指尖上的大數據 - IM消息處理優化方案
在即時通訊領域,高并發消息處理是個很重要的話題。以京東客服系統舉例,每當促銷時,促銷店鋪的每個客服短時間內可能接收到大量的用戶咨詢,如果不能及時快速地展示出用戶咨詢的信息,那么就無法對用戶的咨詢進行快速的回復,進而可能會造成一定的用戶流失,這是商家和京東所不能接受的。處理這種高并發的場景時,我們需要在消息查重、數據庫IO性能、內存緩存、UI顯示等多維度進行優化。
消息從服務端推到客戶端,然后被分發到消息隊列,在消息隊列中經過一番處理后,最終展示到頁面上。這張圖只是簡單地描述了消息的處理流程,下面我們將分步驟說明每個流程的設計和優化。
一、消息查重設計
客戶端在消息處理完(存入數據庫)后會給服務端發送已收回執,當服務端收到回執后便不再重復給客戶端下發此消息,然而現實場景中如果我們處理的過慢或者網絡丟包,那服務端就會重復給客戶端發送該消息。既然我們無法避免重復消息,那查重流程就是我們首先要考慮的。
1.1**重復消息處理過濾機制**
通常情況消息處理隊列為一個串行隊列,一條消息進入處理隊列后,會涉及到Message表、User表,Conversation表等多個表的讀寫,而我們知道數據庫的IO是非常耗時的。由于消息處理是個串行隊列,消息會按照時間接收順序在隊列中排隊,如果消息處理的不夠快,那么服務端會因長時間收不到客戶端回執而重復下發該消息,極端情況下這會導致消息隊列中出現大量的重復消息,隊列壓力會越來越大,內存暴增導致OOM。另外因為重復的消息導致隊列變長,新消息也不能及時被處理。解決這個問題很簡單,我們可以在消息進入處理隊列前先進行過濾,如果已經有同樣的消息進入處理隊列,就直接丟掉。具體設計如下圖:
1.2**本地緩存過濾機制**
為了避免相同消息重復處理的情況,消息在進入處理隊列后,首先要判斷該消息是否已經處理過(標志就是緩存是否已經同樣的消息),如果緩存有則不重復處理。其中緩存分為內存緩存和數據庫兩部分,當消息在持久化時,同時在內存和數據庫中進行緩存。消息查重分為兩步,首先判斷內存緩存中是否有,如果有則直接丟棄該消息,而如果沒有再通過sql來查詢數據庫,如果第一步內存緩存命中,就可以少一次數據庫的查詢。具體設計如下圖:
二、寫入性能優化
2.1**消息批處理寫入**
消息處理完需要入庫持久化,在這里可以分為兩種方式,一種是消息處理完立即入庫,一種是開啟事務批量入庫。其中第一種比較好理解實現起來也比較簡單,第二種我們在消息積攢到一定量或者一個時間段結束后批量入庫。SQLite的數據操作實質上是對數據文件的IO操作,頻繁地插入數據會導致文件IO經常開閉,非常損耗性能。通過開啟事務將數據先緩存在內存中,當提交事務時再把所有的更改更新到數據文件,此時數據文件的IO只需要開閉一次,也避免了長期占用文件IO所導致性能低下的問題。
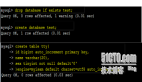
以下數據表記錄了在iPhone 6s設備上,這兩種方式不同數據量寫入數據庫消耗的時間:
通過上表,我們可以看到數據量越大,開啟事務后性能提升就越明顯。那是不是在實踐中一定要開啟事務呢?不一定。對于IM消息來說,大部分服務端都是一條一條下發給客戶端,并不存在多條消息同時到達客戶端的情況,如果我們想用到事務的特性,需要先將處理完的消息緩存到內存中,定時或者定量進行批處理入庫,而這都需要額外的邏輯實現,會增加代碼的復雜度,進而增加維護成本。另外由于消息到達先后特性,最終的效果會因為網絡等狀況并沒有上面的數據那么好。大家可以根據自身的情況抉擇。
除了利用事務來提高寫入性能外,SQLite在3.7.0版本引入了WAL(Write-Ahead Log)模式,在特定情況下可以大幅提升寫入性能。
2.2**開啟WAL模式**
“原子提交(atomic commit)”是SQLite一個重要特性,原子提交意味著單個事務的所有更改要么全部完成,要么全部不完成,不會出現單個事務內的操作執行到一半的情況。為了實現這個特性,SQLite需要臨時文件的輔助,比如rollback模式的journal文件;WAL模式的wal文件和shm文件。
SQLite默認為rollback模式,我們可以通過修改配置更改為WAL模式。下面通過對兩種模式的事務提交流程分析,來看看WAL模式怎么提高寫性能的。
