













Apache Druid歷險記
1. Druid簡介
1. 1 概述
Druid是一個快速的列式分布式的支持實時分析的數據存儲系統。它在處理PB級數據、毫秒級查詢、數據實時處理方面,比傳統的OLAP系統有了顯著的性能改進。
OLAP分析分為關系型聯機分析處理(ROLAP)、多維聯機分析處理(MOLAP)兩種,MOLAP需要數據預計算好為一個多維數組,典型方式就是Cube,而ROLAP就是數據本身什么樣就是什么樣,查詢時通過MPP提高分布式計算能力。
Druid是ROLAP路線,實時攝取數據,實時出結果,不像Kylin一樣,有一個顯式的預計算過程。
1.1.2 補充
MPP:俗稱大規模并行處理,數據庫集群中,每個節點都有獨立的磁盤存儲系統跟內存系統,業務數據根據數據庫模型跟應用特點被劃分到各個節點,MPP就是將任務并行分散到多個節點,每個節點計算完畢后將結果匯總下來得到最終結果。
Lambda架構:該 架構的設計是為了在處理大規模數據時,同時發揮流處理和批處理的優勢。通過批處理提供全面、準確的數據,通過流處理提供低延遲的數據,從而達到平衡延遲、吞吐量和容錯性的目的。為了滿足下游的即席查詢,批處理和流處理的結果會進行合并。一般有三層。
Batch Layer:批處理層,對離線的歷史數據進行預計算。
Speed Layer:加速處理層,處理實時的增量數據。
Serving Layer:合并層,計算歷史數據和實時數據都有了。
注意:阿里巴巴也曾創建過一個開源項目叫作Druid(簡稱阿里Druid),它是一個數據庫連接池的項目。阿里Druid和本文討論的Druid沒有任何關系,它們解決完全不同的問題。
1.2 Druid 特點
- 低延遲交互式查詢:Druid提供低延遲實時數據攝取(?庫),典型的lambda架構。并采?預聚合、列式存儲、位圖索引等?段使得海量數據分析能夠亞秒級響應。
- ?可?性( High Available ):Druid 使?用 HDFS/S3 作為 Deep Storage,Segment 會在多個Historical 節點上進行加載,攝取數據時也可以多副本攝取,保證數據可?性和容錯性。
- 可伸縮( Horizontal Scalable ):Druid 部署架構都可以?平擴展,增加大量服務器來加快數據攝取,以保證亞秒級的查詢服務。集群擴展和縮小,只需添加或刪除服務器,集群將在后臺自動重新平衡,無需任何停機時間。
- 并行處理( Parallel Processing ): Druid 可以在整個集群中進行大規模的并行處理查詢(MPP)。
- 豐富的查詢能力( Rich Query ):Druid支持時間序列、 TopN、 GroupBy等查詢,同時提供了2種查詢方式:API 和 SQL(功能較少)。
1.3 Druid 適用 & 不適用場景
?句話總結,Druid適合帶時間維度、海量數據的實時/準實時分析
- 帶時間字段的數據,且時間維度為分析的主要維度。
- 快速交互式查詢,且亞秒級快速響應。
- 多維度海量數據,能夠預先定義維度。
- 適用于清洗好的記錄實時錄入,但不需要更新操作。
- 適用于支持寬表,不用Join的方式(換句話說就是一張單表)。
- 適用于可以總結出基礎的統計指標,用一個字段表示。
- 適用于對數據質量的敏感度不高的場景(原生版本非精確去重)。
Druid 不適合的場景
- 要求明細查詢(破解?法是數據冗余)。
- 要求原?生Join(提前Join再入Druid)。
