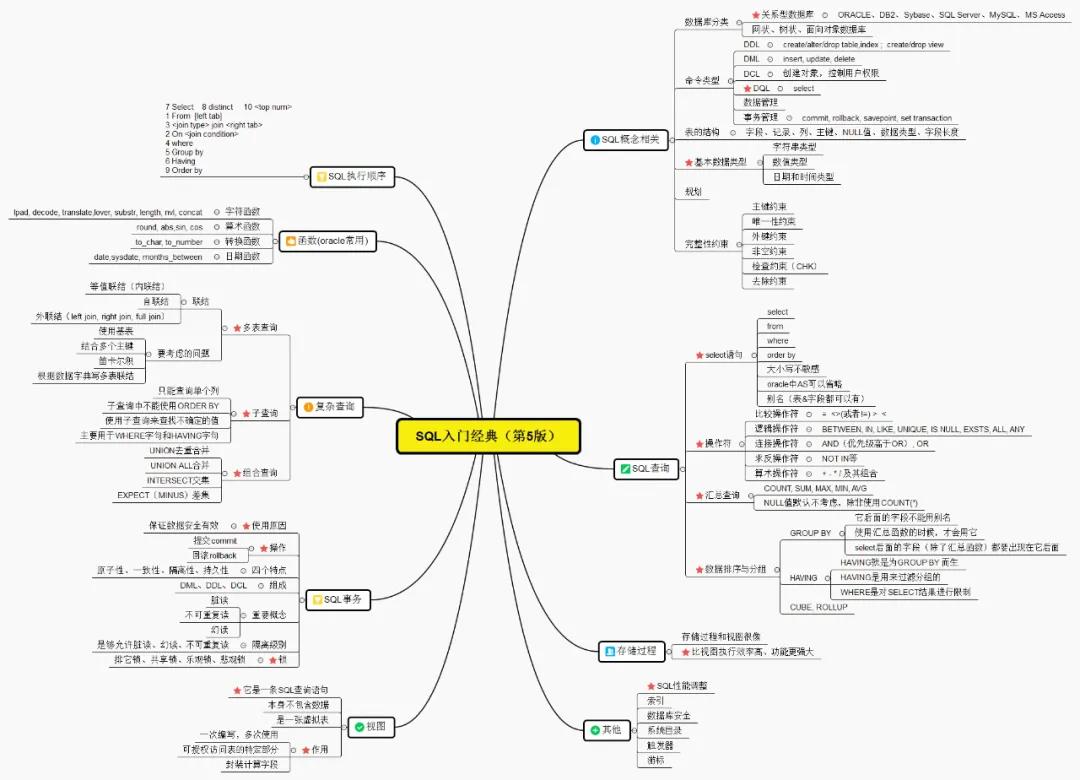
面試 | 面向行的數(shù)據(jù)庫(kù)VS面向列的數(shù)據(jù)庫(kù)
本文轉(zhuǎn)載自微信公眾號(hào)「大數(shù)據(jù)技術(shù)與數(shù)倉(cāng)」,作者西貝。轉(zhuǎn)載本文請(qǐng)聯(lián)系大數(shù)據(jù)技術(shù)與數(shù)倉(cāng)公眾號(hào)。
總覽
數(shù)據(jù)庫(kù)的數(shù)據(jù)存儲(chǔ)有兩種類(lèi)型,一種是面向行的(row-oriented)數(shù)據(jù)庫(kù),另一種是面向列的(column-oriented )數(shù)據(jù)庫(kù)。
面向行(事務(wù)型) 數(shù)據(jù)庫(kù)
該類(lèi)數(shù)據(jù)庫(kù)是根據(jù)記錄(record)組織數(shù)據(jù)的,將所有與記錄相關(guān)聯(lián)的數(shù)據(jù)保存在內(nèi)存中。面向行的數(shù)據(jù)庫(kù)是組織數(shù)據(jù)的傳統(tǒng)方式,并且為快速存儲(chǔ)數(shù)據(jù)提供了一些關(guān)鍵優(yōu)勢(shì)。它們經(jīng)過(guò)優(yōu)化,可以高效地讀取和寫(xiě)入行。
常見(jiàn)的面向行的數(shù)據(jù)庫(kù):
- PostgreSQL
- MySQL
優(yōu)點(diǎn)
- 行存儲(chǔ)的寫(xiě)入是一次性完成,消耗的時(shí)間比列存儲(chǔ)少,并且能夠保證數(shù)據(jù)的完整性;
- insert/update更容易
缺點(diǎn)
- 沒(méi)有索引的查詢(xún)會(huì)產(chǎn)生大量的I/O
- 建立索引需要花費(fèi)大量時(shí)間和資源
- 面對(duì)查詢(xún)的需求,數(shù)據(jù)庫(kù)必須被大量膨脹才能滿(mǎn)足性能的需求
面向列(分析型) 數(shù)據(jù)庫(kù):
該類(lèi)數(shù)據(jù)庫(kù)是按字段組織數(shù)據(jù)的,在內(nèi)存中將所有與字段相關(guān)聯(lián)的數(shù)據(jù)保存在一起。該類(lèi)數(shù)據(jù)庫(kù)在讀取和計(jì)算列有明顯的優(yōu)勢(shì)。
常用的面向列的數(shù)據(jù)庫(kù)
- AWS RedShift
- Google BigQuery
- HBase
優(yōu)點(diǎn)
- 只查詢(xún)涉及的列,會(huì)大量降低系統(tǒng)I/O,適合并發(fā)查詢(xún)
- 數(shù)據(jù)類(lèi)型一致,數(shù)據(jù)特征相似,能對(duì)數(shù)據(jù)進(jìn)行高效壓縮
- 非常適合做聚合操作
缺點(diǎn)
- 缺乏數(shù)據(jù)完整性保證,寫(xiě)入效率低
- 不適合頻繁delete/update操作
面向行的數(shù)據(jù)庫(kù)
傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)管理系統(tǒng)(DBMS)都是面向行的。在行存儲(chǔ)或面向行的數(shù)據(jù)庫(kù)中,數(shù)據(jù)是逐行存儲(chǔ)的,這樣,行的第一列將挨著前一行的最后一列。
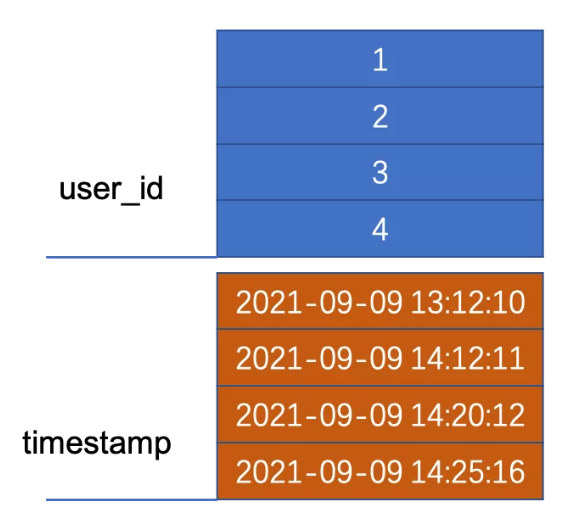
比如,有下面的一張表

