vivo大規模 Kubernetes 集群自動化運維實踐
作者 | vivo 互聯網服務器團隊-Zhang Rong
一、背景
隨著vivo業務遷移到k8s的增長,我們需要將k8s部署到多個數據中心。如何高效、可靠的在數據中心管理多個大規模的k8s集群是我們面臨的關鍵挑戰。kubernetes的節點需要對os、docker、etcd、k8s、cni和網絡插件的安裝和配置,維護這些依賴關系繁瑣又容易出錯。
以前集群的部署和擴縮容主要通過ansible編排任務,黑屏化操作、配置集群的inventory和vars執行ansible playbook。集群運維的主要困難點如下:
- 需要人工黑屏化集群運維操作,存在操作失誤和集群配置差異。
- 部署腳本工具沒有具體的版本控制,不利于集群的升級和配置變更。
- 部署腳本上線需要花費大量的時間驗證,沒有具體的測試用例和CI驗證。
- ansible任務沒有拆分為模塊化安裝,應該化整為零。具體到k8s、etcd、addons的等角色的模塊化管理,可以單獨執行ansible任務。
- 主要是通過二進制部署,需要自己維護一套集群管理體系。部署流程繁瑣,效率較低。
- 組件的參數管理比較混亂,通過命令行指定參數。k8s的組件最多有100以上的參數配置。每個大版本的迭代都在變化。
本文將分享我們開發的Kubernetes-Operator,采用K8s的聲明式API設計,可以讓集群管理員和Kubernetes-Operator的CR資源進行交互,以簡化、降低任務風險性。只需要一個集群管理員就可以維護成千上萬個k8s節點。
二、集群部署實踐
2.1 集群部署介紹
主要基于ansible定義的OS、docker、etcd、k8s和addons等集群部署任務。
主要流程如下:
- Bootstrap OS
- Preinstall step
- Install Docker
- Install etcd
- Install Kubernetes Master
- Install Kubernetes node
- Configure network plugin
- Install Addons
- Postinstall setup
上面看到是集群一鍵部署關鍵流程。當在多個數據中心部署完k8s集群后,比如集群組件的安全漏洞、新功能的上線、組件的升級等對線上集群進行變更時,需要小心謹慎的去處理。我們做到了化整為零,對單個模塊去處理。避免全量的去執行ansible腳本,增加維護的難度。針對如docker、etcd、k8s、network-plugin和addons的模塊化管理和運維,需提供單獨的ansible腳本入口,更加精細的運維操作,覆蓋到集群大部分的生命周期管理。同時kubernetes-operator的api設計的時候可以方便選擇對應操作yml去執行操作。
集群部署優化操作如下:
(1)k8s的組件參數管理通過
ConmponentConfig[1]提供的API去標識配置文件。
- 【可維護性】當組件參數超過50個以上時配置變得難以管理。
- 【可升級性】對于升級,版本化配置的參數更容易管理。因為社區一個大版本的參數沒有變化。
- 【可編程性】可以對組件(JSON/YAML)對象的模板進行修補。如果你啟用動態kubelet配置選項,修改參數會自動生效,不需要重啟服務。
- 【可配置性】許多類型的配置不能表示為key-value形式。
(2)計劃切換到kubeadm部署
- 使用kubeadm對k8s集群的生命周期管理,減少自身維護集群的成本。