2.2.1ROLLBACK 模式
SQLite數據庫連接默認為rollback模式(journal_mode = DELETE;)。 rollback模式工作原理大致為:寫操作進行前進行數據庫文件拷貝,然后對數據庫進行寫操作。如果發生Crash或者Rollback則將日志中的原始內容回滾到數據庫文件進行恢復操作,否則在Commit完成時刪除日志文件。以下為rollback模式下寫入的重要的節點:
- 首先,在系統緩存中創建rollback journal文件,把需要修改的原始內容保存到這個文件中,然后修改用戶空間的數據庫;
- 然后,將rollback journal文件頭和文件內容通過兩次fsync()從系統緩存同步到磁盤中(這個步驟非常耗時);
- 下一步,先將修改后的數據同步到系統緩存,再同步到磁盤中;
- 最后,刪除rollback journal文件;
以上只列舉了單個事務提交成功的流程,由于篇幅的原因,如提交失敗(設備斷電、系統崩潰等)rollback流程等細節內容可以參考SQLite官方文檔,文檔很完善,強烈建議抽時間學習下。
2.2.2WAL**模式**
首先,我們看下官方文檔中對WAL模式的優缺點描述:
優點有:
- 在大多數情況下,使用WAL模式速度更快;
- WAL模式進一步提升了數據庫的并發性,因為讀不會阻塞寫,而寫也不會阻塞讀,讀和寫可以并發執行;
- 使用WAL模式,磁盤I/O操作更有秩序;
- 使用WAL模式減少了fsync()操作次數,因此不易受到系統上的fsync()系統調用(system call)中斷的影響;
缺點有:
- WAL模式通常要求VFS支持共享內存原語(shared-memoryprimitives);
- 使用數據庫的所有進程必須位于同一臺主機上, WAL無法在網絡文件系統上運行;
- 在讀取操作遠多于寫入操作的應用程序中,WAL可能比傳統的日志模式稍慢(可能慢1%或2%);
- 每個數據庫文件都關聯了額外的.wal文件和.shm共享內存文件;
**寫流程:**
WAL模式相較于rollback則采用了相反的做法。在進行數據庫寫操作時,將數據append到-wal日志文件中而原有數據庫內容保存不變。如果事務失敗,-wal文件中的記錄會被忽略;如果事務成功,它將在隨后的某個時間被寫回到數據庫文件中,該步驟被稱為Checkpoint。WAL模式下寫數據庫操作比rollback模式下更為集中,而且該模式下顯著降低了磁盤同步fsync()的頻率,所以相對來說寫性能更優秀。我們可以使用以下代碼開啟WAL模式:
- \1. PRAGMA journal_mode = WAL;
**讀流程:**
在WAL模式下讀的時候,SQLite會先在WAL文件中搜索,找到最后一個寫入點,記住它,并忽略在此之后的寫入點(這保證了讀寫和讀讀可以并發執行)。隨后,它確定所要讀的數據的所在頁是否在-wal文件中,如果在,則讀-wal文件中的數據,如果不在,則直接讀數據庫文件中的數據。為了避免每個讀取操作掃描整個-wal文件來尋找頁面(-wal文件可以增長到幾兆字節,具體取決于Checkpoint運行的頻率,默認情況下,當-wal文件達到1000頁的閾值大小時,SQLite會自動執行Checkpoint,我們也可以修改SQLITE_DEFAULT_WAL_AUTOCHECKPOINT來指定不同的閾值),SQLite提供了WAL-index文件來輔助頁面的查找。WAL-index文件使用了進程間共享內存的技術,共享內存是一個以.shm結尾并且和數據庫文件在同一個目錄下的文件,這個文件比較特別,內存和文件存在映射關系,取到這個文件的地址后可以像內存一樣對其讀寫,而一般文件需要調用read、write函數才能讀寫。WAL-index可以幫助讀取操作快速定位WAL文件中的頁面,極大地提高了讀取的性能。
**讀、寫測試:**
以下數據表記錄了在iPhone 6s設備上,這兩種模式不同數據量的寫和讀耗時:
- 寫入測試
- 讀測試
從上面兩個表的測試數據可以看到WAL模式對讀性能影響有限,而寫入性能相對于rollback模式提升了3**~4倍左右**。iOS系統從5.1.1版本開始SQLite版本便升級到3.7.7,而我們現在大部分應用支持的最低版本為iOS8,所以我們可以直接開啟WAL模式來提高寫入性能。
