













用Spark,Kafka和k8s構建下一代數據管道
譯文【51CTO.com快譯】數據集成,通常在企業的信息架構中扮演著重要的角色。具體而言,企業的分析流程在很大程度上會依賴于此類集成模式,以便從交易系統中,提取方便分析與加載的數據格式。
過去,在傳統的架構范式中,由于系統之間缺乏互連,事務和分析經常出現延遲,我們只能依賴Batch以實現集成。在Batch模式中,大文件(即數據的dump文件)通常是由操作系統生成,并且通過驗證、清理、標準化、以及轉換等處理,進而輸出文件以供系統分析。由于此類大文件的讀取會占用大量的內存,因此數據架構師通常會依賴一些暫存類型的數據庫,來持續存儲已完成處理的數據輸出。
近年來,隨著以Hadoop為代表的分布式計算的廣泛發展與應用,MapReduce通過在商用硬件上的水平擴展,以分布處理的方式,解決了高內存的使用需求。如今,隨著計算技術的進一步發展,我們已可以在內存中運行MapReduce,并使之成為了處理大型數據文件的標準。
就在Batch方式進行演變的過程中,非批(non-batch)處理方式也得到了重大進展。多年來,面向用戶的物聯網設備已逐漸成為數據系統中的重要一環。大量數據源于物聯網設備的采集,而事件驅動型架構也成為了基于微服務的云原生開發方法的流行選擇。由于數據處理頻率的成倍增加,數據流的處理能力成為了數據集成工作的主要非功能性需求。因此,曾經是大文件數據集成問題,已演變成為了流處理需求。這就需要我們提供一個具有足夠緩沖區的數據管道,通過持久性來避免數據包的丟失。
在那些以云服務為主體的平臺上,各種組件的水平擴展能力,相對于數據流和使用者而言,要比垂直擴展更加重要。因此,對流的水平可伸縮性以及流的使用者有明確的關注。這也是諸如Kafka之類的數據流解決方案、以及Kubernetes集群需要向使用者(consumer)提供的。目前,Lambda架構的Speed層、以及Kappa架構的構建也都在向此方法發展。
采用Spark、Kafka和k8s構建下一代數據管道的目的,本文將討論相關架構模式,以及對應的示例代碼,您可以跟著一步一步在自己的環境中搭建與實現。
Lambda架構
Lambda架構主要兩個層次:Batch和Stream。Batch能夠按照預定的批次轉換數據,而Stream負責近乎實時地處理數據。Batch層通常被使用的場景是:在源系統中批量發送的數據,需要訪問整個數據集,以進行所需的數據處理,不過因為數據集太大,無法執行流式處理。相反,那些帶有小塊數據包的高速數據需要在Speed層被處理。這些數據包要么相互獨立,要么按照速度相近的方式形成了對應的上下文。顯然,這兩種類型的數據處理方式,都屬于計算密集型,盡管Batch層的內存需求要高于Speed層。與之對應的架構方案需要具備可擴展性、容錯性、性能優勢、成本效益、靈活性、以及分布式。
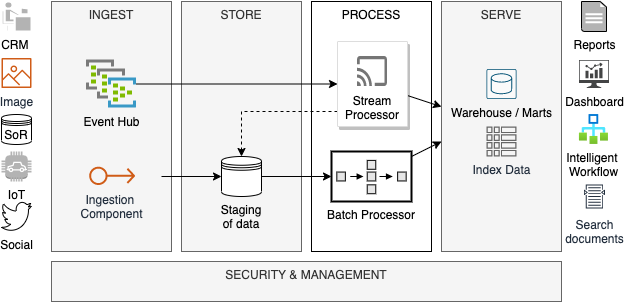
圖 1:Lambda架構
由上圖可知,由于Lambda需要兩個單獨的組件,來進行Batch和Speed層面的數據處理,因此其架構較為復雜。如果我們能夠用某個單一的技術組件,來同時滿足這兩個目的,則會大幅降低復雜性。而這正是Apache Spark大顯身手之處。
分布式計算的最新選擇
憑借著包括SparkSQL和SparkStreaming在內的一系列庫,Apache Spark作為一種有效的方案,可通過內存計算,來實現分布式Lambda架構。其中,SparkSQL能夠支持各種Batch操作,例如:通過分布式架構加載、驗證、轉換、聚合、以及映射數據,進而減少對于單臺機器的內存需求。同樣,基于SparkStreaming的作業任務,可以近乎實時地處理來自Kafka等來源的數據流,并將分析結果提供給諸如:數據倉庫或數據湖等更為持久的組件。

圖 2:Batch和Speed層的上下文
Kubernetes是一種云平臺集群管理器,其最新版本的Spark,可以運行在由 Kubernetes管理的集群上。可以說,基于Kubernetes的Spark是在云端實現Lambda架構的絕佳組合。
