













Redis 內(nèi)存優(yōu)化在 vivo 的探索與實(shí)踐
作者:互聯(lián)網(wǎng)服務(wù)器團(tuán)隊(duì)- Tang Wenjian
一、 背景
使用過(guò) Redis 的同學(xué)應(yīng)該都知道,它基于鍵值對(duì)(key-value)的內(nèi)存數(shù)據(jù)庫(kù),所有數(shù)據(jù)存放在內(nèi)存中,內(nèi)存在 Redis 中扮演一個(gè)核心角色,所有的操作都是圍繞它進(jìn)行。
我們?cè)趯?shí)際維護(hù)過(guò)程中經(jīng)常會(huì)被問(wèn)到如下問(wèn)題,比如數(shù)據(jù)怎么存儲(chǔ)在 Redis 里面能節(jié)約成本、提升性能?Redis內(nèi)存告警是什么原因?qū)е?
本文主要是通過(guò)分析 Redis內(nèi)存結(jié)構(gòu)、介紹內(nèi)存優(yōu)化手段,同時(shí)結(jié)合生產(chǎn)案例,幫助大家在優(yōu)化內(nèi)存使用,快速定位 Redis 相關(guān)內(nèi)存異常問(wèn)題。
二、 Redis 內(nèi)存管理
本章詳細(xì)介紹 Redis 是怎么管理各內(nèi)存結(jié)構(gòu)的,然后主要介紹幾個(gè)占用內(nèi)存可能比較多的內(nèi)存結(jié)構(gòu)。首先我們看下Redis 的內(nèi)存模型。
內(nèi)存模型如圖:
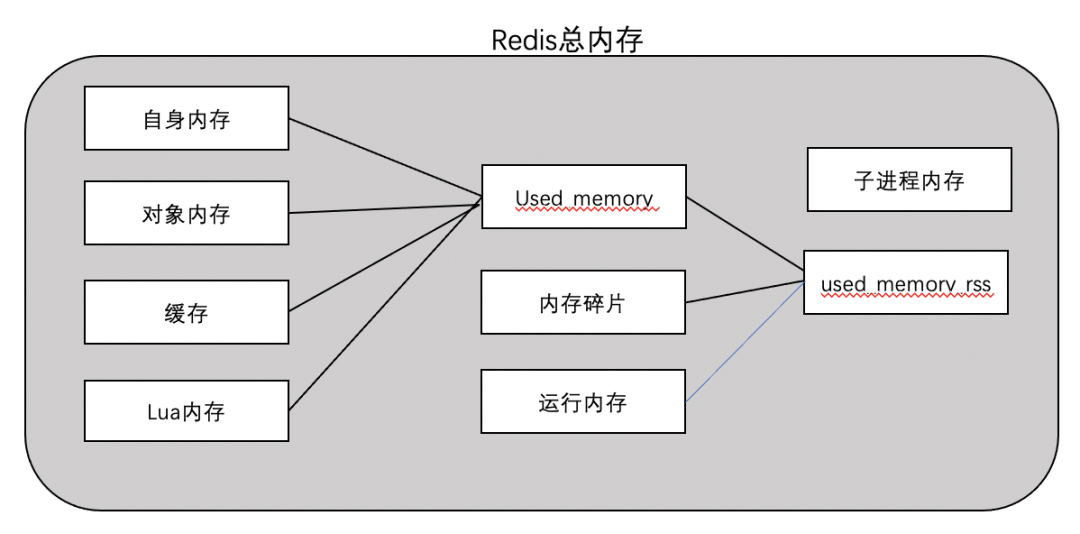
- 【used_memory】:Redis內(nèi)存占用中最主要的部分,Redis分配器分配的內(nèi)存總量(單位是KB)(在編譯時(shí)指定編譯器,默認(rèn)是jemalloc),主要包含自身內(nèi)存(字典、元數(shù)據(jù))、對(duì)象內(nèi)存、緩存,lua內(nèi)存。
- 【自身內(nèi)存】:自身維護(hù)的一些數(shù)據(jù)字典及元數(shù)據(jù),一般占用內(nèi)存很低。
- 【對(duì)象內(nèi)存】:所有對(duì)象都是Key-Value型,Key對(duì)象都是字符串,Value對(duì)象則包括5種類(lèi)(String,List,Hash,Set,Zset),5.0還支持stream類(lèi)型。
- 【緩存】:客戶(hù)端緩沖區(qū)(普通 + 主從復(fù)制 + pubsub)以及aof緩沖區(qū)。
- 【Lua內(nèi)存】:主要是存儲(chǔ)加載的 Lua 腳本,內(nèi)存使用量和加載的 Lua 腳本數(shù)量有關(guān)。
- 【used_memory_rss】:Redis 主進(jìn)程占據(jù)操作系統(tǒng)的內(nèi)存(單位是KB),是從操作系統(tǒng)角度得到的值,如top、ps等命令。
- 【內(nèi)存碎片】:如果對(duì)數(shù)據(jù)的更改頻繁,可能導(dǎo)致redis釋放的空間在物理內(nèi)存中并沒(méi)有釋放,但redis又無(wú)法有效利用,這就形成了內(nèi)存碎片。
- 【運(yùn)行內(nèi)存】:運(yùn)行時(shí)消耗的內(nèi)存,一般占用內(nèi)存較低,在10M內(nèi)。
- 【子進(jìn)程內(nèi)存】:主要是在持久化的時(shí)候,aof rewrite或者rdb產(chǎn)生的子進(jìn)程消耗的內(nèi)存,一般也是比較小。
2.1 對(duì)象內(nèi)存
對(duì)象內(nèi)存存儲(chǔ) Redis 所有的key-value型數(shù)據(jù)類(lèi)型,key對(duì)象都是 string 類(lèi)型,value對(duì)象主要有五種數(shù)據(jù)類(lèi)型String、List、Hash、Set、Zset,不同類(lèi)型的對(duì)象通過(guò)對(duì)應(yīng)的編碼各種封裝,對(duì)外定義為RedisObject結(jié)構(gòu)體,RedisObject都是由字典(Dict)保存的,而字典底層是通過(guò)哈希表來(lái)實(shí)現(xiàn)的。通過(guò)哈希表中的節(jié)點(diǎn)保存字典中的鍵值對(duì),結(jié)構(gòu)如下:

(來(lái)源:書(shū)籍《Redis設(shè)計(jì)與實(shí)現(xiàn)》)
為了達(dá)到極大的提高 Redis 的靈活性和效率,Redis 根據(jù)不同的使用場(chǎng)景來(lái)對(duì)一個(gè)對(duì)象設(shè)置不同的編碼,從而優(yōu)化某一場(chǎng)景下的效率。
各類(lèi)對(duì)象選擇編碼的規(guī)則如下:
string (字符串)
- 【int】:(整數(shù)且數(shù)字長(zhǎng)度小于20,直接記錄在ptr*里面)
- 【embstr】: (連續(xù)分配的內(nèi)存(字符串長(zhǎng)度小于等于44字節(jié)的字符串))
- 【raw】: 動(dòng)態(tài)字符串(大于44個(gè)字節(jié)的字符串,同時(shí)字符長(zhǎng)度小于 512M(512M是字符串的大小限制))
list (列表)
- 【ziplist】:(元素個(gè)數(shù)小于hash-max-ziplist-entries配置(默認(rèn)512個(gè)),同時(shí)所有值都小于hash-max-ziplist-value配置(默認(rèn)64個(gè)字節(jié)))
- 【linkedlist】:(當(dāng)列表類(lèi)型無(wú)法滿(mǎn)足ziplist的條件時(shí),Redis會(huì)使用linkedlist作為列表的內(nèi)部實(shí)現(xiàn))
- 【quicklist】:(Redis 3.2 版本引入了 quicklist 作為 list 的底層實(shí)現(xiàn),不再使用 linkedlist 和 ziplist 實(shí)現(xiàn))
set (集合)
- 【intset 】:(元素都是整數(shù)且元素個(gè)數(shù)小于set-max-intset-entries配置(默認(rèn)512個(gè)))
- 【hashtable】:(集合類(lèi)型無(wú)法滿(mǎn)足intset的條件時(shí)就會(huì)使用hashtable)
hash (hash列表)
- 【ziplist】:(元素個(gè)數(shù)小于hash-max-ziplist-entries配置(默認(rèn)512個(gè)),同時(shí)任意一個(gè)value的長(zhǎng)度都小于hash-max-ziplist-value配置(默認(rèn)64個(gè)字節(jié)))
- 【hashtable】:(hash類(lèi)型無(wú)法滿(mǎn)足intset的條件時(shí)就會(huì)使用hashtable
zset(有序集合)
- 【ziplist】:(元素個(gè)數(shù)小于zset-max-ziplist-entries配置(默認(rèn)128個(gè))同時(shí)每個(gè)元素的value小于zset-max-ziplist-value配置(默認(rèn)64個(gè)字節(jié)))
- 【skiplist】:(當(dāng)ziplist條件不滿(mǎn)足時(shí),有序集合會(huì)使用skiplist作為內(nèi)部實(shí)現(xiàn))
2.2 緩沖內(nèi)存
2.2 1 客戶(hù)端緩存
客戶(hù)端緩沖指的是所有接入 Redis 服務(wù)的 TCP 連接的輸入輸出緩沖。有普通客戶(hù)端緩沖、主從復(fù)制緩沖、訂閱緩沖,這些都由對(duì)應(yīng)的參數(shù)緩沖控制大小(輸入緩沖無(wú)參數(shù)控制,最大空間為1G),若達(dá)到設(shè)定的最大值,客戶(hù)端將斷開(kāi)。
【client-output-buffer-limit】: 限制客戶(hù)端輸出緩存的大小,后面接客戶(hù)端種類(lèi)(normal、slave、pubsub)及限制大小,默認(rèn)是0,不做限制,如果做了限制,達(dá)到閾值之后,會(huì)斷開(kāi)鏈接,釋放內(nèi)存。
【repl-backlog-size】:默認(rèn)是1M,backlog是一個(gè)主從復(fù)制的緩沖區(qū),是一個(gè)環(huán)形buffer,假設(shè)達(dá)到設(shè)置的閾值,不存在溢出的問(wèn)題,會(huì)循環(huán)覆蓋,比如slave中斷過(guò)程中同步數(shù)據(jù)沒(méi)有被覆蓋,執(zhí)行增量同步就可以。backlog設(shè)置的越大,slave可以失連的時(shí)間就越長(zhǎng),受參數(shù)maxmemory限制,正常不要設(shè)置太大。
2.2 2 AOF 緩沖
當(dāng)我們開(kāi)啟了 AOF 的時(shí)候,先將客戶(hù)端傳來(lái)的命令存放在AOF緩沖區(qū),再去根據(jù)具體的策略(always、everysec、no)去寫(xiě)入磁盤(pán)中的 AOF 文件中,同時(shí)記錄刷盤(pán)時(shí)間。
