基于ES的開源分布式SQL數據庫,CrateDB適用于哪些場景?
今天的分享主要包含以下幾個方面的內容:
- CrateDB介紹
- CrateDB在攜程的實踐
- CrateDB在攜程的優化
- 總結
一、CrateDB介紹
1、CrateDB
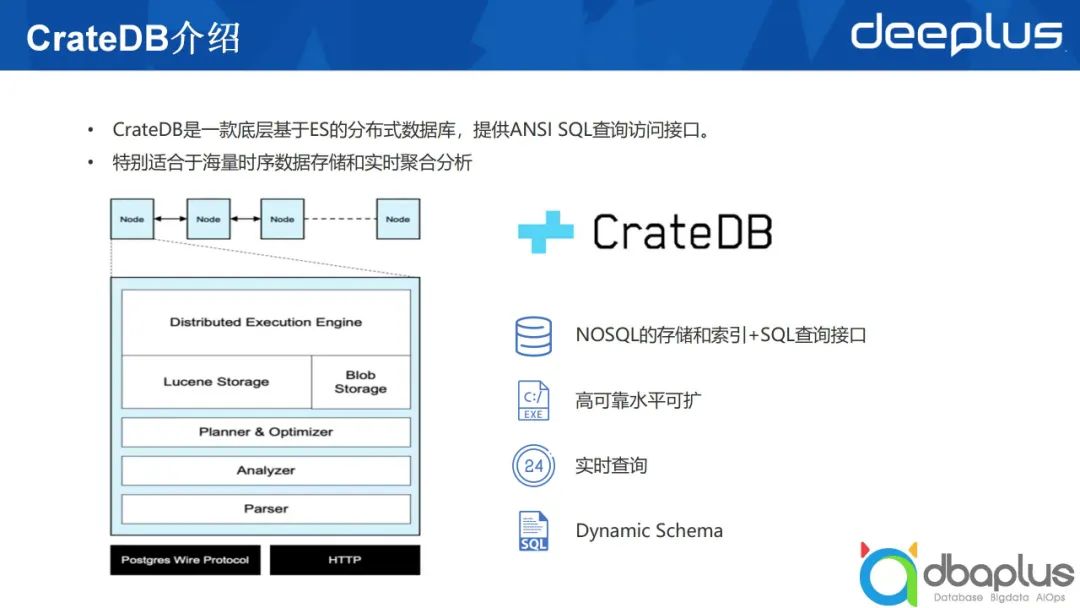
CrateDB是一款基于ElasticSearch的分布式數據庫,它與ElasticSearch最大的區別是提供了ANSI SQL查詢訪問接口。ElasticSearch在6.X版本以后,也開始提供SQL的查詢,但CrateDB與ElasticSearch相比,能夠支持多索引之間的關聯查詢,針對某些聚合函數,它返回的是精確的查詢結果,而ElasticSearch返回的是近似值。
2、CrateDB的特性
- 適用于海量時序數據存儲
CrateDB適用于海量時序數據存儲,需要頻繁更改的數據使用CrateDB存儲效果較差。因為CrateDB基于ElasticSearch,頻繁的刪改操作會使它的性能大大受損。
- 高可靠水平可擴
CrateDB繼承了ElasticSearch設計中高可靠的優點,集群較方便實現擴容,對于一些點查詢或復雜度中等的查詢均能夠較為實時地返回結果。
- 支持Dynamic Schema
CrateDB支持Dynamic Schema,其最新版本能夠支持json數據格式,寫入數據更加方便。
我認為CrateDB的初衷是用SQL的方式查詢訪問基于ElasticSearch存儲的數據。基于這一概念,我們可以看到它大概的分層(如上圖所示),從外部訪問從下到上依次到達最終的存儲,其最外一層提供了PostgresSQL兼容的訪問協議和REST API的訪問協議,接下來對語句進行解析,然后執行,獲取存儲在各個節點上的數據。
3、海量數據存儲對比
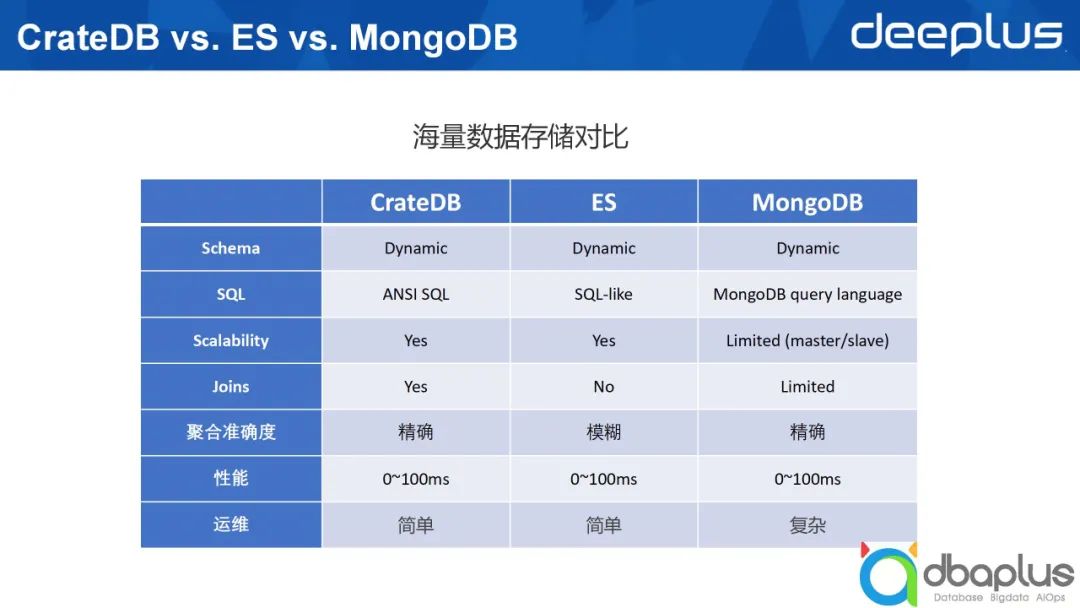
因為類似技術較多,這里只對比幾個典型的技術,CrateDB、ElasticSearch以及MongoDB,這三者都可以歸類于Nosql。下文將從7個維度對三者進行對比。
1)Schema支持類型
這三個數據庫均支持Dynamic Schema。但在現實的生產環境下,我們推薦采用Struct Schema,因為Dynamic Schema可能會帶來種種問題。