雖然我們可以單獨地使用Kubernetes進行分布式計算,但是在這種情況下我們仍需要依賴定制的解決方案。例如,在Batch層中,Spring Batch框架可以與Kubernetes集群結合使用,進而將工作任務分發到多個集群節點處。類似地,Kubernetes也可以將流數據分發到多個針對Speed層,而并行運行的Pod。Pod可以通過在其中生成容器,以實現輕松地水平擴展,進而能夠根據數據的體量和速率去調整集群。
Spark,針對Lambda架構的一站式解決方案
針對Batch和Speed層的非功能性需求,Apache Spark具有如下特性:
- 可擴展性:Spark集群可以按需進行擴、縮容。由于它由一個主節點和一組工作節點組成,因此這些工作節點會隨著工作負載的增加,而提高水平擴展的能力。
- 容錯性:Spark框架能夠處理由于工作節點的崩潰,而導致的集群故障。由于每個數據幀都會被邏輯分區,而每個分區的數據處理都會發生在某個節點上。那么,在處理數據時,如果某個節點發生了故障,那么集群管理器會按照有向無環圖(Directed Acyclic Graph,DAG)的邏輯,分配另一個節點來執行數據幀的相同分區,進而確保絕對的零數據丟失。
- 效率高:由于Spark支持內存計算,因此在執行期間,數據可以根據Hadoop的需要,被存儲在RAM中,而非磁盤上。其效率顯然要高得多。
- 靈活的負載分配:由于Spark支持分布式計算,能夠橫跨多個節點共享任務的組件,并作為一個集成單元生成輸出。Spark可以運行在 Kubernetes 管理的集群上,這使得它在云環境中更加合適。
- 成本:Spark是開源的,本身不包含任何成本。當然,如果選擇托管服務,則需要付出一定的代價。
現在讓我們深入了解Spark以了解它如何幫助Batch和蒸汽處理。Spark由兩個主要組件組成:Spark核心 API 和Spark庫。核心 API 層提供對四種語言的支持:R、Python、Scala 和 Java。在核心 API 層之上,我們有以下Spark庫,每個庫都針對不同的目的。
- SparkSQL:處理(半)結構化數據,執行基本轉換功能并在數據集上執行 SQL 查詢SparkStreaming:能夠處理流數據;支持近實時數據處理
- SparkMLib:用于機器學習;根據需要用于數據處理
- SparkGraphX:用于圖形處理;這里討論的范圍很少使用
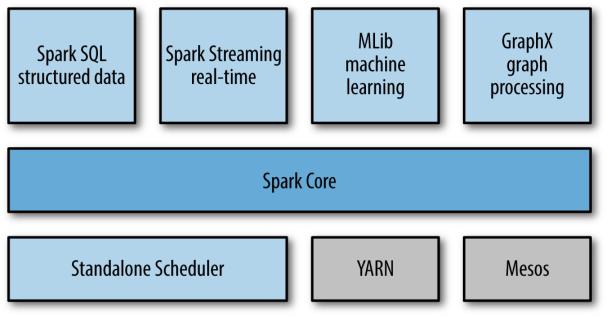
圖 3:Spark堆棧(來源:LearningSpark,O'Reilly Media, Inc.)
Batch層的Spark
在Lambda架構轉換的Batch層,對(半)結構化數據的計算、聚合操作由SparkSQL 庫處理。讓我們進一步討論SparkSQL 架構。
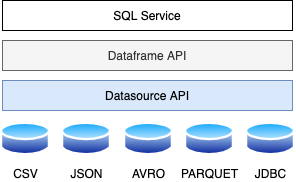
圖 4:SparkSQL 架構
從上圖中可以明顯看出,SparkSQL 具有三個主要架構層,如下所述:
- 數據源 API:處理不同的數據格式,如 CSV、JSON、AVRO 和 PARQUET。它還有助于連接不同的數據源,如 HDFS、HIVE、MYSQL、CASSANDRA 等。 用于加載不同格式數據的通用 API:
Dataframe.read.load(“ParquetFile | JsonFile | TextFile | CSVFile | AVROFile”)
- 數據幀API:Spark2.0 以后,Spark數據幀被大量使用。它有助于保存大型關系數據并公開多個轉換函數以對數據集進行切片和切塊。通過 Dataframe API 公開的此類轉換函數的示例是:
withColumn, select, withColumnRenamed, groupBy, filter, sort, orderBy etc.