AOF 緩沖沒(méi)法限制,也不需要限制,因?yàn)橹骶€(xiàn)程每次進(jìn)行 AOF會(huì)對(duì)比上次刷盤(pán)成功的時(shí)間;如果超過(guò)2s,則主線(xiàn)程阻塞直到fsync同步完成,主線(xiàn)程被阻塞的時(shí)候,aof_delayed_fsync狀態(tài)變量記錄會(huì)增加。因此 AOF 緩存只會(huì)存幾秒時(shí)間的數(shù)據(jù),消耗內(nèi)存比較小。
2.3 內(nèi)存碎片
程序出現(xiàn)內(nèi)存碎片是個(gè)很常見(jiàn)的問(wèn)題,Redis的默認(rèn)分配器是jemalloc ,它的策略是按照一系列固定的大小劃分內(nèi)存空間,例如 8 字節(jié)、16 字節(jié)、32 字節(jié)、…, 4KB、8KB 等。當(dāng)程序申請(qǐng)的內(nèi)存最接近某個(gè)固定值時(shí),jemalloc 會(huì)給它分配比它大一點(diǎn)的固定大小的空間,所以會(huì)產(chǎn)生一些碎片,另外在刪除數(shù)據(jù)的時(shí)候,釋放的內(nèi)存不會(huì)立刻返回給操作系統(tǒng),但redis自己又無(wú)法有效利用,就形成碎片。
內(nèi)存碎片不會(huì)被統(tǒng)計(jì)在used_memory中,內(nèi)存碎片比率在redis info里面記錄了一個(gè)動(dòng)態(tài)值mem_fragmentation_ratio,該值是used_memory_rss / used_memory的比值, mem_fragmentation_ratio越接近1,碎片率越低,正常值在1~1.5內(nèi),超過(guò)了說(shuō)明碎片很多。
2.4 子進(jìn)程內(nèi)存
前面提到子進(jìn)程主要是為了生成 RDB 和 AOF rewrite產(chǎn)生的子進(jìn)程,也會(huì)占用一定的內(nèi)存,但是在這個(gè)過(guò)程中寫(xiě)操作不頻繁的情況下內(nèi)存占用較少,寫(xiě)操作很頻繁會(huì)導(dǎo)致占用內(nèi)存較多。
三、Redis 內(nèi)存優(yōu)化
內(nèi)存優(yōu)化的對(duì)象主要是對(duì)象內(nèi)存、客戶(hù)端緩沖、內(nèi)存碎片、子進(jìn)程內(nèi)存等幾個(gè)方面,因?yàn)檫@幾個(gè)內(nèi)存消耗比較大或者有的時(shí)候不穩(wěn)定,我們優(yōu)化內(nèi)存的方向分為如:減少內(nèi)存使用、提高性能、減少內(nèi)存異常發(fā)生。
3.1 對(duì)象內(nèi)存優(yōu)化
對(duì)象內(nèi)存的優(yōu)化可以降低內(nèi)存使用率,提高性能,優(yōu)化點(diǎn)主要針對(duì)不同對(duì)象不同編碼的選擇上做優(yōu)化。
在優(yōu)化前,我們可以了解下如下的一些知識(shí)點(diǎn):
(1)首先是字符串類(lèi)型的3種編碼,int編碼除了自身object無(wú)需分配內(nèi)存,object 的指針不需要指向其他內(nèi)存空間,無(wú)論是從性能還是內(nèi)存使用都是最優(yōu)的,embstr是會(huì)分配一塊連續(xù)的內(nèi)存空間,但是假設(shè)這個(gè)value有任何變化,那么value對(duì)象會(huì)變成raw編碼,而且是不可逆的。
(2)ziplist 存儲(chǔ) list 時(shí)每個(gè)元素會(huì)作為一個(gè) entry; 存儲(chǔ) hash 時(shí) key 和 value 會(huì)作為相鄰的兩個(gè) entry; 存儲(chǔ) zset 時(shí) member 和 score 會(huì)作為相鄰的兩個(gè)entry,當(dāng)不滿(mǎn)足上述條件時(shí),ziplist 會(huì)升級(jí)為 linkedlist, hashtable 或 skiplist 編碼。
(3)在任何情況下大內(nèi)存的編碼都不會(huì)降級(jí)為 ziplist。
(4)linkedlist 、hashtable 便于進(jìn)行增刪改操作但是內(nèi)存占用較大。
(5)ziplist 內(nèi)存占用較少,但是因?yàn)槊看涡薷亩伎赡苡|發(fā) realloc 和 memcopy, 可能導(dǎo)致連鎖更新(數(shù)據(jù)可能需要挪動(dòng))。因此修改操作的效率較低,在 ziplist 的條目很多時(shí)這個(gè)問(wèn)題更加突出。
