聊聊數據庫組件功能設計點
引言
數據庫中間件承擔應用與數據庫之間的粘合與潤滑,數據庫中間件設計的合理應用跑起來就絲滑,否則會拉胯。本文就常見數據庫組件相關的功能設計點做個歸納整理:
- 分庫分表
- 數據復制
- 數據同步平臺
- 全局唯一主鍵
- 運維自動化可視化
一、分庫分表
分庫分表組件主要為分擔數據庫壓力,通過多庫多表承接請求。盡管擁有眾多的分庫分表組件,Apache ShardingSphere作為Apache的頂級項目依舊是主流。無論直接使用還是基于其二次開發或者自研,均值得研究。
1.ShardingSphere-JDBC
客戶端直連數據庫,分布式無中心化,主要針對java語言,數據庫連接消耗多。
2.ShardingSphere-Proxy
客戶端先連接到Proxy代理,通過代理連接數據庫,能夠跨語言,消耗數據庫的連接數少(僅代理直接連接數據庫),但是中心化風險點也主要在此。
3.ShardingSphere-Sidecar
網格化代理還在規劃中,從當前螞蟻對外提供的service mesh商業方案中,還沒DB的mesh,下沉能力的同時,也帶來了數據面和控制面板的復雜性。
https://github.com/apache/shardingsphere.git
備注:當前還是客戶端直連數據庫為主流,中心化的Proxy依然有公司采納然占比依舊很少,至于Sidecar模式的大規模使用還在未來。
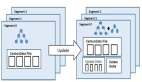
二、數據復制
1.單向搬運
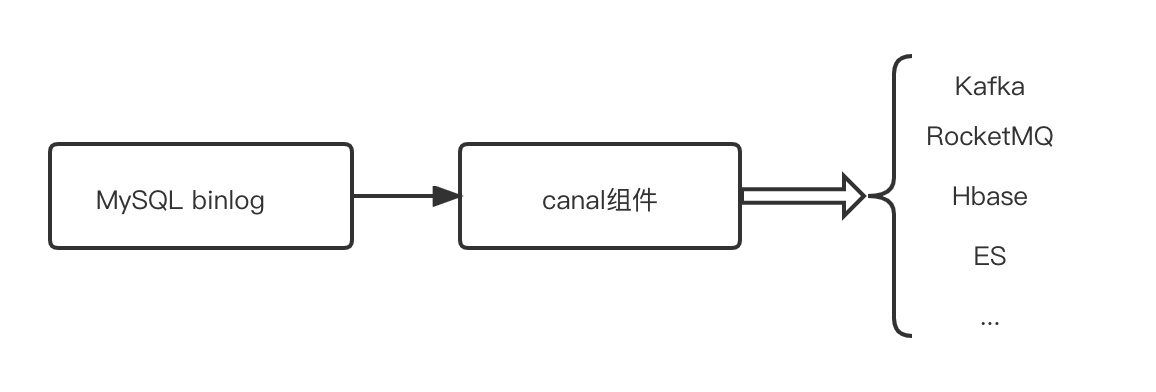
將Mysql數據同步到消息隊列或者其他數據存儲源,常用開源組件為canal。
https://github.com/alibaba/canal
2.雙/單向同步
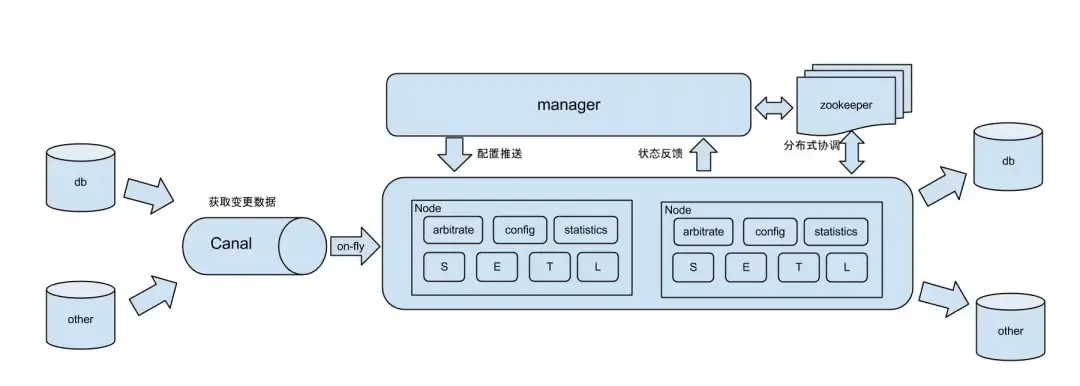
在異地多活場景中數據庫的雙向同步、跨機房災備的單向同步等場景,常用組件otter。
https://github.com/alibaba/otter
其他類似組件:dataLink、databus
https://github.com/ucarGroup/DataLink
https://github.com/linkedin/databus?
