整整修了六個小時,一次難料的分頁慢查詢事故……
一、事故背景
這次事故也是我們組里遇到的一次關于分頁慢查詢的典型例子,通過這篇文章,你可以很清晰地跟隨我們還原事故現場,以及每一步遇到問題做出的調整和改動。
二、事故問題現場
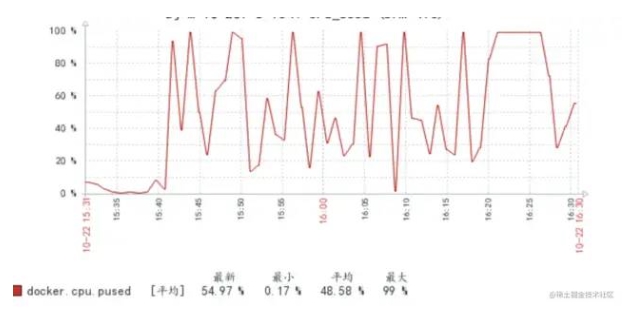
- 16:00 收到同事反饋,融合系統分?查詢可?率降低
- 16:05 查詢接?UMP監控,發現接?TP99異常彪?
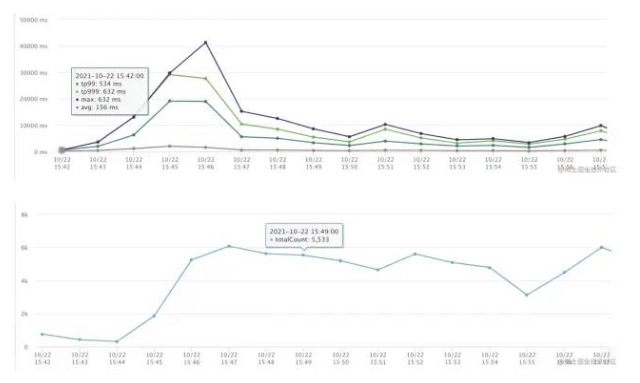
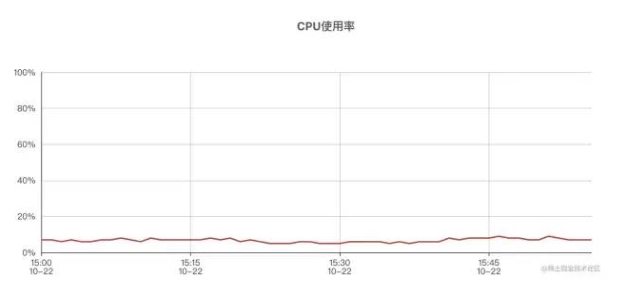
打開機器監控,發現?乎所有機器的TP999都異常的?,觀察機器CPU監控,發現CPU使?率并不?
- 16:10 查看數據庫監控,發現數據庫CPU異常彪?,定位到是數據庫問題,同時收到了?量的慢SQL郵件。
定位到這里,我們基本確定這個不是幾分鐘能解決的問題,于是我們分成兩步去處理。
- 第一步:打開限流,防止更多的慢sql請求進行
- 第二步:分析慢sql,進行改造上線
查看慢SQL,?部分都是融合系統分?查詢接?涉及到的SQL,同時由于上游系統在15:35左右對于該接?調?流量激增,和數據庫CPU暴漲,接?TP999暴漲的時間吻合,推測是由于庫存對于該接?的調?對于數據庫造成了壓?,導致接?耗時增加。但是該接?的調?量并不?,再次查看慢SQL,發現有?量已經遍歷到?百?的慢SQL。推測是深分?的問題。
- 16:15 排查?志發現,?部分SQL都指向商家xxxx,查詢發現其下有10W條數據(占?總數量的?分之?),MQ發現有?量重試,分?查詢接?超時時間發現配置的是2S。推測是慢查詢導致的?頻次重試將數據庫的性能拖垮。
- 16:25 觀察代碼后,確定了是深分頁問題,確定下來了優化?案。為了避免庫存修改接口,?先我們優化SQL將其優化為子查詢的形式。即先通過pageNo和pageSize查詢出ID,然后取出當中的最小值和最大值,然后使?范圍查詢去查詢出來全表數據。由于線上持續對數據庫造成壓力,先讓上游把MQ的消費暫停消費。
- 17:40 優化代碼上線,上游重新打開MQ消費,但是由于消費積累的消息?較多,直接打開后,還是對融合數據庫造成了壓?。接?的TP99再次飆升,數據庫CPU再次飆到100%。
- 18:00 復盤了下,決定不再優化舊接?,?是開發新接?,基于滾動ID進?分?查詢。需要推動上游?起參與開發和聯調。
- 22:20 新接?上線,重新放開MQ消費,上游積壓了?量消息的情況下,新接?表現平穩,“問題解決”
三、問題原因和解決?法
1、深分頁出現原因
問題SQL:
select * from table where org_code = xxxx limit 1000,100
以上?的SQL為例,MySQL的limit?作原理就是先讀取前?1000條記錄,然后拋棄前1000條,讀后?100條想要的,所以?碼越?,偏移量越?,性能就越差。
2、深分頁的幾種解決方法
1)查詢ID+基于ID查詢
即先使?查詢條件查詢出來id,再通過id進?范圍查詢,也就是說我第?次優化的時候使?的?法
?先查詢出來ID,以上?的SQL為例
select id from table where org_code = xxxx limit 1000,5
然后查詢出來id后,使?id進?in查詢,由于是直接基于主鍵的in查詢,所以效率較?
