徹底搞懂 Select / Poll / Epoll,就這篇了!
之前已經把網絡 I/O 相關要點都盤了,還剩 select/poll/epoll 這幾個區別沒說,這篇就來搞搞它們,并且是從完全理解原理的角度來區分它們。
本來是要上源碼的,但是感覺沒啥必要,身為應用開發我覺得理解原理就行了,源碼反正看了就忘了,理解才是最重要!所以我就盡量避免代碼且用大白話來盤一盤這三個玩意。
話不多說,發車。
小思考
首先,我們知道 select/poll/epoll 是用來實現多路復用的,即一個線程利用它們即可 hold 住多個 socket。
按照這個思路,線程不可被任何一個被管理的 Socket 阻塞,且任一個 Socket 來數據之后都得告知 select/poll/epoll 線程。
想想看,這應該如何實現呢?
我們拿 select 的邏輯來分析下
按照我們的理解,select 管理多個 Socket 的模型如下圖所示:
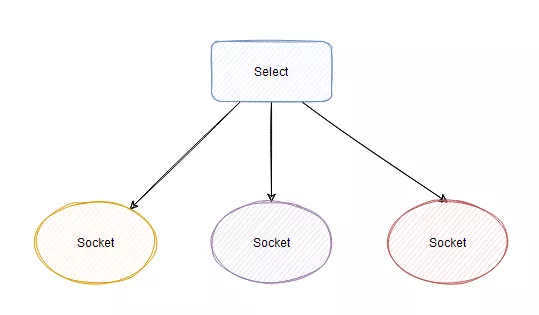
這里要注意一下內核態和用戶態的交互,用戶程序訪問不了內核空間。
所以,我們調用 select 會把所有要管理的 socket 的 fd (文件描述符,Linux下皆為文件,簡單理解就是通過 fd 能找到這個 socket)傳到內核中。
此時,要遍歷所有 socket,看看是否有感興趣的事件發生。如果沒有一個 socket 有事件發生,那么 select 的線程就需要讓出 cpu 阻塞等待,這個等待可以是不設置超時時間的死等,也可以是設置 timeout 的有超時時間的等待。
假設此時客戶端發送了數據,網卡接收到的數據塞到對應的 socket 的接收隊列中,此時 socket 知道來數據了,那如何喚醒 select 呢?
其實每個 socket 有個屬于自己的睡眠隊列,select 會安排一個內應,即在被管理的 socket 的睡眠隊列里面塞入一個 entry。
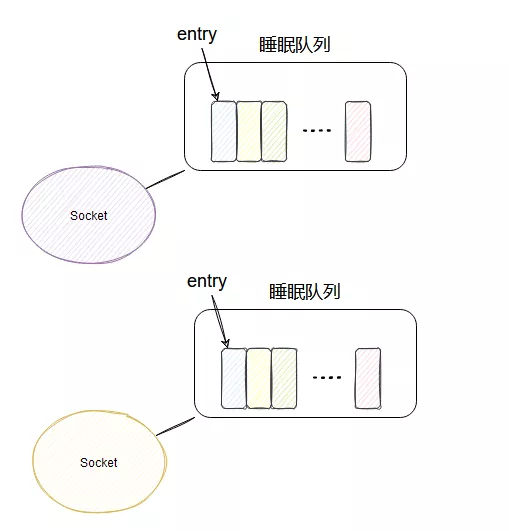
當 socket 接收到網卡的數據后,就會去它的睡眠隊列里遍歷 entry,調用 entry 設置的 callback 方法,這個 callback 方法里就能喚醒 select !
所以 select 在每個被它管理的 socket 的睡眠隊列里都塞入一個與它相關的 entry,這樣不論哪個 socket 來數據了,它立馬就能被喚醒然后干活!
但是,select 的實現不太好,因為喚醒的 select 此時只知道來活了,并不知道具體是哪個 socket 來數據了,所以只能傻傻地遍歷所有 socket ,看看到底是哪個 scoket 來活了,然后把所有來活的 socket 封裝成事件返回。
這樣用戶程序就能獲得發生的事件,然后進行 I/O 和業務處理了。
這就是 select 的實現邏輯,理解起來應該不難。
這里再提一嘴 select 的限制,因為被管理的 socket fd 需要從用戶空間拷貝到內核空間,為了控制拷貝的大小而做了限制,即每個 select 能拷貝的 fds 集合大小只有1024。
然后要改的話只能修改宏..再重新編譯內核。網上很多文章都是這樣說的,但是(沒錯有個但是)。
我看了一篇文章,確實有這個宏,值也是 1024,但內核根本沒有限制 fds 集合的大小。然后托人問了個內核大佬,大佬說內核確實沒做限制,glibc那層做了。
所以..重新編譯內核?那篇文章放文末。
poll
poll 這玩意相比于 select 主要就是優化了 fds 的結構,不再是 bit 數組了,而是一個叫 pollfd 的玩意,反正就是不用管啥 1024 的限制了。
不過現在也沒人用 poll,我就不多說了。
epoll
這個就是重點了。
相信看了 select 的實現,我們稍微思考下,就能想出幾個可以優化的點。
比如,為什么每次 select 需要把監控的 fds 傳輸到內核里?不能在內核里維護個?