- 沒有時列或者不以時間作為主要分析維度。
- 不支持多時間維度,所有維度均為string類型。
- 想通過單純SQL語法查詢。
1.4 橫向對比

產品對比
- Druid:是一個實時處理時序數據的OLAP數據庫,因為它的索引首先按照時間分片,查詢的時候也是按照時間線去路由索引。提起預聚合了模型,不適合即席查詢分享,不支持JOIN,SQL支持雞肋,不適合明細查詢。
- Kylin:核心是Cube,Cube是一種預計算技術,基本思路是預先對數據作多維索引,查詢時只掃描索引而不訪問原始數據從而提速。不適合即席查詢(提前定于模型預聚合,預技術量大),不支持明細查詢,外部依賴較多,不支持多事實表Join。
- Presto:它沒有使用MapReduce,大部分場景下比Hive快一個數量級,其中的關鍵是所有的處理都在內存中完成。不支持預聚合,自己沒存儲。
- Impala:基于內存運算,速度快,支持的數據源沒有Presto多。不支持預聚合,自己沒存儲。
- Spark SQL:基于Spark平臺上的一個OLAP框架,基本思路是增加機器來并行計算,從而提高查詢速度。
- ElasticSearch:最大的特點是使用了倒排索引解決索引問題。根據研究,ES在數據獲取和聚集用的資源比在Druid高。不支持預聚合,不適合超大規模數據處理,組合查詢性能欠佳。
- ClickHouse:C++編寫的高性能OLAP工具,不支持高并發,數據量超大會出現瓶頸(盡量選擇預聚合出結果表),賊吃CPU資源(新版支持MVCC)。
- 框架選型:從超大數據的查詢效率來看 Druid > Kylin > Presto > Spark SQL,從支持的數據源種類來講 Presto > Spark SQL > Kylin > Druid。
2. Druid 架構
Druid為了實現海量數據實時分析采?了?些特殊的?段和?較復雜的架構,大致分兩節分別介紹。
2.1 Druid 核心概念
Druid能實現海量數據實時分析,主要采取了如下特殊手段。
- 預聚合。
- 列式存儲。
- 多級分區 + 位圖索引(Datasource、Segments)。
2.1.1 roll up 預聚合
分析查詢逃不開聚合操作,Druid在數據?庫時就提前進行了聚合,這就是所謂的預聚合(roll-up)。Druid把數據按照選定維度的相同的值進行分組聚合,可以?大降低存儲?小。數據查詢的時候只需要預聚合的數據基礎上進行輕量的?次過濾和聚合即可快速拿到分析結果,當然預聚合是以犧牲明細數據分析查詢為代價。
要做預聚合,Druid要求數據能夠分為三個部分:
- Timestamp列:Druid所有分析查詢均涉及時間(思考:時間實際上是?個特殊的維度,它可以衍?出一堆維度,Druid把它單列列出來了)
- Dimension列(維度):Dimension列指?于分析數據?度的列,例如從地域、產品、用戶的角度來分析訂單數據,一般?用于過濾、分組等等。
- Metric列(度量):Metric列指的是?于做聚合和其他計算的列。?般來說是數字。
{"timestamp":"2018-01-01T01:01:35Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":20,"bytes":9024}
{"timestamp":"2018-01-01T01:01:51Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":255,"bytes":21133}
