高并發(fā)整體可用性:大規(guī)模集群下的分片管理策略
大規(guī)模系統(tǒng)的分片部署是一個難點,既要考慮容災(zāi)和故障轉(zhuǎn)移,又要考慮負(fù)載均衡和資源利用率。本文就從服務(wù)狀態(tài)、故障轉(zhuǎn)移、負(fù)載及資源利用率等幾個方面來闡述下他們的關(guān)系,并帶大家一起看下,facebook面對這種挑戰(zhàn)是怎么做系統(tǒng)架構(gòu)的~
1有狀態(tài)&無狀態(tài)的服務(wù)部署
應(yīng)用服務(wù),根據(jù)其類型一般可以分為兩種:無狀態(tài)服務(wù) 和 有狀態(tài)服務(wù)
無狀態(tài)的服務(wù),擴(kuò)展起來其實比較容易,用流量路由等負(fù)載均衡方式即可實現(xiàn);
但是有狀態(tài)服務(wù)不太容易,讓所有服務(wù)器一直能夠持有全部數(shù)據(jù)時不現(xiàn)實的。
-- 散列是一種方案 --
如一致性散列策略,將數(shù)據(jù)散列部署。但是,一致性散列會存在一些不可避免的問題,主要有數(shù)據(jù)傾斜、數(shù)據(jù)漂移等。雖然我們可以通過將某節(jié)點的一部分?jǐn)?shù)據(jù)移到其他節(jié)點來解決,但這需要非常細(xì)粒度的負(fù)載統(tǒng)計標(biāo)尺來進(jìn)行發(fā)現(xiàn)和衡量。

來源:百度百科
另外,由于一致性散列對多數(shù)據(jù)中心的支持不太友好,比如,希望讓某些區(qū)域的用戶走特定數(shù)據(jù)中心,以降低延遲的話,用該策略不好實現(xiàn)。
-- 分片是另一種方案 --
其目的是支持業(yè)務(wù)增長、應(yīng)對系統(tǒng)的高并發(fā)及吞吐量。并且加載和使用更加靈活。

來源:fb engineering
數(shù)以萬計、億計的數(shù)據(jù)分散存儲在多個數(shù)據(jù)庫實例中,則每個實例都叫一個分片。另外,為了容錯,每個分片都可以有多個副本,而每個副本根據(jù)不同的一致性要求可以分為主副本和從副本。
然后,分片又通過多種策略規(guī)范,顯示計算出到服務(wù)器的映射,以向用戶提供完整的服務(wù)。這些策略規(guī)范包括:不同用戶ID選擇不同的服務(wù)分區(qū)、不同地理位置的請求分散到較近的數(shù)據(jù)中心等等。
從這個要求來看,分片的方式要比散列更靈活,更適用大型服務(wù)部署。
2故障是一種常態(tài)
在分布式環(huán)境下,我們對故障需要有清晰的認(rèn)知--故障的發(fā)生不應(yīng)該被當(dāng)成是小概率事件,而應(yīng)該被當(dāng)成一種常態(tài)。
這也是系統(tǒng)設(shè)計應(yīng)該遵守的一個前提條件。這樣系統(tǒng)才有可能更加穩(wěn)固。
所以,服務(wù)的容錯能力、從故障中恢復(fù)的能力,是實現(xiàn)服務(wù)高可用的關(guān)鍵。
那可以有哪些措施呢?
-- 復(fù)制 --
數(shù)據(jù)、服務(wù)的冗余部署,是提高容錯能力的常用手段。比如服務(wù)主備和數(shù)據(jù)庫主從。
但是有些情況下,這種方式是可以打商量的。如果單個容錯域的故障會導(dǎo)致所有冗余副本宕機(jī),那復(fù)制還有啥作用?
-- 自動檢測 & 故障轉(zhuǎn)移 --
想要高可用,故障的發(fā)現(xiàn)和自動檢測機(jī)制是前提。然后才是故障轉(zhuǎn)移。
故障轉(zhuǎn)移的快慢,決定了程序的可用性高低。那么,所有的故障都必須立馬進(jìn)行轉(zhuǎn)移才能達(dá)到最好的效果么?
也不竟然。
如果新副本的構(gòu)建成本非常大呢?比如要加載龐大的數(shù)據(jù)量資源等等,指不定還沒構(gòu)建完,原故障機(jī)器就恢復(fù)了說不定。
-- 故障轉(zhuǎn)移限流 --
一個服務(wù)掛了不是最可怕的,最可怕的是它能把全鏈路都帶崩。就比如上一篇文章中寫的《Zookeeper引發(fā)的全鏈路崩潰》一樣,級聯(lián)問題,絕對不容小覷!