為什么 socket 只喚醒 select,不能告訴它是哪個 socket 來數據了?
epoll 主要就是基于上面兩點做了優化。
首先,搞了個叫 epoll_ctl 的方法,這方法就是用來管理維護 epoll 所監控的哪些 socket。
如果你的 epoll 要新加一個 socket 來管理,那就調用 epoll_ctl,要刪除一個 socket 也調用 epoll_ctl,通過不同的入參來控制增刪改。
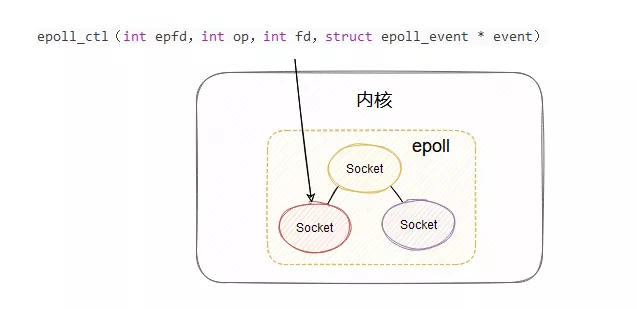
這樣,在內核里面就維護了此 epoll 管理的 socket 集合,這樣就不用每次調用的時候都得把所有管理的 fds 拷貝到內核了。
對了,這個 socket 集合是用紅黑樹實現的。
然后和 select 類似,每個 socket 的睡眠隊列里都會加個 entry,當每個 socket 來數據之后,同樣也會調用 entry 對應的 callback。
與 select 不同的是,引入了一個 ready_list 雙向鏈表,callback 里面會把當前的 socket 加入到 ready_list 然后喚醒 epoll。
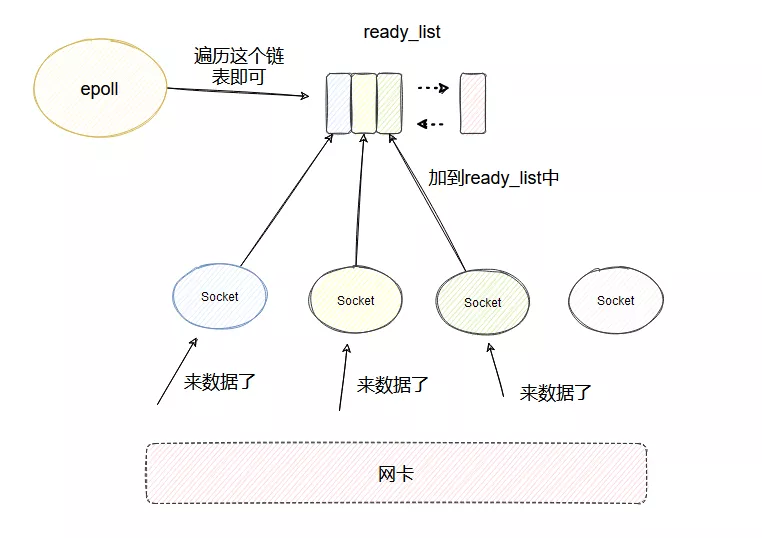
這樣被喚醒的 epoll 只需要遍歷 ready_list 即可,這個鏈表里一定是有數據可讀的 socket,相比于 select 就不會做無用的遍歷了。
同時收集到的可讀的 fd 按理是要拷貝到用戶空間的,這里又做了個優化,利用了 mmp,讓用戶空間和內核空間映射到同一塊內存中,這樣就避免了拷貝。
完美啊~
這就是 epoll 基于 select 所作的優化,還有一些差別沒細說,比如 epoll 是阻塞睡眠在一個 single_epoll_wait_list 而不是 socket 的睡眠隊列等等,我就不提了,理解上面的這些已經夠了。
ET<
都談到 epoll 了,避免不了要扯扯 ET 和 LT 兩個模式。
ET,邊沿觸發。
按照上面的邏輯就是 epoll 遍歷 ready_list 的時候,會把 socket 從 ready_list 里面移除,然后讀取這個 scoket 的事件。
而 LT,水平觸發,有點不一樣。
在這個模式下 epoll 遍歷 ready_list 的時候,會把 socket 從 ready_list 里面移除,然后讀取這個 scoket 的事件,如果這個 socket 返回了感興趣的事件,那么當前這個 socket 會再被加入到 ready_list 中,這樣下次調用 epoll_wait 的時候,還能拿到這個 socket。
這就是這兩者最本質的區別了。
看到這有人會問,這兩種模式的使用會造成哪種不一樣的結果?
如果此時一個客戶端同時發來了 5 個數據包,按正常的邏輯,只需要喚醒一次 epoll ,把當前 socket 加一次到 ready_list 就行了,不需要加 5 次。然后用戶程序可以把 socket 接收隊列的所有數據包都讀完。
但假設用戶程序就讀了一個包,然后處理報錯了,后面不讀了,那后面的 4 個包咋辦?
如果是 ET 模式,就讀不了了,因為沒有把 socket 加入到 ready_list 的觸發條件了。除非這個客戶端發了新的數據包過來,這樣才會再把當前 socket 加入到 ready_list,在新包過來之前,這 4 個數據包都不會被讀到。
而 LT 模式不一樣,因為每次讀完有感興趣的事件發生之后,會把當前 socket 再加入到 ready_list,所以下次肯定能讀到這個 socket,所以后面的 4 個數據包會被訪問到,不論客戶端是否發送新包。
至此,我想你應該理解什么是 ET ,什么是 LT 了,而不用對著一些什么狀態變更觸發這些不易理解的名詞而發暈。
最后
好了,今天的分析到此完畢,我個人覺得對 select/poll/epoll 的理解到這個程度就差不多了,當然還有很多細節,需要自行去看源碼探究,問我我也不懂,這些都是閱讀網上的源碼分析文章得出的結論。
我也不建議讀的那么深,畢竟人的精力有限對吧,有涉及到相關底層優化的時候,再去研究也不遲。
我是yes,從一點點到億點點,我們下篇見。
參考:
https://blog.csdn.net/dog250/article/details/105896693(select真的受1024限制嗎?)
https://blog.csdn.net/dog250/article/details/50528373