{"timestamp":"2018-01-01T01:01:59Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":11,"bytes":5780}
{"timestamp":"2018-01-01T01:02:14Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":38,"bytes":6289}
{"timestamp":"2018-01-01T01:02:29Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":377,"bytes":359971}
{"timestamp":"2018-01-01T01:03:29Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":49,"bytes":10204}
{"timestamp":"2018-01-02T21:33:14Z","srcIP":"7.7.7.7","dstIP":"8.8.8.8","packets":38,"bytes":6289}
{"timestamp":"2018-01-02T21:33:45Z","srcIP":"7.7.7.7","dstIP":"8.8.8.8","packets":123,"bytes":93999}
{"timestamp":"2018-01-02T21:35:45Z","srcIP":"7.7.7.7","dstIP":"8.8.8.8","packets":12,"bytes":2818}
比如上面這樣一份明細數據,timestamp當然是Timestamp列,srcIP和dstIP是Dimension列(維度),packets和bytes是Metric列。該數據?庫到Druid時如果我們打開預聚合功能(可以不打開聚合,數據量?大就不?了),要求對packets和bytes進?行行累加(sum),并且要求按條計數(count *),聚合之后的數據是這樣的:
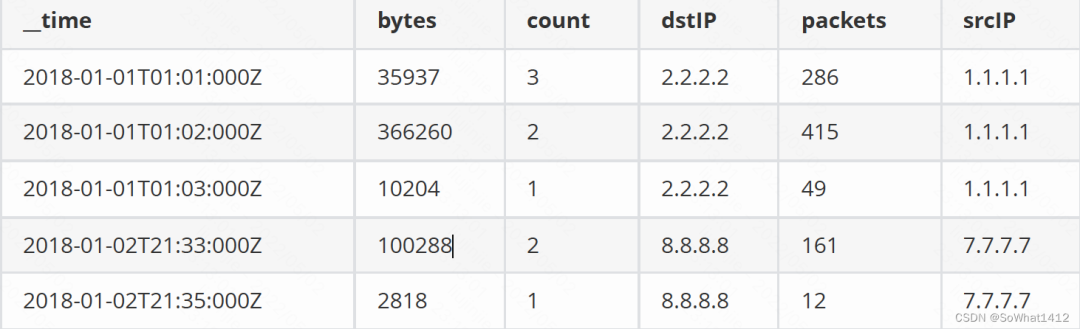
聚合后數據
2.1.2 列式存儲
行式:
行式存儲查詢
列式:

列式存儲查詢
在大數據領域列式存儲是個常見的優化手段,一般在OLTP數據庫會用行式存儲,OLAP數據庫會使用列式存儲。列式存儲一般有如下優點:
對于分析查詢,?般只需要?到少量的列,在列式存儲中,只需要讀取所需的數據列即可。例例如,如果您需要100列列中的5列,則I / O減少20倍。
按列分開存儲,按數據包讀取時因此更易于壓縮。列中的數據具有相同特征也更易于壓縮, 這樣可以進?步減少I / O量。
由于減少了I / O,因此更更多數據可以容納在系統緩存中,進?步提?分析性能。
2.1.3 DataSource & Segments
Druid的數據在存儲層面是按照Datasource和Segments實現多級分區存儲的,并建?了位圖索引。
- Datasource相當于關系型數據庫中的表,
- Datasource會按照時間來分片(類似于HBase?里里的Region和Kudu?的tablet),每?個時間分?被稱為chunk,
