ClickHouse vs StarRocks選型對比
面向列存的DBMS新的選擇
Hadoop從誕生已經十三年了,Hadoop的供應商爭先恐后的為Hadoop貢獻各種開源插件,發明各種的解決方案技術棧,一方面確實幫助很多用戶解決了問題,但另一方面因為繁雜的技術棧與高昂的維護成本,Hadoop也漸漸地失去了原本屬于他的市場。對于用戶來說,一套高性能,簡單化,可擴展的數據庫產品能夠幫助他們解決業務痛點問題。越來越多的人將目光鎖定在列存的分布式數據庫上。
ClickHouse簡介
ClickHouse是由俄羅斯的第一大搜索引擎Yandex公司開源的列存數據庫。令人驚喜的是,ClickHouse相較于很多商業MPP數據庫,比如Vertica,InfiniDB有著極大的性能提升。除了Yandex以外,越來越多的公司開始嘗試使用ClickHouse等列存數據庫。對于一般的分析業務,結構性較強且數據變更不頻繁,可以考慮將需要進行關聯的表打平成寬表,放入ClickHouse中。
相比傳統的大數據解決方案,ClickHouse有以下的優點:
·配置豐富,只依賴與Zookeeper
·線性可擴展性,可以通過添加服務器擴展集群
·容錯性高,不同分片間采用異步多主復制
·單表性能極佳,采用向量計算,支持采樣和近似計算等優化手段
·功能強大支持多種表引擎
StarRocks簡介
StarRocks是一款極速全場景MPP企業級數據庫產品,具備水平在線擴縮容,金融級高可用,兼容MySQL協議和MySQL生態,提供全面向量化引擎與多種數據源聯邦查詢等重要特性。StarRocks致力于在全場景OLAP業務上為用戶提供統一的解決方案,適用于對性能,實時性,并發能力和靈活性有較高要求的各類應用場景。
相比于傳統的大數據解決方案,StarRocks有以下優點:
·不依賴于大數據生態,同時外表的聯邦查詢可以兼容大數據生態
·提供多種不同的模型,支持不同維度的數據建模
·支持在線彈性擴縮容,可以自動負載均衡
·支持高并發分析查詢
·實時性好,支持數據秒級寫入
·兼容MySQL 5.7協議和MySQL生態
StarRocks與ClickHouse的功能對比
StarRocks與ClickHouse有很多相似之處,比如說兩者都可以提供極致的性能,也都不依賴于Hadoop生態,底層存儲分片都提供了主主的復制高可用機制。但功能、性能與使用場景上也有差異。ClickHouse在更適用與大寬表的場景,TP的數據通過CDC工具的,可以考慮在Flink中將需要關聯的表打平,以大寬表的形式寫入ClickHouse。StarRocks對于join的能力更強,可以建立星型或者雪花模型應對維度數據的變更。
大寬表vs星型模型
ClickHouse:通過拼寬表避免聚合操作