僅代表個人觀點,并非適用于所有場景。
2)是否支持SQL訪問
SQL誕生四十多年,已成為非常成熟的語言,具有極強的表達能力。同時SQL具有通用性,被大家普遍接受。CrateDB基于SQL的通用性不斷發展,其支持ANSI SQL,并且采用了PostgreSQL協議。
ElasticSearch起初只支持類json格式的查詢語法,之后開始提供針對單索引的一些SQL語句支持函數,并不斷豐富。MongoDB據我所知并未直接支持SQL,如果寫入SQL語句,需要通過第三方插件才能夠被MongoDB識別,這在一定程度上會影響查詢性能。
3)可擴展性
從可擴展性角度出發,CrateDB和ElasticSearch采用gossip協議組建集群,簡單來說節點之間相應對等。在一個ElasticSearch集群中,節點可分Master、Coordinator,以及承載數據的Data,一個節點可以同時扮演三個不同的角色,因此它們是對等的。
MongoDB則不同,如果用它來構建一個分布式集群,最起碼有三個不同的Host,分別是Config Server、Mongos以及Data,為了實現高可靠,一個分片還需要分成相應的Master或Slave。
綜上所述,從可擴展角度來看,ElasticSearch和CrateDB更好。
4)對于關聯分析的支持程度
CrateDB支持跨索引之間的關聯分析,而ElasticSearch則使用一些變通的方式支持此類關聯查詢,這意味著在寫入數據時需要做相應變更。MongoDB在4.X版本時不支持關聯查詢,之后的版本未及時關注,如描述有誤,歡迎大家指正。
5)聚合準確度
CrateDB和MongoDB返回精確值,ElasticSearch則是返回近似值,雖然返回近似值執行速度快,但其計算的準確度會受到一定影響。
6)性能
在查詢性能方面, CrateDB和ElasticSearch都能夠較好地返回查詢結果,上圖中列出的耗時為100毫秒。對于較為簡單的查詢,100毫秒算是較高的消耗,事實上可以在更短的時間內返回結果。后文中會提到我們自己質量環境下的實際耗時。
7)運維
引入一項新技術后,其帶來的運維復雜度十分關鍵。CrateDB和ElasticSearch相較于MongoDB運維復雜度更低。
4、CrateDB系統架構及節點類型
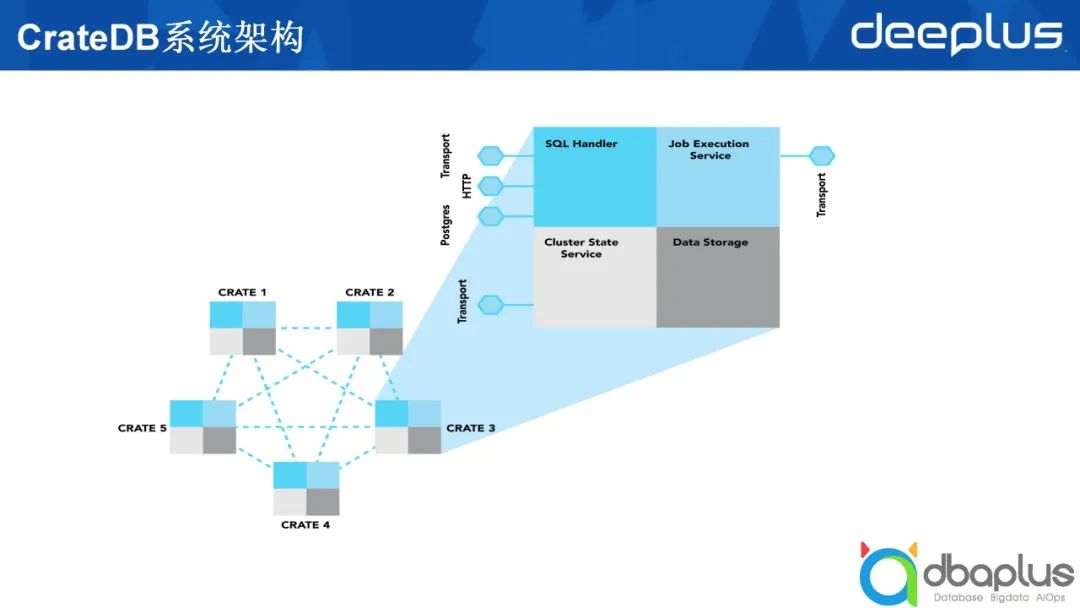
