Google華博士在ICCV 2021發(fā)布新模型,打個(gè)雞蛋就知道你要做煎餅
隨著機(jī)器學(xué)習(xí)的模型在現(xiàn)實(shí)世界中的應(yīng)用和部署越來越多,AI 的決策也能夠用于幫助人們在日常生活中做出決策。
在計(jì)算機(jī)視覺領(lǐng)域的決策過程中,預(yù)測(Prediction)一直都是一個(gè)核心問題。
如何在不同的時(shí)間尺度上對未來作出合理的預(yù)測也是這些機(jī)器模型的重要的能力之一,這種能力可以讓模型預(yù)測出周圍世界的變化,包括其他模型的行為,并計(jì)劃下一步如何行動(dòng)與決策。
更重要的是,成功的未來預(yù)測(future prediction)既需要捕捉環(huán)境中的有意義的物體變化,也需要了解環(huán)境如何隨著時(shí)間的推移進(jìn)行變化,以便作出決策和預(yù)測。
計(jì)算機(jī)視覺中關(guān)于未來預(yù)測的工作主要受限于其輸出的形式,輸出可能是圖像的像素或者是人工預(yù)定義的一些標(biāo)簽(例如預(yù)測某人是否會(huì)繼續(xù)行走、坐下等)。
這些預(yù)測內(nèi)容都太過詳細(xì)以至于難以完全預(yù)測成功,并且對現(xiàn)實(shí)世界信息的豐富性也缺乏有效利用。也就是說,如果一個(gè)模型在預(yù)測「跳躍行為」時(shí),并不知道為什么他們會(huì)跳躍,或者他們在跳什么等等,那就沒辦法預(yù)測成功,結(jié)果基本等于亂猜。
此外,除了極少數(shù)例外,之前的模型被設(shè)計(jì)成對未來進(jìn)行固定偏移(offset)的預(yù)測,無法進(jìn)行動(dòng)態(tài)時(shí)間間隔的預(yù)測,雖然這是一個(gè)限制性的假設(shè),因?yàn)槲覀兒苌僦篮螘r(shí)會(huì)出現(xiàn)有意義的未來狀態(tài)。

在一個(gè)制作冰淇淋的視頻中,從cream到ice cream在視頻中的時(shí)間間隔為35 秒,因此預(yù)測這種變化的模型需要提前35秒來預(yù)判。但這一間隔在不同的行為和視頻中變化很大,例如有的博主可能用了更詳細(xì)、更長時(shí)間來制作冰淇淋,也就是說在未來的任何時(shí)間都有可能制作完成冰淇淋。