- SQL 服務:SparkSQL 服務是幫助我們創建數據框和保存關系數據以進行進一步轉換的主要元素。這是我們使用SparkSQL 時Batch層轉換的入口點。在轉換過程中,可以使用python、R、Scala或Java中的不同API,也可以直接執行SQL來轉換數據。
下面是一些Batch的代碼示例:
假設有兩個表:一個是 PRODUCT,另一個是 TRANSACTION。PRODUCT 表包含商店特定產品的所有信息,Transaction 表包含針對每個產品的所有交易。我們可以通過轉換和聚合得到以下信息。
- 產品明智的總銷售量
- 分部明智的總收入
通過在Spark數據幀上編寫純 SQL 或使用聚合函數可以獲得相同的結果。
- Python
- from pyspark.sql importSparkSession
- from pyspark.sql.functions import *
- Spark=SparkSession.builder.master("local").appName("Superstore").getOrCreate()
- df1 =Spark.read.csv("Product.csv")
- df2 =Spark.read.csv("Transaction.csv")
- df3 = df1.filter(df1.Segment != 'Electric')
- df4 = df2.withColumn("OrderDate",df2.OrderDate[7:10])
- result_df1 = df3.join(df4, on= ['ProductCode'], how='inner')
- result_df2 = result_df1.groupBy('ProductName').sum('Quantity')
- result_df2.show()
- # Display segment wise revenue generated
- result_df3 = result_df1.groupBy('Segment').sum('Price')
- result_df3.show()
- Python
- from pyspark.sql importSparkSession
- from pyspark.sql.functions import *
- Spark=SparkSession.builder.master("local").appName("Superstore").getOrCreate()
- df1 =Spark.read.csv("Product.csv")
- df2 =Spark.read.csv("Transaction.csv")
- df3 = df1.filter(df1.Segment != 'Electric')
- df4 = df2.withColumn("OrderDate",df2.OrderDate[7:10])
- result_df1 = df3.join(df4, on= ['ProductCode'], how='inner')
- result_df1.createOrReplaceTempView("SuperStore")
- # Display product wise quantity sold
- result_df2 =Spark.sql("select ProductName , Sum(Quantity) from Superstore group by ProductName")
- result_df2.show()
- # Display segment wise revenue earned
- result_df3 =Spark.sql("select Segment , Sum(Price) from Superstore group by Segment")
- result_df2.show()
在這兩種情況下,第一個數據是從兩個不同的來源加載的,并且產品數據針對所有非電氣產品進行過濾。交易數據根據訂單日期的某種格式進行更改。然后,將兩個數據幀連接起來,并生成該超市中細分收入和產品銷售數量的結果。
當然,這是加載、驗證、轉換和聚合的簡單示例。使用SparkSQL 可以進行更復雜的操作。要了解有關SparkSQL 服務的更多信息,請參閱此處的文檔。
Sparkfor Speed 層
SparkStreaming 是一個庫,用于核心Spark框架之上。它確保實時數據流處理的可擴展性、高吞吐量和容錯性。

圖 5:SparkStreaming 架構(來源:https : //spark.apache.org)
如上圖所示,Spark將輸入數據流轉換為批量輸入數據。這種離散Batch有兩種實現方式:a) Dstreams 或離散化流和 b) 結構化流。前者非常受歡迎,直到后者作為更高級的版本出現。但是,Dstream 還沒有完全過時,為了完整起見,將其保留在本文中。
· Discretized Streams:這提供了對火花流庫的抽象。它是 RDD 的集合,代表一個連續的數據流。它將數據離散成小批量并運行小作業來處理這些小批量。任務根據數據的位置分配給工作節點。因此,通過 Dstream 的這個概念,Spark可以并行讀取數據,執行小批量處理流并確保流處理的有效節點分配。
· 結構化流:這是使用Spark引擎的最先進和現代的流處理方法。它與SparkDataframe API(在上面的Batch部分中討論)很好地集成在一起,用于對流數據的各種操作。結構化流可以增量和連續地處理數據。基于特定窗口和水印的近實時聚合也是可能的。
Spark結構化流可以處理不同的流處理用例,如下面的示例所示:
簡單的結構化流媒體
簡單的結構化流只會轉換和加載來自流的數據,并且不包括特定時間范圍內的任何聚合。例如,系統從 Apache Kafka 獲取數據,并通過Spark流和SparkSQL 近乎實時地對其進行轉換(請參閱下面的代碼片段)。
- Python
- from pyspark.sql importSparkSession
- from pyspark.streaming import StreamingContext