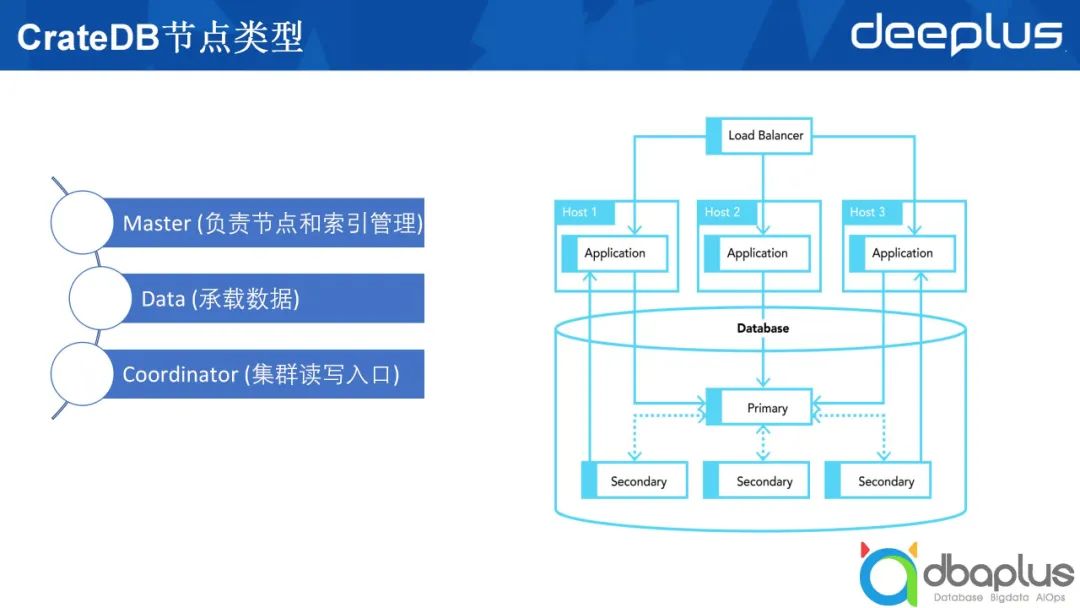
上文中提到在CrateDB和ElasticSearch中節點之間相互對等。以ElasticSearch舉例,由5個節點構成的ElasticSearch集群中起碼有兩個不同的角色。
- Master
該角色需要負責兩個方面的工作,分別是管理節點和管理索引。節點加入集群,在集群中創建了多少個不同的索引,這些索引的分片分布在哪些機器上,這些信息都由 Master來管理。
- 數據節點
我們創建好的索引,數據最終要落到一個具體的ElasticSearch節點上,這些最終承載數據的就是數據節點。
上圖右半部分所示為在生產上部署一個CrateDB或ElasticSearch集群。最上方的負載均衡部分可有可無。除上文提到的兩種節點類型外,還有一種叫做Coordinator的節點類型,它既不承載具體的數據,也不扮演Master的角色,只接受外部的請求,并將外部請求路由到數據節點上做具體查詢,然后在Coordinator節點做一些匯總,最后返回給應用程序。除此之外,ElasticSearch中可能還會有一個叫Ingest的節點類型,這里不進行過多闡述。
綜上所述,一個CrateDB的表類似于一個ElasticSearch的索引,ElasticSearch中索引由多個不同的分片組成,每一個分片可能會落到某一個數據節點上。為了實現高可靠,一個分片又分成主分片和副本分片,即圖中列出的Primary和Secondary。
5、CrateDB具體操作
1)表創建
這個操作和我們平時用PostgreSQL或MySQL創建一張表并無很大差別。
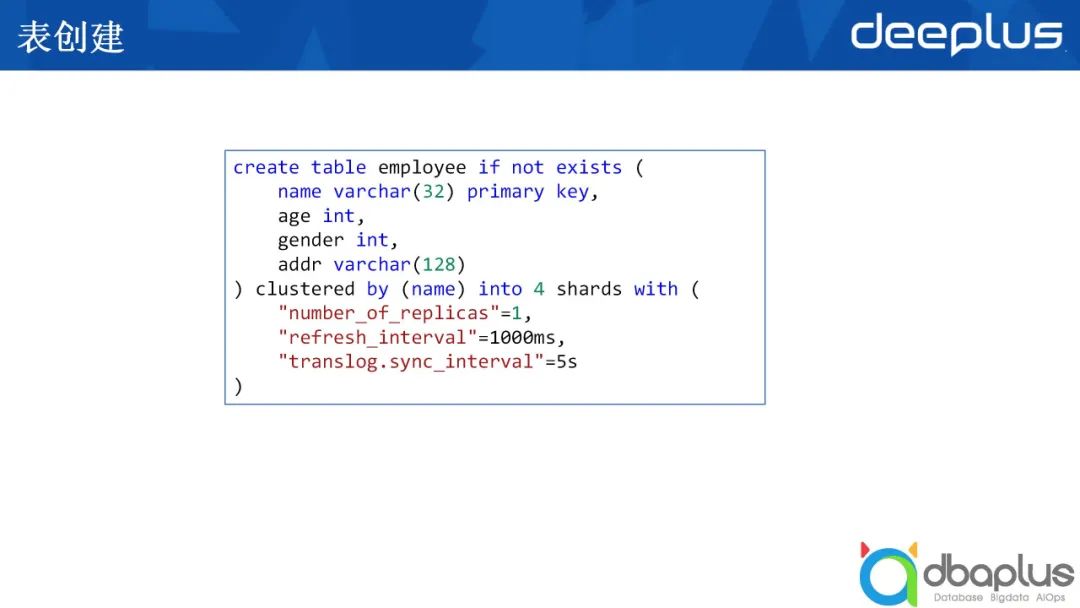
創建一張職工的表(如上圖所示),其中包括姓名、年齡、性別以及住址。這張表根據姓名來進行哈希,哈希的結果分到4個不同的分片中,with后面跟著一些針對索引層面的配置,它的配置項多達幾十項。我們最主要關注以下幾點:
- 分片的副本數
如果只有主分片,replica數為0。如果在主分片之外,還有別的副本分片,增加相應的replica數即可。
- refresh_interval
ElasticSearch進行刷新數據會從內存刷新到磁盤,不斷刷新會降低性能。為了保證更多數據留在內存中,減少刷新的次數,我們可以調節刷新間隔,具體調整根據對數據的新鮮度要求而定。數據只有被刷新后才能被搜索到。