不同于以點查為主的TP業務,在AP業務中,事實表和維度表的關聯操作不可避免。ClickHouse與StarRocks最大的區別就在于對于join的處理上。ClickHouse雖然提供了join的語義,但使用上對大表關聯的能力支撐較弱,復雜的關聯查詢經常會引起OOM。一般我們可以考慮在ETL的過程中就將事實表與維度表打平成寬表,避免在ClickHouse中進行復雜的查詢。
目前有很多業務使用寬表來解決多遠分析的問題,說明了寬表確有其獨到之處:
·在ETL的過程中處理好寬表的字段,分析師無需關心底層的邏輯就可以實現數據的分析
·寬表能夠包含更多的業務數據,看起來更直觀一些
·寬表相當于單表查詢,避免了多表之間的數據關聯,性能更好
但同時,寬表在靈活性上也帶來了一些困擾:
·寬表中的數據可能會因為join的過程中存在一對多的情況造成錯誤數據冗余
·寬表的結構維護麻煩,遇到維度數據變更的情況需要重跑寬表
·寬表需要根據業務預先定義,寬表可能無法滿足臨時新增的查詢業務
StarRocks:通過星型模型適應維度變更
可以說,拼寬表的形式是以犧牲靈活性為代價,將join的操作前置,來加速業務的查詢。但在一些靈活度要求較高的場景,比如訂單的狀態需要頻繁改變,或者說業務人員的自助BI分析,寬表往往無法滿足我們的需求。此時我們還需要使用更為靈活的星型或者雪花模型進行建模。對于星型/雪花模型的兼容度上,StarRocks的支撐要比ClickHouse好很多。
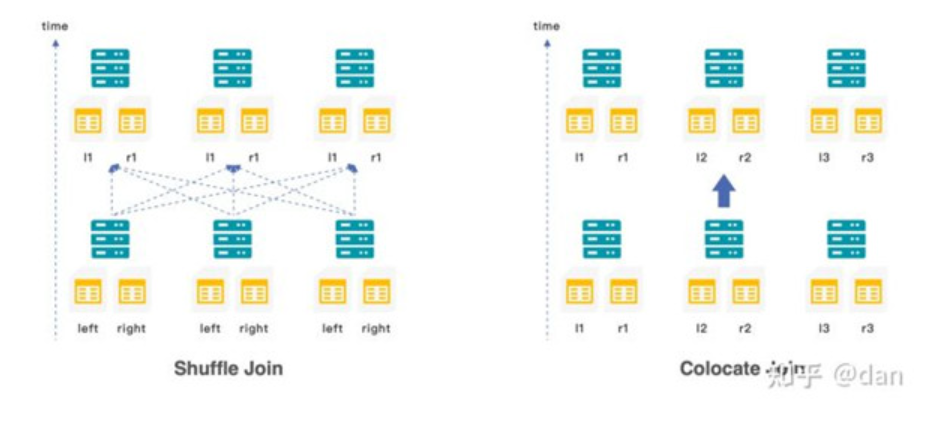
在StarRocks中提供了三種不同類型的join:
·當小表與大表關聯時,可以使用boardcast join,小表會以廣播的形式加載到不同節點的內存中
·當大表與大表關聯式,可以使用shuffle join,兩張表值相同的數據會shuffle到相同的機器上
·為了避免shuffle帶來的網絡與I/O的開銷,也可以在創建表示就將需要關聯的數據存儲在同一個colocation group中,使用colocation join
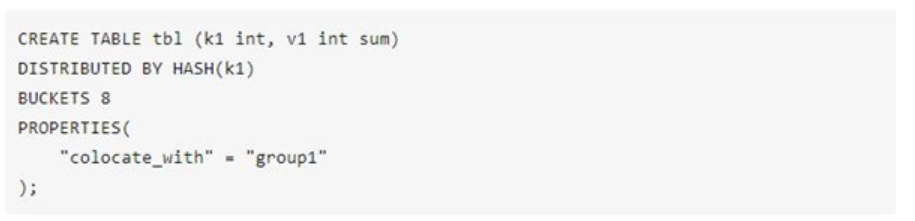
目前大部分的MPP架構計算引擎,都采用基于規則的優化器(RBO)。為了更好的選擇join的類型,StarRocks提供了基于代價的優化器(CBO)。用戶在開發業務SQL的時候,不需要考慮驅動表與被驅動表的順序,也不需要考慮應該使用哪一種join的類型,CBO會基于采集到的表的metric,自動的進行查詢重寫,優化join的順序與類型。
高并發支撐
ClickHouse對高并發的支撐