- import pyspark.sql.functions as sf
- spark=SparkSession.builder.master('local').appName('StructuredStreamingApp').getOrCreate()
- df =Spark.readStream.format("kafka").option("kafka.bootstrap.servers,"localhost:9092")
- .option("subscribe", "test_topic").load()
- df1 = df.selectExpr("CAST(value AS STRING)")
- df2 = df1.selectExpr("split(value, ',')[0] as Dept","split(value, ',')[1] as Age")
- df2.show()
SparkSession 對象的ReadStream函數用于連接特定的 Kafka 主題。正如上面選項中的代碼片段一樣,我們需要提供 Kafka 集群代理的 IP 和 Kafka 主題名稱。此代碼的輸出是一個表,有兩列:Dept 和 Age。
結構化流媒體聚合
可以通過 Structured Streaming 對流數據進行聚合,它能夠在新事件到達的基礎上計算滾動聚合結果。這是對整個數據流的運行聚合。請參考下面的代碼片段,它在整個數據流上推導出部門明智的平均年齡。
- Python
- from pyspark.sql importSparkSession
- from pyspark.streaming import StreamingContext
- import pyspark.sql.functions as sf
- spark=SparkSession.builder.master('local').appName('StructuredStreamingApp').getOrCreate()
- df =Spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092")
- .option("subscribe", "test_topic").load()
- df1 = df.selectExpr("CAST(value AS STRING)")
- df2 = df1.selectExpr("split(value, ',')[0] as Dept","split(value, ',')[1] as Age")
- df3 = df2.groupBy("Dept").avg("Age")
- df3.show()
窗口聚合
有時我們需要在某個時間窗口內進行聚合,而不是運行聚合。SparkStructured Streaming 也提供了這樣的功能。假設我們要計算過去 5 分鐘內的事件數。這個帶聚合的窗口函數將幫助我們。
- Python
- from pyspark.sql importSparkSession
- from pyspark.streaming import StreamingContext
- import pyspark.sql.functions as sf
- import datetime
- import time
- spark=SparkSession.builder.master('local').appName('StructuredStreamingApp').getOrCreate()
- df =Spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092")
- .option("subscribe", "test_topic").load()
- df1 = df.selectExpr("CAST(value AS STRING)")
- df2 = df1.selectExpr("split(value, ',')[0] as Dept","split(value, ',')[1] as Age")
- df3 = df2.withColumn("Age", df2.Age.cast('int'))
- df4 = df3.withColumn("eventTime",sf.current_timestamp())
- df_final = df4.groupBy(sf.window("eventTime", "5 minute")).count()
- df_final.show()
重疊窗口上的聚合
在上面的例子中,每個窗口都是一個完成聚合的組。還提供了通過提及窗口長度和滑動間隔來定義重疊窗口的規定。它在窗口聚合中的后期數據處理中非常有用。下面的代碼基于 5 分鐘窗口計算事件數,滑動間隔為 10 分鐘。
- Python
- from pyspark.sql importSparkSession
- from pyspark.streaming import StreamingContext
- import pyspark.sql.functions as sf
- import datetime
- import time
- spark=SparkSession.builder.master('local').appName('StructuredStreamingApp').getOrCreate()
- df =Spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092")
- .option("subscribe", "test_topic").load()
- df1 = df.selectExpr("CAST(value AS STRING)")
- df2 = df1.selectExpr("split(value, ',')[0] as Dept","split(value, ',')[1] as Age")
- df3 = df2.withColumn("Age", df2.Age.cast('int'))
