復雜推理模型從服務器移植到Web瀏覽器的理論和實戰
一 背景
隨著機器學習的應用面越來越廣,能在瀏覽器中跑模型推理的Javascript框架引擎也越來越多了。在項目中,前端同學可能會找到一些跑在服務端的python算法模型,很想將其直接集成到自己的代碼中,以Javascript語言在瀏覽器中運行。
對于一部分簡單的模型,推理的前處理、后處理比較容易,不涉及復雜的科學計算,碰到這種模型,最多做個模型格式轉化,然后用推理框架直接跑就可以了,這種移植成本很低。
而很大一部分模型會涉及復雜的前處理、后處理,包括大量的矩陣運算、圖像處理等Python代碼。這種情況一般的思路就是用Javascript語言將Python代碼手工翻譯一遍,這么做的問題是費時費力還容易出錯。
Pyodide作為瀏覽器中的科學計算框架,很好的解決了這個問題:瀏覽器中運行原生的Python代碼進行前、后處理,大量numpy、scipy的矩陣、張量等計算無需翻譯為Javascript,為移植節省了很多工作。本文就基于pyodide框架,從理論和實戰兩個角度,幫助前端同學解決復雜模型的移植這一棘手問題。
二 原理篇
Pyodide是個可以在瀏覽器中跑的WebAssembly(wasm)應用。它基于CPython的源代碼進行了擴展,使用emscripten編譯成為wasm,同時也把一大堆科學計算相關的pypi包也編譯成了wasm,這樣就能在瀏覽器中解釋執行python語句進行科學計算了。所以pyodide也必然遵循wasm的各種約束。Pyodide在瀏覽器中的位置如下圖所示:?? 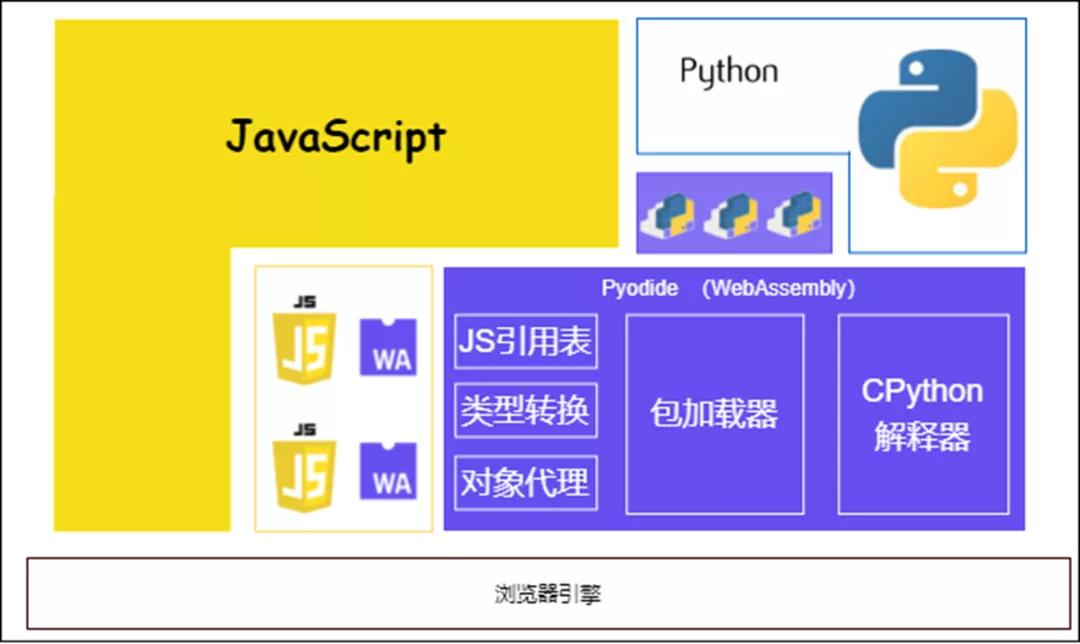
1 wasm內存布局
這是wasm線性內存的布局:
?