此外,可以大規(guī)模、數(shù)以百萬計(jì)收集此類視頻逐幀標(biāo)注,許多教學(xué)視頻都有語音轉(zhuǎn)換記錄,通常在整個(gè)視頻中提供簡明、一般的描述。這種數(shù)據(jù)源可以引導(dǎo)模型關(guān)注視頻中的重要部分,而無需手動(dòng)標(biāo)注就能夠?qū)ξ磥硎录M(jìn)行靈活的數(shù)據(jù)驅(qū)動(dòng)預(yù)測。
基于這個(gè)思路,Google在ICCV 2021上發(fā)表了一篇文章,提出了一種自監(jiān)督的方法,使用了一個(gè)大型、未標(biāo)記的人類活動(dòng)數(shù)據(jù)集。所建立的模型具有高度的抽象性,可以任意時(shí)間間隔對未來進(jìn)行遠(yuǎn)距離預(yù)測,并能夠根據(jù)上下文選擇對未來的遠(yuǎn)期預(yù)測。

模型具有多模態(tài)周期一致性(Multi-Modal Cycle Consistency,MMCC)的目標(biāo)函數(shù),能夠利用敘事教學(xué)視頻來學(xué)習(xí)一個(gè)強(qiáng)大的未來預(yù)測模型。研究人員在文中還展示了如何在不進(jìn)行微調(diào)的情況下,將MMCC應(yīng)用于各種具有挑戰(zhàn)性的任務(wù),并對其預(yù)測進(jìn)行了量化測試實(shí)驗(yàn)。
文章的作者Chen Sun來自Google和布朗大學(xué),目前是布朗大學(xué)計(jì)算機(jī)科學(xué)助理教授,研究計(jì)算機(jī)視覺、機(jī)器學(xué)習(xí)和人工智能,也是谷歌研究所的一名研究科學(xué)家。
他在2016年博士畢業(yè)于南加州大學(xué),導(dǎo)師是Ram Nevatia教授,于2011年完成清華大學(xué)計(jì)算機(jī)科學(xué)學(xué)士學(xué)位。
正在進(jìn)行的研究項(xiàng)目包括從無標(biāo)簽視頻中學(xué)習(xí)多模式表示和視覺交流,識(shí)別人類活動(dòng)、對象及其隨時(shí)間的相互作用,并將表示轉(zhuǎn)移到embodied agents。
研究中主要解決了未來預(yù)測的三個(gè)核心問題:
1. 手動(dòng)標(biāo)注視頻中的時(shí)間關(guān)系是非常耗時(shí)耗力的,而且很難定義標(biāo)簽的正確性。所以模型應(yīng)當(dāng)能夠從大量未標(biāo)記的數(shù)據(jù)中自主學(xué)習(xí)和發(fā)現(xiàn)事件的變換,從而實(shí)現(xiàn)實(shí)際應(yīng)用。
2. 對現(xiàn)實(shí)世界中復(fù)雜的長期事件變換進(jìn)行編碼需要學(xué)習(xí)更高層次的概念,這些概念通常在抽象的潛在表示中可以找到,而非只是圖像中的像素。
3. 時(shí)序的事件變換非常依賴于上下文,所以模型必須能夠在可變時(shí)間間隔下預(yù)測未來。
為了滿足這些需求,研究人員引入了一個(gè)新的自監(jiān)督訓(xùn)練目標(biāo)函數(shù)MMCC以及一個(gè)學(xué)習(xí)表達(dá)式來解決這一問題的模型。
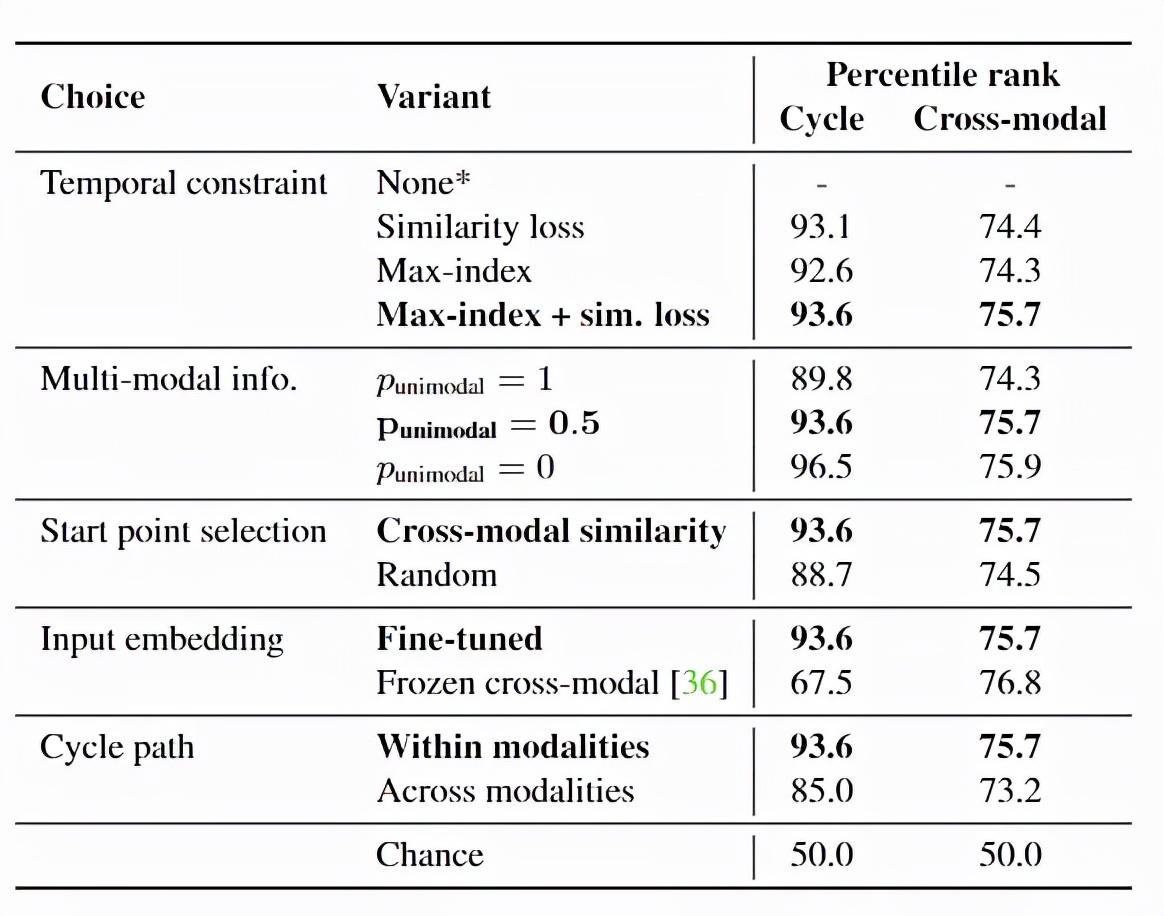
模型從敘事視頻中的一個(gè)樣本幀開始,學(xué)習(xí)如何在所有敘事文本中找到相關(guān)的語言表述。結(jié)合視覺和文本這兩種模式,該模型能夠用到整個(gè)視頻來學(xué)習(xí)到如何預(yù)測潛在未來的事件,并估計(jì)該幀的相應(yīng)語言描述,并以類似的方式學(xué)習(xí)預(yù)測過去幀的函數(shù)。
循環(huán)約束(cycle constraint)要求最終模型預(yù)測等于起始幀。
另一方面,由于該模型不知道其輸入數(shù)據(jù)來自哪個(gè)模式,因此必須在視覺和語言上共同運(yùn)作,因此無法選擇較低級(jí)別的未來預(yù)測框架。
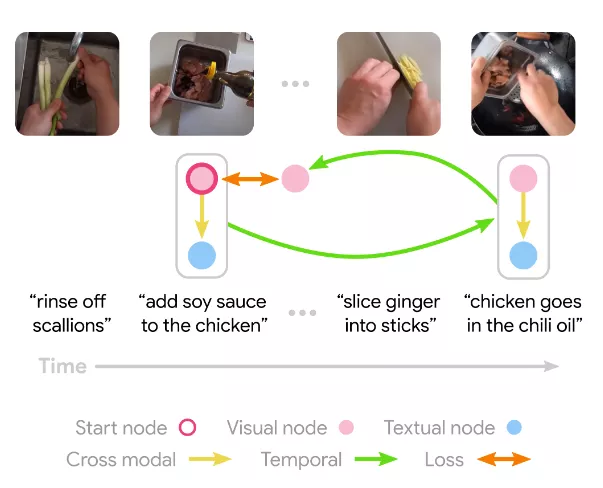
模型學(xué)習(xí)嵌入所有視覺和文本節(jié)點(diǎn),然后在其他模式下仔細(xì)計(jì)算與起始節(jié)點(diǎn)對應(yīng)的跨模式節(jié)點(diǎn)。這兩個(gè)節(jié)點(diǎn)的表示都被轉(zhuǎn)換為全連接層,預(yù)測了在初始模態(tài)下使用注意力的未來幀。然后重復(fù)backward過程,模型損失是通過預(yù)測起始節(jié)點(diǎn)來訓(xùn)練模型的最終輸出來結(jié)束循環(huán)(cycle)。