(6)由于目前大部分redis運(yùn)行的版本都是在3.2以上,所以 List 類(lèi)型的編碼都是quicklist,它是 ziplist 組成的雙向鏈表linkedlist ,它的每個(gè)節(jié)點(diǎn)都是一個(gè)ziplist,考慮了綜合平衡空間碎片和讀寫(xiě)性能兩個(gè)維度所以使用了個(gè)新編碼quicklist,quicklist有個(gè)比較重要的參數(shù)list-max-ziplist-size,當(dāng)它取正數(shù)的時(shí)候,正數(shù)表示限制每個(gè)節(jié)點(diǎn)ziplist中的entry數(shù)量,如果是負(fù)數(shù)則只能為-1~-5,限制ziplist大小,從-1~-5的限制分別為4kb、8kb、16kb、32kb、64kb,默認(rèn)是-2,也就是限制不超過(guò)8kb。
(7)【rehash】: redis存儲(chǔ)底層很多是hashtable,客戶(hù)端可以根據(jù)key計(jì)算的hash值找到對(duì)應(yīng)的對(duì)象,但是當(dāng)數(shù)據(jù)量越來(lái)越大的時(shí)候,可能就會(huì)存在多個(gè)key計(jì)算的hash值相同,這個(gè)時(shí)候這些相同的hash值就會(huì)以鏈表的形式存放,如果這個(gè)鏈表過(guò)大,那么遍歷的時(shí)候性能就會(huì)下降,所以Redis定義了一個(gè)閾值(負(fù)載因子 loader_factor = 哈希表中鍵值對(duì)數(shù)量 / 哈希表長(zhǎng)度),會(huì)觸發(fā)漸進(jìn)式的rehash,過(guò)程是新建一個(gè)更大的新hashtable,然后把數(shù)據(jù)逐步移動(dòng)到新hashtable中。
(8)【bigkey】:bigkey一般指的是value的值占用內(nèi)存空間很大,但是這個(gè)大小其實(shí)沒(méi)有一個(gè)固定的標(biāo)準(zhǔn),我們自己定義超過(guò)10M就可以稱(chēng)之為bigkey。
優(yōu)化建議:
(1)key盡量控制在44個(gè)字節(jié)數(shù)內(nèi),走embstr編碼,embstr比raw編碼減少一次內(nèi)存分配,同時(shí)因?yàn)槭沁B續(xù)內(nèi)存存儲(chǔ),性能會(huì)更好。
(2)多個(gè)string類(lèi)型可以合并成小段hash類(lèi)型去維護(hù),小的hash類(lèi)型走ziplist是有很好的壓縮效果,節(jié)約內(nèi)存。
(3)非string的類(lèi)型的value對(duì)象的元素個(gè)數(shù)盡量不要太多,避免產(chǎn)生大key。
(4)在value的元素較多且頻繁變動(dòng),不要使用ziplist編碼,因?yàn)閦iplist是連續(xù)的內(nèi)存分配,對(duì)頻繁更新的對(duì)象并不友好,性能損耗反而大。
(5)hash類(lèi)型對(duì)象包含的元素不要太多,避免在rehash的時(shí)候消耗過(guò)多內(nèi)存。
(6)盡量不要修改ziplist限制的參數(shù)值,因?yàn)閦iplist編碼雖然可以對(duì)內(nèi)存有很好的壓縮,但是如果元素太多使用ziplist的話(huà),性能可能會(huì)有所下降。
3.2 客戶(hù)端緩沖優(yōu)化
客戶(hù)端緩存是很多內(nèi)存異常增長(zhǎng)的罪魁禍?zhǔn)祝蟛糠侄际瞧胀蛻?hù)端輸出緩沖區(qū)異常增長(zhǎng)導(dǎo)致,我們先了解下執(zhí)行命令的過(guò)程,客戶(hù)端發(fā)送一個(gè)或者通過(guò)piplie發(fā)送一組請(qǐng)求命令給服務(wù)端,然后等待服務(wù)端的響應(yīng),一般客戶(hù)端使用阻塞模式來(lái)等待服務(wù)端響應(yīng),數(shù)據(jù)在被客戶(hù)端讀取前,數(shù)據(jù)是存放在客戶(hù)端緩存區(qū),命令執(zhí)行的簡(jiǎn)易流程圖如下:

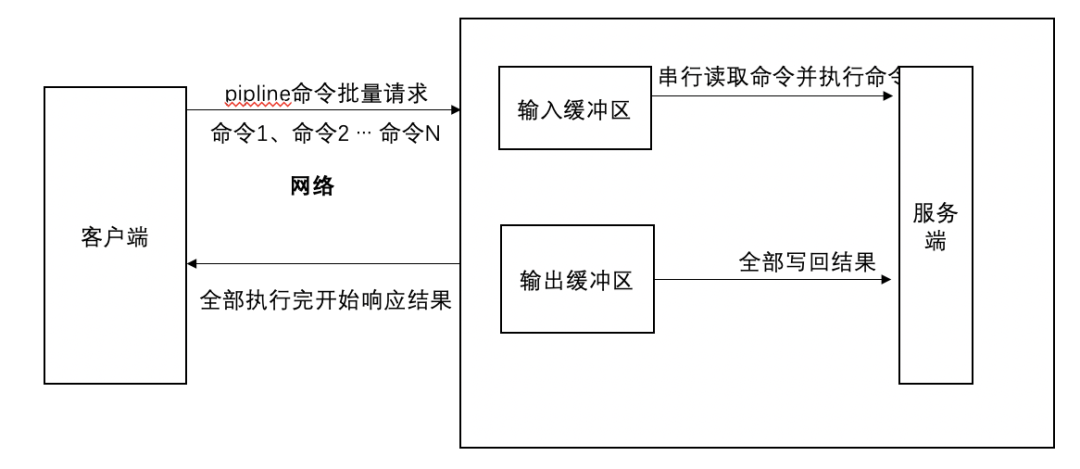
異常增長(zhǎng)原因可能如下幾種:
- 客戶(hù)端訪(fǎng)問(wèn)大key 導(dǎo)致客戶(hù)端輸出緩存異常增長(zhǎng)。
- 客戶(hù)端使用monitor命令訪(fǎng)問(wèn)Redis,monitor命令會(huì)把所有訪(fǎng)問(wèn)redis的命令持續(xù)存放到輸出緩沖區(qū),導(dǎo)致輸出緩沖區(qū)異常增長(zhǎng)。
- 客戶(hù)端為了加快訪(fǎng)問(wèn)效率,使用pipline封裝了大量命令,導(dǎo)致返回的結(jié)果集異常大(pipline的特性是等所有命令全部執(zhí)行完才返回,返回前都是暫存在輸出緩存區(qū))。
- 從節(jié)點(diǎn)應(yīng)用數(shù)據(jù)較慢,導(dǎo)致輸出主從復(fù)制輸出緩存有很多數(shù)據(jù)積壓,最后導(dǎo)致緩沖區(qū)異常增長(zhǎng)。