?? 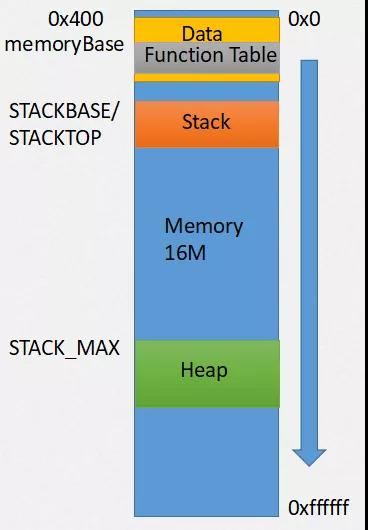
Data數據段是從0x400開始的, Function Table表也在其中,起始地址為memoryBase(Emscripten中默認為1024,即0x400),STACKTOP為棧地址起始,堆地址起始為STACK_MAX。而我們實際更關心的是Javascript內存與wasm內存的互相訪問。
2 Javascript與Python的互訪
瀏覽器基于安全方面的考慮,防止wasm程序把瀏覽器搞崩潰,通過把wasm運行在一個沙箱化的執行環境中,禁止了wasm程序訪問Javascript內存,而Javascript代碼卻可以訪問wasm內存。因為wasm內存本質上是一個巨大的ArrayBuffer,接受Javascript的管理。我們稱之為“單向內存訪問”。
作為一個wasm格式的普通程序,pyodide被調用起來后,當然只能直接訪問wasm內存。
?
?? 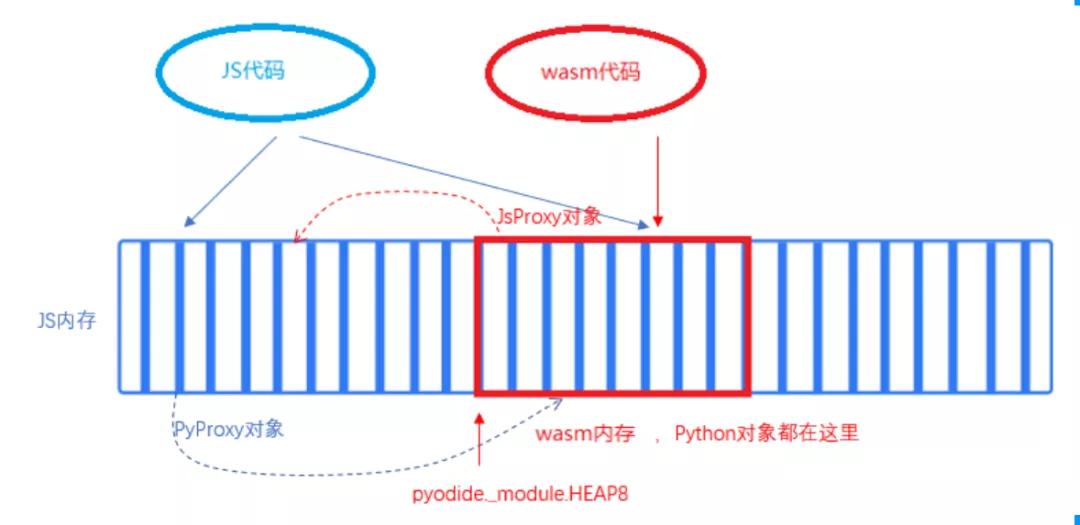
為了實現互訪,pyodide引入了proxy,類似于指針:在Javascript側,通過一個PyProxy對象來引用python內存里的對象;在Python側,通過一個JsProxy對象來引用Javascript內存里的對象。
在Javascript側生成一個PyProxy對象:
在Python側生成一個JsProxy對象:
互訪時的類型轉換分為如下三個等級:
- 【自動轉換】對于簡單類型,如數字、字符串、布爾等,會被自動拷貝內存值,此時產生的就不是Proxy、而是最終的值了。
- 【半自動轉換】非簡單的內置類型,都需要通過to_js()、to_py()方式來顯式轉換:
- 對于Python內置的list、dict、numpy.ndarray等對象,不屬于簡單類型,不會自動轉換類型,必須通過pyodide.to_js()來轉,相應的會被轉成JS的list、map、TypedArray類型
- 反過來也類似,通過to_py()方法,JS的TypedArray轉為memoryview,list、map轉為list、dict
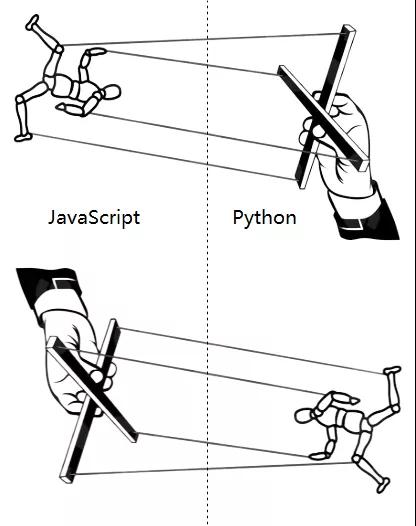
- 【手動轉換】各種class、function和用戶自定義類型,因為對方的語言沒有對應的現成類型,所以只能以proxy的形式存在,需要通過運算符來間接操縱,就像操縱提線木偶一樣。為了達到方便操縱的目的,pyodide對兩種語言進行了語法模擬,用一種語言里的操作符模擬另一種語言的類似行為。例如:JS中的let a=new XXX(),在Python中就變為a=XXX.new()。
?
