再棘手的線上故障,都逃不過這些高效排查套路
一、前言
線上問題排查相比于coding,是一個低頻的工作,很多人不會經常遇到。一旦需要進行問題排查的時候,往往是重要且緊急的,因此問題排查的效率,就顯得尤為重要。有些線上問題,比較直觀,比如磁盤使用率高、網絡流量高這種,借助合適的工具很快能定位到原因;但對于一些復雜的問題,如系統(tǒng)Load高、RSS占用高、內存溢出等,需要結合多方面的數(shù)據(jù)才能定位到原因。這時候,需要有正確的解題思路,并輔以合適的工具,才能高效地解決問題。
目前業(yè)界排查問題的優(yōu)秀工具還是挺多的,比如國內阿里開源的Arthas、PerfMa開源的為終結性能問題而生的xPocket,Java官方的JMC(JDK Mission Control)、Eclipse的MAT(Memory Analyzer Tooling),以及我一直很推崇的神器Async-Profiler。上述只是列舉了一些比較流行的開源工具,商業(yè)工具如jProfiler、YourKit等也都建立了穩(wěn)定的用戶群體,這些工具功能各有差異。當然這不是本文描述的重點,就不詳細展開了。
在對這些工具進行橫向對比時我們發(fā)現(xiàn),他們的目標都是為了解決一些特定的問題,如果我們有清晰的問題排查思路,結合這些工具,可以很快解決問題。
而對于一些復雜場景,尤其是一些陌生的復雜問題,在沒有頭緒的情況下,縱然有各種神兵利器,也無計可施。線上問題排查猶如開車,老司機駕輕就熟,新手則手忙腳亂。當然如果新手有老司機加以指點,也可能很快地解決問題。
但問題是,這種老司機并不常見,也不可能時刻都能幫你。我們可以去網上查閱其他人總結的問題排查套路,再結合我們自己的場景,去嘗試解決問題,我也是經常這么干的。但這種方式效率依然不高,原因有三個:
- 信息檢索的成本:我們需要花時間去翻閱資料,去跟自己的場景匹配以判斷是否適合自己;
- 試錯的成本:有些資料不適合我們的場景,我們按照資料去嘗試,有可能被帶溝里去,浪費時間;
- 問題排查需要借助于一些第三方工具,而這些工具在生產環(huán)境需要安裝、配置和使用,也需要花較多的時間成本。