- translog.sync_interval
ElasticSearch采用的是write ahead log的方式,這意味著有大量的translog。translog同樣將數據從內存寫到磁盤,這當中有一個sync的間隔,如果調高這一間隔,可能會加快寫入速度,但也有可能帶來容錯方面的問題。
2)樂觀并發控制
CrateDB是基于ElasticSearch的數據庫,其在ElasticSearch基礎上進行了叫做樂觀并發控制的演變。我們將數據寫入到某一張表時,有兩個隱藏的列,一個是sequence_number,即這一列的版本號,另一個為primary_term,二者聯合使用可以實現某一版本的數據只更新一次,避免頻繁更新。
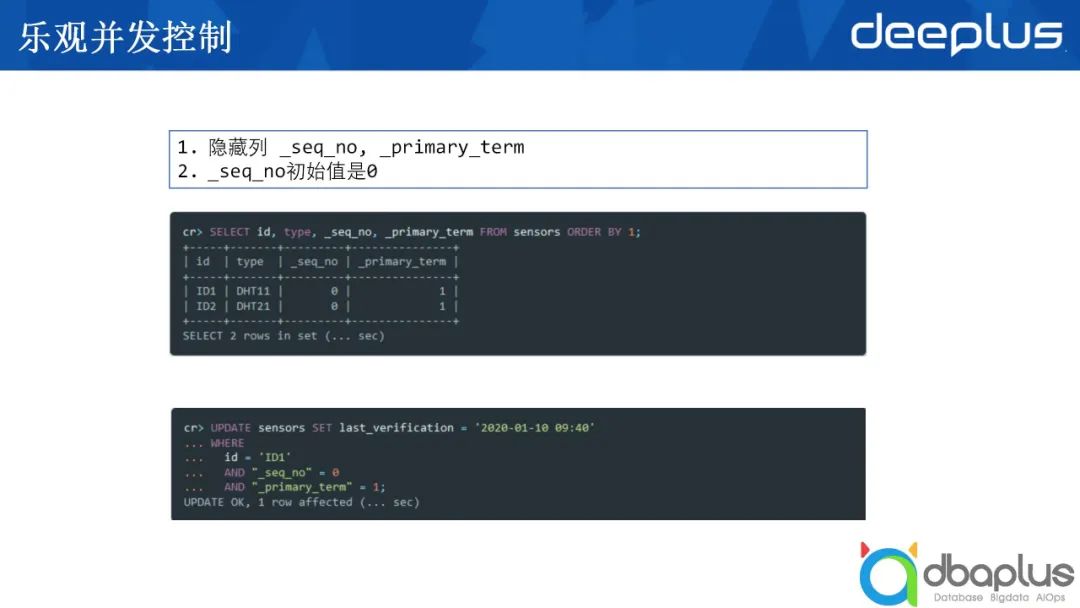
以上圖中的語句為例,對sequence_number等于0進行更新,當這條語句執行成功后,它的sequence_number會自動跳到1,每更新一次,這個值就會遞增。如果有兩個不同的進程或兩個不同的外部訪問,試圖來更新同一條語句,那么只有一條會被執行成功,這就做到了樂觀并發控制。
3)Partitioned Table
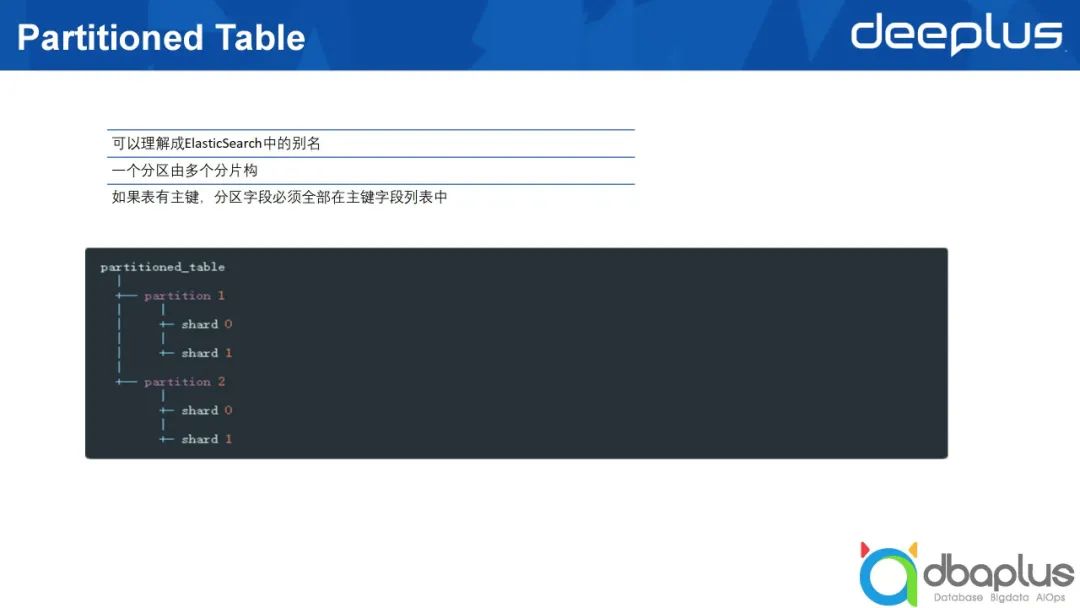
CrateDB與ElasticSearch不同,它引入了Partitioned Table的概念,即所謂的分區表。
上文中講到一個表存在多個分片承載數據,即ElasticSearch的一個索引有多個不同的分片,對應到CrateDB中是分區,CrateDB中的分區可以與ElasticSearch中的別名相對應。
如果我們要查詢或寫入表的數據量達幾十億或上百億,將這些表都放到同樣一個索引當中,可能會導致查詢與寫入的速度變慢,我們其實可以把這些數據分成多個不同的分區。
在我們實際的生產中有這樣一種情況,一些坐過飛機的用戶可能希望查看自己的飛行足跡,如果將所有用戶的歷史數據都放在同一個索引中,經過查詢最后在前端展現的話,速度可能會較慢,因為這一操作對接口的要求較高。
例如要求在50毫秒內返回結果,如果不把這些數據做分區的話,查詢會很慢。此處的慢是99%line的情況,在此情況下,我們要達到滿足性能指標,其中一個變通方法就是把它拆成多個不同的分區,每個uid進入后只需要到對應的分區表查詢即可。
