詳解大數據批流處理中的兩大架構
1.Lambda架構
對于在云端的數據中心實現針對海量歷史數據的批量計算(及優化),同時需要分別在云端、邊緣端實現針對流數據的實時處理的場景。換言之,為了達到全量數據批處理的準確性與實時數據流處理的低延遲的兼具,Nathan Marz基于他在Backtype和Twitter公司中對大數據處理系統的設計、開發經驗,于2013年提出了批流處理系統架構——Lambda。

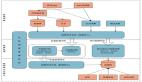
Lambda架構是當前大數據中批流處理方向影響最為深刻、應用最為廣泛的架構,主要分為以下3個組成部分:
(1)批處理層(batch layer)
該層負責兩方面的內容:1)管理“主數據庫”,即保存有完整的歷史數據、持久化存儲的、不可變的、僅支持追加的數據倉庫;2)計算批處理視圖,即通過批處理的方式對全量數據進行分析所得出的視圖。
可見,批處理部分類似于其他專用批處理系統,對大規模的數據在保證準確性和完整性的前提下,利用批處理優化技術進行全局分析。
(2)服務層(serving layer)
該層與批處理層一同工作,功能上作為應用程序進行查詢的服務器,負責對批處理層中產生的批處理視圖建立索引,以便應用程序能夠根據用戶的指定進行低延遲的、點對點(ad-hoc)的查詢。需要注意的是,這里的“低延遲”指的是用于進行查詢(query)時系統響應結果的延遲,這個時間會因為索引的建立而大大降低,但并不會改變批處理層中對全量數據進行計算更新的時間開銷。
(3)流處理層(speed layer)
上述由批處理層與服務層組成的批處理部分能夠對離線的歷史數據進行完整的分析,但如同傳統的批處理專用系統,這個處理過程將會遍歷所有已存在的數據,將不可避免地造成較大的計算開銷,并占用較長的處理時間。那么為了實現對實時數據的流式處理,便需要“流處理層”與它相結合。流處理層即基于流式處理建立的數據處理模塊,彌補了批處理部分的高延遲更新缺陷,僅用于接收最近產生的流數據,并根據它進行計算得出即時結果。這里的“計算”更準確而言應是“近似計算”,因為流處理部分并不能夠獲知全局的數據,而僅僅能夠獲取剛剛發生的事件及最近的狀態信息,但同時也由于這個原因,流處理層具備批處理模塊無法達到的視圖更新速度,能夠以高出數個數量級的響應效率,支撐用戶對于最新數據的分析要求。
在上述批處理層、服務層和流處理層的基礎上,Lambda架構的核心思想便是將數據輸入到了批處理、流處理兩個數據鏈路中,分別并行地進行計算,并在用戶進行查詢的階段,將兩個數據鏈路產生的結果(視圖)進行融合,返回給用戶。這樣,一方面,批處理模塊基于全量數據計算得出的結果保證了最終響應結果的完整性與準確性;另一方面,流處理模塊基于實時數據進行流處理獲得的即時更新保證了用戶查詢的極低延遲。
缺陷:設計和實現該架構的過程中,存在一些無法避免的問題,其中最為主要的便是開發和維護的復雜性。對于開發人員而言,實現一個較為完善的分布式處理系統需要付出很大的精力,這不僅表現在設計、編碼的過程中,更表現在效率優化、后期維護升級等方面,每一個細節的調整都可能會導致設計思路的轉變,從而造成較大的更新代價。
那么,是否能夠在盡量避免同時開發批、流兩個系統的復雜性的同時,實現基于云邊協同平臺的批流融合處理呢?換言之,能否改進批處理或流處理其中一個,以使它不足的方面達到或接近另一模塊的水平?
2.Kappa架構
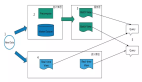
Kappa架構由來自于LinkedIn公司的Jay Kreps在2014年提出,這一架構不僅大大降低了開發人員的負擔,而且更為重要的是,使得在更高程度邊緣化的云邊協同平臺上,利用邊緣端的計算,使得批流一體化處理成為可能。
該架構提出輸入數據只通過流計算一條鏈路進行處理,并生成待查詢的視圖。它的核心是數據以日志(log)的形式,以追加(append-only)且不可變的方式,存儲在數據倉庫中。換句話說,它要求長期存儲的歷史數據能夠以有序日志流重新流入計算引擎,以備需要重新計算全局視圖時,從數據倉庫中取出這些數據進行全量計算,直到該數據副本的進度趕上當前事件發生的進度,丟棄原有視圖,將新的副本視圖作為主要結果。
利用這一架構,不僅能夠在邊緣端實現低延遲的流處理,同時也能夠實現歷史數據的批量處理。這為主要依賴于邊緣計算能力的諸多應用場景提供了有力的技術支撐。
3.其他技術
在對基于云邊協同環境下數據處理方案以及數據系統架構的研究外,相關的其他研究也在不斷嘗試、探索。其中,一個方向便是將傳統系統(例如MapReduce)中基于硬盤的存儲改進為基于內存的存儲。一方面,借助內存在硬件上天生具有的低延遲、高吞吐等特性,不論是實時的自動駕駛行車數據,還是短時高密度的健康行為統計數據,都能夠避免大量的I/O(輸入/輸出)開銷,支撐批流數據處理的速度要求;另一方面,通過檢查點(checkpoint)備份算法、自動恢復(recovery)機制等補充,實現硬盤持久化存儲的穩定性,保證了數據的可追溯、可恢復。目前,相關的研究人員已經在該研究方向上進行了長久的探索,并取得了較好的成效,實現了包括Spark在內的多個系統。
關于作者:
韓銳,北京理工大學特別研究員,博士生導師。專注于研究面向典型負載(機器學習、深度學習、互聯網服務)的云計算系統優化,在 TPDS、TC、TKDE、TSC等領域頂級(重要)期刊和INFOCOM、ICDCS、ICPP、RTSS等會議上發表超過40篇論文,Google學術引用1000 余次。
劉馳,北京理工大學計算機學院副院長,教授,博士生導師。智能信息技術北京市重點實驗室主任,國家優秀青年科學基金獲得者,國家重點研發計劃首席科學家,中國電子學會會士,英國工程技術學會會士,英國計算機學會會士。
本文摘編自《云邊協同大數據:技術與應用》,經出版方授權發布。(ISBN:9787111701002)轉載請保留文章出處。