針對線上問題排查的特點和現(xiàn)狀,我們是否可以構建一個系統(tǒng),這個系統(tǒng)會針對各種線上問題的排查形成一個知識(套路)庫,針對每一種問題,都有對應的套路和自動化工具幫助我們去定位問題。本文將結合一個比較有代表性的線上問題的排查過程,來探討這種方式的可行性。
二、問題排查的套路化
本章將以RSS占用高為例來對問題排查的套路化進行說明。RSS占用高是很多人遇到過的問題,這個問題涉及的因素比較多,比較有代表性。當然在開啟了Swap的運行環(huán)境中,Swap高也是RSS高的一種表象,殊途同歸。
RSS是Resident Set Size(常駐內存大小)的縮寫,用于表示進程使用了多少內存(RAM中的物理內存)。如果我們遇到進程RSS接近服務器的物理內存,那就意味著你需要關注應用的健康程度了,這意味著應用后面很有可能出現(xiàn)OOM的問題,比如進程被OOM killer殺死,或者容器重啟,或者因使用Swap而速度變慢。
針對RSS高的問題,首先我們需要知道的是,Java進程消耗的內存絕不僅僅是你設置的Xmx或堆內存的用量這么簡單,Java進程占用的內存主要分為2大部分:on-heap(堆內內存)和off-heap(堆外內存)。而堆外內存又包含JVM自身消耗的內存、JVM外的內存。所以,后續(xù)的排查思路我們也是按照堆內內存、JVM內存、JVM外內存3個方向來順序展開。
1. 堆內存是否太大
首先要確認一下Java應用的堆內存是否太大,因為JVM自身也會消耗一些內存,所以你至少需要預留出部分內存存給JVM使用。如果應用涉及較多的網絡通信,那還需要預留一些內存給堆外使用,所以一般來說你的堆內存最多為服務器物理內存的75%(經驗值,需依據(jù)應用自身特點調整),如4G內存服務器,那么堆內存最大為3G。
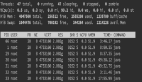
堆內存用量的查看手段非常多,相信各個公司的基礎架構團隊都提供了可視化的監(jiān)控手段,當然也可以通過原生命令jcmd GC.heap_info查看,如圖1所示:

