大規模可擴展的地理圖形分析:InfiniteGraph和Uber的六邊形層次空間索引
譯文譯者 | 李睿
審校 | 孫淑娟
許多企業發現了圖形數據庫在解決連接數據的復雜問題方面提供的巨大價值。在關系數據庫關注數據模型中的數據時,它們很難從同一數據模型中的數據項之間的關系中獲取價值。而圖形數據庫旨在從數據模型中的數據和關系中獲取價值。
當需要捕獲和分析的圖形數據包含地理元素時會發生什么?當企業的大部分分析都關注數據模型的“位置”方面時會發生什么情況?
Uber公司工程團隊開發了名稱為H3的分層六邊形索引,作為將世界劃分為六邊形的模型,并且他們創建了一組用于與這些六邊形交互的API。他們沒有提供H3 API的數據庫或存儲模型,但InfiniteGraph可以發揮重要作用。
本文描述了開發人員實現圖形數據模型來表示Uber H3索引的方法。這個模型擴展了H3模型,允許開發人員將域數據模型組件與存儲在數據庫中的H3六邊形相關聯。
將所有這些結合在一起,為開發人員提供了一組強大的功能,可以根據域模型和底層H3地理模型來存儲和查詢域數據。通過使用InfiniteGraph作為圖形數據庫平臺,可以在高性能系統和分析中以近乎實時的速度和規模對這些數據執行復雜的查詢。InfiniteGraph支持垂直和水平可擴展性,以及通過分布實現的可擴展性。因此,可以輕松地向上和向下擴展應用程序。
統一的地理環境:一個故事
為了更深入地了解其現有運營的業務并幫助他們規劃未來,一家全國性零售商從其所有的商店的各種來源收集數據。所有收集的數據都提供了對其業務有直接影響的事物的可見性。
零售商收集以下數據:
- 購買:
o購買了什么商品
o購買時間
o購買地點
- 顧客:
o客戶住址
o客戶的電子郵件、電話號碼和購買歷史記錄
- 供應鏈:
o哪些供應商供應哪些商品
o交貨延遲
o批發價格波動
- 運營商店數據:
o勞動力成本
o水電費
o庫存損失
- 天氣:
o每日溫度
o即將來臨的風暴
每個數據項都存儲在創建統一地理環境的數字地圖上。購買信息與進行購買的商店的地圖位置相關聯。客戶數據與每個客戶的住址、鄰居和社區相關聯。供應鏈數據與供應商的位置和他們使用的交付路線相關聯。運營商店數據與商店的位置相關聯。最后,將天氣數據應用于與商店、客戶和供應鏈相關的所有區域的地圖。
使用圖形數據庫時,所有這些數據匯集在一起,提供了一個強大的新工具,使零售商能夠對客戶購買模式和人口統計、復雜的供應鏈互動以及惡劣天氣對銷售和供應鏈績效的影響進行預測分析。
什么是圖形數據庫?
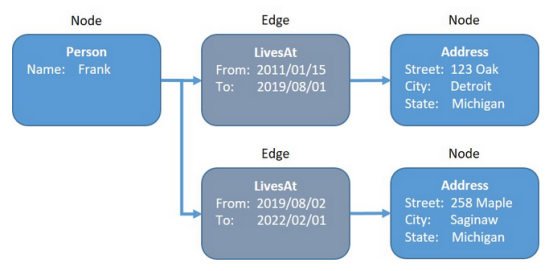
從根本上說,圖形數據庫是將數據表示為節點和邊的數據庫。節點通常表示域中的數據項(如人物、地點或事物),邊表示節點之間的關系。例如,可以將一個人和一個地址表示為節點,然后可以在他們之間創建一條邊來表示“LivesAt”關系。
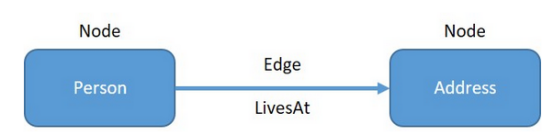
圖形數據模型為表示數據提供了極大的靈活性,可以通過在LivesAt邊緣包含一個日期范圍來擴展Person-LivesAt地址模型,這樣就可以表示一個人居住過的所有地方。
什么是InfiniteGraph?
InfiniteGraph是一個面向對象的圖形數據庫平臺。InfiniteGraph使用聯合架構來實現大規模的可擴展性。單個InfiniteGraph聯合數據庫可以分布在65,000臺服務器上,理論上可以容納1.84×1019個對象。