在做分區的時候有一點需要注意,如果表已經創建了組件,分區的字段必須都屬于組件字段的列表,因為這個組件可以由一個列或多個列組成,也可能是一種復合的組件,分區的字段必須在組件的字段列表當中。
二、CrateDB在攜程的實踐
1、實時聚合分析
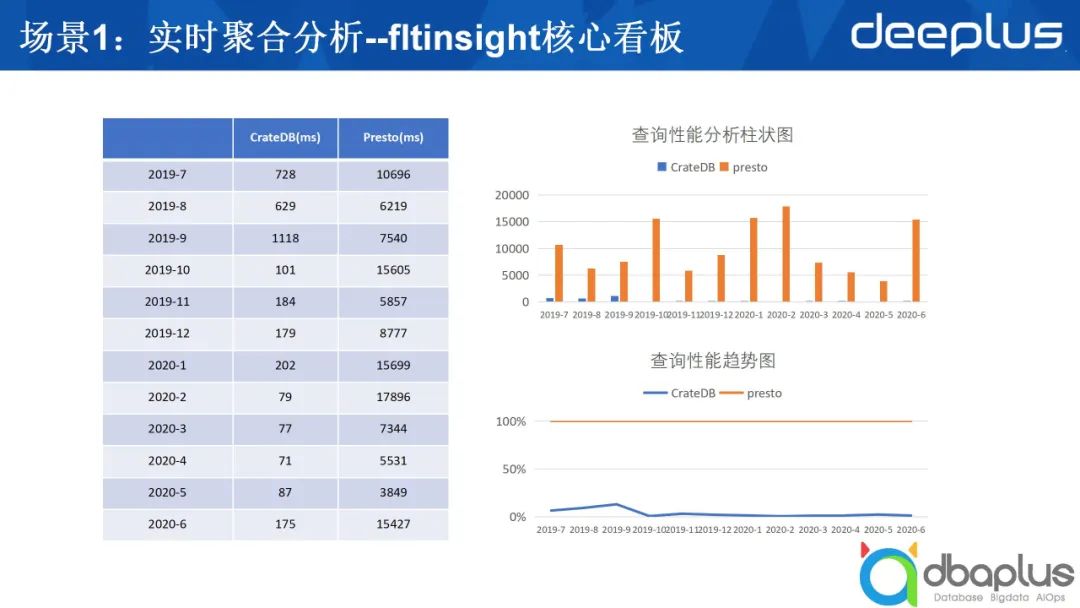
上圖是我們使用CrateDB之后進行的比較,圖中只比較了CrateDB和Presto,我們當時的場景如下。
我們有不少的表,每張表的數據量都有幾千萬條,有的甚至上億條,需要對數據做比較復雜的聚合。原來是用Presto查詢,因為它是一個看板,每次刷新的間隔延遲較大,為了解決這個問題,我們嘗試了一些方法,后來發現用CrateDB效果較好,右側是性能對比,收益十分明顯。
1)具體分析場景
- 國內產品/業務/收益數據分析;
- 主要對常用產量收益(多維度)進行監控;
- 進行拆分下鉆分析;
- 進行了sum、between、groupby、case when、left join、union all等操作。
在性能對比方面,采用CrateDB后,我們基本上能夠在1~2秒之內返回結果。
2、海量數據存儲以及實時查詢
在我們實際的生產中有不少實時數據聚合分析的調用。
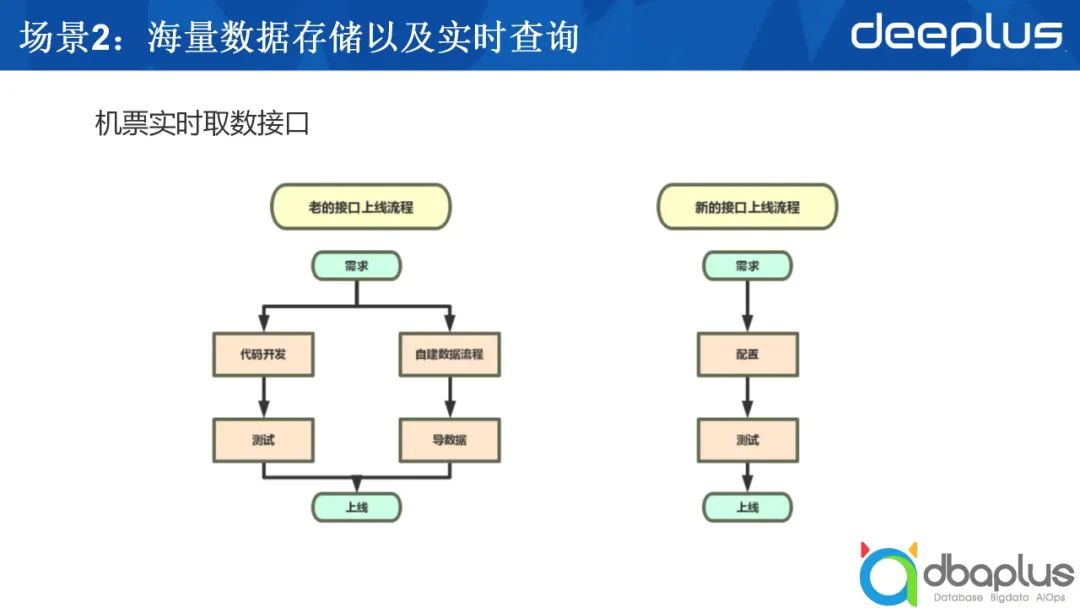
起初,我們是將數據放入Redis中,每收到一次取數請求,我們都會進行相應的代碼開發,把取出的數據進行相應解析,處理之后返回給調用方。這個需求雖然不復雜,但是因為我們沒有辦法注入數據分析的邏輯,所以不得不進行代碼工作。
引入CrateDB后,我們可以將分析工作采用SQL的方式來實現,對于那些用SQL分析不能完全解決掉的剩余部分,則聯合一些Groovy腳本完成。
基于這樣的理念,我們開發了一個模板,我們將SQL寫入模板中,指定從哪個表中取數,如何分析,決定取完數后是否需要進行定制的后續處理,如果需要,則執行相應的Groovy的腳本,最后返回結果。這一套流程大大節省了開發的周期,提升了開發的效率。
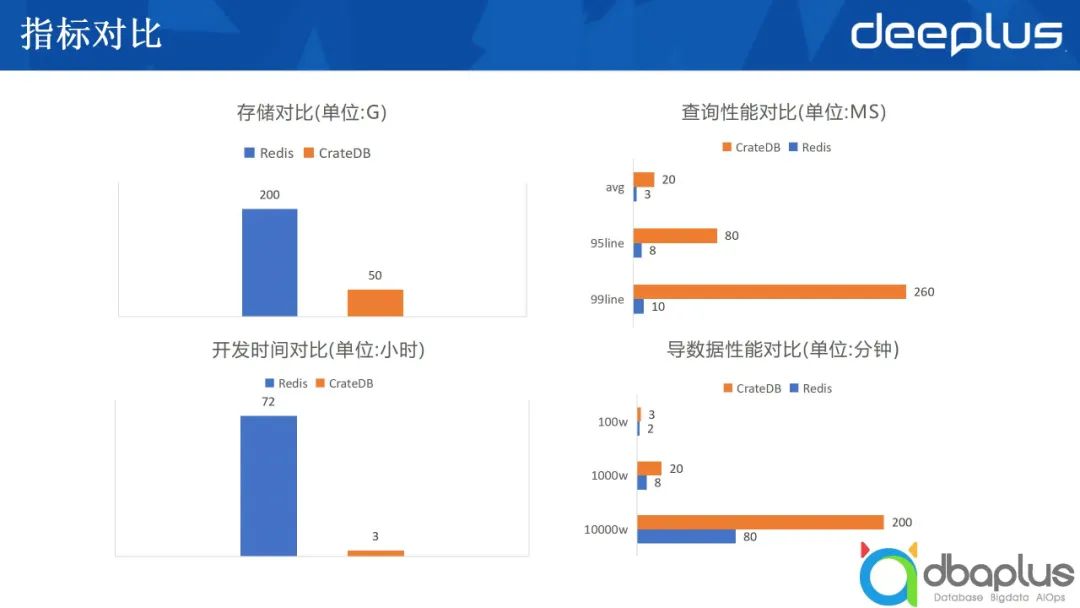
除開發周期對比外,存儲方面的對比也十分顯著。例如數據放入到Redis中,需要200g內存,用CrateDB來存,可能只需要50g,這不僅是數據量上的減少,同時意味著成本的大大縮減。在攜程,有基于RocksDB的存儲,它開發有Redis兼容協議,可以做到把數據存儲到磁盤上,同時可以用Redis的接口訪問。
