













女朋友問小灰:什么是數據倉庫?什么是數據湖?什么是智能湖倉?
本文轉載自微信公眾號「程序員小灰」,作者小灰。轉載本文請聯系程序員小灰公眾號。




首先,我們來講一講什么是數據庫。
作為程序員,我們寫的大多數商業項目,往往都需要用到大量的數據。計算機的內存,可以實現數據的快速存儲和訪問。
但是,內存的空間是有限的,也無法長期保存有用的數據。對于那些大量的,需要長期使用的數據,我們需要對它們進行持久的、規范化的存儲,于是就有了數據庫(DataBase)。
市場上常用的數據庫有很多種,包括像MySQL、Oracle這樣的關系型數據庫,也包括Redis,HBase這樣的非關系型數據庫。
無論是哪一種數據庫,它們所存儲的都是結構化數據,主要應用的領域是聯機事務處理(OLTP),也就是我們程序員所熟悉的增刪改查業務。

滿足了業務需求,數據庫當中的數據不斷積累,變得越來越豐富。這時候人們發現,這些數據不但可以支撐業務的運行,也可以用于生成商業報表,進行數據分析,提供有價值的決策參考。這些數據分析和生成報表的處理操作,被稱為聯機分析處理(OLAP)。
但是,傳統數據庫擅長的是快速地對小規模數據進行增刪改查,并不擅長大規模數據的快速讀取。
于是,人們發明了一種全新的數據存儲方式,并把原本分散在不同項目當中的業務數據進行抽取、清洗、轉換、加載,最終匯總成為一系列面向主題的數據集合,按照全新的方式進行存儲。
這種全新的存儲方式,被稱為數據倉庫(Data Warehouse);把數據進行抽取、清洗、轉換、加載的過程,被稱為ETL(Extract Transform Load)。
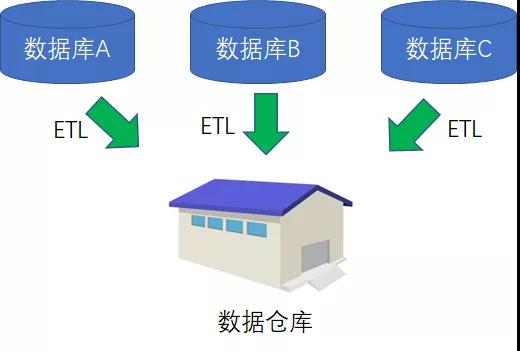
數據倉庫當中存儲的數據,同樣是結構化數據。

數據庫用于業務處理,數據倉庫用于數據分析,一時間大家都使用得十分愉快。
但是,隨著大數據和機器學習技術的不斷發展,人們發現不僅是結構化的數據具有分析價值,許多非結構化的數據,例如用戶日志、電子郵件、PDF等等,同樣具有可觀的分析和學習價值。
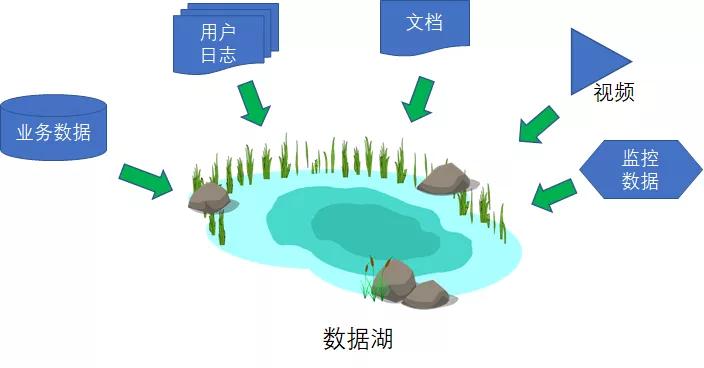
這些五花八門的數據,如果統一按照ETL的方式進行加工處理,實在是不太現實,那么索性把它們按照原始格式匯總在一起吧。這樣匯總起來的龐大集合,被存儲在了數據湖(Data Lake)當中。
數據湖當中的數據可謂是包羅萬象:
結構化的,有各種關系型數據庫的行和列。
半結構化的,有JSON、XML、CSV。
非結構化的,有電子郵件、PDF、各種文檔。
甚至還有雜七雜八的二進制文件,比如圖片、視頻、音頻。
通過數據湖這個統一的數據管理節點,企業可以利用更加豐富多樣的數據,為商業智能、機器學習等方向賦能。