備注:在單/雙向同步場景中通常伴隨著DDL的同步。
三、數據同步平臺
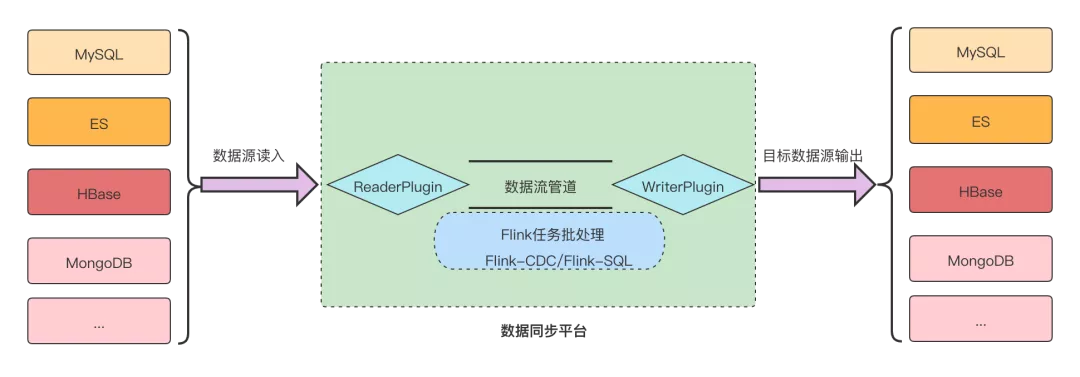
當隨著數據同步的場景越來越多,為每個不同的數據源寫一個同步插件變得復雜和不好維護,此時可以考慮搭建一個數據同步平臺。
- 通過ReaderPugin和WriterPlugin插件化
- 插件化對接入的數據源和目標數據源只需要編寫插件即可
- 數據轉換為提高吞吐性能可以引入Flink批處理框架
備注:數據同步平臺社區也有開源DataX可供參考。
https://github.com/alibaba/DataX/blob/master/introduction.md
Flink-CDC
https://github.com/ververica/flink-cdc-connectors
四、全局唯一主鍵
在分布式數據庫中最好使用分布式全局唯一ID作為數據記錄的唯一標識,原因也很簡單,主要是避免主鍵沖突。
- 跨庫數據遷移避免主鍵沖突
- 雙活數據庫雙向同步時避免主鍵沖突
- 唯一鍵設計合理對排序和識別均有良好的輔助作用
生成全局唯一ID的方案有很多,常見的有:
- UUID
- 數據庫發放不同的ID區段
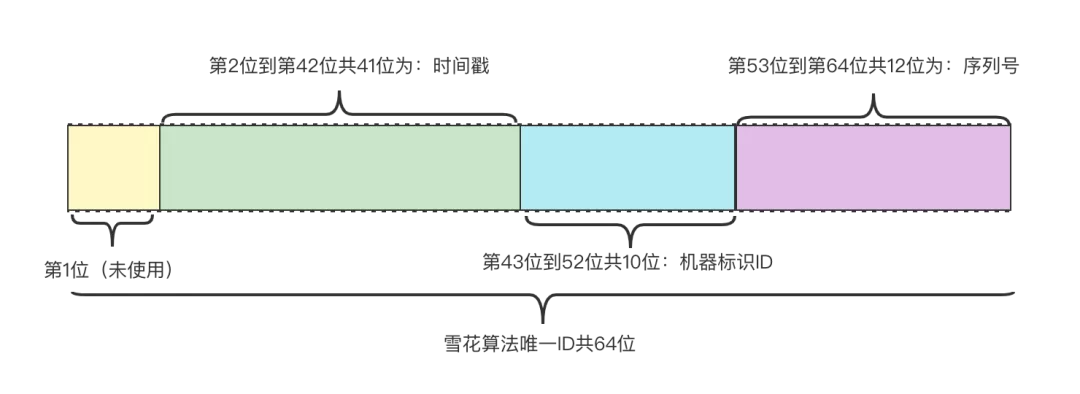
- 雪花算法(snowflake)生成唯一標識
雪花算法: 由Twitter創建生成全局唯一ID算法,一個Snowflake ID組成共64位構成如下,如果不需要這么多位可以改造縮短一些長度。
Twitter Scala 版本:
https://github.com/twitter-archive/snowflake/tree/scala_28https://github.com/twitter-archive/snowflake/releases/tag/snowflake-2010
雪花算法java版本參考:
https://github.com/beyondfengyu/SnowFlake/blob/master/SnowFlake.java
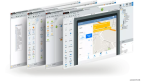
五、運維自動化可視化
將常用的一些與DB相關需要手動的創建的自動化、可視化。
- 數據庫申請與創建
- DDL變更自動化
- SQL執行結果導出
- 同步任務申請自動化
- 任務運行監控可視化