Mongodb和數(shù)據(jù)庫(kù)雙寫(xiě)的數(shù)據(jù)一致性?
群友們針對(duì)這個(gè)技術(shù)點(diǎn)討論的內(nèi)容,引起了我的興趣。
其實(shí)我在實(shí)際工作中的有些業(yè)務(wù)場(chǎng)景,也在使用Mongodb,也遇到過(guò)雙寫(xiě)的數(shù)據(jù)一致性問(wèn)題。
今天跟大家一起分享一下,這類問(wèn)題的解決辦法,希望對(duì)你會(huì)有所幫助。
1.常見(jiàn)誤區(qū)
很多小伙伴看到雙寫(xiě)數(shù)據(jù)一致性問(wèn)題,首先會(huì)想到的是Redis和數(shù)據(jù)庫(kù)的數(shù)據(jù)雙寫(xiě)一致性問(wèn)題。
有些小伙伴認(rèn)為,Redis和數(shù)據(jù)庫(kù)?的數(shù)據(jù)雙寫(xiě)一致性問(wèn)題,跟Mongodb和數(shù)據(jù)庫(kù)的數(shù)據(jù)雙寫(xiě)一致性問(wèn)題,是同一個(gè)問(wèn)題。
但如果你仔細(xì)想想它們的使用場(chǎng)景,就會(huì)發(fā)現(xiàn)有一些差異。
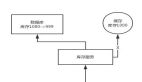
1.1 我們是如何用緩存的?
Redis緩存能提升我們系統(tǒng)的性能。
一般情況下,如果有用戶請(qǐng)求過(guò)來(lái),先查緩存,如果緩存中存在數(shù)據(jù),則直接返回。如果緩存中不存在,則再查數(shù)據(jù)庫(kù),如果數(shù)據(jù)庫(kù)中存在,則將數(shù)據(jù)放入緩存,然后返回。如果數(shù)據(jù)庫(kù)中也不存在,則直接返回失敗。
流程圖如下:

有了緩存之后,能夠減輕數(shù)據(jù)庫(kù)的壓力,提升系統(tǒng)性能。
通常情況下,保證緩存和數(shù)據(jù)雙寫(xiě)數(shù)據(jù)一致性,最常用的技術(shù)方案是:延遲雙刪。
感興趣的小伙伴,可以看看我的另一篇文章《如何保證數(shù)據(jù)庫(kù)和緩存雙寫(xiě)一致性?》,里面有非常詳細(xì)的介紹。
1.2 我們是如何用MongoDB的?
MongoDB?是一個(gè)高可用、分布式的文檔數(shù)據(jù)庫(kù)?,用于大容量數(shù)據(jù)存儲(chǔ)。文檔存儲(chǔ)一般用類似json的格式存儲(chǔ),存儲(chǔ)的內(nèi)容是文檔型的。
通常情況下,我們用來(lái)存儲(chǔ)大數(shù)據(jù)或者json格式的數(shù)據(jù)。
用戶寫(xiě)數(shù)據(jù)的請(qǐng)求,核心數(shù)據(jù)?會(huì)被寫(xiě)入數(shù)據(jù)庫(kù),json格式的非核心數(shù)據(jù),可能會(huì)寫(xiě)入MongoDB。
流程圖如下:

此外,在數(shù)據(jù)庫(kù)的表中,保存了MongoDB相關(guān)文檔的id。
用戶讀數(shù)據(jù)的請(qǐng)求,會(huì)先讀數(shù)據(jù)庫(kù)中的數(shù)據(jù),然后通過(guò)文檔的id,讀取MongoDB中的數(shù)據(jù)。
流程圖如下:

這樣可以保證核心屬性不會(huì)丟失,同時(shí)存儲(chǔ)用戶傳入的較大的數(shù)據(jù),兩全其美。
Redis和MongoDB在我們實(shí)際工作中的用途不一樣,導(dǎo)致了它們雙寫(xiě)數(shù)據(jù)一致性問(wèn)題的解決方案是不一樣的。
接下來(lái)我們一起看看,如何保證MongoDB和數(shù)據(jù)庫(kù)的雙寫(xiě)的數(shù)據(jù)一致性?
2.如何保證雙寫(xiě)一致性?
目前雙寫(xiě)MongoDB和數(shù)據(jù)庫(kù)的數(shù)據(jù),用的最多的就是下面這兩種方案。
2.1 先寫(xiě)數(shù)據(jù)庫(kù),再寫(xiě)MongoDB
該方案最簡(jiǎn)單,先在數(shù)據(jù)庫(kù)中寫(xiě)入核心數(shù)據(jù),再在MongoDB中寫(xiě)入非核心數(shù)據(jù)。
流程圖如下:

如果有些業(yè)務(wù)場(chǎng)景,對(duì)數(shù)據(jù)的完整性要求不高,即非核心數(shù)據(jù)可有可無(wú),使用該方案也是可以的。
但如果有些業(yè)務(wù)場(chǎng)景,對(duì)數(shù)據(jù)完整性要求比較高,用這套方案可能會(huì)有問(wèn)題。
當(dāng)數(shù)據(jù)庫(kù)剛保存了核心數(shù)據(jù),此時(shí)網(wǎng)絡(luò)出現(xiàn)異常,程序保存MongoDB的非核心數(shù)據(jù)時(shí)失敗了。
但MongoDB并沒(méi)有拋出異常,數(shù)據(jù)庫(kù)中已經(jīng)保存的數(shù)據(jù)沒(méi)法回滾,這樣會(huì)出現(xiàn)數(shù)據(jù)庫(kù)中保存了數(shù)據(jù),而MongoDB中沒(méi)保存數(shù)據(jù)的情況,從而導(dǎo)致MongoDB中的非核心數(shù)據(jù)丟失的問(wèn)題。
所以這套方案,在實(shí)際工作中使用不多。
2.2 先寫(xiě)MongoDB,再寫(xiě)數(shù)據(jù)庫(kù)
在該方案中,先在MongoDB中寫(xiě)入非核心數(shù)據(jù),再在數(shù)據(jù)庫(kù)中寫(xiě)入核心數(shù)據(jù)。
流程圖如下:

關(guān)鍵問(wèn)題來(lái)了:如果MongoDB中非核心數(shù)據(jù)寫(xiě)入成功了,但數(shù)據(jù)庫(kù)中的核心數(shù)據(jù)寫(xiě)入失敗了怎么辦?
這時(shí)候MongoDB中非核心數(shù)據(jù)不會(huì)回滾,可能存在MongoDB中保存了數(shù)據(jù),而數(shù)據(jù)庫(kù)中沒(méi)保存數(shù)據(jù)的問(wèn)題,同樣會(huì)出現(xiàn)數(shù)據(jù)不一致的問(wèn)題。
答:我們忘了一個(gè)前提,查詢MongoDB文檔中的數(shù)據(jù),必須通過(guò)數(shù)據(jù)庫(kù)的表中保存的mongo id?。但如果這個(gè)mongo id在數(shù)據(jù)庫(kù)中都沒(méi)有保存成功,那么,在MongoDB文檔中的數(shù)據(jù)是永遠(yuǎn)都查詢不到的。
也就是說(shuō),這種情況下MongoDB文檔中保存的是垃圾數(shù)據(jù),但對(duì)實(shí)際業(yè)務(wù)并沒(méi)有影響。
這套方案可以解決雙寫(xiě)數(shù)據(jù)一致性問(wèn)題,但它同時(shí)也帶來(lái)了兩個(gè)新問(wèn)題:
用戶修改操作如何保存數(shù)據(jù)?
如何清理垃圾數(shù)據(jù)?
3 用戶修改操作如何保存數(shù)據(jù)?
我之前聊的先寫(xiě)MongoDB,再寫(xiě)數(shù)據(jù)庫(kù),這套方案中的流程圖,其實(shí)主要說(shuō)的是新增數(shù)據(jù)的場(chǎng)景。
但如果在用戶修改數(shù)據(jù)的操作中,用戶先修改MongoDB文檔中的數(shù)據(jù),再修改數(shù)據(jù)庫(kù)表中的數(shù)據(jù)。
流程圖如下:

如果出現(xiàn)MongoDB文檔中的數(shù)據(jù)修改成功了,但數(shù)據(jù)庫(kù)表中的數(shù)據(jù)修改失敗了,不也出現(xiàn)問(wèn)題了?
那么,用戶修改操作時(shí)如何保存數(shù)據(jù)呢?
這就需要把流程調(diào)整一下,在修改MongoDB文檔時(shí),還是新增一條數(shù)據(jù),不直接修改,生成一個(gè)新的mongo id。然后在修改數(shù)據(jù)庫(kù)表中的數(shù)據(jù)時(shí),同時(shí)更新mongo id字段為這個(gè)新值。
流程圖如下:

這樣如果新增MongoDB文檔中的數(shù)據(jù)成功了,但修改數(shù)據(jù)庫(kù)表中的數(shù)據(jù)失敗了,也沒(méi)有關(guān)系,因?yàn)閿?shù)據(jù)庫(kù)中老的數(shù)據(jù),保存的是老的mongo id。通過(guò)該id,依然能從MongoDB文檔中查詢出數(shù)據(jù)。
使用該方案能夠解決修改數(shù)據(jù)時(shí),數(shù)據(jù)一致性問(wèn)題,但同樣會(huì)存在垃圾數(shù)據(jù)。
其實(shí)這個(gè)垃圾數(shù)據(jù)是可以即使刪除的,具體流程圖如下:

在之前的流程中,修改完數(shù)據(jù)庫(kù),更新了mongo id為新值,接下來(lái),就把MongoDB文檔中的那條老數(shù)據(jù)直接刪了。
該方案可以解決用戶修改操作中,99%的的垃圾數(shù)據(jù),但還有那1%的情況,即如果最后刪除失敗該怎么辦?
答:這就需要加重試機(jī)制了。
我們可以使用job?或者mq?進(jìn)行重試,優(yōu)先推薦使用mq增加重試功能。特別是想RocketMQ?,自帶了失敗重試機(jī)制,有專門(mén)的重試隊(duì)列?,我們可以設(shè)置重試次數(shù)。
流程圖優(yōu)化如下:

將之前刪除MongoDB文檔中的數(shù)據(jù)操作,改成發(fā)送mq消息,有個(gè)專門(mén)的mq消費(fèi)者,負(fù)責(zé)刪除數(shù)據(jù)工作,可以做成共用的功能。它包含了失敗重試機(jī)制,如果刪除5次還是失敗,則會(huì)把該消息保存到?死信隊(duì)列中。
然后專門(mén)有個(gè)程序監(jiān)控死信隊(duì)列中的數(shù)據(jù),如果發(fā)現(xiàn)有數(shù)據(jù),則發(fā)報(bào)警郵件。
這樣基本可以解決修改刪除垃圾數(shù)據(jù)失敗的問(wèn)題。
4 如何清理新增的垃圾數(shù)據(jù)?
還有一種垃圾數(shù)據(jù)還沒(méi)處理,即在用戶新增數(shù)據(jù)時(shí),如果寫(xiě)入MongoDB文檔成功了,但寫(xiě)入數(shù)據(jù)庫(kù)表失敗了。由于MongoDB不會(huì)回滾數(shù)據(jù),這時(shí)候MongoDB文檔就保存了垃圾數(shù)據(jù),那么這種數(shù)據(jù)該如何清理呢?
4.1 定時(shí)刪除
我們可以使用job定時(shí)掃描,比如:每天掃描一次MongoDB文檔,將mongo id取出來(lái),到數(shù)據(jù)庫(kù)查詢數(shù)據(jù),如果能查出數(shù)據(jù),則保留MongoDB文檔中的數(shù)據(jù)。
如果在數(shù)據(jù)庫(kù)中該mongo id不存在,則刪除MongoDB文檔中的數(shù)據(jù)。
如果MongoDB文檔中的數(shù)據(jù)量不多,是可以這樣處理的。但如果數(shù)據(jù)量太大,這樣處理會(huì)有性能問(wèn)題。
這就需要做優(yōu)化,常見(jiàn)的做法是:縮小掃描數(shù)據(jù)的范圍。
比如:掃描MongoDB文檔數(shù)據(jù)時(shí),根據(jù)創(chuàng)建時(shí)間,只查最近24小時(shí)的數(shù)據(jù),查出來(lái)之后,用mongo id去數(shù)據(jù)庫(kù)查詢數(shù)據(jù)。
如果直接查最近24小時(shí)的數(shù)據(jù),會(huì)有問(wèn)題,會(huì)把剛寫(xiě)入MongoDB文檔,但還沒(méi)來(lái)得及寫(xiě)入數(shù)據(jù)庫(kù)的數(shù)據(jù)也查出來(lái),這種數(shù)據(jù)可能會(huì)被誤刪。
可以把時(shí)間再整體提前一小時(shí),例如:
獲取25小時(shí)前到1小時(shí)前的數(shù)據(jù)。
這樣可以解決大部分系統(tǒng)中,因?yàn)閿?shù)據(jù)量過(guò)多,在一個(gè)定時(shí)任務(wù)的執(zhí)行周期內(nèi),job處理不完的問(wèn)題。
但如果根據(jù)時(shí)間縮小范圍之后,數(shù)據(jù)量還是太大,job還是處理不完該怎么辦?
答:我們可以在job用多線程刪除數(shù)據(jù)。
當(dāng)然我們還可以將job的執(zhí)行時(shí)間縮短,根據(jù)實(shí)際情況而定,比如每隔12小時(shí),查詢創(chuàng)建時(shí)間是13小時(shí)前到1小時(shí)前的數(shù)據(jù)。
或者每隔6小時(shí),查詢創(chuàng)建時(shí)間是7小時(shí)前到1小時(shí)前的數(shù)據(jù)。
或者每隔1小時(shí),查詢創(chuàng)建時(shí)間是2小時(shí)前到1小時(shí)前的數(shù)據(jù)等等。
4.2 隨機(jī)刪除
其實(shí)刪除垃圾數(shù)據(jù)還有另外一種思路。
不知道你了解過(guò)Redis?刪除數(shù)據(jù)的策略?嗎?它在處理大批量數(shù)據(jù)時(shí),為了防止使用過(guò)多的CPU資源,用了一種隨機(jī)刪除的策略。
我們?cè)谶@里可以借鑒一下。
有另外一個(gè)job,每隔500ms隨機(jī)獲取10條數(shù)據(jù)進(jìn)行批量處理,當(dāng)然獲取的數(shù)據(jù)也是根據(jù)時(shí)間縮小范圍的。