如果Java進程的堆內存用量已接近或超過物理內存的75%,那么基本可以確定堆內存用量過大。這時可以調小Xmx來控制堆內存用量。如果Xmx不能減小,可以通過dump堆內存+MAT或JFR(Java Flight Recorder)+ JMC(JDK Mission Control)來分析內存占用/分配情況,通過程序調優(yōu)來減少堆內存用量。
如果到此RSS占用呈穩(wěn)定趨勢,我們就可以告一段落了,否則要繼續(xù)后面的步驟。
2. 是否存在大量ARENA區(qū)
如果堆內存不大,那么繼續(xù)排查非堆內存。首先去看一下ARENA區(qū),在高并發(fā)的應用中,往往ARENA區(qū)占用的內存會比較多。為什么先看ARENA區(qū)的內存占用呢?是因為這個步驟是不需要重啟JVM進程就可以完成的。
接下來我們直接進入排查問題環(huán)節(jié)。執(zhí)行如下命令:
- sudo -u pmap -x |sort -gr -k2 |less
如果存在大量大小為65536或60000左右的內存區(qū)域,則很大可能是ARENA區(qū)域占用了太多的內存,如圖2所示:
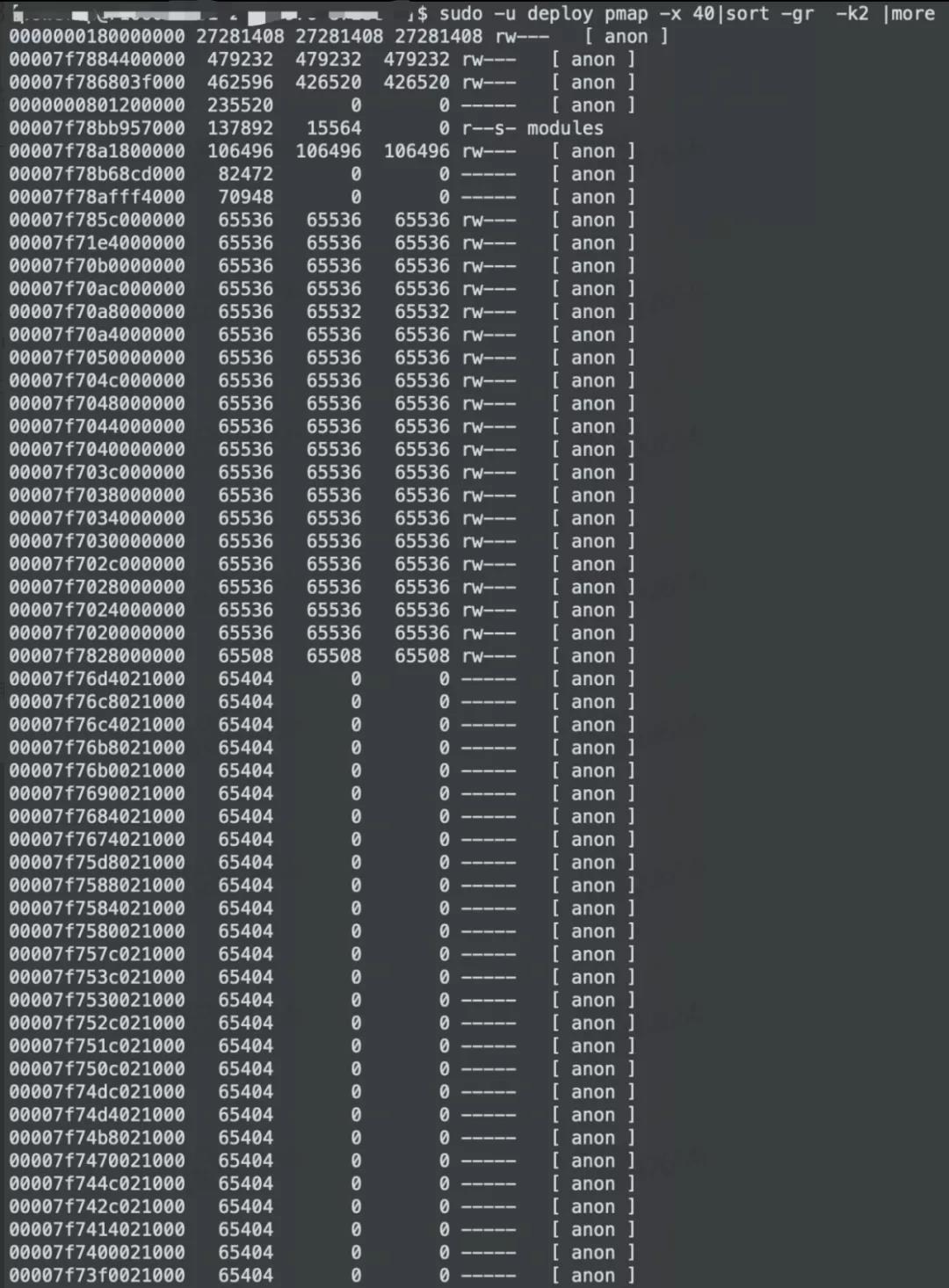
這種情況下,最簡單粗暴的辦法是在JVM啟動參數(shù)中增加配置:
- export MALLOC_ARENA_MAX=1
需要注意的是,上述的數(shù)值只能是1,其他大于1的數(shù)值經實踐證明是無法控制ARENA數(shù)量的。
3. 非堆內存是否開銷過大
如果前面2個步驟過后都沒有發(fā)現(xiàn)問題,還有很多內存你不知道消耗在哪里了,那么我們開始第3步:開啟Native Memory Tracking。前面說過,Java應用的執(zhí)行,JVM自身也需要消耗一些內存的,通過開啟Native Memory Tracking,我們就能知道JVM自身消耗了多少內存。
書歸正傳,通過修改JVM參數(shù)并重啟Java進程開啟NativeMemory Tracking:
- -XX:NativeMemoryTracking=detail
進程重啟后,可以通過NMT的一些子命令(summary/detail/baseline/diff)查看Native Memory的占用情況:
- sudo -u jcmd VM.native_memory detail