- chunk并不是直接存儲單元,在chunk內部數據還會被切分為?個或者多個segment。所有的segment獨?立存儲,通常包含數百萬?行行,segment與chunk的關系如下圖:
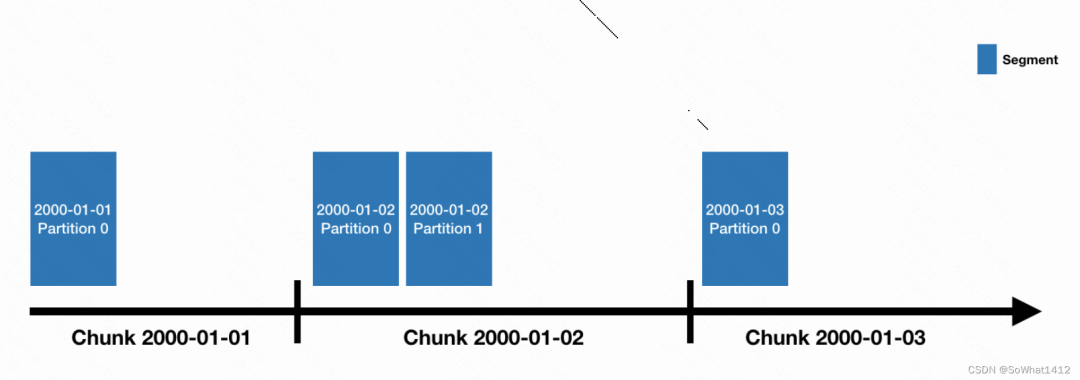
Segment跟Chunk
Segment是Druid數據存儲的最小單元,內部采用列式存儲,建立了位圖索引,對數據進行了編碼跟壓縮。
Druid數據存儲的攝取方式、聚合方式、每列數據存儲的字節起始位都有存儲。
2.1.4 位圖索引
假設現有這樣一份數據:
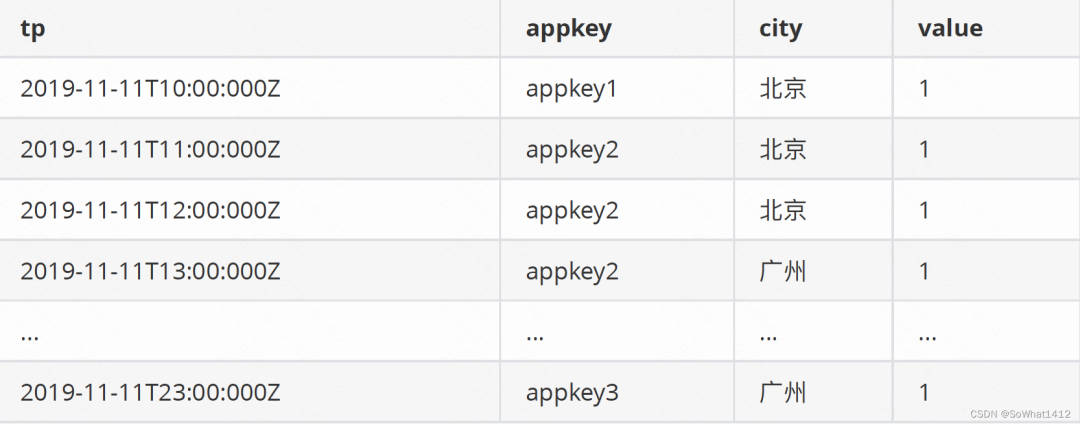
原始數據
以tp為時間列,appkey和city為維度,以value為度量值,導?Druid后按天聚合,最終結果是:
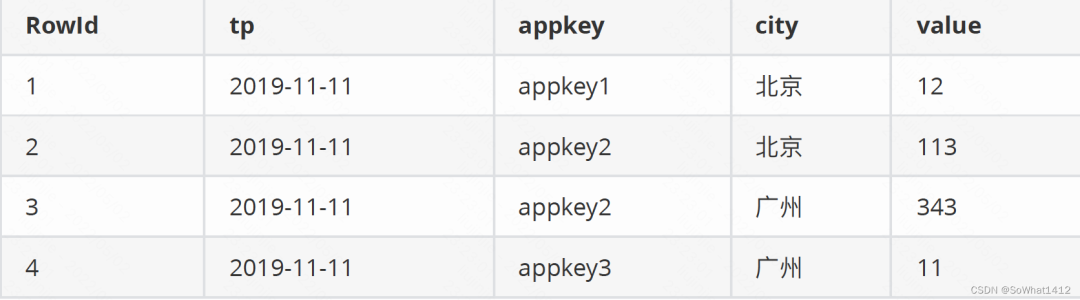
聚合后
數據經過聚合之后查詢本身就很快了,為了進?步加速對聚合之后數據的查詢,Druid會建立位圖索引:
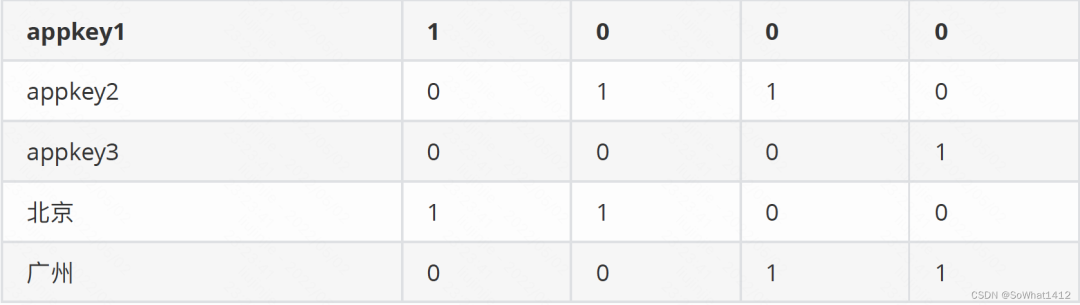
位圖索引
上?的位圖索引不是針對列?是針對列的值,記錄了列的值在數據的哪?行出現過,第一列是具體列的值,后續列標識該列的值在某??是否出現過,依次是第1列到第n列。例如appkey1在第??出現過,在其他?沒出現,那就是1000(例子中只有四個列)。
Select sum(value) from xxx where time=’2019-11-11’and appkey in
(‘appkey1’,’appkey2’) and area=’北京’
當我們有如上查詢時,?先根據時間段定位到segment,然后根據appkey in (‘appkey1’,’appkey2’) and area=’北京’ 查到各?的bitmap:(appkey1(1000) or appkey2(0110)) and 北京(1100) = (1100) 也就是說,符合條件的列是第?行和第?行,這兩?的metric的和為125.
2.2 Druid 架構
2.2.1 核心架構
Druid在架構上主要參考了Google的Dremel,PowerDrill。
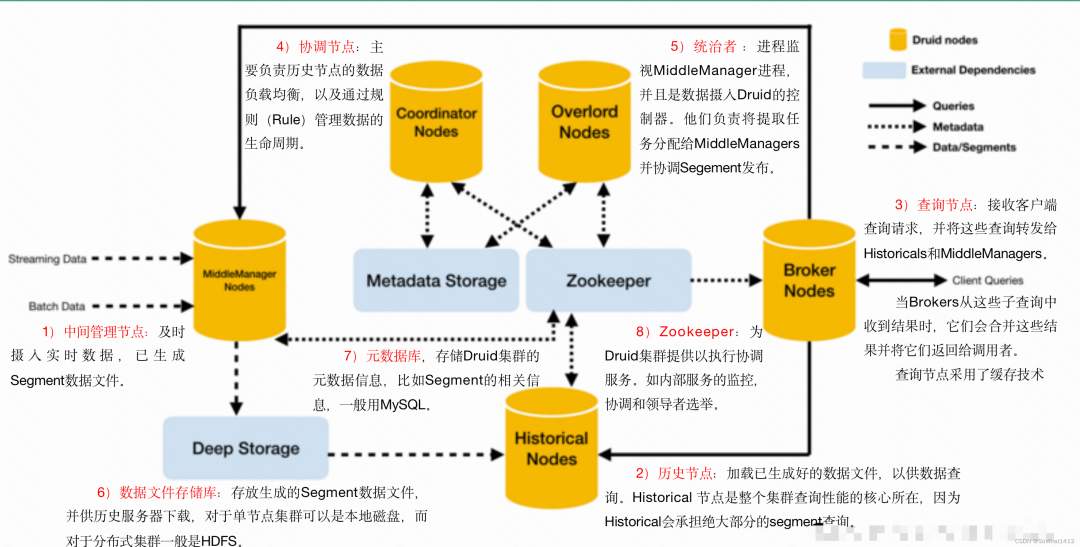
Druid官方架構圖
Druid核?架構中包括如下節點(Druid 的所有功能都在同?個包,通過不同的命令啟動):
- Coordinator: 負責集群 Segment 的管理和發布,并確保 Segment 在 Historical 集群中的負載均衡。
- Broker : 負責從客戶端接收查詢請求,并將查詢請求轉發給 Historical 節點和MiddleManager 節點。Broker 節點需要感知 Segment 信息在集群上的分布。
- Historical :負責按照規則加載Segment并提供歷史數據的查詢。
- Router(可選) :可選節點,在 Broker 集群之上的API?網關,有了 Router 節點 Broker 不不在是單點服務了,提?高了并發查詢的能力,提供類似Nginx的功能。