我們將數據存入了磁盤,分別從均線、95%line、99%line三方面對比性能。均線方面還在可以忍受的范圍內,當然CrateDB不可能比Redis更快。從上圖中可以看出,除99.9%line的時候差距大一點,其他均在可接受的范圍內。在數據導入耗時方面,我們運用Spark將數據導入CrateDB,兩者差距不是特別大。
三、CrateDB在攜程的優化
1、落地時的調優
當我們將CrateDB引入整體的技術方案中時,還需要進行一些調優。
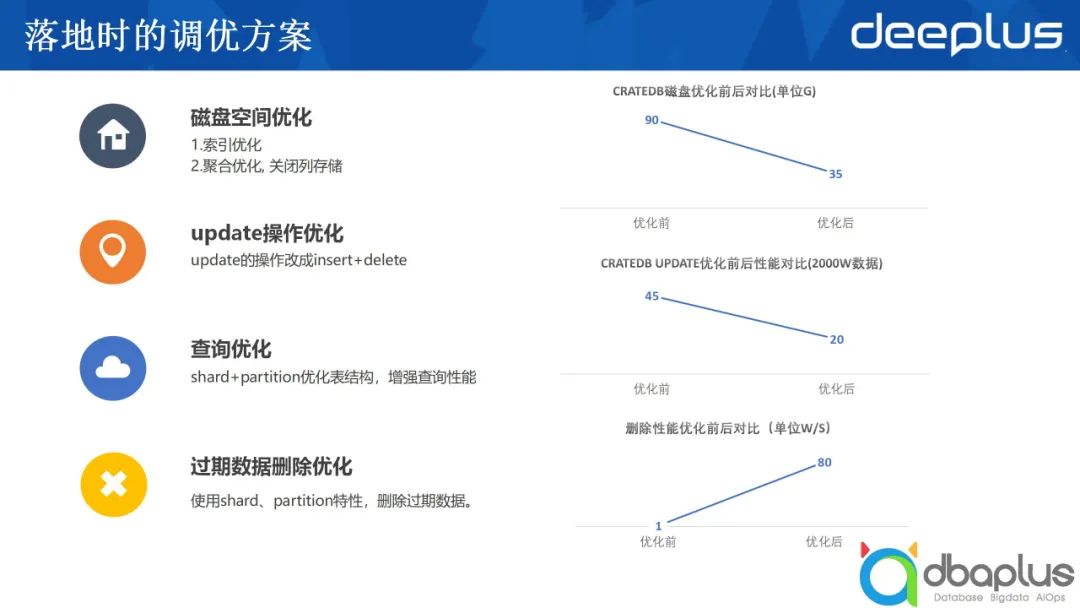
1)磁盤空間調優
為了避免大量磁盤空間的消耗,需要對索引層面進行優化。除此之外,還可以進行聚合優化,關閉列存儲。
2)update操作優化
為了提升 update操作的性能,我們建議先insert,然后再刪除已有的數據。為了達到目的,可以加上相應的版本號,每次只取最新版本的數據。對于在線更新的需求需要做轉換,這也意味著采用CrateDB所能夠支持的場景是有受限的,對于嚴格要求一致,或更新頻繁的場景,CrateDB不是很好的選擇。
3)查詢優化
上文中提到采用分區加多個分片的方式優化表結構的存儲,使得每一次查詢只需要去查盡可能少的分區或分片,查的數據越少、越精準,時間消耗就越短。
4)過期數據刪除優化
2、Spark數據導入
在數據導入CrateDB時,我們可能會用 Spark進行操作,此處向大家分享這一過程中的一個細節點。

此處用分區舉例,如果有一個十幾億或幾億的用戶ID,還有一些關聯數據,要把它均勻地落到每個分區上,有一種比較簡單的方法。我們把 uid(一串字符)進行相應的MD5,MD5之后,取前兩位或后兩位,就可以得到256個分片。256分片顯然太多了,可以再除以一個系數,減少分片數,就可以讓這些數據均勻分布,這樣可以做到分片上承載的數據量是差不多的。
這樣做的挑戰是在寫Spark程序時,怎樣讓每一個partition當中的數據都是落入同一個分片的內容,大家可能會想到repartition函數,但repetition是對某個字段進行哈希,并不能保證落到同一個 partition的數據,這時我們就需要去制定 partition。上圖右側寫出了一些偽碼,我們在spark中定義一個repartition,然后重載,顯示這里可能會有多少個不同的分片。
