性能調優篇:困擾我半年之久的RocketMQ timeout exception 終于被破解了
在內網環境中,超時問題,網絡表示這個鍋我不背。
筆者對于超時的理解,隨著在工作中不斷實踐,其理解也越來越深刻,RocketMQ在生產環境遇到的超時問題,已經困擾了我將近半年,現在終于取得了比較好的成果,和大家來做一個分享。
本次技術分享,由于涉及到網絡等諸多筆者不太熟悉的領域,如果存在錯誤,請大家及時糾正,實現共同成長與進步。
1、網絡超時現象
時不時總是接到項目組反饋說生產環境MQ發送超時,客戶端相關的日志截圖如下:
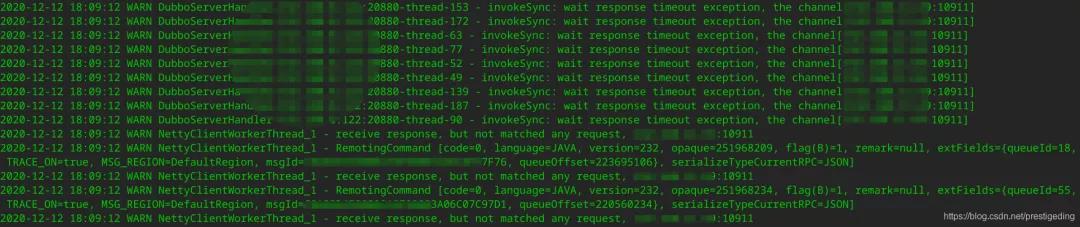
今天的故事將從張圖開始。
2、問題排查
2.1 初步分析
上圖中有兩條非常關鍵日志:
- invokeSync:wait response timeout exception
網絡調用超時
- recive response,but not matched any request
這條日志非常之關鍵,表示盡管客戶端在獲取服務端返回結果時超時了,但客戶端最終還是能收到服務端的響應結果,只是此時客戶端已經等待足夠時間后放棄處理了。
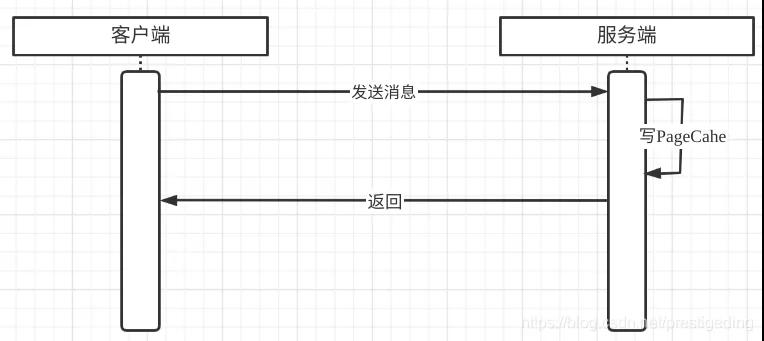
關于第二條日志,我再詳細闡述一下其運作機制,其實也是用一條鏈接發送多個請求的編程套路。一條長連接,向服務端先后發送2個請求,客戶端在收到服務端響應結果時,怎么判斷這個響應結果對應的是哪個請求呢?如下圖所示:

客戶端多個線程,通過一條連接發送了req1,req2兩個請求,但在服務端通常都是多線程處理,返回結果時可能會先收到req2的響應,那客戶端如何識別服務端返回的數據是對應哪個請求的呢?