在實(shí)驗(yàn)部分,由于大多數(shù)先前的benchmark側(cè)重于具有固定類別和時(shí)間偏移的有監(jiān)督行為預(yù)測,這篇論文中研究人員設(shè)計(jì)了一系列新的定性和定量實(shí)驗(yàn)來評估不同的方法。
首先是數(shù)據(jù),研究人員在無約束的真實(shí)世界視頻數(shù)據(jù)上訓(xùn)練模型。使用HowTo100M數(shù)據(jù)集的子集,其中包含大約123萬個(gè)視頻及其自動(dòng)提取的音頻腳本。此數(shù)據(jù)集中的視頻大致按主題區(qū)域分類,并且只使用分類為 Recipe 的視頻,大約是數(shù)據(jù)集中的四分之一。
在338033個(gè)Recipe視頻中,80% 為訓(xùn)練集,15%在驗(yàn)證集,5%在測試集。Recipe視頻包含了豐富的復(fù)雜對象、操作和狀態(tài)轉(zhuǎn)換,并且該子集能夠讓開發(fā)者更快地訓(xùn)練模型。
為了進(jìn)行更多的控制測試(controlled test),研究人員使用CrossTask數(shù)據(jù)集,包含相似的視頻以及特定于任務(wù)的標(biāo)注。
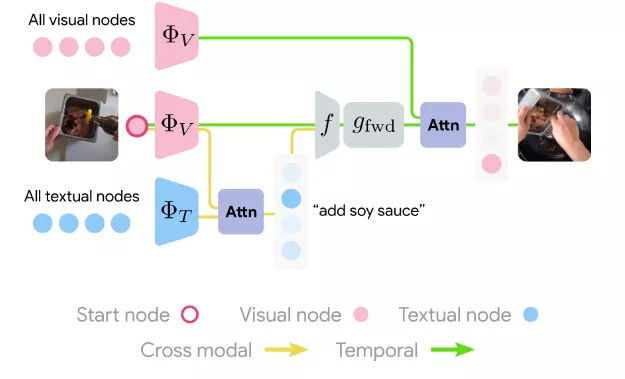
所有視頻都與任務(wù)相關(guān),例如制作煎餅等,其中每個(gè)任務(wù)都有一個(gè)預(yù)先定義的高級(jí)別子任務(wù)序列,這些子任務(wù)具有豐富的長時(shí)間的相互依賴性,例如,要先把糊弄到碗里,然后才能把雞蛋打成碗,再加入糖漿等等。
使用TOP-K召回指標(biāo)評估模型預(yù)測行動(dòng)的能力來衡量了模型預(yù)測正確未來的能力(越高越好)。
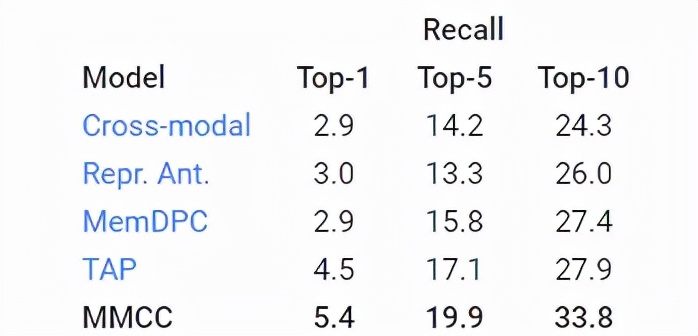
對于MMCC,為了確定整個(gè)視頻中有意義的隨時(shí)間推移的事件變化,研究人員根據(jù)模型的預(yù)測,為視頻中的每個(gè)幀對(pair)定義了一個(gè)可能的過渡分?jǐn)?shù),預(yù)測的幀越接近實(shí)際幀,則分?jǐn)?shù)越高。