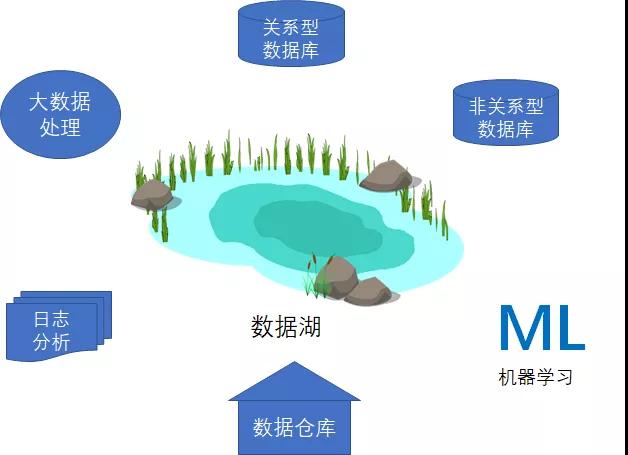
在現實的企業項目當中,所需要的不只是統一存儲的數據湖,也需要各種各樣專門構建的存儲方案,由此為特定應用場景提供必要的性能、規模與成本優勢。
比如,我們仍然需要數據倉庫,適合針對結構化數據通過復雜查詢快速獲取結果;我們需要Lucene或Elastic Search這樣的全文檢索引擎,從而實現快速搜索并分析日志數據,借此監控生產系統的運行狀態。
通過這些多樣的存儲方案,我們可以高效低成本地進行數據分析、機器學習、大數據處理、日志分析等工作。
為了從數據湖及專門構建的存儲中獲取最大收益,企業希望在不同系統之間輕松移動數據。比如有些情況下,客戶希望將數據湖當中的部分數據移至數據倉庫、日志系統等節點。我們將這種情況,歸納為由內向外的數據移動操作。
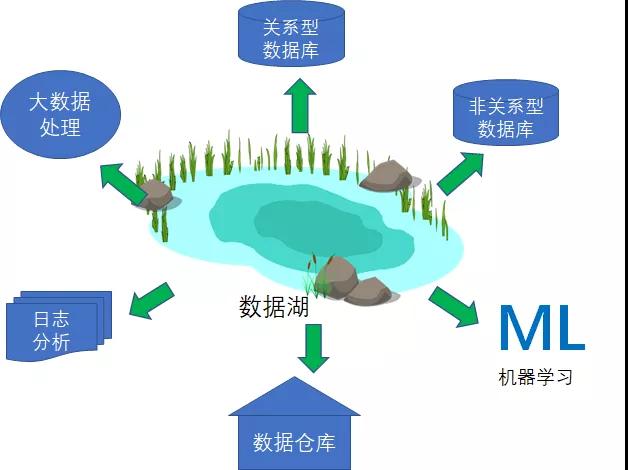
還有些情況下,企業希望將業務數據從關系型數據庫和非關系型數據庫移動到數據湖內。我們將這種情況,歸納為由外向內的數據移動操作。
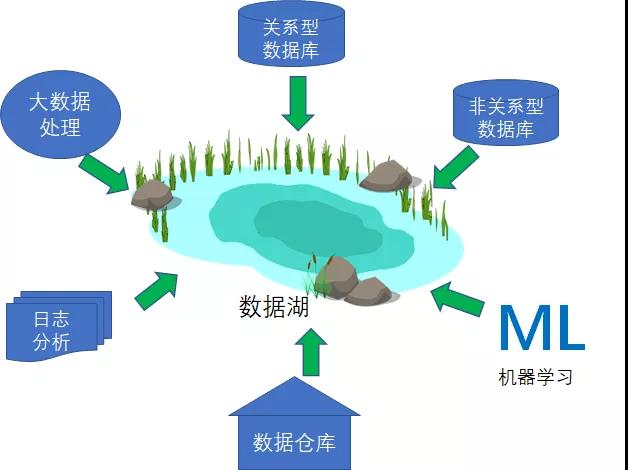
最后,企業還可能要求將數據在不同的專用數據存儲方案之間往來移動,比如將數據倉庫內的數據提供給機器學習系統。我們將這種情況,歸納為圍繞邊界的數據移動操作。
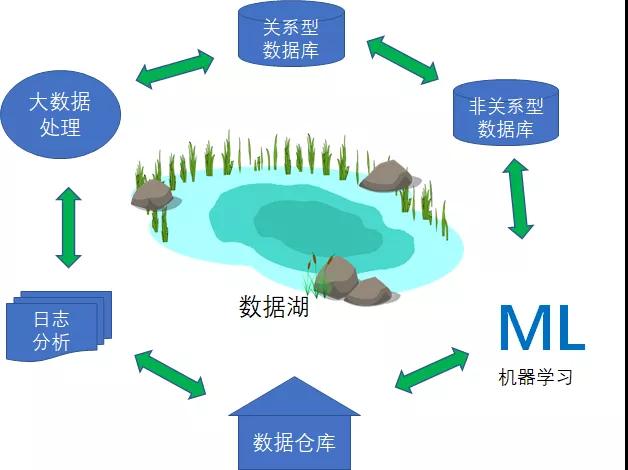




1.快速構建起可擴展的數據湖。
2.豐富而且功能強大的專門構建的數據服務集合,這些數據服務可以為交互式儀表板與日志分析等提供必要的性能支持。
3.在數據湖及各專門構建的數據服務之間實現數據的無縫化移動。
4.通過統一方式加以保護、監控與管理,保證數據訪問活動的合規性。
5.以低成本方式擴展系統,保證不對性能產生負面影響。
我們將這樣一種強大的數據湖及其配套的專用構建數據服務體系,稱為智能湖倉(Lake House)架構。