開發人員創建使用InfiniteGraph API庫與聯合數據庫交互的應用程序。InfiniteGraph部署了兩個輕量級服務器:一個鎖服務器,用于協調所有正在運行的應用程序的鎖;一個頁面服務器,響應來自客戶端應用程序中運行的InfiniteGraph API的頁面請求。所有圖形處理都發生在客戶端應用程序和API中。API用作鏈接到客戶端應用程序的數據庫服務器,使其速度非常快。
在許多其他圖形數據庫產品使用屬性模型方法的情況下,InfiniteGraph使用基于模式的方法。InfiniteGraph基于模式的方法要求開發人員在存儲任何數據之前,為要存儲的數據類型創建模式定義。這提供了許多優點,其中包括支持InfiniteGraph的布局管理功能(PMC)。PMC是一個基于規則的系統,允許開發人員定義規則,規定數據在數據庫中的放置方式。PMC規則可以告訴InfiniteGraph,可能是不同類型的兩個對象(例如Person和Address)應該放在同一個磁盤頁面上,因為它們經常一起使用。
當用戶對人員(Person)執行查詢時,他們接下來可能會請求相關的地址(Address)對象。如果這兩個對象在同一個磁盤頁面上,當磁盤頁面被讀取以響應對人員(對象)的查詢時,同一磁盤頁面上的相關地址對象將被讀入客戶端應用程序中的InfiniteGraph頁面緩存中。當用戶隨后請求地址對象時,將不需要進行第二次讀取頁面,因為帶有地址對象的頁面已在內存中。
所有這些功能共同創建了一個可大規模擴展的高性能對象圖分析平臺,客戶可以在該平臺上構建尖端應用程序。
什么是H3?
H3是Uber的六邊形分層空間索引系統。
Uber公司指出,“……我們開發了網格系統,以有效地優化乘車的定價和調度,以可視化和探索空間數據。H3使我們能夠分析地理信息以設置動態價格,并在全市范圍內做出其他決策。我們使用H3作為整個市場的分析和優化網格系統。H3就是為這一目的而設計的,并引導我們做出一些選擇,例如使用六邊形層次索引。”
H3六邊形地址
H3為每個六邊形分配一個唯一的地址。H3地址是形式為“852A1077FFFFF”的十六進制值,它們表示特定的六邊形。
該地址允許H3確定:
- 六邊形的分辨率
- 六邊形中心的經緯度
- 六邊形每個角的經緯度
- 它的父地址(假設它不是分辨率為0的六邊形)
- 它的7個H3的子地址(假設它不是分辨率為15的六邊形)
H3地址主要是開發人員與H3索引系統交互的方式。
H3分辨率
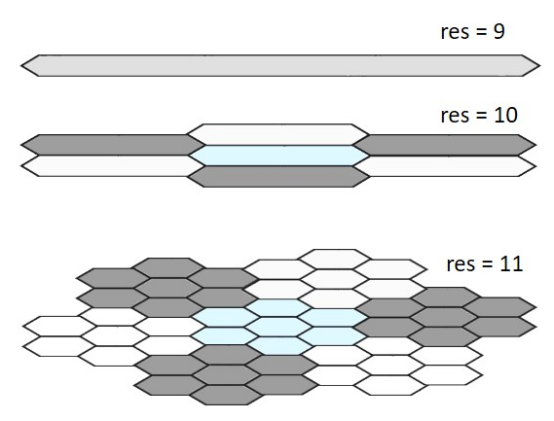
H3還引入了分辨率概念,以支持不同尺寸的六邊形層次。下表給出了每種解決方案的詳細信息。在15個解決方案中,每個六邊形都有7個子六邊形。每個子六邊形約占其父六邊形覆蓋面積的1/7。在除0以外的所有分辨率下,每個六邊形都有一個父六邊形。每個父六邊形覆蓋的面積約為子六邊形的7倍。圖1顯示了分辨率為9的單個六邊形,它的七個六邊形分辨率為10,這些六邊形的子六邊形分辨率為11。
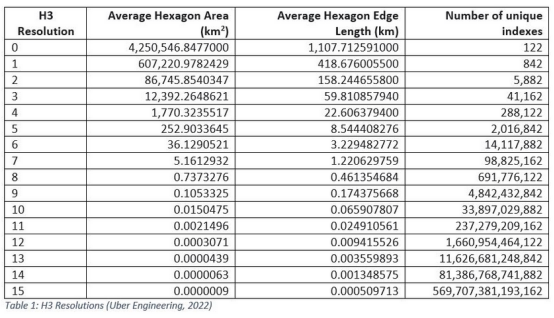
圖1:H3六邊形分辨率
構建H3圖數據庫
H3 API支持廣泛的轉換,使H3成為管理地理數據模型的優雅工具。但是,H3不提供存儲模型。H3不附帶底層數據庫。它本質上是一組工具,用于獲取有關映射到地球上的六邊形的信息。
因為H3提供了有趣的功能,例如根據其緯度/經度計算六邊形的地址或給六邊形的鄰居的地址,所以創建一個H3六邊形對象的圖形數據庫似乎是合理的,其中每個六邊形都是一個節點,它與鄰居、其父節點(分辨率減1)及其子節點(分辨率加1)邊連接。這正是開發人員所要做的。
H3數據的InfiniteGraph模式
六邊形類的初始模式非常簡單。因此需要地址、分辨率、對父六邊形的引用,對子六邊形引用的一個列表,以及一個對相鄰六邊形參考的列表。
這給出以下信息:

這是一個很好的開始,但是為了有用,需要添加更多的信息。首先,為了支持更廣泛的地理查詢,需要添加字段,為六邊形的緯度和經度提供最小值和最大值。最后,想將一些數據與六邊形對象相關聯,因此需要一個對某種數據對象的引用,現在稱之為HexagonData。
這給出以下定義:

這為構建H3圖數據庫提供了強大的基礎。
HexagonData 類
擁有邊連接六邊形的圖形數據庫非常棒。它使能夠跨連接的六邊形執行圖形導航查詢。但是,除非可以使用與六邊形相關聯的某種域數據來限定導航查詢,否則它并不是很有用。
一種方法是將域數據屬性放在Hexagon類定義中。更好的方法是將Hexagon對象與域數據分開。這就是HexagonData類發揮作用的地方。
如下圖所示,HexagonData類只有一個屬性“itemMap”。itemMap屬性是一個NameToReferenceMap,它允許將字符串鍵映射到將存儲實際數據值的DataItem對象的引用。在這種情況下,鍵本質上是數據字段名稱,關聯的字段值包含在引用的DataItem對象中。

HexagonData對象用作六邊形地圖對象和可能與其關聯的任何數據之間的間接層次。可以安全地假設六邊形對象在其初始創建后不會經常更改。假設可能有大量數據被攝取并與每個六邊形相關聯,或者更具體地說,與每個HexagonData對象相關聯,也可能是安全的。
將六邊形對象與HexagonData和DataItem對象分開的另一個優點是對象放置。可以將六邊形對象放在聯合架構的一個部分,然后將HexagonData和DataItem對象放在聯合架構的完全不同的部分。在數百個甚至數千個線程從數據庫讀取和寫入數據庫的環境中,一個理想的放置策略將最大限度地減少鎖的爭用。
DataItem類
DataItem類是實際將值與六邊形關聯的旅程的最后一站。
這是DataItem類的簡化版本:

DataItem類有一個時間戳,用于指示值何時出現,然后有一個strValue String屬性用于存儲文本數據,還有一個realValue用于存儲十進制值。在當前設計中,DataItem對象中沒有任何信息可以指示值所代表的內容。該信息源自HexagonData對象中itemMap指向DataItem對象的鍵。
一圖勝千言…
給定一個特定的六邊形對象,與其關聯的DataItems的“路徑”如下所示。
在這個圖中,有一些由變量“hex”表示的六邊形。它有一個屬性“data”,它是對HexagonData對象的引用。該HexagonData對象有一個屬性:“itemMap”。itemMap有一個鍵值對,其鍵為“Population.density”,該鍵與對DataItem對象的引用相關聯,其中存儲了Hexagon的Population.density值hex。同一個HexagonData對象還有一個鍵“Climate.avgTemp”,它與存儲Climate.avgTemp值的DataItem相關聯。
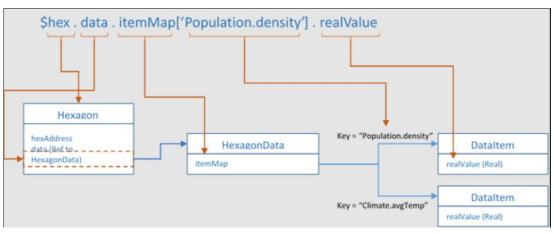
圖2:DataItems的路徑
查詢
InfiniteGraph支持幾種不同類型的查詢,這些查詢分為兩大類:FROM查詢和匹配(MATCH)查詢。
(1)FROM查詢
FROM查詢允許根據特定的類類型和可能的謂詞從對象返回數據。例如,以下查詢返回所有Hexagon對象的每個屬性:
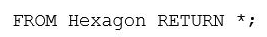
如果只想要所有Hexagon對象的地址屬性,可以修改return子句只返回地址:
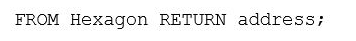
可以添加一個謂詞來縮小結果集。

最后,可以使用點符號返回連接到每個符合WHERE子句的六邊形對象的DataItem對象。

(2)匹配查詢
匹配查詢是可以真正利用圖片的強大功能的地方。
一個簡單的匹配查詢允許找到到1度鄰居的所有路徑:
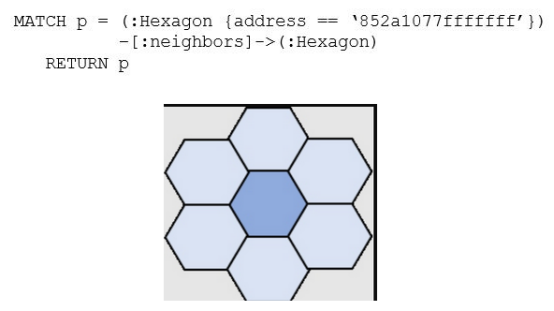
圖3:1度鄰居
如果不想要路徑,而是想要out degree=1鄰居中的地址,可以通過將返回的內容從“p”修改為“h2.addresses” 來實現。

在這里,為目標六邊形和返回的h2.address分配了一個變量h2。這將提供degree=1相鄰六邊形對象的從0到6個地址的列表。
如果想獲得degree=2相鄰六邊形的地址,只需在查詢中間添加另一個邊緣節點子句:
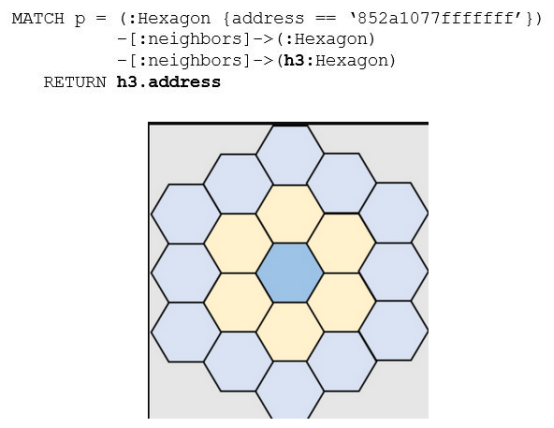
圖4:2度鄰居
(3)查詢之間的路徑
可以使用匹配查詢來查找兩個六邊形對象之間的路徑。在六邊形網格系統中,會有很多路徑,所以只對兩個六邊形之間的最短路徑感興趣。需要注意的是,設置希望查詢搜索距離的上限也很重要,否則查詢可能最終需要很長時間才能運行,因為需要處理大量數據才能找到端點。這是通過設置一個變量但有界的邊緣限定符來完成的,例如“-[:neighbors*1..20]->”。“*1..20”表示在進行搜索時從1跳到不超過20跳。
給定兩個六邊形地址,可以通過將最短運算符合并到匹配查詢中來找到它們之間的最短路徑,如下所示:

這是路徑之間查詢的最簡單形式。
(4)數據符合匹配查詢
假設有一個六邊形,被要求在20度以內的某個屬性內找到平均大于72度的最近的六邊形。只需在目標六邊形中添加一個限定符,就很容易做到這一點。

這個查詢將找到20度內相鄰六邊形的最短路徑,其中“Climate.avgTemp”值大于72度。
(5)沿路徑限定的六邊形
最后一個查詢演示了如何限定路徑末端的頂點六邊形。如果想限定一條路徑上的所有六邊形怎么辦?具體來說,如果想找到一條從一個六邊形到另一個六邊形的路徑,并且該路徑上的每個六邊形都滿足某些條件,該怎么辦?為此,將采用稍微不同的方法,并使用DO查詢語言加權圖權重計算器運算符。
權重計算器允許定義一組函數來根據某些標準計算邊的權重。如果有一張由道路連接的城市圖,可能會說道路是城市頂點之間的邊,并且每條邊的權重是每條道路的長度。
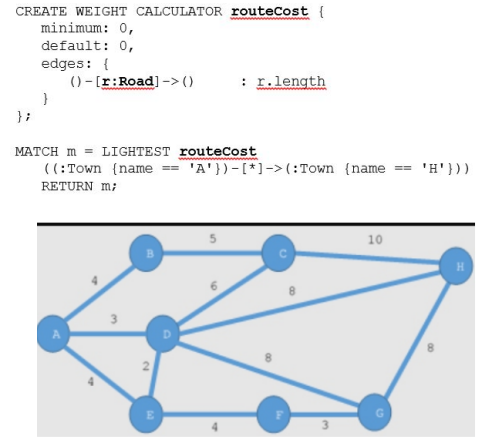
圖5:加權邊
可以擴展加權圖和查詢的概念以及之前討論的點符號,以找到兩個六邊形之間的最短路徑,其中每個六邊形沿著路徑滿足某些標準。在這個示例中,希望找到從定義的原點六邊形到定義的目標六邊形的六邊形路徑,其中沿路徑的每個六邊形的Climate.avgTemp大于72度。
在六邊形類定義中,“鄰居”邊沒有屬性,這很好。將通過檢查每個鄰居邊參考遠端的六邊形來推斷邊的權重。
希望通向符合條件的六邊形的每條邊都具有較低的邊權重,與其相反,希望通向不符合條件的六邊形的每條邊都具有非常高的邊權重。以下是如何使用權重計算器實現的:

這個權重計算器定義了兩個邊匹配模式。第一個匹配源自六邊形并導致Climate.avgTemp >72.00的六邊形的邊。對于符合這些條件的邊,權重計算器將分配1的權重。
第二個邊匹配模式將匹配源自六邊形的邊緣并導致Climate.avgTemp<=72.00的六邊形。對于與此模式匹配的任何邊緣,將分配1000的權重。
使用這個權重計算器,查詢就變成了:

這一查詢將返回權重最低的路徑(最短,因為符合條件的邊的權重為1)并將取消權重(長度)超過21.0的任何路徑,因此如果存在則返回結果路徑。
權重計算器的真正優點在于可以更改,甚至編寫新的權重計算器來限定相同圖形數據上的邊,而無需更改節點和邊上的數據。權重計算器是動態的,它從任何可用節點和邊數據計算權重,這些數據可以從源節點、邊或目標節點訪問。在這個例子中,創建了兩個邊權重函數,它們使用連接到節點的對象中的信息。
結論
H3分層六邊形索引方案是組織、管理和與地理數據交互的極好方式。創建InfiniteGraph圖形數據庫六邊形模型提供了一個很好的基礎,可以在這個基礎上捕獲其他數據,并將其與六邊形相關聯。這一切都構建了一個地理圖形分析平臺,該平臺可用于對大量數據執行高級和復雜的數據分析。
原文標題:??Massively Scalable Geographic Graph Analytics: InfiniteGraph and Uber’s Hexagonal Hierarchical Spatial Index???,作者:Daniel Hall?