解決辦法是客戶端在發送請求之前,會為該請求生成一個本機器唯一的請求id(requestId),并且會采用Future模式,將requestId與Future對象放入一個Map中,然后將reqestId放入請求體中,服務端在返回響應結果時將請求ID原封不動的放入到響應結果中,當客戶端收到響應時,先界面出requestId,然后從緩存中找到對應的Future對象,喚醒業務線程,將返回結構通知給調用方,完成整個通信。
故從這里能看到,客戶端在指定時間內沒有收到服務端的請求,但最終還是能收到,矛頭直接指向Broker端,是不是Broker有瓶頸,處理很慢導致的。
2.2 Broker端處理瓶頸分析
在我的“經驗”中,RocketMQ消息發送如果出現瓶頸,通常會返回各種各樣的Broker Busy,而且可以通過跟蹤Broker端寫入PageCache的數據指標來判斷Broker是否遇到了瓶頸。
- grep "PAGECACHERT" store.log
得到的結果類似如下截圖:
圖片
溫馨提示:上圖是我本機中的截圖,當時分析問題的時候,MQ集群中各個Broker中這些數據,寫入PageCache的時間沒有超過100ms的。
正是由于良好的pagecache寫入數據,根據如下粗糙的網絡交互特性,我提出將矛盾點轉移到網絡方面:
并且我還和業務方確定,雖然消息發送返回超時,但消息是被持久化到MQ中的,消費端也能正常消費,網絡組同事雖然從理論上來說局域網不會有什么問題,但鑒于上述現象,網絡組還是開啟了網絡方面的排查。
溫馨提示:最后證明是被我帶偏了。
2.3 網絡分析
通常網絡分析有兩種手段,netstat 與網絡抓包。
2.3.1 netstat查看Recv-Q與Send-Q
我們可以通過netstat重點觀察兩個指標Recv-Q、Send-Q。
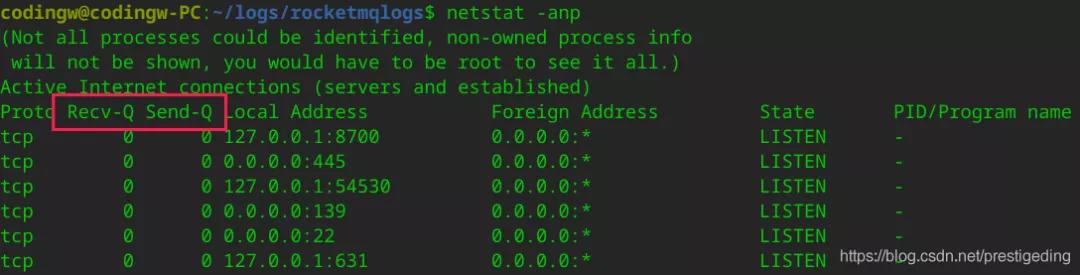
- Recv-Q
tcp通道的接受緩存區
- Send-Q
tcp通道的發送緩存區
在TCP中,Recv-Q與Send-Q的作用如下圖所示:
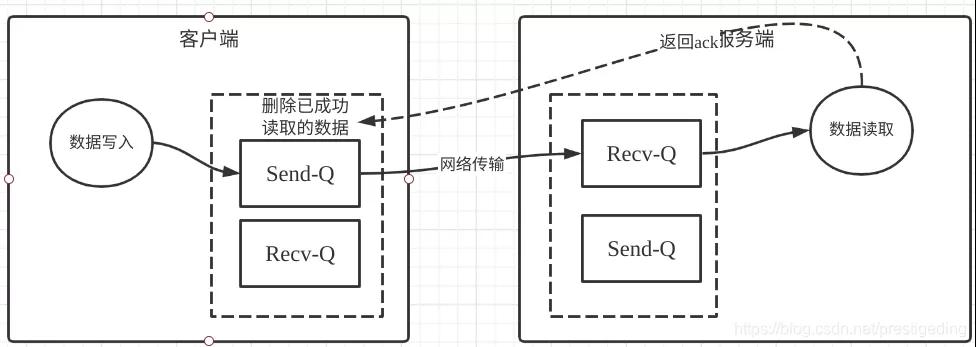
- 客戶端調用網絡通道,例如NIO的Channel寫入數據,數據首先是寫入到TCP的發送緩存區,如果發送發送區已滿,客戶端無法繼續向該通道發送請求,從NIO層面調用Channel底層的write方法,會返回0,表示發送緩沖區已滿,需要注冊寫事件,待發送緩存區有空閑時再通知上層應用程序可以發消息。
- 數據進入到發送緩存區后,接下來數據會隨網絡到達目標端,首先進入的是目標端的接收緩存區,如果與NIO掛鉤的化,通道的讀事件會繼續,應用從接收緩存區中成功讀取到字節后,會發送ACK給發送方。