因此,在進(jìn)行故障轉(zhuǎn)移時,要給予這個問題足夠的重視,以免引發(fā)正常服務(wù)在脈沖流量下崩盤。
3資源是寶貴的,不浪費才最好
就算是阿里的財大氣粗,每個季度也會有運維同學(xué)和業(yè)務(wù)同學(xué),因為1%的CPU利用率,在服務(wù)容器數(shù)量分配上來回博弈好多次。
業(yè)務(wù)同學(xué)當(dāng)然是想機(jī)器越多越好,因為機(jī)器越多,單節(jié)點的故障幾率就可以小些;
而運維同學(xué)的任務(wù)則是盡可能提高資源利用率。畢竟有那么多要買718、911的。。。不都得錢么~
-- 負(fù)載均衡 --
負(fù)載均衡是指在應(yīng)用服務(wù)器之間持續(xù)均勻地分布分片及其工作負(fù)載的過程。它可以有效地利用資源,避免熱點。
- 異構(gòu)的硬件。由于硬件規(guī)格不同,服務(wù)所能承載的壓力也不盡相同,因此需要考慮硬件限制來分配負(fù)載。
- 動態(tài)資源。比如可用的磁盤空間、空閑的CPU等,如果負(fù)載和這些動態(tài)資源綁定,那么不同的時間點,服務(wù)負(fù)載是不能一概而論的。
-- 彈性擴(kuò)展 --
很多時候,我們的很多應(yīng)用都是為用戶提供服務(wù)的。而用戶的行為隨著作息呈現(xiàn)一定的規(guī)律性,如白天的訪問量大,晚上的訪問量小。
因此,彈性計算其實是在不影響可靠性的前提下提高資源效率的一種解決方案,即根據(jù)負(fù)載變化動態(tài)調(diào)整資源分配。
4Facebook怎么平衡上述訴求[1]
我們平常見到,其實不同的團(tuán)隊有不同的分片管理策略。比如,本地生活有一套自己的外賣服務(wù)分片的管理容災(zāi)方案、大文娛也有一套自己視頻服務(wù)的分片管理。
facebook早期也是如此。不同團(tuán)隊間各有各的方案,但是這些方案都更偏重于解決故障轉(zhuǎn)移,保障系統(tǒng)可用性,對負(fù)載均衡考慮較少。
這樣的方式,其實對集團(tuán)資源利用率、操作性上有些不適合。基于這樣的考慮,facebook設(shè)計了一個通用的分片管理平臺Shard Manager,簡稱 SM 。。。
距今,已經(jīng)有成百上千的應(yīng)用程序被構(gòu)建或遷移到分片管理器上,在幾十萬的服務(wù)器上構(gòu)建出總計超過千萬的分片副本。。。
那么,我們來一起看下,他們是怎么做的。
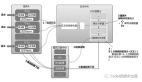
1、基礎(chǔ)架構(gòu)分層設(shè)計

facebook基礎(chǔ)設(shè)施架構(gòu)
Host management: 即主機(jī)管理,使用資源配額系統(tǒng),管理所有物理服務(wù)器,并給各團(tuán)隊分配容量。
Container management: 每個團(tuán)隊從下層獲取到容量后,以容器為單位將其分配給各個應(yīng)用程序。
Shard management: 在下層提供的容器內(nèi)為分片應(yīng)用程序分配分片。
Sharded applications: 在每個分片中,應(yīng)用程序分配并運行相關(guān)的工作負(fù)載。
Products: 上層應(yīng)用程序。
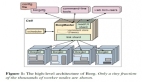
2、Shard Management整體架構(gòu)
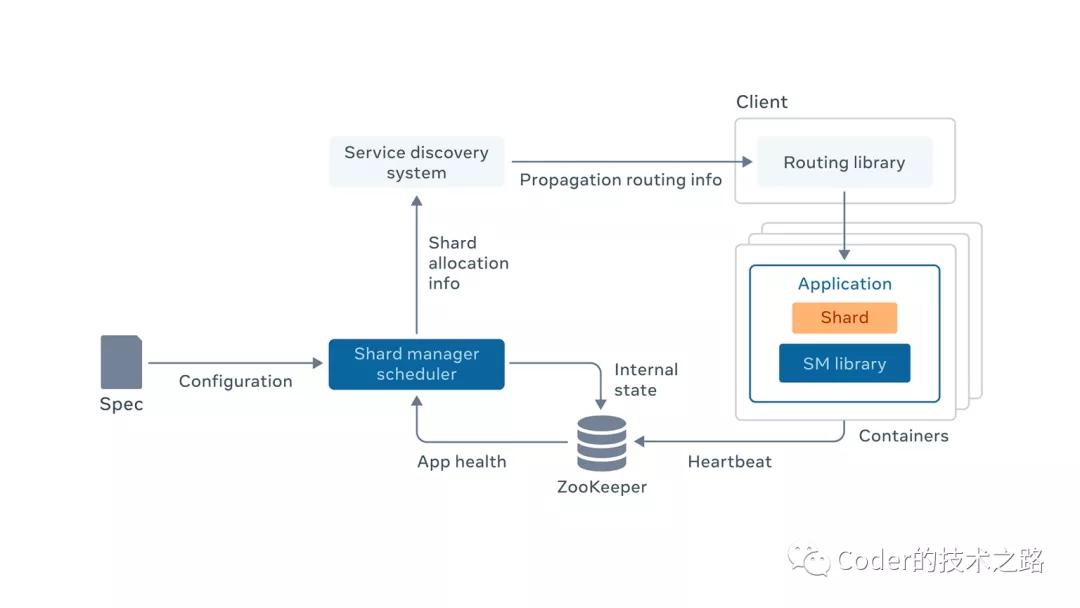
來源:fb engineering
應(yīng)用程序?qū)崿F(xiàn)分片狀態(tài)轉(zhuǎn)換接口(該接口由SM library定義,由應(yīng)用程序?qū)崿F(xiàn)),并根據(jù)調(diào)度程序的調(diào)用進(jìn)行狀態(tài)轉(zhuǎn)換。
應(yīng)用程序向 ZooKeeper 上報服務(wù)器成員資格和活動狀態(tài)。由Shard Manager Scheduler 收集應(yīng)用程序監(jiān)測的自身動態(tài)負(fù)載信息。