- Indexing Service : Indexing Service顧名思義就是指索引服務,在索引服務?成segment的過程中,由OverlordNode接收加載任務,然后?成索引任務(Index Service)并將任務分發給多個MiddleManager節點,MiddleManager節點根據索引協議?生成多個Peon,Peon將完成數據的索引任務并?成segment,并將segment提交到分布式存儲?面(?般是HDFS),然后Coordinator節點感知到segment?成,給Historical節點分發下載任務,Historical節點從分布式存儲?面下載segment到本地(?持量和流式攝取)。
- Overlord : Overlord Node負責segment生成的任務,并提供任務的狀態信息,當然原理跟上?類似,也在Zookeeper中對應的?錄下,由實際執行任務的最?單位在Zookeeper中同步更新任務信息,類似于回調函數的執?過程。跟Coordinator Node?樣,它在集群里??般只存在一個,如果存在多個Overlord Node,Zookeeper會根據選舉算法(?一致性算法避免腦裂)產?生?一個Leader,其余的當Follower,當Leader遇到問題宕機時,Zookeeper會在Follower中再次選取?一個Leader,從?維持集群?成segment服務的正常運行。Overlord Node會將任務分發給MiddleManager Node,由MiddleManager Node負責具體的segment?成任務。
- MiddleManager : Overlord Node會將任務分發給MiddleManager Node,所以MiddleManager Node會在Zookeeper中感知到新的索引任務。?但感知到新的索引任務,會創建Peon(segment具體執?者,也是索引過程的最?單位)來具體執行索引任務,一個 MiddleManager Node會運行很多個Peon的實例。
簡單來說:
- coordinator : 管理集群的數據視圖,segment的load與dropr。
- historical : 歷史節點,負責歷史窗?口內數據的查詢r。
- broker : 查詢節點,查詢拆分,結果匯聚r。
- indexing service : ?套實時/批量數據導?任務的調度服務r。
- overlord : 負責接收任務,管理理任務狀態,類似Hadoop中ResourceManager。
- middleManager : 接受任務啟動任務,類似Hadoop中NodeManager。
- peon : 實際的任務進程,類似Hadoop中的container。
總結下大致查詢鏈路,查詢打到Router, Router選擇對應的broker,broker會根據查詢時間,查詢屬性等因素來進行segment篩選。broker會查找到對應的Historical跟MiddleManager節點,這倆節點會重寫為子查詢,然后最終把結果匯總到broker,需要注意middleManager可以查詢沒有發布到歷史節點的數據,這樣Druid可以進行近實時查詢。
Druid通過下面三種優化方法提高查詢性能:
- Segment 裁剪。
- 對于每個Segment,通過索引過濾指定行。
- 制度去結果所需的行列。
2.2.2 外部依賴
- Zookeeper :主要用于內部服務發現,協調跟leader選舉。
- 深度存儲(Deep Storage) : 深度存儲服務是能夠被每個Druid服務能訪問到的共享文件系統,一般類似S3、HDFS或網絡文件系統。
- 元數據存儲(Metadata Store) : 元數據存儲服務主要用來存儲Druid中一些元數據,比如segment相關信息,跟Hadoop一樣,一般把數存儲到MySQL中。