為了更深維度的挖掘數據的價值,就需要引入更多的分析師從不同的維度進行數據勘察。更多的使用者同時也帶來了更高的QPS要求。對于互聯網,金融等行業,幾萬員工,幾十萬員工很常見,高峰時期并發量在幾千也并不少見。隨著互聯網化和場景化的趨勢,業務逐漸向以用戶為中心轉型,分析的重點也從原有的宏觀分析變成了用戶維度的細粒度分析。傳統的MPP數據庫由于所有的節點都要參與運算,所以一個集群的并發能力與一個節點的并發能力相差無幾。如果一定要提高并發量,可以考慮增加副本數的方式,但同時也增加了RPC的交互,對性能和物理成本的影響巨大。
在ClickHouse中,我們一般不建議做高并發的業務查詢,對于三副本的集群,通常會將QPS控制在100以下。ClickHouse對高并發的業務并不友好,即使一個查詢,也會用服務器一半的CPU去查詢。一般來說,沒有什么有效的手段可以直接提高ClickHouse的并發量,只能考慮通過將結果集寫入MySQL中增加查詢的并發度。
StarRocks對高并發的支撐
相較于ClickHouse,StarRocks可以支撐數千用戶同時進行分析查詢,在部分場景下,高并發能力能夠達到萬級。StarRocks在數據存儲層,采用先分區再分桶的策略,增加了數據的指向性,利用前綴索引可以快讀對數據進行過濾和查找,減少磁盤的I/O操作,提升查詢性能。
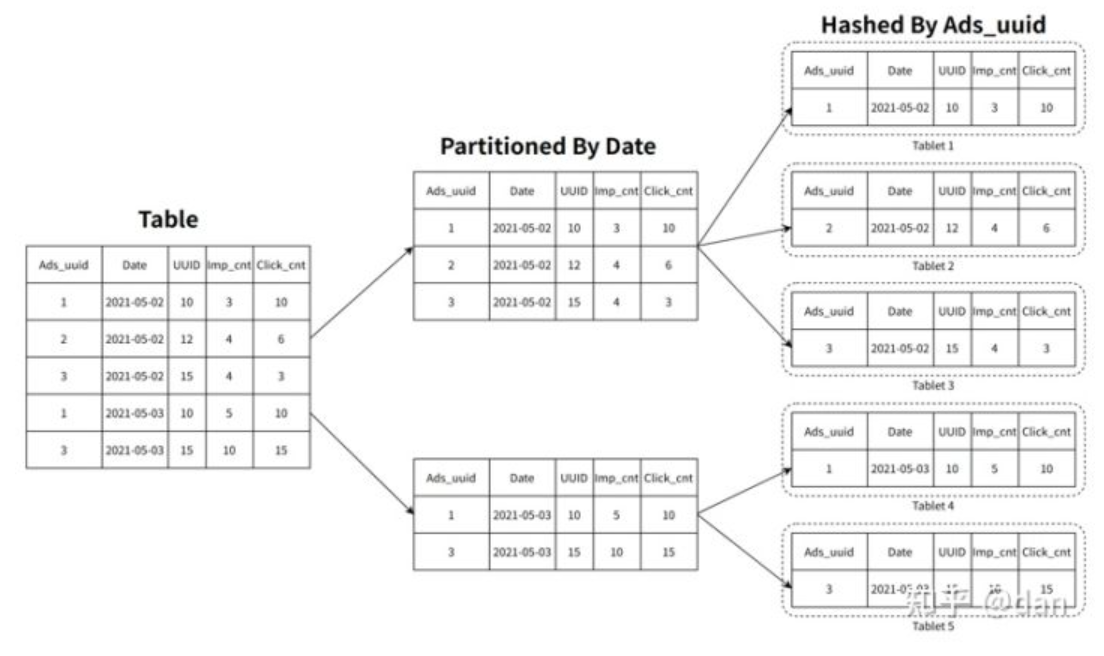
在建表的時候,分區分桶應該盡可能的覆蓋到所帶的查詢語句,這樣可以有效的利用分區分桶剪裁的功能,盡可能的減少數據的掃描量。此外,StarRocks也提供了MOLAP庫的預聚合能力。對于一些復雜的分析類查詢,可以通過創建物化視圖進行預先聚合,原有幾十億的基表,可以通過預聚合RollUp操作變成幾百或者幾千行的表,查詢時延遲會有顯著下降,并發也會有顯著提升。
數據的高頻變更
ClickHouse中的數據更新
在OLAP數據庫中,可變數據(Mutable data)通常是不受歡迎的。ClickHouse也是如此。早期的版本中并不支持UPDATE和DELETE操作。在1.15版本后,Clickhouse提供了MUTATION操作(通過ALTER TABLE語句)來實現數據的更新、刪除,但這是一種“較重”的操作,它與標準SQL語法中的UPDATE、DELETE不同,是異步執行的,對于批量數據不頻繁的更新或刪除比較有用。除了MUTATION操作,Clickhouse還可以通過CollapsingMergeTree、VersionedCollapsingMergeTree、ReplacingMergeTree結合具體業務數據結構來實現數據的更新、刪除,這三種方式都通過INSERT語句插入最新的數據,新數據會“抵消”或“替換”掉老數據,但是“抵消”或“替換”都是發生在數據文件后臺Merge時,也就是說,在Merge之前,新數據和老數據會同時存在。