Shard Manager Scheduler 是協(xié)調(diào)分片轉(zhuǎn)換和移動的中央服務(wù)。它收集應(yīng)用程序狀態(tài);監(jiān)控服務(wù)器加入、服務(wù)器故障和負(fù)載變化等狀態(tài)變化;通過對應(yīng)用程序服務(wù)器的RPC調(diào)用來驅(qū)動分片狀態(tài)轉(zhuǎn)換,從而實現(xiàn)分片分配的調(diào)整。
Shard Manager Scheduler 將分片分配的公共視圖發(fā)布到服務(wù)發(fā)現(xiàn)系統(tǒng)(該系統(tǒng)保障了自己的高可用和可擴(kuò)展);
服務(wù)發(fā)現(xiàn)系統(tǒng)將信息傳遞到應(yīng)用程序的客戶端用于計算請求路由。
那么,Shard Manager Scheduler掛了怎么辦呢?
一是,其內(nèi)部可以進(jìn)行分片擴(kuò)展,來保證其高可用;
二是,由上述設(shè)計可知,中央處理程序不在客戶端調(diào)用的關(guān)鍵路徑上,即使掛了,應(yīng)用程序還是可以以現(xiàn)有的分片來執(zhí)行運轉(zhuǎn),業(yè)務(wù)不會受中央處理器宕機(jī)的影響。
3、標(biāo)準(zhǔn)化分片管理
為了實現(xiàn)上述架構(gòu),facebook定義了幾個原語:
- //分片加載
- status add_shard(shard_id)
- //分片刪除
- status drop_shard(shard_id)
- //主從切換
- status change_role(shard_id, primary <-> secondary)
- //驗證和變更副本成員關(guān)系
- status update_membership(shard_id, [m1, m2, ...])
- //客戶端路由計算和直連調(diào)用
- rpc_client create_rpc_client(app_name, shard_id)
- rpc_client.execute(args)
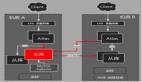
根據(jù)上述原語,通過組合,即可以合成高級分片移動協(xié)議:
如,我們希望將將分片A,從當(dāng)前負(fù)載較高的服務(wù)器A,移動到負(fù)載較低的服務(wù)器B:
- Status status= A.drop_share(xx);
- if(status == success){
- B.add_share(xx)
- }
不僅是普通服務(wù),對于主從切換、paxos協(xié)議的服務(wù)管理也可以用上述原語滿足,有興趣的同學(xué)可以自己試試組合一下,這個對我們工作中的系統(tǒng)設(shè)計時非常有幫助的。
那么,針對文章前半部分涉及到的一些分片管理的難點和問題,facebook在該架構(gòu)下是怎么應(yīng)對的呢?
對于容錯中的復(fù)制,Shard Manager允許在每個分片上配置復(fù)制因子,以實現(xiàn)合理的復(fù)制策略,如果不需要復(fù)制,則可以通過復(fù)制因子來控制;
對于故障轉(zhuǎn)移,Shard Manager通過配置故障轉(zhuǎn)移延遲策略,來權(quán)衡新副本的構(gòu)建成本和服務(wù)的不可用時間;
對于故障節(jié)流,Shard Manager支持限制分片故障轉(zhuǎn)移速度,來保護(hù)其余健康服務(wù)器不會被沖垮;
對于負(fù)載均衡,Shard Manager支持根據(jù)硬件規(guī)格定制負(fù)載因子;通過定期收集應(yīng)用程序每個副本的負(fù)載,來實現(xiàn)各實例間的平衡;并支持多資源平衡,確保短板資源可用。
對于彈性,Shard Manager支持分片縮放和擴(kuò)展,針對不同流量實行不同的擴(kuò)展速率。
參考資料
[1]fb engineering: "使用ShardManager擴(kuò)展服務(wù)"