3. 數據攝取
3.1 攝取分類
目前Druid數據攝取主要有批量跟流式兩大類。
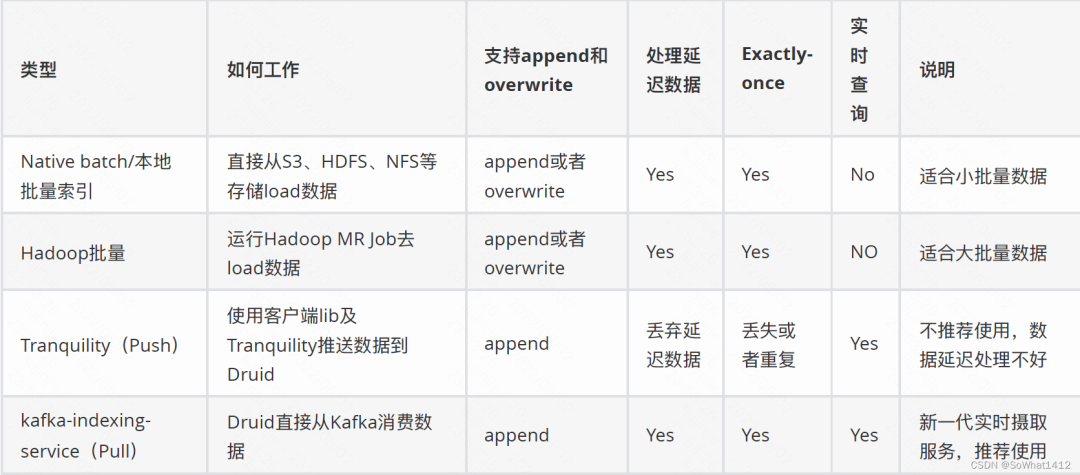
數據攝取
Druid的indexing-service即?持批量也支持流式,上表中的Native batch/本地批量索引和kafkaindexing-service(Pull)均使?用了了indexing-service,只不過通過攝取任務類型來區分。
3.2 Index Service
Index Service是運行索引相關任務的?可?性分布式服務,它的架構中包括了了Overlord、MiddleManager、Peon。簡單理解:
- Indexing Service : ?套實時/批量數據導?任務的調度服務。
- Overlord-調度服務的master節點,負責接收任務,管理理任務狀態。
- MiddleManager-worker節點,接收任務啟動任務。
- Peon-實際的任務進程(Hadoop批量索引方式下,Pero就是YARN client)。
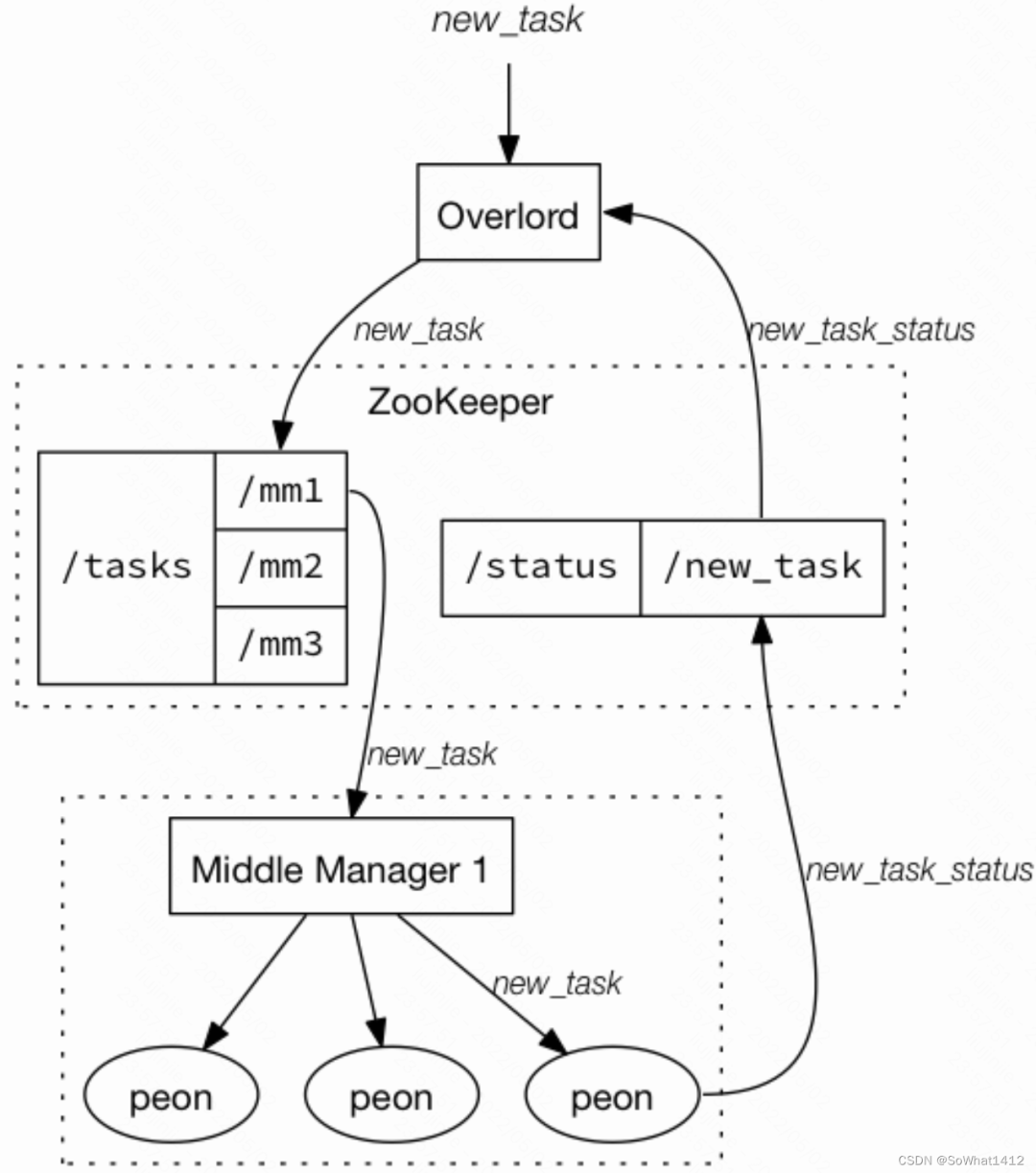
index Service工作流程
在上圖中,通過index-service的方式批量攝取數據,我們需要向Overlord提交?個索引任務,Overlord接受任務,通過Zookeeper將任務信息分配給MiddleManger,Middlemanager領取任務后創建Peon進程,Peon通過Zookeeper向Overlord定期匯報任務狀態。
3.3 攝取規則
Druid?持批量數據攝?和實時流數據攝入兩種數據攝?方式,?論是哪種?式都得指定?個攝取規則?文件(Ingestion Spec)定義攝取的詳細規則(類似于Flume采集數據都得指定?個配置文件?樣)。
數據攝取時type可指定為index、index_hadoop、kafka這三種,然后可以嘗試通過本地、HDFS、Kafka準備數據源,準備好數據攝取規則文件。
4. 查詢
Druid?直提供REST API進行數據查詢,在0.10之前第三方提供SQL?持,但不是很成熟,從0.10開始原生提供實驗性SQL查詢功能,截?Druid0.12.3還是處于實驗性階段。

查詢方式
4.1 REST API 查詢
用戶可通過REST API的方式將請求包裝為JSON格式進行查詢,返回的結果也是JSON格式,接下來主要說明下請求JSON的格式。
4.2 Filter
Filter就是過濾器,?用對維度進行行篩選和過濾,滿?Filter的行將會被返回,類似sql中的where?句。
- Selector Filte : 類似于SQL中的where colname=value。
- Regex Filter : 使用Java支持的正則表達式進行維度過濾篩選。
- In Filter : 類似于SQL中的in語句。
- Bound Filter : 比較過濾器,包含?于,等于,?于三種,它默認支持的就是字符串串?比較,如果使用數字進行比較,需要在查詢中設定alpaNumeric的值為true,需要注意的是Bound Filter默認的?小?較為>=或者<=,因此如果使用<或>,需要指定lowerStrict值為true,或者upperStrict值為true。