針對與不同的業務場景,ClickHouse提供了不同的業務引擎來進行數據變更。
對于離線業務,可以考慮增量和全量兩種方案:
增量同步方案中,使用ReplacingMergeTree引擎,先用Spark將上游數據同步到Hive,再由Spark消費Hive中的增量數據寫入到ClickHouse中。由于只同步增量數據,對下游的壓力較小。需要確保維度數據基本不變。
全量同步方案中,使用MergeTree引擎,通過Spark將上游數據定時同步到Hive中,truncate ClickHouse中的表,隨后使用Spark消費Hive近幾天的數據一起寫入到ClickHouse中。由于是全量數據導入,對下游壓力較大,但無需考慮維度變化的問題。
對于實時業務,可以采用VersionedCollapsingMergeTree和ReplacingMergeTree兩種引擎:
使用VersionedCollapsingMergeTree引擎,先通過Spark將上游數據一次性同步到ClickHouse中,在通過Kafka消費增量數據,實時同步到ClickHouse中。但因為引入了MQ,需要保證exectly once語義,實時和離線數據連接點存在無法折疊現象。
使用ReplacingMergeTree引擎替換VersionedCollapsingMergeTree引擎,先通過Spark將上游存量數據一次性同步到ClickHouse中,在通過MQ將實時數據同步到ReplacingMergeTree引擎中,相比VersionedCollapsingMergeTree要更簡單,且離線和實時數據連接點不存在異常。但此種方案無法保重沒有重復數據。
StarRocks中的數據更新
相較于ClickHouse,StarRocks對于數據更新的操作更加簡單。
StarRocks中提供了多種模型適配了更新操作,明細召回操作,聚合操作等業務需求。更新模型可以按照主鍵進行UPDATE/DELETE操作,通過存儲和索引的優化可以在并發更新的同時高效的查詢。在某些電商場景中,訂單的狀態需要頻繁的更新,每天更新的訂單量可能上億。通過更新模型,可以很好的適配實時更新的需求。
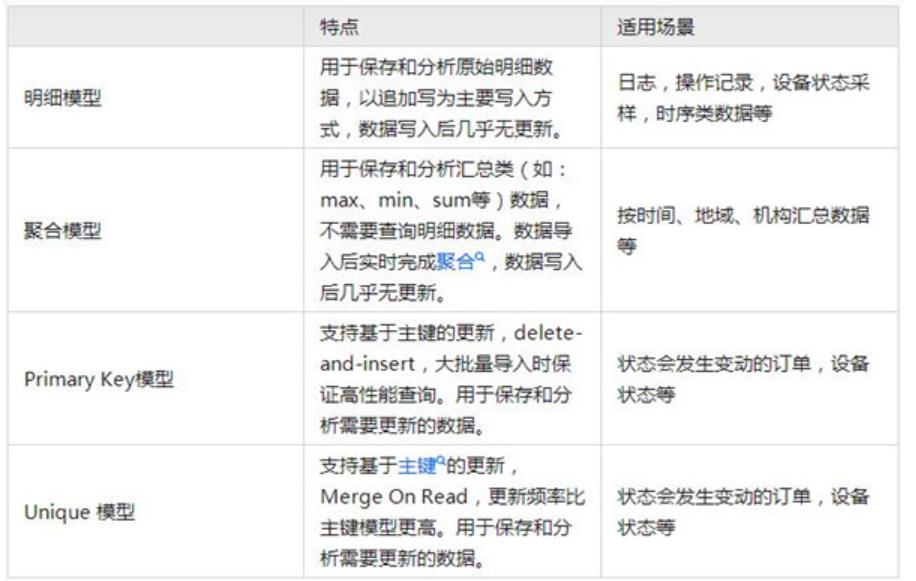
StarRocks 1.19版本之前,可以使用Unique模型進行按主鍵的更新操作,Unique模型使用的是Merge-on-Read策略,即在數據入庫的時候會給每一個批次導入數據分配一個版本號,同一主鍵的數據可能有多個版本號,在查詢的時候StarRocks會先做merge操作,返回一個版本號最新的數據。