異常表現(xiàn):
- 在Redis的info命令返回的結(jié)果里面,client部分client_recent_max_output_buffer的值很大。
- 在執(zhí)行client list命令返回的結(jié)果集里面,omem不為0且很大,omem代表該客戶(hù)端的輸出代表緩存使用的字節(jié)數(shù)。
- 在集群中,可能少部分used_memory在監(jiān)控顯示存在異常增長(zhǎng),因?yàn)椴还苁莔onitor或者pipeline都是針對(duì)單個(gè)實(shí)例的下發(fā)的命令。
優(yōu)化建議:
- 應(yīng)用不要設(shè)計(jì)大key,大key盡量拆分。
- 服務(wù)端的普通客戶(hù)端輸出緩存區(qū)通過(guò)參數(shù)設(shè)置,因?yàn)閮?nèi)存告警的閾值大部分是使用率80%開(kāi)始,實(shí)際建議參數(shù)可以設(shè)置為實(shí)例內(nèi)存的5%~15%左右,最好不要超過(guò)20%,避免OOM。
- 非特殊情況下避免使用monitor命令或者rename該命令。
- 在使用pipline的時(shí)候,pipeline不能封裝過(guò)多的命令,特別是一些返回結(jié)果集較多的命令更應(yīng)該少封裝。
- 主從復(fù)制輸出緩沖區(qū)大小設(shè)置參考: 緩沖區(qū)大小=(主庫(kù)寫(xiě)入命令速度 * 操作大小 - 主從庫(kù)間網(wǎng)絡(luò)傳輸命令速度 * 操作大小)* 2。
3.3 碎片優(yōu)化
碎片優(yōu)化可以降低內(nèi)存使用率,提高訪(fǎng)問(wèn)效率,在4.0以下版本,我們只能使用重啟恢復(fù),重啟加載rdb或者重啟通過(guò)高可用主從切換實(shí)現(xiàn)數(shù)據(jù)的重新加載可以減少碎片,在4.0以上版本,Redis提供了自動(dòng)和手動(dòng)的碎片整理功能,原理大致是把數(shù)據(jù)拷貝到新的內(nèi)存空間,然后把老的空間釋放掉,這個(gè)是有一定的性能損耗的。
- 【a. redis手動(dòng)整理碎片】:執(zhí)行memory purge命令即可。
- 【b.redis自動(dòng)整理碎片】:通過(guò)如下幾個(gè)參數(shù)控制
- 【activedefrag yes 】:啟用自動(dòng)碎片清理開(kāi)關(guān)
- 【active-defrag-ignore-bytes 100mb】:內(nèi)存碎片空間達(dá)到多少才開(kāi)啟碎片整理
- 【active-defrag-threshold-lower 10】:碎片率達(dá)到百分之多少才開(kāi)啟碎片整理
- 【active-defrag-threshold-upper 100 】:內(nèi)存碎片率超過(guò)多少,則盡最大努力整理(占用最大資源去做碎片整理)
- 【active-defrag-cycle-min 25 】:內(nèi)存自動(dòng)整理占用資源最小百分比
- 【active-defrag-cycle-max 75】:內(nèi)存自動(dòng)整理占用資源最大百分比
3.4 子進(jìn)程內(nèi)存優(yōu)化
前面談到 AOF rewrite和 RDB 生成動(dòng)作會(huì)產(chǎn)生子進(jìn)程,正常在兩個(gè)動(dòng)作執(zhí)行的過(guò)程中,Redis 寫(xiě)操作沒(méi)有那么頻繁的情況下fork出來(lái)的子進(jìn)程是不會(huì)消耗很多內(nèi)存的,這個(gè)主要是因?yàn)?Redis 子進(jìn)程使用了 Linux 的 copy on write 機(jī)制,簡(jiǎn)稱(chēng)COW。
COW的核心是在fork出子進(jìn)程后,與父進(jìn)程共享內(nèi)存空間,只有在父進(jìn)程發(fā)生寫(xiě)操作修改內(nèi)存數(shù)據(jù)時(shí),才會(huì)真正去分配內(nèi)存空間,并復(fù)制內(nèi)存數(shù)據(jù)。
但是有一點(diǎn)需要注意,不要開(kāi)啟操作系統(tǒng)的大頁(yè)THP(Transparent Huge Pages),開(kāi)啟 THP 機(jī)制后,本來(lái)頁(yè)的大小由4KB變?yōu)? 2MB了。它雖然可以加快 fork 完成的速度( 因?yàn)橐截惖捻?yè)的數(shù)量減少 ),但是會(huì)導(dǎo)致 copy-on-write 復(fù)制內(nèi)存頁(yè)的單位從 4KB 增大為 2MB,如果父進(jìn)程有大量寫(xiě)命令,會(huì)加重內(nèi)存拷貝量,從而造成過(guò)度內(nèi)存消耗。