- Logincal Expression Filter : 包含and,not,or三種過濾器器,?持嵌套,可以構建豐富的邏輯表達式,與sql 中的and、not、or類似。
4.3 granularity
granularity 配置項指定查詢時的時間聚合粒度,查詢時的時間聚合粒度要 >= 創建索引時設置的索引粒度,druid提供了了三種類型的聚合粒度分別是:Simple、Duration、Period。
Simple :druid提供的固定時間粒度,?字符串串表示,默認就是Simple,定義查詢規則的時候不需要顯示設置type配置項,druid提供的常?用Simple粒度:
all:會將起始和結束時間內所有數據聚合到?一起返回?一個結果集,
none:按照創建索引時的最?粒度做聚合計算,最?粒度是毫秒為單位,不推薦使?,性能較差
minute:以分鐘作為聚合的最?小粒度
fifteen_minute:15分鐘聚合
thirty_minute:30分鐘聚合
hour:?小時聚合
day:天聚合
month:按年年聚合
quarter:按季度聚合
Duration : 對Simple的補充,duration聚合粒度提供了了更更加靈活的粒度,不不只局限于Simple聚合粒度提供的固定聚合粒度,?是以毫秒為單位?定義聚合粒度。
?如兩小時做?次聚合可以設置duration配置項為7200000毫秒,
所以Simple聚合粒度不能夠滿?足的聚合粒度可以選擇使?用Duration聚合粒度。
注意:使?用Duration聚合粒度需要設置配置項type值為duration。
Period : 聚合粒度采?了?期格式,常?的?種時間跨度表示?法。
一小時:PT1H
一周:P1W
?天:P1D
?月:P1M
注意: 使?Period聚合粒度需要設置配置項type值為period
4.4 Aggregator
聚合器在數據攝?和查詢是均可以使用,在數據攝?]入階段使?]用聚合器能夠在數據被查詢之前按照維度進行聚合計算,提?查詢階段聚合計算性能,在查詢過程中,使?聚合器能夠實現各種不同指標的組合計算。
公共屬性:
- type : 聲明使?用的聚合器器類型
- name : 定義返回值的字段名稱,相當于sql語法中的字段別名
- fieldName : 數據源中已定義的指標名稱,該值不可以?自定義,必須與數據源中的指標名?致
4.4.1 常見聚合器
- count
計數聚合器,等同于sql語法中的count函數,?于計算druid roll-up合并之后的數據條數,并不是原始數據條數。
在定義數據模式指標規則中必須添加?個count類型的計數指標count;
{"type":"count","name":out_name}
如果想要查詢原始數據攝?入多少條,在查詢時使?用longSum,JSON示例例如下:
{"type":"longSum","name":out_name,"fieldName":"count"}
- sum
求和聚合器,等同于sql語法中的sum函數,druid提供兩種類型的聚合器,分別是long類型和double類型的聚合器。
longSum
doubleSum
floatSum
- Min/Max
類似SQL語法中的Min/Max
longMin
longMax
doubleMin
doubleMax
floatMin
floatMax
4.4.2 去重
原生 Druid 去重功能支持情況
- 維度列
僅支持單維度,構建時需要基于該維度做 hash partition。