?? 
這里列舉了一部分,詳情可以查文檔(見文章底部)。
?
?? 
Javascript的模塊也可以引入到Python中,這樣Python就能直接調用該模塊的接口和方法了。例如,pyodide沒有編譯opencv包,可以使用opencv.js:
這對于pyodide缺失的pypi包是個很好的補充。
三 實踐篇
我們從一個空白頁面開始。使用瀏覽器打開測試頁面(測試頁面見文章底部)。
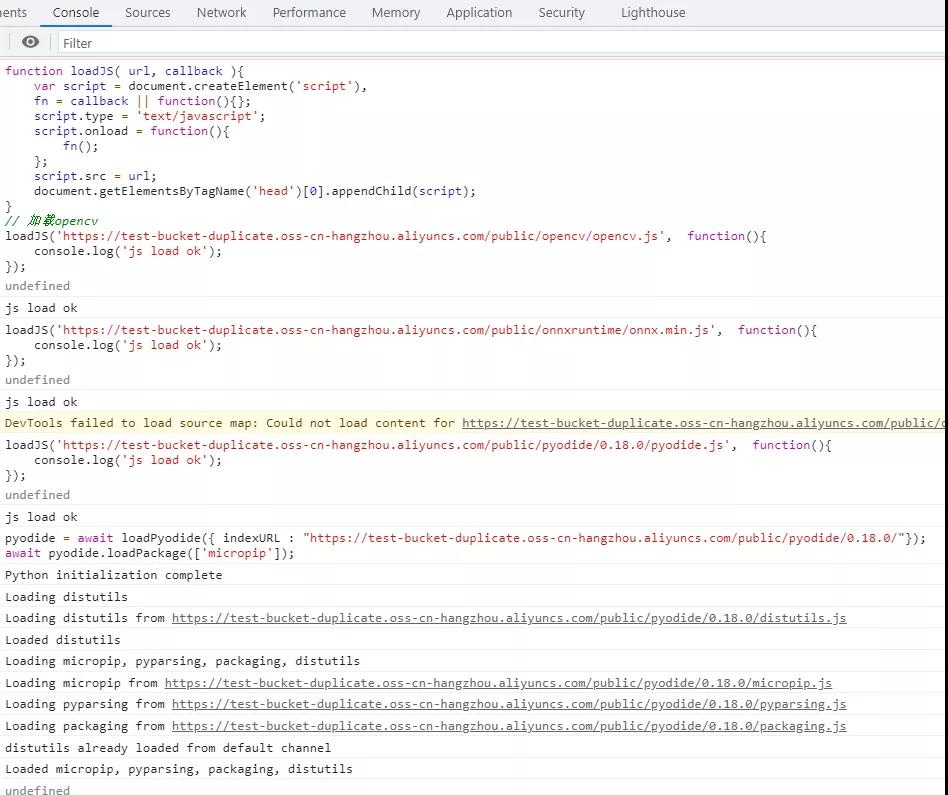
1 初始化python
為了方便觀察運行過程,使用動態的方式加載所需js和執行python代碼。打開瀏覽器控制臺,依次運行以下語句:
?
?? 