- 使用kubeadm的證書管理,如證書上傳到secret里減少證書在主機拷貝的時間消耗和重新生成證書功能等。
- 使用kubeadm的kubeconfig生成admin kubeconfig文件。
- kubeadm其它功能如image管理、配置中心upload-config、自動給控制節點打標簽和污點等。
- 安裝coredns和kube-proxy addons。
(3)ansible使用規范
- 使用ansible自帶模塊處理部署邏輯。
- 避免使用hostvars。
- 避免使用delegate_to。
- 啟用–limit 模式。
- 等等。
2.2 CI 矩陣測試
部署出來的集群,需要進行大量的場景測試和模擬。保證線上環境變更的可靠性和穩定性。
CI矩陣部分測試案例如下。
(1)語法測試:
- ansible-lint
- shellcheck
- yamllint
- syntax-check
- pep8
(2)集群部署測試:
- 部署集群
- 擴縮容控制節點、計算節點、etcd
- 升級集群
- etcd、docker、k8s和addons參數變更等
(3)性能和功能測試:
- 檢查kube-apiserver是否正常工作
- 檢查節點之間網絡是否正常
- 檢查計算節點是否正常
- k8s e2e測試
- k8s conformance 測試
- 其他測試
這里利用了GitLab、gitlab-runner[2]、ansible和kubevirt[3]等開源軟件構建了CI流程。
詳細的部署步驟如下:
- 在k8s集群部署gitlab-runner,并對接GitLab倉庫。
- 在k8s集群部署Containerized-Data-Importer (CDI)[4]組件,用于創建pvc的存儲虛擬機的映像文件。
- 在k8s集群部署kubevirt,用于創建虛擬機。
- 在代碼倉庫編寫gitlab-ci.yaml[5], 規劃集群測試矩陣。
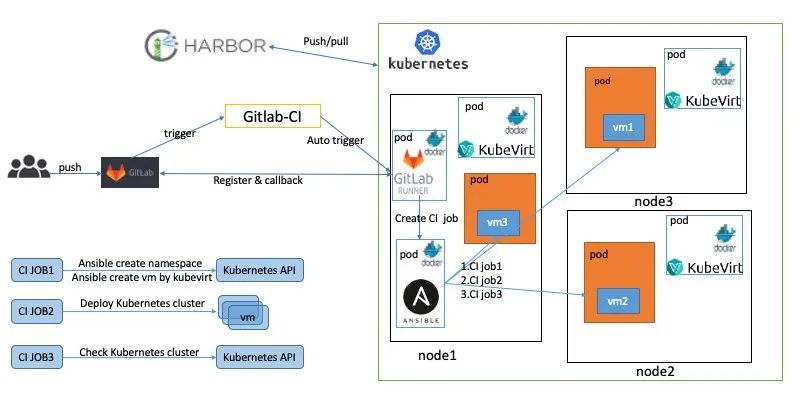
如上圖所示,當開發人員在GitLab提交PR時會觸發一系列操作。這里主要展示了創建虛擬機和集群部署。其實在我們的集群還部署了語法檢查和性能測試gitlab-runner,通過這些gitlab-runner創建CI的job去執行CI流程。
具體CI流程如下:
- 開發人員提交PR。
- 觸發CI自動進行ansible語法檢查。
- 執行ansible腳本去創建namespace,pvc和kubevirt的虛擬機模板,最終虛擬機在k8s上運行。這里主要用到ansible的k8s模塊[6]去管理這些資源的創建和銷毀。
- 調用ansible腳本去部署k8s集群。
- 集群部署完進行功能驗證和性能測試等。
- 銷毀kubevirt、pvc等資源。即刪除虛擬機,釋放資源。
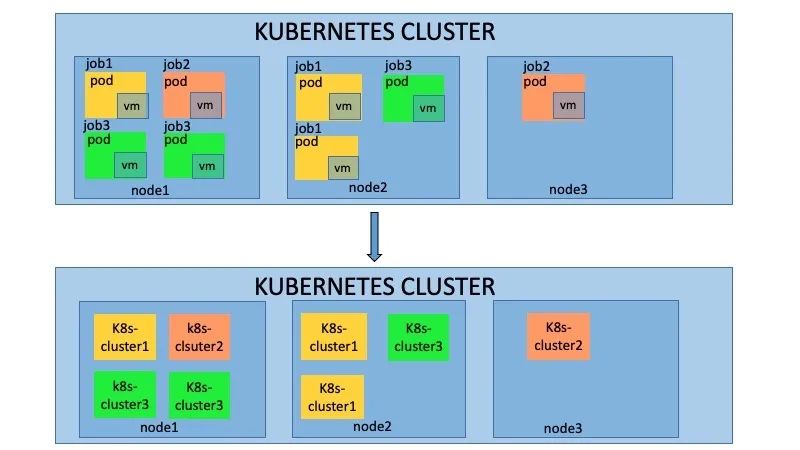
如上圖所示,當開發人員提交多個PR時,會在k8s集群中創建多個job,每個job都會執行上述的CI測試,互相不會產生影響。這種主要使用kubevirt的能力,實現了k8s on k8s的架構。
kubevirt主要能力如下:
- 提供標準的K8s API,通過ansible的k8s模塊就可以管理這些資源的生命周期。
- 復用了k8s的調度能力,對資源進行了管控。
- 復用了k8s的網絡能力,以namespace隔離,每個集群網絡互相不影響。
三、Kubernetes-Operator 實踐