select * from table where id in (1,2,3,4,5);
2)基于ID查詢優化
由于在第?次查詢已經查詢出來了所有符合條件的ID了,可以使?范圍查詢來替代in查詢,效率更?(in
查詢需要和集合里面的元素進??對,但是范圍查詢只需要?較最大和最小即可)
select * from table where org_code = xxxx and id >= 1 and id <= 5;
使用子查詢
select a.id,a.dj_sku_id,a.jd_sku_id from table a join (select id from
jd_spu_sku where org_code = xxxx limit 1000,5) b
on a.id = b.id;
使用子查詢可以減少和數據庫的IO交互,也是?種常?的解決深分頁的?法。
3)使用滾動查詢
每次接?都會返回查詢出來的數據的最?的id(游標),下?次查詢傳?這個游標,服務端只需要根據這個游標,取出id?于這個游標的n個數據即可。n為每?展示條數。
select * from table where org_code = xxxx and id > 0 limit 10;
這種?式服務端實現起來?較簡單且性能很好。缺點是需要客戶端修改,且需要保證ID是自增有序且結果需要是按照ID排序的。
最終定下的是使用滾動查詢的方法。
最終優化SQL上線后,表現平穩。第?周和庫存?起重新優化了?多規格SKU的SQL。如下:
SELECT id,dj_org_code,dj_sku_id,jd_sku_id,yn FROM table where
org_code = xxxx and id > 0 order by id asc limit 500
測試了沒問題后上線。觀察線上監控穩定。
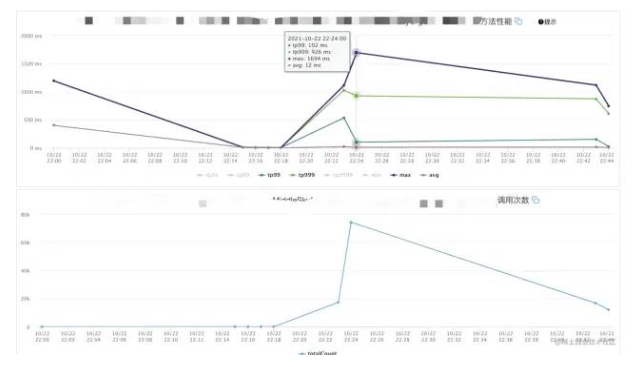
本以為高枕無憂的時候,?周之后,數據庫再次出現了?量的慢查詢,數據庫CPU報警,觀察接?監控:
可以看到在調用量并不?的前提下,接?的耗時達到了60S。聯系運維同學幫忙排查,發現了大量的慢SQL:
SELECT id,dj_org_code,dj_sku_id,jd_sku_id,yn FROM table where
org_code = xxxx and id > 0 order by id asc limit 500
可以看出來,這就是我們優化后的SQL。運維同學explain這條sql后發現,這條SQL?了主鍵索引,沒有?我們以為應該要?的org_code的索引。
和運維初步溝通后得出結論,在某些情況下,主鍵索引的優先級是會?于普通索引的。
四、最終解決方案
1、引用join
因為我們使用了主鍵索引進?排序,且查詢了不在索引樹只在葉子節點中的字段。因此mysql認為主鍵索引更優,因為既可以排序,?不?回表,所以就使?主鍵索引最終導致了全表掃描。
最終使用了先查詢ID(不查詢葉子節點字段保證使?索引),在通過join,使用查詢出來的ID來查詢對應的數據的SQL:
select a.id AS id,a.dj_org_code AS djOrgCode,a.dj_sku_id AS
djSkuId,a.jd_sku_id AS jdSkuId,a.yn AS yn from
table a join
(
SELECT id FROM table where org_code = xxxx and id > 0 order
by id asc limit 500
) t on a.id=t.id;
再次explain了下,可以發現?了我們既定的索引:

于是上線,解決問題。
上線穩定后,分析之前的問題SQL,執?下?兩條語句,同樣的SQL,不同的商家,MYSQL的執?結果也是不?樣的。

查閱資料得知:
MYSQL會將limit的數量和where條件?查詢出的數量進行比對,如果limit數量占比較小(例如某些商家的sku數??較多),則會"優化"為主鍵索引,因為MYSQL此時認為?主鍵索引會減少?次索引樹的查詢,且可以在較短時間??得到結果。(沒有LIMIT不會?主鍵索引)
因此在where 索引A order by 主鍵索引 limit N的這種SQL,需要考慮MYSQL優化主鍵索引的情況。
除了上面最終上線后的優化SQL,也可以通過force index強制使?索引:
SELECT id,dj_org_code,dj_sku_id,jd_sku_id,yn FROM table force
index(idx_upc) where org_code = xxxx and id > 0 order by id asc limit
500
但是這種寫死了索引名稱的?式,如果以后修改了索引名,容易導致安全隱患。
五、問題總結
1)B端系統也需要考慮對自己系統的保護,接?限流等,防止異常流量或者異常調用把自己的系統調死。這次幸虧上游系統是通過MQ調?融合API的,可以暫停消費,如果是?API調?,且流量較?,持續讓數據庫處于?壓狀態,會影響到融合系統的整體穩定性。
2)針對可能出現的風險點絕不姑息。這次這個分頁查詢sku的接?,之前就看到過,但是當時覺得這個接?在數據量較少的情況下性能也還好,而且也有了商家維度的索引,就放過了,考慮后續優化。結果現在就爆出了問題。
3)針對SQL的優化,上線前要謹慎,而且需要同?條SQL,需要針對不同的邊界情況(例如這次的多SKU的商家)進?反復測試,調整。