- df4 = df3.withColumn("eventTime",sf.current_timestamp())
- df_final = df4.groupBy("Dept",sf.window("eventTime","10 minutes", "5 minute")).count()
- df_final.show()
帶水印和重疊窗口的聚合
數據遲到會在近實時系統的聚合中產生問題。我們可以使用重疊窗口來解決這個錯誤。但問題是:系統等待遲到的數據需要多長時間?這可以通過水印解決。通過這種方法,我們在重疊窗口之上定義了一個特定的時間段。之后,系統丟棄該事件。
- Python
- from pyspark.sql importSparkSession
- from pyspark.streaming import StreamingContext
- import pyspark.sql.functions as sf
- import datetime
- import time
- spark=SparkSession.builder.master('local').appName('StructuredStreamingApp').getOrCreate()
- df =Spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092")
- .option("subscribe", "test_topic").load()
- df1 = df.selectExpr("CAST(value AS STRING)")
- df2 = df1.selectExpr("split(value, ',')[0] as Dept","split(value, ',')[1] as Age")
- df3 = df2.withColumn("Age", df2.Age.cast('int'))
- df4 = df3.withColumn("eventTime",sf.current_timestamp())
- df_final = df4.withWatermark("eventTime","10 Minutes").groupBy("Dept",sf.window("eventTime","10 minutes", "5 minute")).count()
- df_final.show()
上面的代碼表示對于延遲事件,10 分鐘后,舊窗口結果將不會更新。
Kafka + k8s - Speed層的另一種解決方案
托管在 Kubernetes 集群上的 Pod 形成了 Kafka 流的消費者組,是另一種近乎實時數據處理的方法。通過使用這種組合,我們可以輕松獲得分布式計算的優勢。
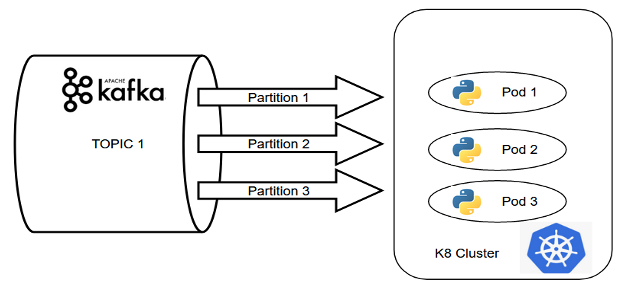
圖 6:通過 Kafka + Kubernetes 實現的Speed層示例
在上面例子中的事件驅動系統中,數據正在從 Kafka 主題加載到基于 Python 的處理單元中。如果 Kafka 集群中的分區數量與 Pod 的復制因子匹配,則 Pod 一起組成一個消費者組,消息被無縫消費。
這是構建分布式數據處理系統的經典示例,僅使用Kafka+k8s組合即可確保并行處理。
使用 Python 創建 Kafka 消費者的兩個非常流行的庫是:
- Python_Kafka 庫
- Confluent_Kafka 庫
- Python_Kafka
- Python
- from kafka import KafkaConsumer
- consumer = KafkaConsumer(TopicName,
- bootstrap_servers= <broker-list>,
- group_id=<GroupName>,
- enable_auto_commit=True,
- auto_offset_reset='earliest')
- consumer.poll()
- Confluent_Kafka
- Python
- from confluent_kafka import Consumer
- consumer = Consumer({'bootstrap.servers': <broker-list>,
- 'group.id': <GroupName>,
- 'enable.auto.commit': True,
- 'auto.offset.reset': 'earliest'
- })
- consumer.subscribe([TopicName])
K8.yml 文件的示例結構如下:
- YAML
- metadata:
- name: <app name>
- namespace: <deployment namespace>
- labels:
- app: <app name>
- spec:
- replicas: <replication-factor>
- spec:
- containers:
- - name: <container name>
如果按照上述方式開發基本組件,系統將獲得分布式計算的幫助,而無需進行內存計算。一切都取決于系統的體積和所需速度。對于低/中等數據量,可以通過實現這種基于 python-k8 的架構來確保良好的速度。
這兩種方法都可以托管在具有各種服務的云中。例如,我們在 AWS 中有 EMR 和 Glue,可以在 GCP 中通過 Dataproc 創建Spark集群,或者我們可以在 Azure 中使用 Databricks。另一方面,kafka-python-k8的方式可以很容易地在云端實現,這保證了更好的可管理性。例如在 AWS 中,我們可以將 MSK 或 Kinesis 和 EKS 的組合用于這種方法。在下一個版本中,我們將討論所有云供應商中Batch和Speed層的實現,并根據不同的需求提供比較研究。
原文標題:Next-Gen Data Pipes WithSpark, Kafka and k8s,作者:Subhendu Dey & Abhishek Sinha
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】