圖3是在使用baseline建立了基線的情況下用detail.diff看到的各內存區(qū)的變化情況:
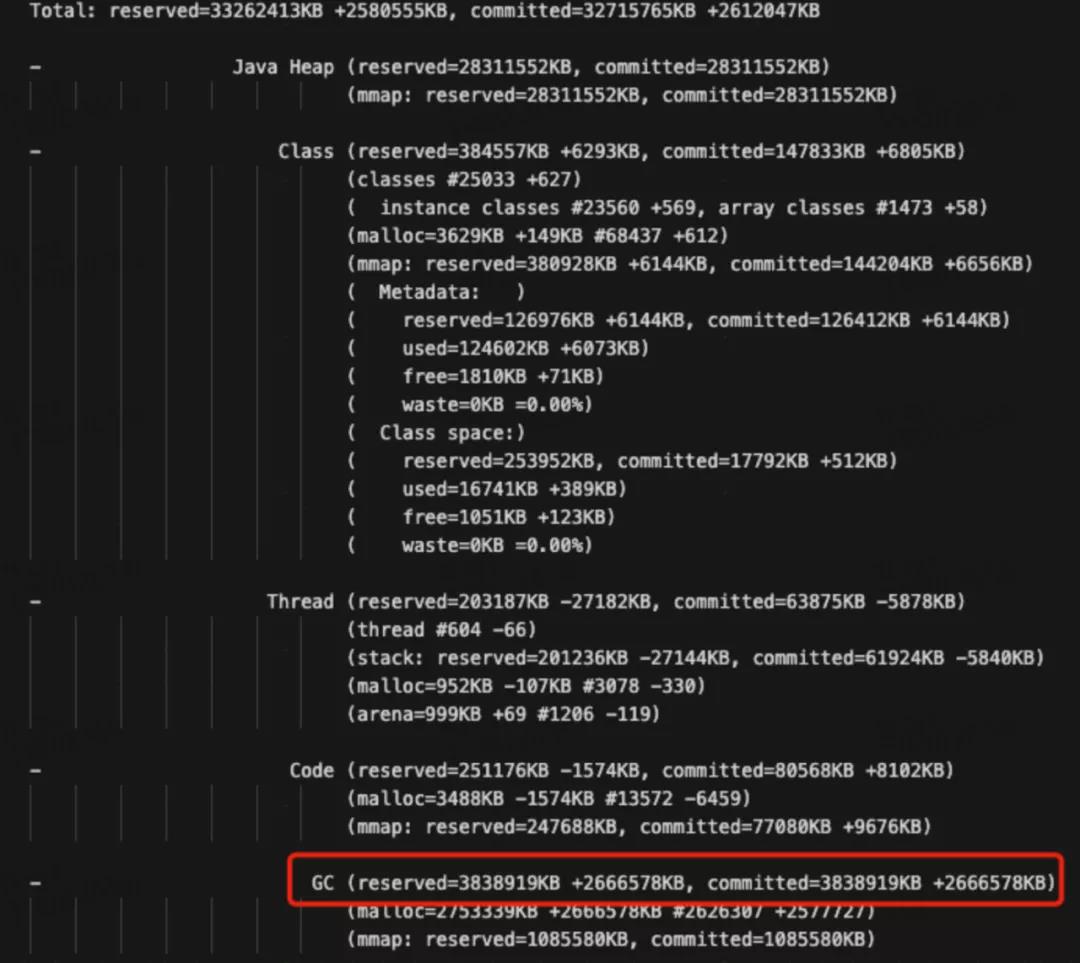
通過上圖,可以看到JVM各個區(qū)域所使用的內存大小,主要包含了Java Heap、Class、Thread、Code、GC、Compiler、Internal、Other、Symbol等,各部分作用如下:
- Class:加載的類與方法信息,其實就是 metaspace,包含兩部分:一是 metadata,被-XX:MaxMetaspaceSize限制最大大小,另外是 class space,被-XX:CompressedClassSpaceSize限制最大大小;
- Thread:線程與線程棧占用內存,每個線程棧占用大小受-Xss限制,但是總大小沒有限制。在x64的JVM中,Xss默認為1024K,所以如果你的應用開啟了1000個線程,那么這個Thread區(qū)占用將是1024M,所以一般我們會把Xss設置為256K即滿足要求;
- Code:JIT 即時編譯后(C1C2 編譯器優(yōu)化)的代碼占用內存,受-XX:ReservedCodeCacheSize限制;
- GC:垃圾回收占用內存,例如垃圾回收需要的 CardTable,標記數(shù),區(qū)域劃分記錄,還有標記 GC Root 等等,都需要內存。這個不受限制,一般不會很大,但也有例外,圖3是27G的堆內存,使用G1垃圾回收器,你能看到GC區(qū)居然占用了3.8G的內存;
- Compiler:C1 C2 編譯器本身的代碼和標記占用的內存,這個不受限制,一般不會很大;
- Internal:命令行解析,JVMTI 使用的內存,這個不受限制,一般不會很大;
- Symbol: 常量池占用的大小,字符串常量池受-XX:StringTableSize個數(shù)限制,總內存大小不受限制;
我們需要需要注意的是Class、Thread、GC幾個區(qū)域的大小。圖4是各種JVM垃圾回收器消耗內存的比例,注意這部分內存是堆內存之外的:
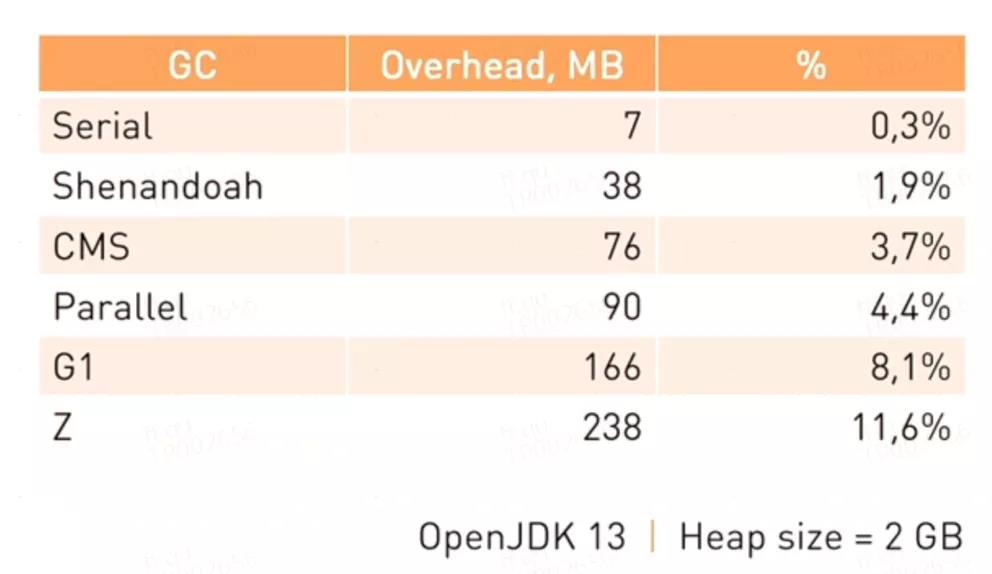