四、內(nèi)存優(yōu)化案例
4.1 緩沖區(qū)異常優(yōu)化案例
線(xiàn)上業(yè)務(wù) Redis 集群出現(xiàn)內(nèi)存告警,內(nèi)存使用率增長(zhǎng)很快達(dá)到100%,值班人員先進(jìn)行了緊急擴(kuò)容,同時(shí)反饋至業(yè)務(wù)群是否有大量新數(shù)據(jù)寫(xiě)入,業(yè)務(wù)反饋并無(wú)大量新數(shù)據(jù)寫(xiě)入,且同時(shí)擴(kuò)容后的內(nèi)存還在漲,很快又要觸發(fā)告警了,業(yè)務(wù) DBA 去查監(jiān)控看看具體原因。
首先我們看used_memory增長(zhǎng)只是集群的少數(shù)幾個(gè)實(shí)例,同時(shí)內(nèi)存異常的實(shí)例的key的數(shù)量并沒(méi)有異常增長(zhǎng),說(shuō)明沒(méi)有寫(xiě)入大批量數(shù)據(jù)導(dǎo)致。
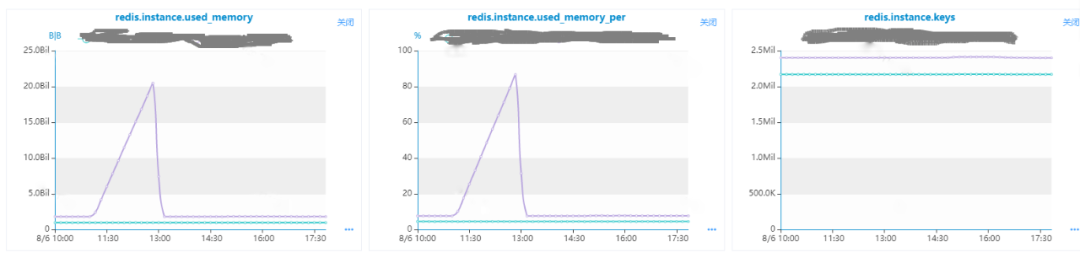
我們?cè)偻路治觯赡苁强蛻?hù)端的內(nèi)存占用異常比較大,查看實(shí)例 info 里面的客戶(hù)端相關(guān)指標(biāo),觀(guān)察發(fā)現(xiàn)output_list的增長(zhǎng)曲線(xiàn)和used_memory一致,可以判定是客戶(hù)端的輸出緩沖異常導(dǎo)致。

接下來(lái)我們?cè)偃ネㄟ^(guò)client list查看是什么客戶(hù)端導(dǎo)致output增長(zhǎng),客戶(hù)端在執(zhí)行什么命令,同時(shí)去分析是否訪(fǎng)問(wèn)大key。
執(zhí)行 client list |grep -i omem=0 發(fā)現(xiàn)如下:
id=12593807 addr=192.168.101.1:52086 fd=10767 name= age=15301 idle=0 flags=N
db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=16173 oll=341101
omem=5259227504 events=rw cmd=get
說(shuō)明下相關(guān)的幾個(gè)重點(diǎn)的字段的含義:
- 【id】:就是客戶(hù)端的唯一標(biāo)識(shí),經(jīng)常用于我們kill客戶(hù)端用到id;
- 【addr】:客戶(hù)端信息;
- 【obl】:固定緩沖區(qū)大小(字節(jié)),默認(rèn)是16K;
- 【oll】:動(dòng)態(tài)緩沖區(qū)大小(對(duì)象個(gè)數(shù)),客戶(hù)端如果每條命令的響應(yīng)結(jié)果超過(guò)16k或者固定緩沖區(qū)寫(xiě)滿(mǎn)了會(huì)寫(xiě)動(dòng)態(tài)緩沖區(qū);
- 【omem】: 指緩沖區(qū)的總字節(jié)數(shù);
- 【cmd】: 最近一次的操作命令。
可以看到緩沖區(qū)內(nèi)存占用很大,最近的操作命令也是get,所以我們先看看是否大key導(dǎo)致(我們是直接分析RDB發(fā)現(xiàn)并沒(méi)有大key),但是發(fā)現(xiàn)并沒(méi)有大key,而且get對(duì)應(yīng)的肯定是string類(lèi)型,string類(lèi)型的value最大是512M,所以單個(gè)key也不太可能產(chǎn)生這么大的緩存,所以斷定是客戶(hù)端緩存了多個(gè)key。
這個(gè)時(shí)候?yàn)榱吮M快恢復(fù),和業(yè)務(wù)溝通臨時(shí)kill該連接,內(nèi)存釋放,然后為了避免防止后面還產(chǎn)生異常,和業(yè)務(wù)方
- 【int:】 (整數(shù)且數(shù)字長(zhǎng)度小于20,直接記錄在ptr*里面)
- 【embstr】: (連續(xù)分配的內(nèi)存(字符串長(zhǎng)度小于等于44字節(jié)的字符串))
- 【raw】: 動(dòng)態(tài)字符串(大于44個(gè)字節(jié)的字符串,同時(shí)字符長(zhǎng)度小于 512M(512M是字符串的大小限制))
溝通設(shè)置普通客戶(hù)端緩存限制,因?yàn)樽畲髢?nèi)存是25G,我們把緩存設(shè)置了2G-4G, 動(dòng)態(tài)設(shè)置參數(shù)如下:
config set client-output-buffer-limit normal
4096mb 2048mb 120