假設我們剛才取前兩位或取后兩位,然后除以4得到64個分片的話,那么我們把傳進來的數字跟64取模就對應到某一個具體的partition的位置。在Spark中有partitionBy,partitionBy只支持rdd算子,DataFrame中沒有partitionBy的算子,所以我們需要先把DataFrame或者DataSet轉成rdd,通過組成一個 key鍵值對的方式進行partitionBy操作。之后還需要將相應的rdd轉換回DataFrame,這樣就可以得到一個分布很均勻的 DataFrame,再將其寫入CrateDB中,就能達到很快的寫入速度。
3、運維自動化嘗試
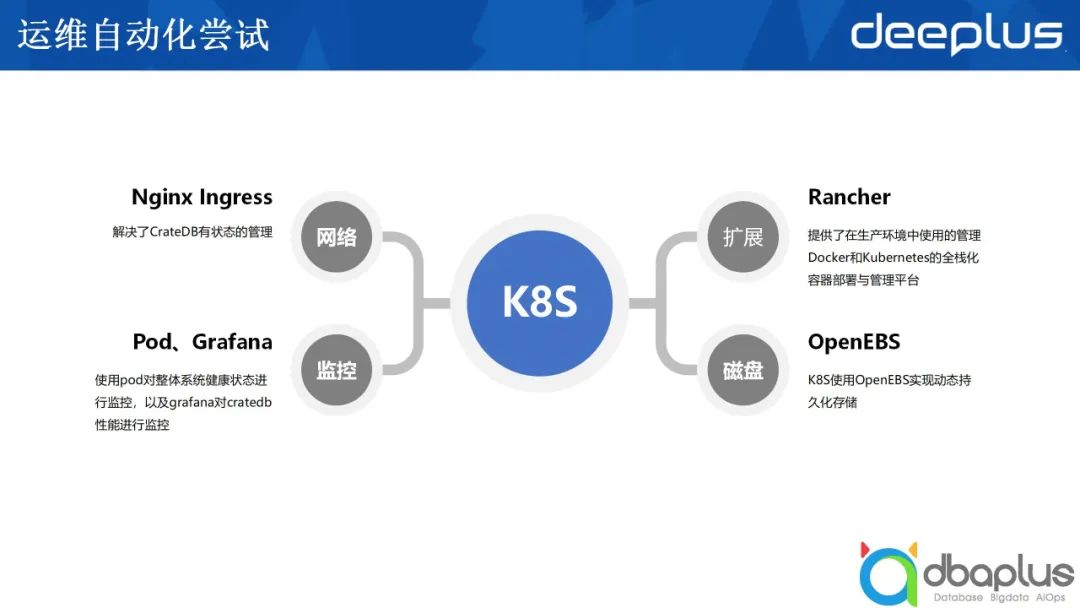
我當時是用 Rancher、OpenEBS,以及Nginx Ingress實現了一個在K8S上的CrateDB集群,這使得我們在云環境去部署CrateDB成為一種可能,部署到云上,即便是私有云上,也可以提高硬件使用率,這也是我的初衷。
4、CrateDB admin UI
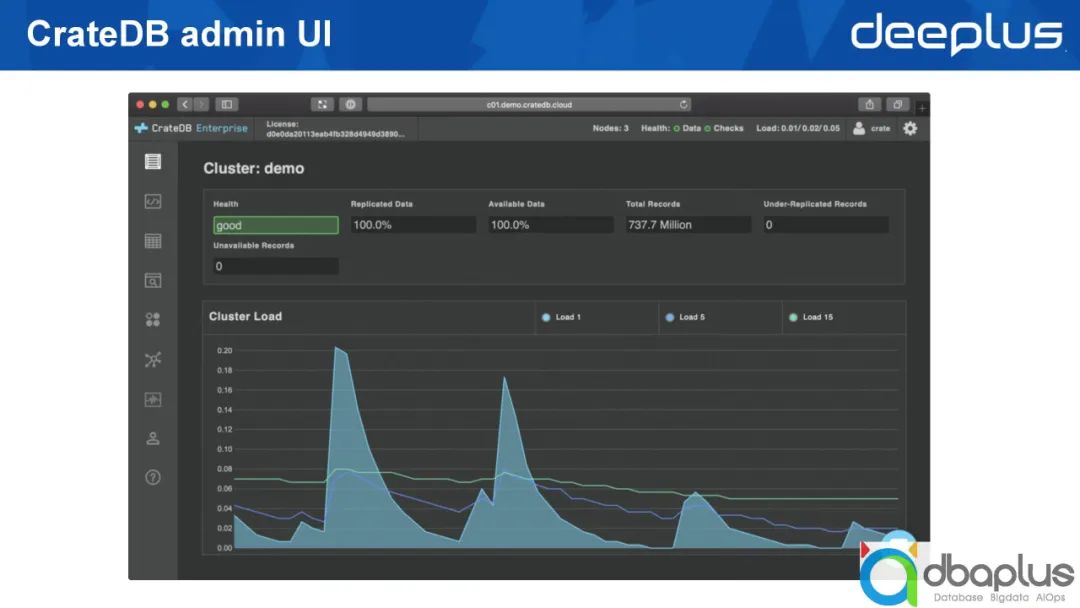
CrateDB安裝完成后,會打開上圖所示的操作界面,我們能夠直接寫入查詢語句,也可以方便地觀測到整個集群的狀況。
四、總結
1、CrateDB的適用場景
- 單點查詢
- 寫入少,查詢多
- 時序數據存儲
- 全文本查詢
2、CrateDB的不足
- Upsert性能較低
- 僅支持NRT查詢
- 高階SQL函數有待實現
- 不支持事務
Q&A
Q1:CrateDB有解決ES字段類型無法修改、寫入性能較低和高硬件資源消耗等痛點嗎?
A1:首先,CrateDB支持修改字段類型,這個字段類型的修改和PostgreSQL中相同,可以將varchar改成text,但將varchar類型直接改成time stamp可能就會有問題,這時就不得不從重寫或者是進行轉換。其次,寫入性能高低分場景,如果只是單獨insert的話,它的性能還是很高的,如果是upsert,或delete與insert摻雜在一起的話,這種混雜這種模式的話,寫入性能就會有一些問題,需要進行相應的變通。變通的方式有兩種,第一種是先把新數據insert,再把老數據delete。第二種方式是新數據較小的話,可以寫入一張另外的臨時表中,臨時表和新的表進行關聯,再做相應的update。