實踐證明,G1的內存開銷甚至能占到堆內存的20%,當然這不是本文要討論的內容,感興趣的讀者可以去閱讀《JVM G1源碼分析和調優(yōu)》一書查看相關內容。
針對上面的各個區(qū)域大小做加法,看一下是否接近于RSS的大小,如果是,恭喜你可以到此結束了。后續(xù)你需要做的就是針對內存占用比較大的JVM區(qū)去做優(yōu)化,這里就不詳細介紹了。
如果不是,很遺憾,你進入到了最難啃的環(huán)節(jié),繼續(xù)往下看吧。
注:開啟NativeMemoryTracking會造成5%的性能下降,用完記得修改JVM參數(shù)并重啟永久關閉,或者可以通過以下命令臨時關閉:jcmd vm.native_memory stop 。
4. 堆外內存是否用量太多
堆外內存也是比較容易被忽略的一個區(qū)域,尤其是網絡通信非常頻繁的應用,這種應用往往大量使用Java NIO,而NIO為了提高效率,往往會申請很多的堆外內存。確認這個區(qū)域用量是否過大,最直接的方法是先查看是否是DirectByteBuffer或者MappedByteBuffer使用了較多的堆外內存。
如果你的服務器已經開啟了遠程JMX,你可以通過ops提供的jmx查詢工具去查詢,也可以通過jdk自帶的工具(比如jconsole、jvisualvm)查詢,如圖5所示:
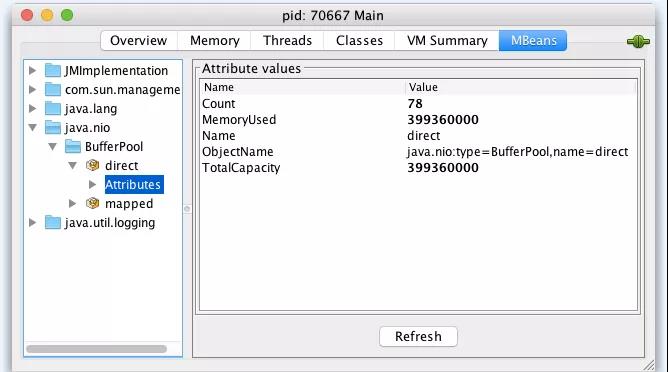
圖5
如果未開啟遠程JMX,可以通過jmxterm(https://docs.cyclopsgroup.org/jmxterm)工具在本地模式下查詢以下兩項內容確認用量:
- java.nio:name=direct,type=BufferPool
- java.nio:name=mapped,type=BufferPool
如果確認上述堆外內存使用過多,那么可以通過在jvm參數(shù)中設置-XX:MaxDirectMemorySize這個參數(shù)控制一下,因為通過DirectByteBuffer分配的堆外內存,默認是不會控制這個區(qū)域的內存用量的。
如果上述內存用量不大,那我們就需要祭出終極殺器jemalloc來做進一步分析了。這里涉及的內容比較多,受限于文章篇幅限制,就不展開描述了。