這些數(shù)據(jù)將被存儲(chǔ)在一個(gè)面向行的數(shù)據(jù)庫(kù)中的一個(gè)磁盤(pán)上,按照下面這樣的順序一行一行的排列:


這允許數(shù)據(jù)庫(kù)快速寫(xiě)入一行,因?yàn)橐獙?xiě)入數(shù)據(jù),只需在數(shù)據(jù)的末尾添加另一行即可。
面向行的數(shù)據(jù)庫(kù)仍然通常用于聯(lián)機(jī)事務(wù)處理(OLTP)的應(yīng)用程序,因?yàn)樗鼈兛梢院芎玫毓芾韺?duì)數(shù)據(jù)庫(kù)的寫(xiě)操作。對(duì)于聯(lián)機(jī)分析處理(OLAP)的場(chǎng)景需要一個(gè)支持特定數(shù)據(jù)查詢(xún)的數(shù)據(jù)庫(kù)。這就是面向行的數(shù)據(jù)庫(kù)比面向列的數(shù)據(jù)庫(kù)慢的地方。
讀取面向行的數(shù)據(jù)庫(kù)
面向行的數(shù)據(jù)庫(kù)檢索行或一組行的速度很快,但在執(zhí)行聚合時(shí),它將額外的數(shù)據(jù)(列)帶入內(nèi)存,這比只選擇要執(zhí)行聚合的列要慢。此外,面向行的數(shù)據(jù)庫(kù)可能需要訪(fǎng)問(wèn)的磁盤(pán)數(shù)量通常更多。
因此,我們可以看到,雖然向面向行的數(shù)據(jù)庫(kù)添加數(shù)據(jù)是快速和簡(jiǎn)單的,但從中獲取數(shù)據(jù)可能需要使用額外的內(nèi)存和訪(fǎng)問(wèn)多個(gè)磁盤(pán)。
面向列的數(shù)據(jù)庫(kù)
數(shù)據(jù)倉(cāng)庫(kù)的創(chuàng)建是為了支持?jǐn)?shù)據(jù)分析。這些類(lèi)型的數(shù)據(jù)庫(kù)通常對(duì)數(shù)據(jù)讀取做了優(yōu)化。
在面向列的數(shù)據(jù)庫(kù)中,數(shù)據(jù)的存儲(chǔ)形式為列中的每一行都挨著同一列中的其他行。
仍然以上面的表為例:

一個(gè)表一次存儲(chǔ)一列,按照一行一行的順序排列:

寫(xiě)入面向列的數(shù)據(jù)庫(kù)
如果我們想要添加一個(gè)新記錄,必須先定位數(shù)據(jù)的位置(比如HBASE的三級(jí)尋址),將每一列插入到它應(yīng)該在的位置。
如果數(shù)據(jù)存儲(chǔ)在一個(gè)單獨(dú)的磁盤(pán)上,那么它將有與面向行的數(shù)據(jù)庫(kù)相同的額外內(nèi)存問(wèn)題,因?yàn)樗枰獙⑺袃?nèi)容都放入內(nèi)存中。但是,當(dāng)存儲(chǔ)在單獨(dú)的磁盤(pán)上時(shí),面向列的數(shù)據(jù)庫(kù)將有很大的好處。
從面向列的數(shù)據(jù)庫(kù)中讀取
只需要計(jì)算需要的列,減少磁盤(pán)掃描,減少不必要的內(nèi)存開(kāi)銷(xiāo),只需要訪(fǎng)問(wèn)極少數(shù)量的磁盤(pán)。
附錄(SQL知識(shí)大圖)