數據庫的分庫分表是什么?
阿粉相信,現在很多的做開發的都喜歡研究一些新的技術,但是能不能把數據都實際應用到公司的環境中,這個就不好說了,畢竟有些東西用上了,一旦出現問題了,那么就會導致一連串的生產事故的發生。今天阿粉就來學習一下這個Sharding,也就是分庫分表實戰,接下來我們來學習一下什么是分庫分表,什么是Sharding。
什么是分庫分表
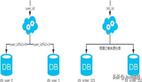
分庫,顯而易見,就是一個數據庫分成多個數據庫,部署到不同機器。
分表,就是一個數據庫表分成多個表。
那么為什么需要分庫分表呢?
為什么需要分庫分表?
首先我們要明確一個問題,單一的數據庫是否能夠滿足公司目前的線上業務需求,比如,我們的用戶表,可能有幾千萬,甚至上億的數據,阿粉只是說可能,如果有這么多用戶,那必然是大公司了,那么這個時候,如果你不分表也不分庫的話,那么數據了上來的時候,稍微一個不注意,MySQL單機磁盤容量會撐爆,但是如果拆成多個數據庫,磁盤使用率大大降低。
這樣就把磁盤使用率降低,這是通過硬件的形式解決問題,就像阿粉所有,如果你的數據量是巨大的,這時候,SQL 如果沒有命中索引,那么就會導致一個情況,查這個表的SQL語句直接把數據庫給干崩了。
即使SQL命中了索引,如果表的數據量 超過一千萬的話, 查詢也是會明顯變慢的。這是因為索引一般是B+樹結構,數據千萬級別的話,B+樹的高度會增高,查詢自然就變慢了,當然,這是題外話了。
那么我們接下來就得說說如何進行分庫和分表的操作了,今天阿粉就講一下這個如何進行進行分庫分表。
分庫分表方案
分庫分表方案,不外乎就兩種,一種是垂直切分,一種是水平切分。
但是總有做開發的小伙伴不知道這垂直切分和水平切分到底是什么樣的,為什么垂直切分,為什么水平切分,什么時候應該選擇垂直切分,什么時候應該選擇水平切分。
有人是這么說的,垂直切分是根據業務來拆分數據庫,同一類業務的數據表拆分到一個獨立的數據庫,另一類的數據表拆分到其他數據庫。
有些人不理解這個,實際上垂直切分也是有劃分的,上面描述的是垂直切分數據庫,可能容易讓很多人不太理解,但是如果是垂直切分表,那么肯定百分之90的人都能理解。
我們又一張Order表,表中有諸多記錄,比如我們設計這么一張簡單的表。
字段有如下。
id | order_id | order_date | order_type | order_state |
1 | cd96cff0356e483caae6b2ff4e878fd6 | 2022-06-11 13:57:11 | 支付寶 | 1 |
2 | e2496f9e22ce4391806b18480440526a | 2022-06-12 14:22:33 | 微信 | 2 |
3 | 9e7ab5a1915c4570a9eaaaa3c01f79c1 | 2022-06-12 15:21:44 | 現金 | 2 |
以上是我們的簡化版Order表,如果我們想要垂直切分,那么應該怎么處理?
直接拆分成2個表,這時候就直接就一份為2 ,咔的一下拆分成兩個表?
Order1
id | order_id | order_date |
1 | cd96cff0356e483caae6b2ff4e878fd6 | 2022-06-11 13:57:11 |
2 | e2496f9e22ce4391806b18480440526a | 2022-06-12 14:22:33 |
3 | 9e7ab5a1915c4570a9eaaaa3c01f79c1 | 2022-06-12 15:21:44 |
Order2
id | order_type | order_state |
1 | 支付寶 | 1 |
2 | 微信 | 2 |
3 | 現金 | 2 |
這時候我們的主鍵ID保持的時一致的,而這個操作,就是垂直拆分,分表的操作。
既然我們說了垂直拆分,那么必然就有水平拆分。
什么是水平拆分呢?
實際上水平拆分的話,那真的是只有一句話。
按照數據來拆分
水平拆分數據庫:將一張表的數據 ( 按照數據行) 分到多個不同的數據庫.每個庫的表結構相同. 每個 庫都只有這張表的部分數據,當單表的數據量過大,如果繼續使用水平分庫, 那么數據庫的實例 就會不斷增加,不利于系統的運維. 這時候就要采用水平分表。
水平拆分分表: 將一張表的數據 ( 按照數據行) , 分配到同一個數據庫的多張表中,每個表都只有一部 分數據。
我們來看看Order表進行水平拆分的話,是什么樣子的。
Order1
id | order_id | order_date | order_type | order_state |
1 | cd96cff0356e483caae6b2ff4e878fd6 | 2022-06-11 13:57:11 | 支付寶 | 1 |
2 | e2496f9e22ce4391806b18480440526a | 2022-06-12 14:22:33 | 微信 | 2 |
Order2
id | order_id | order_date | order_type | order_state |
3 | 9e7ab5a1915c4570a9eaaaa3c01f79c1 | 2022-06-12 15:21:44 | 現金 | 2 |
實際上就是水平的把表數據給分成了2份,這么看起來是不是就很好理解了。
分庫分表帶來的問題
事務問題首先,分庫分表最大的隱患就是,事務的一致性, 當我們需要更新的內容同時分布在不同的庫時,不可避免的會產生跨庫的事務問題。原來在一個數據庫操作,本地事務就可以進行控制,分庫之后 一個請求可能要訪問多個數據庫,如何保證事務的一致性,目前還沒有簡單的解決方案。
無法連表的問題
還有一個就是,沒有辦法進行連表查詢了,因為,, 原來在一個庫中的一些表,被分散到多個庫,并且這些數據庫可能還不在一臺服務器,無法關聯查詢。所以相對應的業務代碼可能就比較多了。
分頁問題
分庫并行查詢時,如果用到了分頁 每個庫返回的結果集本身是無序的, 只有將多個庫中的數據先查出來,然后再根據排序字段在內存中進行排序,如果查詢結果過大也是十分消耗資源的。
阿粉之前用過一次分頁,直接能把線上CPU瞬間會有一個頂峰值。所以,慎重呀。
分庫分表的技術
目前比較流行的就兩種,一種是MyCat,另外一種則是Sharding-jdbc,都是可以進行分庫的。
MyCat是一個數據庫中間件,Sharding-jdbc是以 jar 包提供服務的jdbc框架。
如果要是讓阿粉選擇,那么阿粉絕對會選擇最方便快捷的,也就是jar包的形式來操作。
Mycat和Sharding-jdbc 實現原理也是不同。
Mycat的原理中最重要的一個動詞是“攔截”,它攔截了用戶發送過來的SQL語句,首先對SQL語句做了一些特定的分析:如分庫分表分析、路由分析、讀寫分離分析、緩存分析等,然后將此SQL發往后端的真實數據庫,并將返回的結果做適當的處理,最終再返回給用戶。
而Sharding-JDBC的原理是接受到一條SQL語句時,會陸續執行SQL解析 => 查詢優化 => SQL路由 => SQL改寫 => SQL執行 => 結果歸并 ,最終返回執行結果。