通過jemalloc的收集到的數(shù)據(jù),我們基本能夠定位到堆外內存問題的原因。
5. 總結
上述的4個步驟,基本能夠解決大多數(shù)的RSS占用高的問題了。當然事無絕對,沒有一種藥是包治百病的。我們追求的基本目標是,通過問題排查的套路化,幫助工程師理清思路,少走彎路,以提高問題排查的效率。
三、問題排查的工具化
復盤一下上述的問題排查過程,我們用到了很多的命令和第三方工具,整個過程還是工程師驅動命令行和工具。如果對命令參數(shù)不熟悉,或本地沒有安裝相應的工具,那這種套路化的教程也只能在一定程度上提高效率。在這個套路的基礎上,我們是否可以轉變思路,以工具為主,工程師輔助,來提高排查問題的效率呢?讓我們來嘗試一下。
1. 流程梳理
先來梳理工具的執(zhí)行流程以及每個步驟需要做的事情,與第二節(jié)保持一致性,本節(jié)也劃分成4個子步驟。
1)確認堆內存是否太大
第一步要做的事情比較多,梳理如下:
- Java進程pid:使用jps -v列出java進程列表,由用戶選擇具體的進程;
- 獲取運行環(huán)境的物理內存和剩余內存(free -m)
- Java進程的堆內存用量(jcmd GC.heap_info)
- Java進程GC情況(jstat-gcutil);
獲取到上述信息后,判斷堆內存是否太大。
2)是否存在大量ARENA區(qū)
通過pmap命令獲取內存分配列表,輔以awk命令提取內存信息,據(jù)此判斷是否存在大量ARENA區(qū)。
3)非堆內存是否開銷過大
此步驟需要在JVM啟動腳本中增加啟動參數(shù)并重新啟動進程,對于標準化的運行環(huán)境來說,在知道了啟動腳本位置和啟動命令的情況下,是可以通過工具來完成參數(shù)的修改和進程啟動。如果不能知道啟動腳本所在位置,我們可以復制當前進程的JVM參數(shù)來完成進程的啟動。
當JVM進程啟動完成,再次進入工具,我們就能借助于Native Memory Tracking的結果來判斷當前環(huán)節(jié)是否存在問題。
4)堆外內存是否用量太多