- 發送方在收到ACK后,會刪除發送緩沖區中的數據,如果接收方一直不讀取數據,那發送方也無法發送數據。
網絡同事分布在客戶端、MQ服務器上通過每500ms采集一次netstat ,經過對采集結果進行匯總,出現如下圖所示:
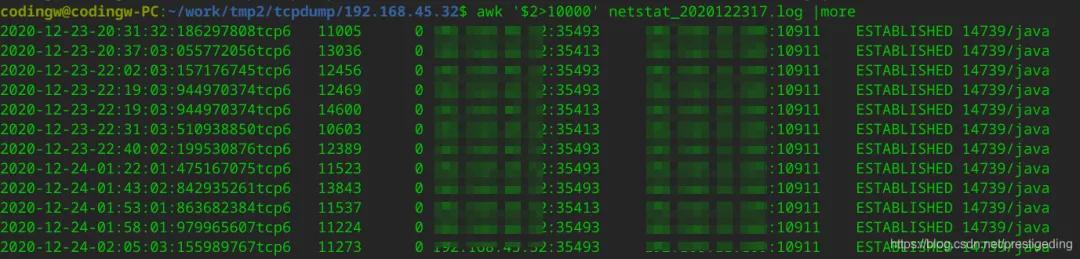
從客戶端來看,客戶端的Recv-Q中會出現大量積壓,對應的是MQ的Send-Q中出現大量積壓。
從上面的通訊模型來看,再次推斷是否是因為客戶端從網絡中讀取字節太慢導致的,因為客戶端為虛擬機,從netstat 結果來看,疑似是客戶端的問題(備注,其實最后并不是客戶端的問題,請別走神)。
2.3.2 網絡抓包
網絡組同事為了更加嚴謹,還發現了如下的包:
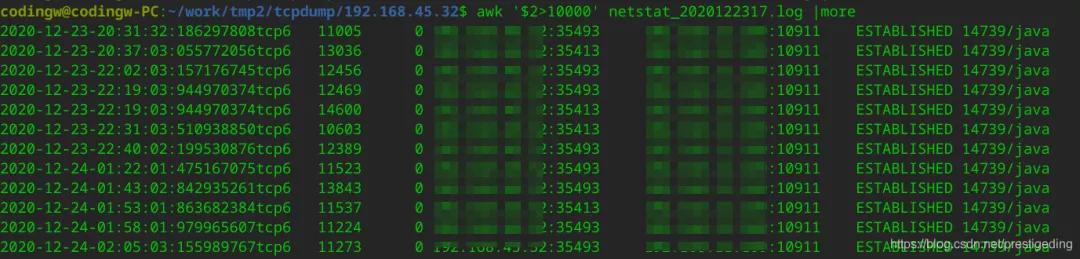
這里有一個問題非常值得懷疑,就是客戶端與服務端的滑動窗口只有190個字節,一個MQ消息發送返回包大概有250個字節左右,這樣會已響應包需要傳輸兩次才能被接收,一開始以為這里是主要原因,但通過其他對比,發現不是滑動窗口大于250的客戶端也存在超時,從而判斷這個不是主要原因,后面網絡同事利用各種工具得出結論,網絡不存在問題,是應用方面的問題。
想想也是,畢竟是局域網,那接下來我們根據netstat的結果,將目光放到了客戶端的讀性能上。
2.4 客戶端網絡讀性能瓶頸分析
為此,我為了證明讀寫方面的性能,我修改了RocketMQ CLient相關的包,加入了Netty性能采集方面的代碼,其代碼截圖如下:
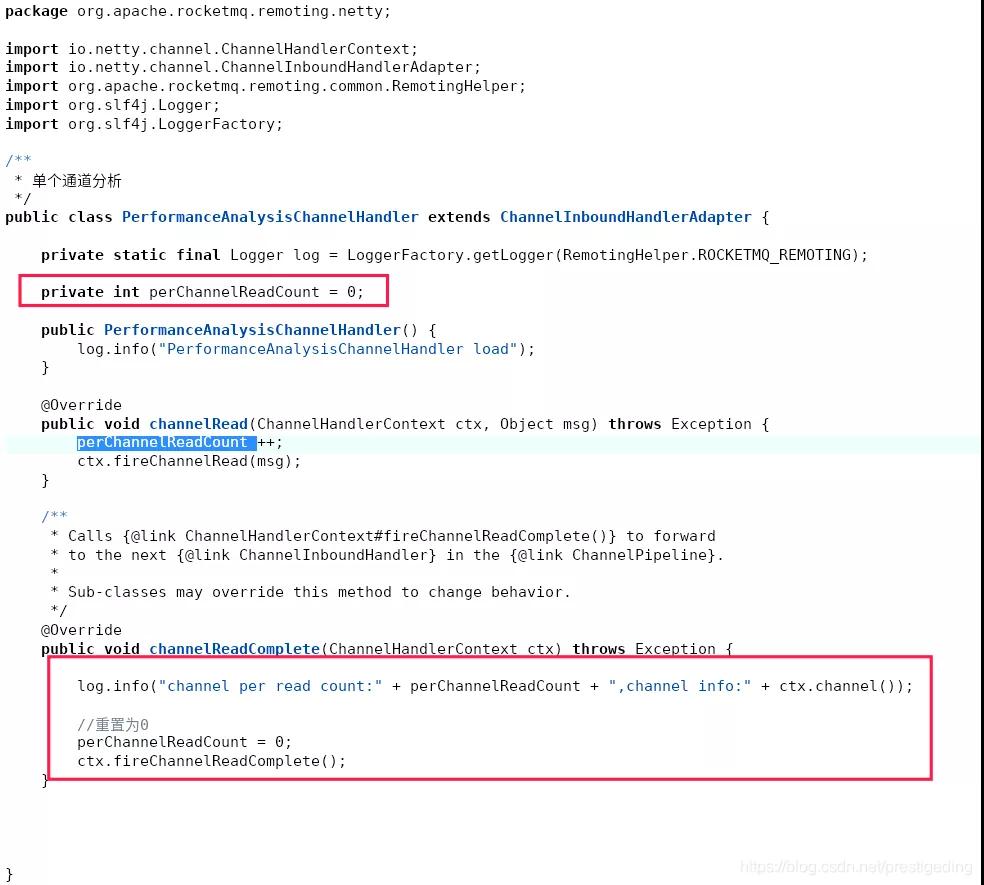
我的主要思路是判斷客戶端對于一個通道,每一次讀事件觸發,一個通道會進行多少次讀取操作,如果一次讀事件觸發,需要觸發很多次的讀取,說明一個通道中確實積壓了很多數據,網絡讀存在瓶頸。
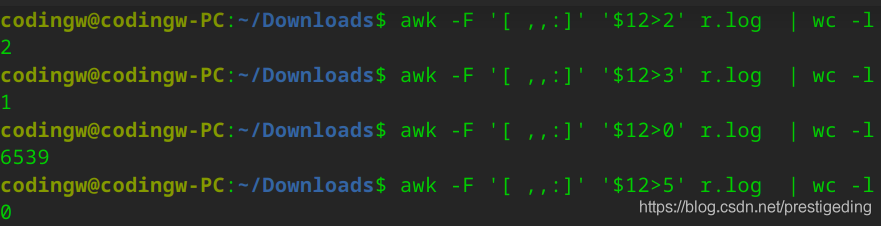
但令人失望的是客戶端的網絡讀并不存在瓶頸,部分采集數據如下所示:

通過awk命令對其進行分析,發現一次讀事件觸發,大部分通道讀兩次即可將讀緩存區中的數據抽取成功,讀方面并不存在瓶頸,對awk執行的統計分析如下圖所示:
那矛頭又將指向Broker,是不是寫到緩存區中比較慢呢?
2.5 Broker端網絡層面瓶頸
經過上面的分析,Broker服務端寫入pagecache很快,維度將響應結果寫入網絡這個環節并未監控,是不是寫入響應結果并不及時,大量積壓在Netty的寫緩存區,從而導致并未及時寫入到TCP的發送緩沖區,從而造成超時。