因?yàn)閰?shù)限制也只是針對(duì)單個(gè)client的輸出緩沖這么大,所以還需要檢查客戶(hù)端使用使用 pipline 這種管道命令或者類(lèi)似實(shí)現(xiàn)了封裝大批量命令導(dǎo)致結(jié)果統(tǒng)一返回之前被阻塞,后面確定確實(shí)會(huì)有這個(gè)操作,業(yè)務(wù)層就需要去逐步優(yōu)化,不然我們限制了輸出緩沖,達(dá)到了上限,會(huì)話(huà)會(huì)被kill, 所以業(yè)務(wù)不改的話(huà)還是會(huì)有拋錯(cuò)。
業(yè)務(wù)方反饋用的是 C++ 語(yǔ)言 brpc 自帶的 Redis客戶(hù)端,第一次直接搜索沒(méi)有pipline的關(guān)鍵字,但是現(xiàn)象又指向使用的管道,所以繼續(xù)仔細(xì)看了下代碼,發(fā)現(xiàn)其內(nèi)部是實(shí)現(xiàn)了pipline類(lèi)似的功能,也是會(huì)對(duì)多個(gè)命令進(jìn)行封裝去請(qǐng)求redis,然后統(tǒng)一返回結(jié)果,客戶(hù)端GitHub鏈接如下:
??https://github.com/apache/incubator-brpc/blob/master/docs/cn/redis_client.md??
總結(jié):
pipline 在 Redis 客戶(hù)端中使用的挺多的,因?yàn)榇_實(shí)可以提供訪(fǎng)問(wèn)效率,但是使用不當(dāng)反而會(huì)影響訪(fǎng)問(wèn),應(yīng)該控制好訪(fǎng)問(wèn),生產(chǎn)環(huán)境也盡量加這些內(nèi)存限制,避免部分客戶(hù)端的異常訪(fǎng)問(wèn)影響全局使用。
4.2 從節(jié)點(diǎn)內(nèi)存異常增長(zhǎng)案例
線(xiàn)上 Redis 集群出現(xiàn)內(nèi)存使用率超過(guò) 95% 的災(zāi)難告警,但是該集群是有190個(gè)節(jié)點(diǎn)的集群觸發(fā)異常內(nèi)存告警的只有3個(gè)節(jié)點(diǎn)。所以查看集群對(duì)應(yīng)信息以及監(jiān)控指標(biāo)發(fā)現(xiàn)如下有用信息:
- 3個(gè)從節(jié)點(diǎn)對(duì)應(yīng)的主節(jié)點(diǎn)內(nèi)存沒(méi)有變化,從節(jié)點(diǎn)的內(nèi)存是逐步增長(zhǎng)的。
- 發(fā)現(xiàn)集群整體ops比較低,說(shuō)明業(yè)務(wù)變化并不大,沒(méi)有發(fā)現(xiàn)有效命令突增。
- 主從節(jié)點(diǎn)的最大內(nèi)存不一致,主節(jié)點(diǎn)是6G,從節(jié)點(diǎn)是5G,這個(gè)是導(dǎo)致災(zāi)難告警的重要原因。
- 在出問(wèn)題前,主節(jié)點(diǎn)比從節(jié)點(diǎn)的內(nèi)存大概多出1.3G,后面從節(jié)點(diǎn)used_memory逐步增長(zhǎng)到超過(guò)主節(jié)點(diǎn)內(nèi)存,但是rss內(nèi)存是最后保持了一樣。
- 主從復(fù)制出現(xiàn)延遲也內(nèi)存增長(zhǎng)的那個(gè)時(shí)間段。
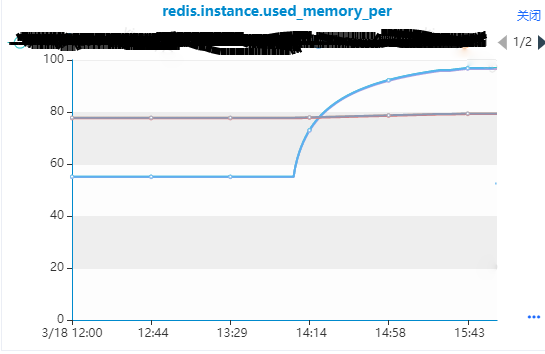


處理過(guò)程:
首先想到的應(yīng)該是保持主從節(jié)點(diǎn)最大內(nèi)存一致,但是因?yàn)橹鳈C(jī)內(nèi)存使用率比較高暫時(shí)沒(méi)法擴(kuò)容,因?yàn)橄氲降氖菑墓?jié)點(diǎn)可能什么原因阻塞,所以和業(yè)務(wù)方溝通是重啟下2從節(jié)點(diǎn)緩解下,重啟后從節(jié)點(diǎn)內(nèi)存釋放,降到發(fā)生問(wèn)題前的水平,如上圖,后面主機(jī)空出了內(nèi)存資源,所以?xún)?yōu)先把內(nèi)存調(diào)整一致。
內(nèi)存調(diào)整好了一周后,這3個(gè)從節(jié)點(diǎn)內(nèi)存又告警了,因?yàn)楝F(xiàn)在主從內(nèi)存是一致的,所以觸發(fā)的是嚴(yán)重告警(>85%),查看監(jiān)控發(fā)現(xiàn)情況是和之前一樣,猜測(cè)這個(gè)是某些操作觸發(fā)的,所以還是決定問(wèn)問(wèn)業(yè)務(wù)方這 兩個(gè)時(shí)間段都有哪些操作,業(yè)務(wù)反饋這段時(shí)間就是在寫(xiě)業(yè)務(wù),那2個(gè)時(shí)間段都是在寫(xiě)入,也看了寫(xiě)redis的那段代碼,用了一個(gè)比較少見(jiàn)的命令append,append是對(duì)string類(lèi)型的value進(jìn)行追加。