3.1 Operator 介紹
Operator是一種用于特定應用的控制器,可以擴展 K8s API的功能,來代表k8s的用戶創建、配置和管理復雜應用的實例。基于k8s的資源和控制器概念構建,又涵蓋了特定領域或應用本身的知識。用于實現其所管理的應用生命周期的自動化。
總結 Operator功能如下:
- kubernetes controller
- 部署或者管理一個應用,如數據庫、etcd等
- 用戶自定義的應用生命周期管理
- 部署
- 升級
- 擴縮容
- 備份
- 自我修復
- 等等
3.2 Kubernetes-Operator CR 介紹
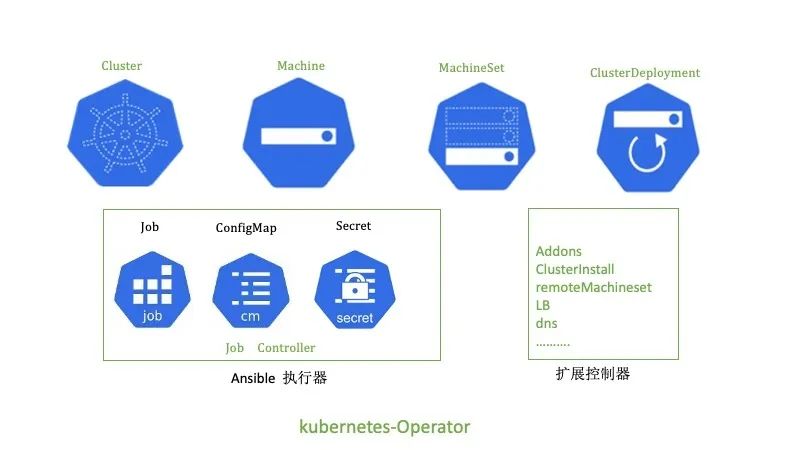
kubernetes-operator的使用很多自定義的CR資源和控制器,這里簡單的介紹功能和作用。
【ClusterDeployment】: 管理員配置的唯一的CR,其中MachineSet、Machine和Cluster它的子資源或者關聯資源。ClusterDeployment是所有的配置參數入口,定義了如etcd、k8s、lb、集群版本、網路和addons等所有配置。
【MachineSet】:集群角色的集合包括控制節點、計算節點和etcd的配置和執行狀態。
【Machine】:每臺機器的具體信息,包括所屬的角色、節點本身信息和執行的狀態。
【Cluster】:和ClusterDeployment對應,它的status定義為subresource,減少
clusterDeployment的觸發壓力。主要用于存儲ansible執行器執行腳本的狀態。
【ansible執行器】:主要包括k8s自身的job、configMap、Secret和自研的job控制器。其中job主要用來執行ansible的腳本,因為k8s的job的狀態有成功和失敗,這樣job 控制器很好觀察到ansible執行的成功或者失敗,同時也可以通過job對應pod日志去查看ansible的執行詳細流程。configmap主要用于存儲ansible執行時依賴的inventory和變量,掛在到job上。secret主要存儲登陸主機的密鑰,也是掛載到job上。
【擴展控制器】:主要用于擴展集群管理的功能的附加控制器,在部署kubernetes-operator我們做了定制,可以選擇自己需要的擴展控制器。比如addons控制器主要負責addon插件的安裝和管理。clusterinstall主要生成ansible執行器。remoteMachineSet用于多集群管理,同步元數據集群和業務集群的machine狀態。還有其它的如對接公有云、dns、lb等控制器。
3.3 Kubernetes-Operator 架構
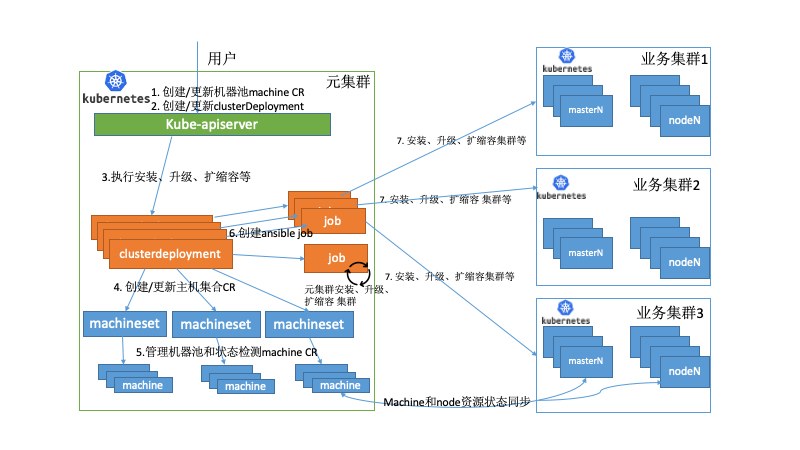
vivo的應用分布在數據中心的多個k8s集群上,提供了具有集中式多云管理、統一調度、高可用性、故障恢復等關鍵特性。主要搭建了一個元數據集群的pass平臺去管理多個業務k8s集群。在眾多關鍵組件中,其中kubernetes-operator就部署在元數據集群中,同時單獨運行了machine控制器去管理物理資源。
下面舉例部分場景如下:
場景一:
當大量應用遷移到kubernets上,管理員評估需要擴容集群。首先需要審批物理資源并通過pass平臺生成對應machine的CR資源,此時的物理機處于備機池里,machine CR的狀態為空閑狀態。當管理員創建ClusterDeploment時所屬的MachineSet會去關聯空閑狀態的machine,拿到空閑的machine資源,我們就可以觀測到當前需要操作機器的IP地址生成對應的inventory和變量,并創建configmap并掛載給job。執行擴容的ansible腳本,如果job成功執行完會去更新machine的狀態為deployed。同時跨集群同步node的控制器會檢查當前的擴容的node是否為ready,如果為ready,會更新當前的machine為Ready狀態,才完成整個擴容流程。
場景二:
當其中一個業務集群出現故障,無法提供服務,觸發故障恢復流程,走統一資源調度。同時業務的策略是分配在多個業務集群,同時配置了一個備用集群,并沒有在備用集群上分配實例,備用集群并不實際存在。
有如下2種情況:
- 其它的業務集群可以承載故障集群的業務,kubernetes-operator不需要執行任何操作。
- 如果其他業務集群不能承載故障集群的業務。容器平臺開始預估資源,調用kubernetes-operator創建集群,即創建clusterDeployment從備機池里選擇物理機器,觀測到當前需要操作機器的IP地址生成對應的inventory和變量,創建configmap并掛載給job。執行集群安裝的ansible腳本, 集群正常部署完成后開始業務的遷移。
3.4 Kubernetes-Operator 執行流程
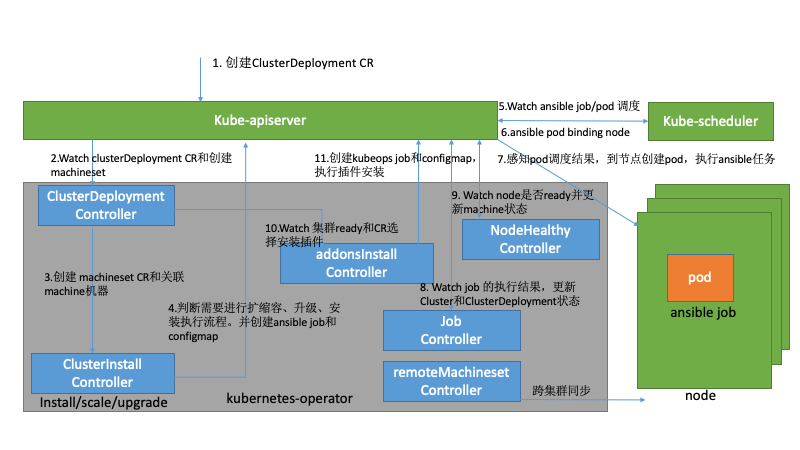
- 集群管理員或者容器平臺觸發創建ClusterDeployment的CR,去定義當前集群的操作。
- ClusterDeployment控制器感知到變化進入控制器。
- 開始創建machineSet和關聯machine 資源。
- ClusterInstall 控制器感知ClusterDeployment和Machineset的變化,開始統計machine資源,創建configmap和job,參數指定操作的ansible yml入口,執行擴縮容、升級和安裝等操作。
- 調度器感知到job創建的pod資源,進行調度。
- 調度器調用k8s客戶端更新pod的binding資源。
- kubelet感知到pod的調度結果,創建pod開始執行ansible playbook。
- job controller感知job的執行狀態,更新ClusterDeployment狀態。一般策略下job controller會去清理configmap和job資源。
- NodeHealthy感知k8s的node是否為ready,并同步machine的狀態。
- addons 控制器感知集群是否ready,如果為ready去執行相關的addons插件的安裝和升級。
四、總結
vivo大規模的K8s集群運維實踐中,從底層的集群部署工具的優化,到大量的CI矩陣測試保證了我們線上集群運維的安全和穩定性。采用了K8s托管K8s的方式來自動化管理集群(K8s as a service),當operator檢測當前的集群狀態,判斷是否與目標一致,出現不一致時,operator會發起具體的操作流程,驅動整個集群達到目標狀態。
當前vivo的應用主要分布在自建的數據中心的多個K8s集群中,隨著應用的不斷的增長和復雜的業務場景,需要提供跨自建機房和云的多個K8s集群去運行原云生的應用程序。就需要Kubernetes-Operator提供對接公有云基礎設施、apiserver的負載均衡、網絡、dns和Cloud Provider 等。需要后續不斷完善,降低K8s集群的運維難度。