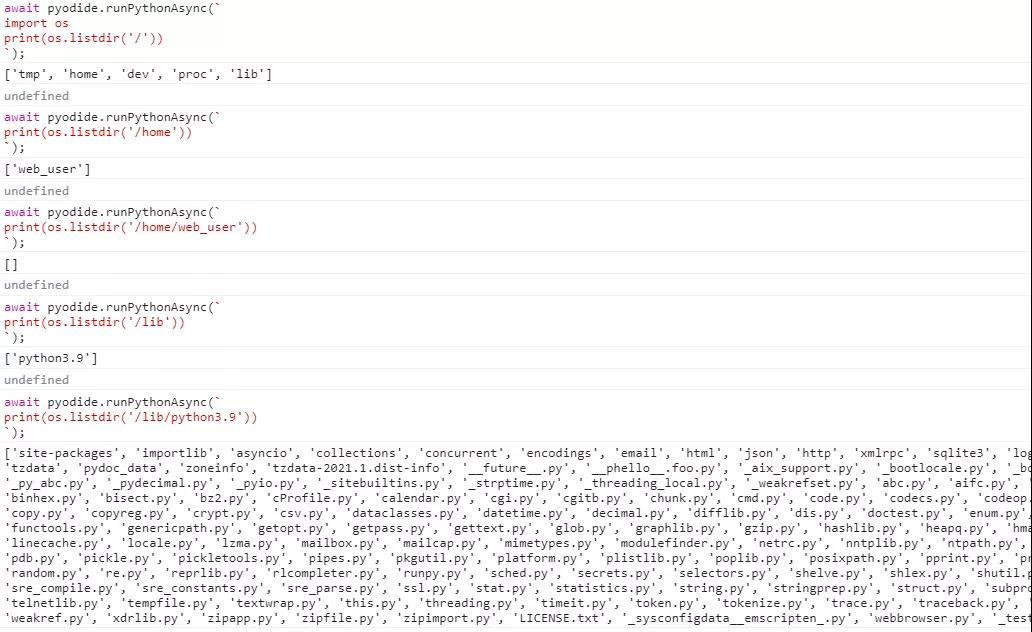
至此,python和pip就安裝完畢了,都位于內存文件系統中。我們可以查看一下python被安裝到了哪里:
?
?? 
注意,這個文件系統是內存里虛擬出來的,刷新頁面就丟失了。不過由于瀏覽器本身有緩存,所以刷新頁面后從服務端再次加載pyodide的引導js和主體wasm還是比較快的,只要不清理瀏覽器緩存。
2 加載pypi包
在pyodide初始化完成后,python系統自帶的標準模塊可以直接import。第三方模塊需要用micropip.install()安裝:
- pypi.org上的純python包可以用micropip.install() 直接安裝
- 含有C語言擴展(編譯為動態鏈接庫)的wheel包,需要對照官方已編譯包的列表
- 在列表中的直接用micropip.install()安裝
- 不在這個列表里的,就需要自己手動編譯后發布到服務器后再用micropip.install()安裝。
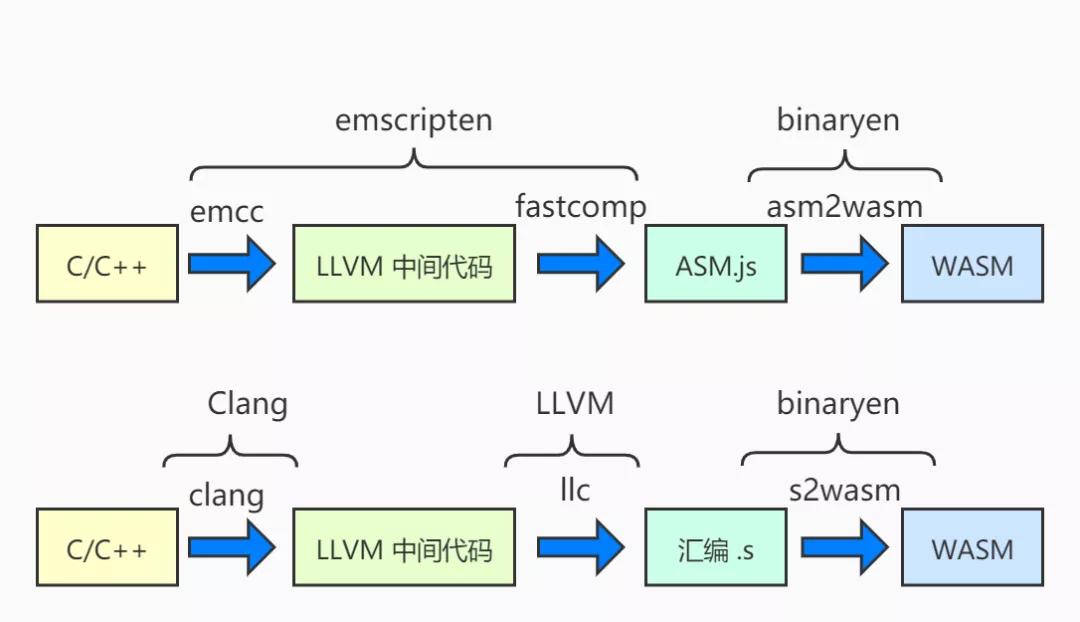
下圖展示了業內常用的兩種編譯為wasm的方式。
?
?? 