Q2:CrateDB 相比于 Elasticsearch 和 MongoDB ,備份和恢復能力如何?
A2:CrateDB和Elasticsearch在備份和恢復能力層面一樣,但是和MongoDB相比,可能更加直觀和容易,這是我個人的理解。恢復方面,如果你要求寫入時所有數據都吐到磁盤之后才返回,那么所有數據應該都是全部無丟失的。
Q3:CrateDB運行一段時間性能會明顯降低,除了重啟還有什么方案?
A3:CrateDB在實際運維中確實會碰到一些問題,但是我沒有碰到性能明顯下降的情況。如果有的話,你可以進行索引級別的重建,而不是整個集群的重啟,因為集群重啟帶來的成本較高。
Q4:CrateDB日志分析能力如何,有繼承ES的ELK能力嗎?
A4:在與Logstash和Kibana搭配這一層面,還是ES能力更強。從整個生態圈的角度來看,CrateDB還是不能和Elasticsearch相比的,因為Elasticsearch的發展時間久,然后有Logstash和Kibana的加持,在數據的可視化還有分析展現層面確實很強,但是CrateDB可以和另外幾個開源的產品搭配使用,比如說Apache Superset但是肯定沒有Kibana那種原生定制的強大。
Q5:如果把CrateDB部署在k8s上,數據存儲應該怎么存放,是分布存儲,本地存儲,還是集中存儲?
A5:上文中提到需要和OpenEBS或Rancher結合,它是分布式處理的,你的節點要附著于相應的存儲機器上面,即使Docker掛了,數據是不會丟失掉的。
Q6:CrateDB貴司用在TP場景多還是AP場景多?
A6:我們用到的是 AP場景,實時數據的聚合返回結果的,當然每一次查詢所命中的數據集并不是特別大,我們要查詢的數據集可能是很大的,但是真正被查詢條件所命中的還是比較少的,可能是幾十萬。
Q7:CrateDB 的對標競品是什么,和大數據生態圈比如hadoop有互補嗎 ?
A7:CrateDB不是跟Hadoop相競爭,它們兩個應該在不同的層面,因為Hadoop是進行離線數據存儲的,而CrateDB是做數據分析的。如果要尋找對標競品的話,我個人認為TimescaleDB是一個很強的競品,因為它們都號稱是時序數據庫,同時也提供ANSI SQL的查詢標準。從現在的態勢來看,可能TimescaleDB獲得的用戶群更多一點。