不能跨 interval 進行計算。
cardinality agg,非精確,基于 hll 。查詢時 hash 函數較耗費 CPU。
嵌套 group by,精確,耗費資源。
社區 DistinctCount 插件,精確,但是局限很大。
- 指標列
HyperUniques/Sketch,非精確,基于 hll,攝入時做計算,相比 cardinality agg 性能更高。
結論:Druid 缺乏一種支持預聚合、資源占用低、通用性強的精確去重支持。用戶可自己基于bitmap、unique做二次開發精確去重。
4.4.3 Post Aggregator
Post-Aggregator可以對結果進?行?次加工并輸出,最終的輸出既包含Aggregation的結果,也包含Post-Aggregator的結果,Post-Aggregator包含的類型:
- Arithmetic Post-Aggregator ?持對Aggregator的結果進行加減乘除的計算。
- Field Accessor Post-Aggregator 返回指定的Aggregator的值,在Post-Aggregator中大部分情況下使?用fieldAccess來訪問Aggregator,在fieldName中指定Aggregator里定義的name。
4.5 查詢類型
druid的查詢分為三大類,分別是聚合查詢,元數據查詢以及普通查詢。
普通的查詢:
Select
Scan
Search
聚合查詢:
Timeseries
TopN
GroupBy
元數據查詢:
Time Bounding
Segment Metadata
DataSource Metadata
普通的查詢沒什么好講的,只有一個需要注意的點,那就是select在查詢大量的數據的時候,很消耗內存,如果沒有分頁的需求,可以用scan替代。
元數據的查詢,主要不是基于業務的查詢,而是對當前表的屬性,或者是定義列的類型這一類屬性的查詢,比如xxx表中"country"是什么類型的數據,xxx表收集數據起止時間,或者當前分段的版本是什么之類的信息。
主要需要理解的是三種內置的聚合查詢,本質上做的操作是這樣的。
- timeseries: 時序查詢,實際上即是對數據基于時間點(timestamp)的一次上卷。適合用來看某幾個度量在一個時間段內的趨勢。排序可按時間降序或升序。
- topN: 在時間點的基礎上,又增加了一個維度(OLAP的概念算兩個維度),進而對源數據進行切片,切片之后分別上卷,最后返回一個聚合集,你可以指定某個指標作為排序的依據。官方文檔稱這對比單個druid dimension 的groupBy 更高效。適合看某個維度下的時間趨勢,(比如美國和中國十年內GDP的增長趨勢比對,在這里除了時間外國家就是另外一個維度)。
- GroupBy: 適用于兩個維度以上的查詢,druid會根據維度切塊,并且分別上卷,最后返回聚合集。相對于topN而言,這是一個向下鉆取的操作,每多一個維度意味著保留更多的細節。(比如增加一個行業的維度,就可以知道美國和中國十年內,每一年不同行業貢獻GDP的占比)。
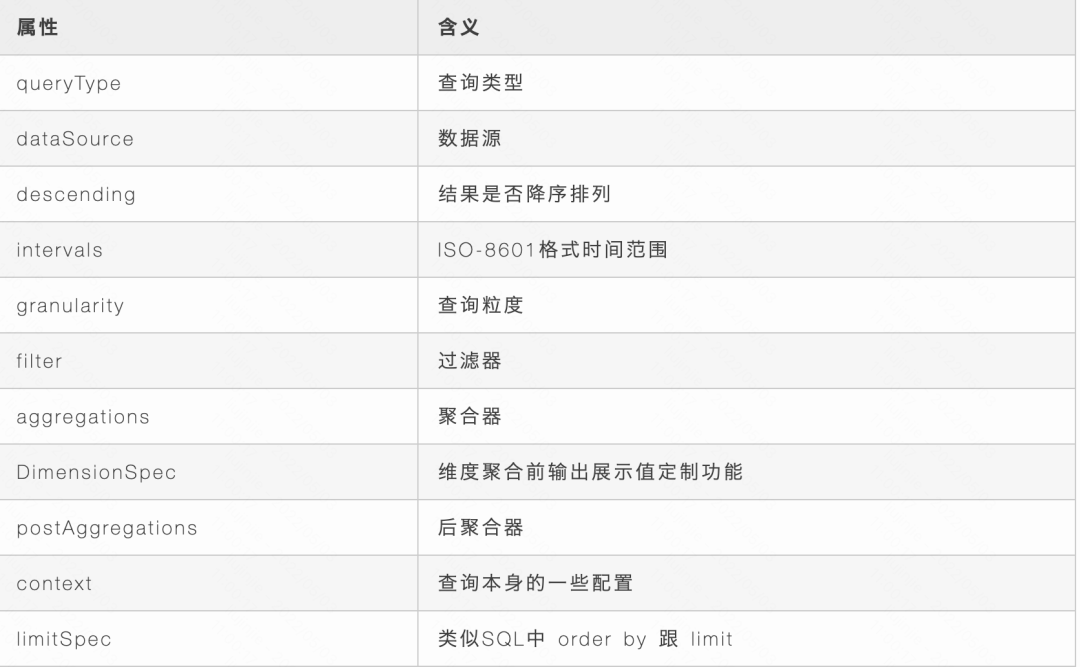
一般在查詢時需要指定若干參數的。
參考
Druid官網:https://druid.apache.org
快手Druid實戰:https://toutiao.io/posts/9pgmav/preview
