三、查詢性能優化
3.1**對常用列查詢添加索引**
為了防止查詢數據時每次都遍歷整張表,常見的關系型數據庫均提供了索引,適當地添加索引可以大大提高數據庫的讀性能。SQLite索引結構為B+樹,也被存在數據庫文件里,結構如下圖(該圖來自維基百科) :
提升查找速度的關鍵在于盡可能減少磁盤I/O,那么可以知道,每個節點中的key個數越多,樹的高度就越小,需要I/O的次數也就越少。因為B+樹的非葉節點中不存儲data,所以可以存儲更多的key。很多存儲引擎在B+樹的基礎上進行了優化,添加了指向相鄰葉節點的指針,形成了帶有順序訪問指針的B+樹,這樣做可以提高區間查找的效率,只要找到第一個值那么就可以順序的查找后面的值。
3.1.1**幾種索引方式**
SQLite主要有以下四種索引方式:
- 普通索引(只基于表的一個列創建的索引)
- 唯一索引(除了普通索引的特性,索引列重復的數據不允許插入到表中)
- 隱式索引(數據庫隱式為主鍵創建的唯一索引)
- 組合索引(基于一個表的兩個或多個列創建的索引)
這里重點說下組合索引,例如為table_name表創建了col1,col2,col3組合索引:
- \1. ALTER TABLE 'table_name' ADD INDEXindex_name('col1','col2','col3');
組合索引遵循”最左前綴”原則,把最常用作為檢索或排序的列放在最左,依次遞減,上面的組合索引相當于建立了col1,col1col2,col1col2col3三個索引,而col2或者col3是不能使用索引的,這里一定要注意查詢語句和索引的順序要一致,否則索引無法正常命中。
3.1.2**添加索引性能提升**
以下數據表記錄了在iPhone 6s設備上,不同數據量有無索引情況下的性能表現:
從上面表來看,添加索引對數據庫的讀性能提升很大,尤其是當本地數據表越來越大,有索引與沒有索引讀性能對比是天壤地別。但是在使用索引時一定要要了解每種索引的適用、命中原則情況,不要一股腦的添加索引。首先,索引是需要額外的磁盤空間存儲;其次,在insert/update數據時索引結構可能會發生變化消耗一部分寫入性能;再次,不合理的查詢語句會命中不了索引。查詢優化還是建議大家翻閱官方文檔。
3.2**增加內存Cache層提升查詢性能**
雖然我們可以通過添加索引的方式,提升數據庫的查詢性能。但畢竟在系統磁盤緩存未命中時還是需要進行磁盤IO,而我們知道磁盤IO是非常耗時,所以減少對庫的操作對讀性能提升也很有幫助。為了實現這點,我們可以在DB層上面增加內存Cache層,在讀數據時優先從內存Cache層讀,如果命中便可以少一次讀庫操作。內存緩存可以使用簡單的key-value結構,key為主鍵(或者其他唯一鍵,這個鍵應當經常被當作查詢條件),下圖為增加內存Cache層后的查詢和緩存邏輯:
四、消息**UI刷新設計**
當消息處理完后,下一步需要把消息展示在UI上。如果每條消息處理完就立即刷新頁面,在普通低并發場景下沒有太大問題,但是在高并發場景下就會造成短時間內UI刷新次數過多,從而導致頁面卡頓,在這里我們可以通過兩種方式進行優化。
4.1**延遲刷新**
消息到達UI隊列時,可以延遲特定時間(比如100ms)再刷新UI,每條消息都將UI刷新的時間延遲100ms刷新。為了防止UI刷新操作因新消息的到來而一直被延遲,可以設置延遲閾值(比如2s),當達到延時閾值時,直接提交刷新UI操作。
4.2**滑動列表時不刷新UI**
當用戶滑動會話列表/會話頁消息列表時,列表不刷新,等到列表停止滑動時再刷新,這樣可以保證列表的滑動流暢度。iOS實現起來很方便,只要把Timer加到NSDefaultRunLoopMode就可以了。下圖為具體的實現邏輯:
五、最終完整的設計
我們通過上面幾點,將消息處理的每個步驟的優化點一一做了說明,下圖詳細地展示了消息從接收到展示的完整處理流程:
六、最后
我們通過消息查重設計、寫入性能優化、查詢性能優化、消息UI刷新設計四個維度,分別介紹了高并發消息處理的優化邏輯。希望通過此文章,可以給你在設計客戶端高并發消息處理方案時提供一種新的思路。