自StarRocks 1.19版本之后發布了主鍵模型,能夠通過主鍵進行更新和刪除的操作,更友好的支持實時/頻繁更新的需求。相較于Unique模型中Merge-on-Read的模式,主鍵模型中使用的是Delete-and-Insert的更新策略,性能會有三倍左右的提升。對于前端的TP庫通過CDC實時同步到StarRocks的場景,建議使用主鍵模型。
集群的維護
相比于單實例的數據庫,任何一款分布式數據庫維護的成本都要成倍的增長。一方面是節點增多,發生故障的幾率變高。對于這種情況,我們需要一套良好的自動failover機制。另一方便隨著數據量的增長,要能做到在線彈性擴縮容,保證集群的穩定性與可用性。
ClickHouse中的節點擴容與重分布
與一般的分布式數據庫或者Hadoop生態不同,HDFS可以根據集群節點的增減自動的通過balance來調節數據均衡。但是ClickHouse集群不能自動感知集群拓撲的變化,所以就不能自動balance數據。當集群數據較大時,新增集群節點可能會給數據負載均衡帶來極大的運維成本。
一般來說,新增集群節點我們通常有三種方案:
·如果業務允許,可以給集群中的表設置TTL,長時間保留的數據會逐漸被清理到,新增的數據會自動選擇新節點,最后會達到負載均衡。
·在集群中建立臨時表,將原表中的數據復制到臨時表,再刪除原表。當數據量較大時,或者表的數量過多時,維護成本較高。同時無法應對實時數據變更。
·通過配置權重的方式,將新寫入的數據引導到新的節點。權重維護成本較高。
無論上述的哪一種方案,從時間成本,硬件資源,實時性等方面考慮,ClickHouse都不是非常適合在線做節點擴縮容及數據充分布。同時,由于ClickHouse中無法做到自動探測節點拓撲變化,我們可能需要再CMDB中寫入一套數據重分布的邏輯。所以我們需要盡可能的提前預估好數據量及節點的數量。
StarRocks中的在線彈性擴縮容
與HDFS一樣,當StarRocks集群感知到集群拓撲發生變化的時候,可以做到在線的彈性擴縮容。避免了增加節點對業務的侵入。
StarRocks中的數據采用先分區再分桶的機制進行存儲。數據分桶后,會根據分桶鍵做hash運算,結果一致的數據被劃分到同一數據分片中,我們稱之為tablet。Tablet是StarRocks中數據冗余的最小單位,通常我們會默認數據以三副本的形式存儲,節點中通過Quorum協議進行復制。當某個節點發生宕機時,在其他可用的節點上會自動補齊丟失的tablet,做到無感知的failover。
在新增節點時,也會有FE自動的進行調度,將已有節點中的tablet自動的調度到擴容的節點上,做到自動的數據片均衡。為了避免tablet遷移時對業務的性能影響,可以盡量選擇在業務低峰期進行節點的擴縮容,或者可以動態調整調度參數,通過參數控制tablet調度的速度,盡可能的減少對業務的影響。