此步驟的自動執(zhí)行,需要安裝第三方工具如jxmterm、jemalloc。在生產環(huán)境訪問外網受限的情況下,可以通過搭建內網資源服務器的方式來解決這個問題。通過一鍵安裝腳本,我們能快速完成所依賴工具的安裝和配置,剩下的就是讓工具來收集和分析數(shù)據(jù)定位問題了。
2. 工具實現(xiàn)
目前公司內部很多運維工具,都是采用C+B/S的方式實現(xiàn),這種方式工程師不需要申請目標服務器權限就能夠實現(xiàn)很多運維操作。但這種實現(xiàn)方式比較復雜,而我們的工具是帶有實驗性質,所以暫時使用shell+工具包的方式實現(xiàn),即使用shell腳本將主流程串起來,各節(jié)點使用的工具如果有缺失,yum能安裝使用yum安裝,yum不能安裝的則提前下載內置到工具包中。
所有的準備工作完成后,編寫腳本的工作就相對簡單了,當然這需要用到很多的shell和linux、java命令,此處就不贅述了。腳本的最終運行效果如下:
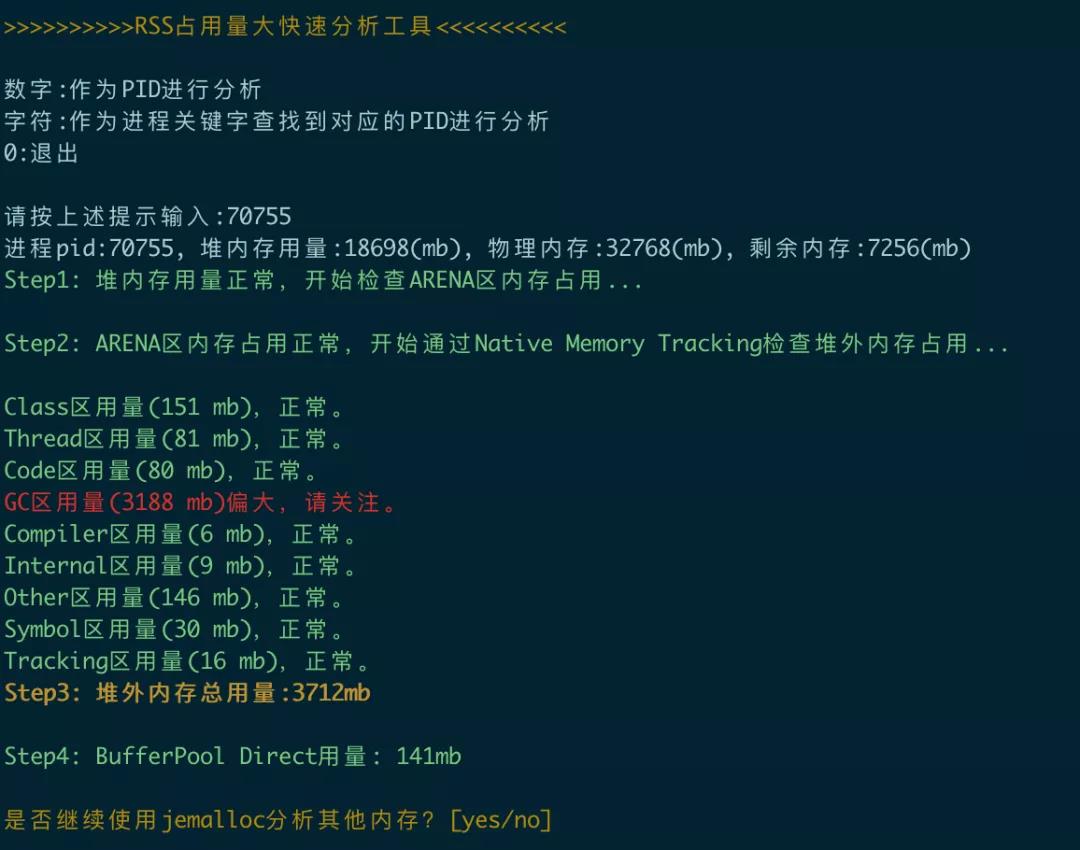
四、總結
通過針對RSS占用高問題的排查套路和排查工具的梳理,我們實現(xiàn)了一個簡單的問題快速排查腳本。當然在這個過程中可以發(fā)現(xiàn),很多問題的排查,都可以使用類似的思路來工具化,日積月累,就形成了一個問題排查的工具包。
以內存問題排查舉例,我們積累了以下的快速工具,如圖:
這只是工具包的一部分,針對CPU、磁盤、網絡、GC等問題,借助于Arthas、Async-Profiler等優(yōu)秀的開源工具,我們都積累了很多快速工具,期望能幫工程師提高問題排查的效率。
如前面所講,這種完全基于shell的方式,由于需要登錄到目標服務器上操作,多數(shù)功能還需要有sudo權限,這有些許的不方便。另外,某些公司生產環(huán)境嚴格受限,那shell的方式就無法使用了。所以在此基礎上,可以擴展成Client+Server+Browser的模式,讓工程師在不登錄到服務器的情況下,就能完成問題的排查。
到此,本文的內容就結束了,但我們的工具還在不斷地積累中,在此也歡迎感興趣的同學幫我們提供場景,我們不斷豐富這個工具庫。同時,受限于作者水平,文中內容難免有不當之處,也歡迎提出意見和建議。