這里就得提下string類(lèi)型在 Redis 里面是怎么分配內(nèi)存的:string類(lèi)型都是都是sds存儲(chǔ),當(dāng)前分配的sds內(nèi)存空間不足存儲(chǔ)且小于1M時(shí)候,Redis會(huì)重新分配一個(gè)2倍之前內(nèi)存大小的內(nèi)存空間。
根據(jù)上面到知識(shí)點(diǎn),所以可以大致可以解析上述一系列的問(wèn)題,大概是當(dāng)時(shí)做 append 操作,從節(jié)點(diǎn)需要分配空間從而發(fā)生內(nèi)存膨脹,而主節(jié)點(diǎn)不需要分配空間,因?yàn)閮?nèi)存重新分配設(shè)計(jì)malloc和free操作,所以當(dāng)時(shí)有l(wèi)ag也是正常的。
Redis的主從本身是一個(gè)邏輯復(fù)制,加載 RDB 的過(guò)程其實(shí)也是拿到kv不斷的寫(xiě)入到從節(jié)點(diǎn),所以主從到內(nèi)存大小也經(jīng)常存在不相同的情況,特別是這種values大小經(jīng)常改變的場(chǎng)景,主從存儲(chǔ)的kv所用的空間很多可能是不一樣的。
為了證明這一猜測(cè),我們可以通過(guò)獲取一個(gè)key(value大小要比較大)在主從節(jié)點(diǎn)占用空間的大小,因?yàn)槭?.0以上版本,所以我們可以使用memory USAGE 去獲取大小,看看差異有多少,我們隨機(jī)找了幾個(gè)稍微大點(diǎn)的key去查看,發(fā)現(xiàn)在有些key從庫(kù)占用空間是主庫(kù)的近2倍,有的差不多,有的也是1倍多,rdb解析出來(lái)的這個(gè)key空間更小,說(shuō)明從節(jié)點(diǎn)重啟后加載rdb進(jìn)行存放是最小的,然后因?yàn)槟扯螘r(shí)間大批量key操作,導(dǎo)致從節(jié)點(diǎn)的大批量的key分配的空間不足,需要擴(kuò)容1倍空間,導(dǎo)致內(nèi)存出現(xiàn)增長(zhǎng)。
到這就分析的其實(shí)差不多了,因?yàn)閍ppend的特性,為了避免內(nèi)存再次出現(xiàn)內(nèi)存告警,決定把該集群的內(nèi)存進(jìn)行擴(kuò)容,控制內(nèi)存使用率在70%以下(避免可能發(fā)生的大量key使用內(nèi)存翻倍的情況)。
最后還有1個(gè)問(wèn)題:上面的used_memory為什么會(huì)比memory_rss的值還大呢?(swap是關(guān)閉的)。
這是因?yàn)閖emalloc內(nèi)存分配一開(kāi)始其實(shí)分配的是虛擬內(nèi)存,只有往分配的page頁(yè)里面寫(xiě)數(shù)據(jù)的時(shí)候才會(huì)真正分配內(nèi)存,memory_rss是實(shí)際內(nèi)存占用,used_memory其實(shí)是一個(gè)計(jì)數(shù)器,在 Redis做內(nèi)存的malloc/free的時(shí)候,對(duì)這個(gè)used_memory做加減法。
關(guān)于used_memory大于memory_rss的問(wèn)題,redis作者也做了回答:
??https://github.com/redis/redis/issues/946#issuecomment-13599772??
總結(jié):
在知曉 Redis內(nèi)存分配原理的情況下,數(shù)據(jù)庫(kù)的內(nèi)存異常問(wèn)題進(jìn)行分析會(huì)比較快速定位,另外可能某個(gè)問(wèn)題看起來(lái)和業(yè)務(wù)沒(méi)什么關(guān)聯(lián),但是我們還是應(yīng)該多和業(yè)務(wù)方溝通獲取一些線(xiàn)索排查問(wèn)題,最后主從內(nèi)存一定按照規(guī)范保持一致。
五、總結(jié)
Redis在數(shù)據(jù)存儲(chǔ)、緩存都是做了很巧妙的設(shè)計(jì)和優(yōu)化,我們?cè)诹私饬怂膬?nèi)部結(jié)構(gòu)、存儲(chǔ)方式之后,我們可以提前在key的設(shè)計(jì)上做優(yōu)化。我們?cè)谟龅絻?nèi)存異常或者性能優(yōu)化的時(shí)候,可以不再局限于表面的一些分析如:資源消耗、命令的復(fù)雜度、key的大小,還可以結(jié)合根據(jù)Redis的一些內(nèi)部運(yùn)行機(jī)制和內(nèi)存管理方式去深入發(fā)現(xiàn)是否還有可能哪些方面導(dǎo)致異常或者性能下降。






