筆者本來想也對其代碼進行改造,從Netty層面去監控服務端的寫性能,但考慮到風險較大,暫時沒有去修改代碼,而是再次認真讀取了RocketMQ封裝Netty的代碼,在此次讀取源碼之前,我一直以為RocketMQ的網絡層基本不需要進行參數優化,因為公司的服務器都是64核心的,而Netty的IO線程默認都是CPU的核數,但在閱讀源碼發現,在RocketMQ中與IO相關的線程參數有如下兩個:
- serverSelectorThreads
默認值為3。
- serverWorkerThreads
默認值為8。
serverSelectorThreads,在Netty中,就是WorkGroup,即所謂的IO線程池,每一個線程池會持有一個NIO中的Selector對象用來進行事件選擇,所有的通道會輪流注冊在這3個線程中,綁定在一個線程中的所有Channel,會串行進行讀寫操作,即所有通道從TCP讀緩存區,將數據寫到發送緩存區都在這個線程中執行。
我們的MQ服務器的配置,CPU的核屬都在64C及以上,用3個線程來做這個事情,顯然有點太“小家子氣”,該參數可以調優。
serverWorkerThreads,在Netty的線程模型中,默認情況下事件的傳播(編碼、解碼)都在IO線程中,即在上文中提到的Selector對象所在的線程,為了降低IO線程的壓力,RocketMQ單獨定義一個線程池,用于事件的傳播,即IO線程只負責網絡讀、寫,讀取的數據進行解碼、寫入的數據進行編碼等操作,單獨放在一個獨立的線程池,線程池線程數量由serverWorkerThreads指定。
看到這里,終于讓我心潮澎湃,感覺離真相越來越近了。參考Netty將IO線程設置為CPU核數的兩倍,我第一波參數優化設置為serverSelectorThreads=16,serverWorkerThreads=32,在生產環境進行一波驗證。
經過1個多月的驗證,在集群機器數量減少(雙十一之后縮容),只出現過極少數的消息發送超時,基本可以忽略不計。
3、總結
本文詳細介紹了筆者排查MQ發送超時的精力,最終定位到的是RocketMQ服務端關于網絡通信線程模型參數設置不合理。
之所以耗費這么長時間,其實有值得反思的地方,我被我的“經驗”誤導了,其實以前我對超時的原因直接歸根于網絡,理由是RocketMQ的寫入PageCache數據非常好,基本都沒有超過100ms的寫入請求,以為RocketMQ服務端沒有性能瓶頸,并沒有從整個網絡通信層考慮。
本文轉載自微信公眾號「中間件興趣圈」,可以通過以下二維碼關注。轉載本文請聯系中間件興趣圈公眾號。