自己編譯wasm package的方法可參考官方手冊,大致步驟就是pull官方的編譯基礎鏡像,把待編譯包的setup.cfg文件放到模塊目錄里,再加上些hack的語句和配置(如果有的話),然后指定目標進行編譯。編譯成功后部署時,需要注意2點:
- 設置允許跨域
- 對于wasm格式的文件請求,響應Header里應當帶上:"Content-type": "application/wasm"
下面是一個自建wasm服務器的nginx/openresty示例配置:
回到我們的推理實例, 現在用pip安裝模型推理所需的numpy和Pillow包并將其import:
這樣python所需的opencv、onnxruntime包就已全部導入了。
3 opencv的使用
一般python里的圖片數組都是從JS里傳過來的,這里我們模擬構造一張圖片,然后用opencv對其resize。上面提到過,pyodide官方的opencv還沒編譯出來。如果涉及到的opencv方法調用有其他pypi包的替代品,那是最好的:比如,cv.resize可以用Pillow庫的PIL.resize代替(注意Pillow的resize速度比opencv的resize要慢);cv.threshold可以用numpy.where代替。 否則只能調用opencv.js的能力了。為了演示pyodide語法,這里都從opencv.js庫里調用。
傳參原則:除了簡單的數字、字符串類型可以直接傳,其他類型都需要通過pyodide.to_js()轉換后再傳入。 返回值的獲取也類似,除了簡單的數字、字符串類型可以直接獲取,其他類型都需要通過xx.to_py()轉換后獲取結果。
接著對一個mask檢測其輪廓:
4 推理引擎的使用
最后,用onnx.js加載模型并進行推理,詳細語法可參考onnx.js官方文檔。其他js版的推理引擎也都可以參考各自的文檔。
通過以上的操作,我們確保了一切都在python語法范圍內進行,這樣修改原始的Python文件就比較容易了:把不支持的函數替換成我們自定義的調用js的方法;原Python里的推理替換成調用js版的推理引擎;最后在Javascript主程序框架里加少許調用Python的膠水代碼就完成了。
5 掛載持久存儲文件系統
有時我們需要對一些數據持久保存,可以利用pyodide提供的持久化文件系統(其實是emscripten提供的),見手冊(文章底部)。
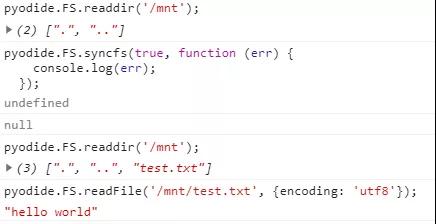
這樣文件就持久保存了。即使當我們刷新頁面后,仍可以通過掛載該文件系統來讀出里面的內容:
運行結果如下:
?
?? 
當然,以上語句可以在python中以Proxy的語法方式運行。
持久文件系統有很多用處。例如,可以幫我們在多線程(webworker)之間共享大數據;可以把模型文件持久存儲到文件系統里,無需每次都通過網絡加載。
6 打wheel包
單Python文件無需打包,直接當成一個巨大的字符串,交給pyodide.runPythonAsync()運行就好了。當有多個Python文件時,我們可以把這些python文件打成普通wheel包,部署到webserver,然后可以用micropip直接安裝該wheel包:
注意,打wheel包需要有__init__.py文件,哪怕是個空文件。
四 存在的缺陷
目前pyodide有如下幾個缺陷:
- Python運行環境加載和初始化時間有點兒長,視網絡情況,幾秒到幾十秒都有可能。
- pypi包支持的不完整。雖然pypi.org上的純python包都可以直接使用,但涉及到C擴展寫的包,如果官方還沒編譯出來,那就需要自己動手編譯了。
- 個別很常用的包,例如opencv,還沒成功編譯出來;模型推理框架一個都沒有。不過還好可以通過相應的JS庫來彌補。
- 如果python中調用了js庫的話:
- 可能會產生一定的內存拷貝開銷(從wasm內存到JS內存的來回拷貝)。尤其是大數組作為參數或返回值,在速度要求高的場合下,額外的內存拷貝開銷就不能忽視了。
- python庫的方法接口可能跟其對應的js庫的接口參數、返回值格式不一致,有一定的適配工作量。
五 總結
盡管有上述種種缺陷,得益于代碼移植的高效率和邏輯上1:1復刻的高可靠性保障,我們還是可以把這種方法運用到多種業務場景里,為推動機器學習技術的應用添磚加瓦。
鏈接:
1、測試頁面:https://test-bucket-duplicate.oss-cn-hangzhou.aliyuncs.com/public/pyodide/test.html
2、文檔:https://pyodide.org/en/stable/usage/type-conversions.html
3、官方已編譯包的列表:https://github.com/pyodide/pyodide/tree/main/packages
4、手冊:https://emscripten.org/docs/api_reference/Filesystem-API.html