ClickHouse與StarRocks的性能對比
單表SSB性能測試
由于ClickHouse join能力有限,無法完成TPCH的測試,這里使用SSB 100G的單表進行測試。
測試環境
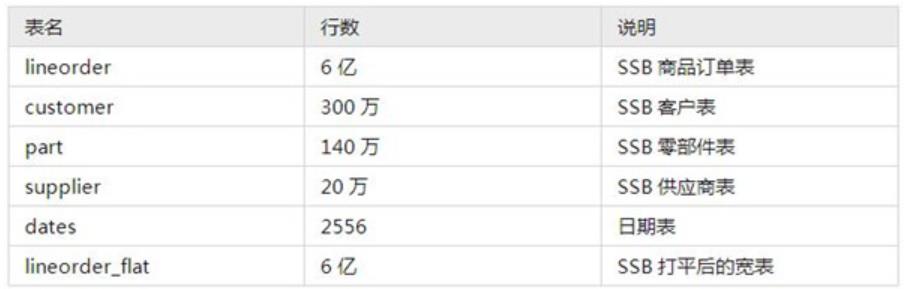
測試數據
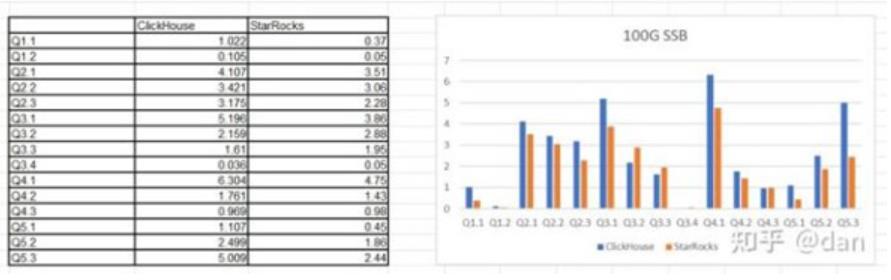
測試結果
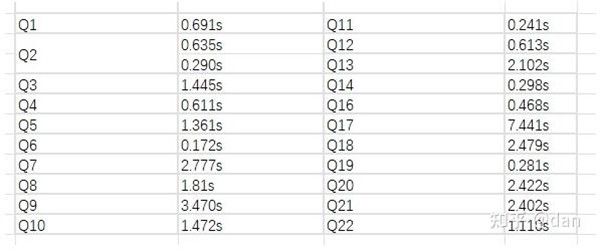
從測試結果中可以看出來,14個測試中,有9個SQL,StarRocks在性能上要超過ClickHouse。
多表TPCH性能測試
ClickHouse不擅長多表關聯的場景,對于TPCH測試機,很多查詢無法跑出,或者OOM,目前只進行了StarRocks的TPCH測試。
測試環境
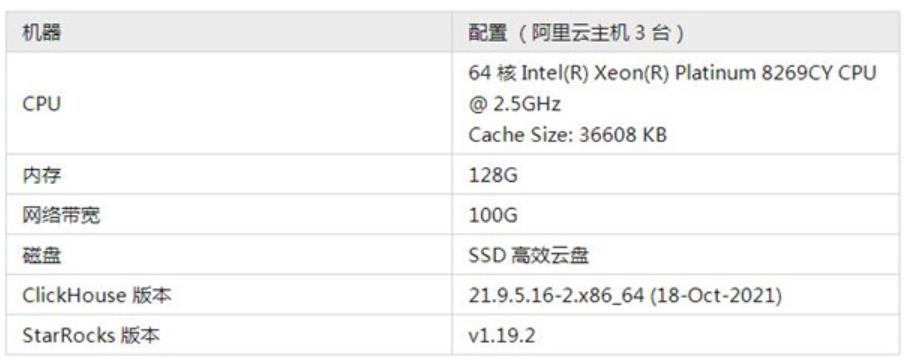
測試數據
選用TPCH 100G測試集。
測試結果
導入性能測試
無論是ClickHouse還是StarRocks,我們都可以使用DataX進行全量數據的導入,增量部分通過CDC工具寫入到MQ中在經過下游數據庫消費即可。
數據集
導入測試選取了ClickHouse Native Format數據集。1個xz格式壓縮文件大概85GB左右,解壓后原始文件1.4T,31億條數據,文件格式為CSV
導入方式
ClickHouse中采用的HDFS外表的形式。ClickHouse中分布式表只能選擇一個integer列作為Sharding Key,觀察數據發現技術都很低,因此使用rand()分布形式。
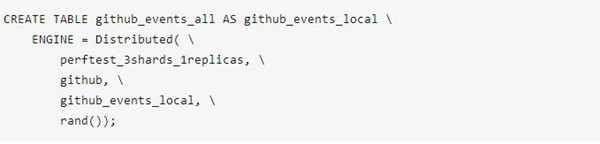
HDFS外表定義如下:
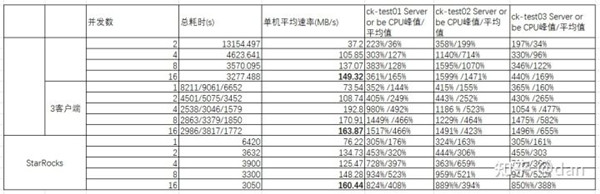
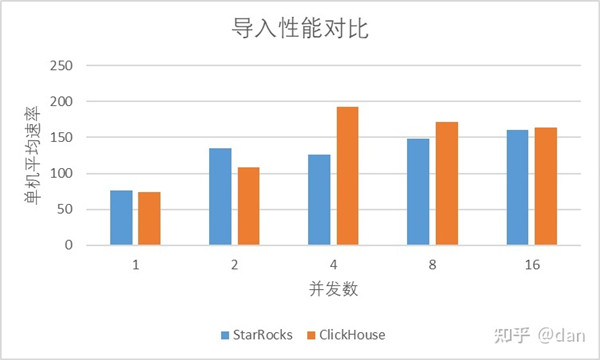
導入結果
可以看出,在使用github數據集進行導入的時候,基本上StarRocks和ClickHouse導入的性能相差不多。
結論
ClickHouse與StarRocks都是很優秀的關系新OLAP數據庫。兩者有著很多的相似之處,對于分析類查詢都提供了極致的性能,都不依賴于Hadoop生態圈。從本次的選型對比中,可以看出在一些場景下,StarRocks相較于ClickHouse有更好的表現。一般來說,ClickHouse適合于維度變化較少的拼寬表的場景,StarRocks不僅在單表的測試中有著更出色的表現,在多表關聯的場景具有更大的優勢。