













機器學習概述
概述:讀完這篇文章你將能夠:
- 辨別不同類型的機器學習問題;
- 理解什么是機器學習模型;
- 知道建立和應用機器學習模型的一般工作流;
- 了解常見機器學習算法的優點和缺點。
機器學習模型
機器學習(Machine Learning)這個術語常常掩蓋了它的計算機科學性質,因為它的名字可能暗示機器正在像人類一樣學習,甚至做得更好。
盡管我們希望有一天機器能夠像人類一樣思考和學習,但如今機器學習并不能超越執行預定義過程的計算機程序。機器學習算法與非機器學習算法(如控制交通燈的程序)的不同之處在于,它能夠使自身的行為適應新的輸入。而這種似乎沒有人為干預的適應,偶爾會給人一種機器真的是在學習的錯覺。然而,在機器學習模型的背后,這種行為上的適應和人類編寫的每一條機器指令一樣嚴格。
那么什么是機器學習模型?
機器學習算法是揭示數據中潛在關系的過程。
機器學習模型(machine learning model)是機器學習算法產出的結果,可以將其看作是在給定輸入情況下、輸出一定結果的函數(function)F。
機器學習模型不是預先定義好的固定函數,而是從歷史數據中推導出來的。因此,當輸入不同的數據時,機器學習算法的輸出會發生變化,即機器學習模型發生改變。
例如,在圖像識別的場景中,可以訓練機器學習模型來識別照片中的對象。在某種情況下,人們可能會將數千張有貓和沒有貓的圖像輸入到機器學習算法中,以獲得一個能夠判斷照片中是否有貓的模型。因此,生成的模型對應的輸入將是一張數字照片,而輸出是一個表示照片上是否存在貓的布爾值。
在上述情況下,機器學習模型是一個將多維像素值映射到二進制值的函數。假設我們有一張 3 維像素的照片,每個像素的值范圍從 0 到 255。那么輸入和輸出之間的映射空間將是 (256×256×256)×2,大約是 3300 萬。我們可以說服自己,在現實世界的案例中學習這種映射(機器學習模型)一定是一項艱巨的任務,因為在這種情況下,一張普通照片占到數百萬像素,并且每個像素由三種顏色(RGB)組成,而不是單一的灰色。
機器學習的任務,就是從廣闊的映射空間中學習函數。
在這種情況下,找出數百萬像素和 “是/否” 答案之間的潛在映射關系的過程,就是我們所說的機器學習。大多數時候,我們學習的最后結果是對這種潛在關系的一種近似。由于機器學習模型的近似性質,人們不應該因發現機器學習模型的結果往往無法達到 100%精確而感到失望。在 2012 年深度學習被廣泛應用之前,最好的機器學習模型只能在 ImageNet 視覺識別挑戰 中達到 75% 精度。到目前為止,還沒有一種機器學習模型能夠保證 100%精確,盡管在這項任務中,有一些模型的誤差要比人類少 <5%。
有監督 VS. 無監督
給出一個機器學習問題,首先可以確定它是有監督(supervised) 問題還是無監督(unsupervised) 問題。
對于任何機器學習問題,我們都從一組樣本(samples)組成的數據集開始。每個樣本可以表示為一個屬性(attributes)元組。
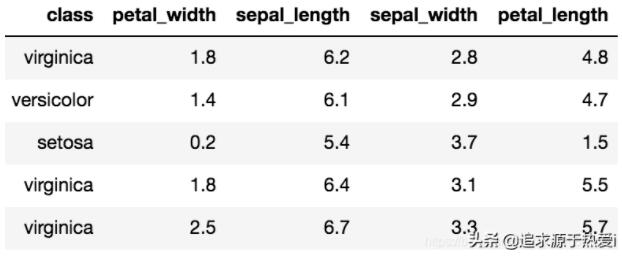
例如,有一個名為 Iris 的著名經典數據集,首次發表于 Ronald. A. Fisher 在 1936 年的論文 “The use of multiple measurements in taxonomic problems(可譯作:多重測量在分類學問題中的使用)”。Iris 數據集包括對 150 個鳶尾花樣本的測量。每個樣本都包含其花瓣和萼片的長度和寬度的測量值,以及指示鳶尾花類別的屬性,即山鳶尾、變色鳶尾和維吉尼亞鳶尾。以下是 Iris 數據集的一些示例
有監督學習
在一個有監督的學習任務中,數據樣本將包含一個目標屬性 yyy,也就是所謂的真值(ground truth)。我們的任務是通過學習得到一個函數 F,它接受非目標屬性 X,并輸出一個接近目標屬性的值,即 F(X)≈yF(X) \approx yF(X)≈y。目標屬性 yyy 就像指導學習任務的教師,因為它提供了一個關于學習結果的基準。所以,這項任務被稱為有監督學習。
在 Iris 數據集中,類別屬性(鳶尾花的類別)可以作為目標屬性。具有目標屬性的數據通常稱為 “標記” 數據(labeled data)。基于上述定義,可以看出用標記數據預測鳶尾花的種類的任務是一個有監督的學習任務。
無監督學習
與有監督的學習任務相反,我們在無監督的學習任務中沒有設置真值。人們期望從數據中學習潛在的模式或規則,而不以預先定義的真值作為基準。
人們可能會問,如果沒有來自真值的監督,我們還能學到什么嗎?答案是肯定的。以下是一些無監督學習任務的示例:
- 聚類(Clustering):給定一個數據集,可以根據數據集中樣本之間的相似性,將樣本聚集成組。例如,樣本可以是一個客戶檔案,具有諸如客戶購買的商品數量、客戶在購物網站上花費的時間等屬性。根據這些屬性的相似性,可以將客戶檔案分組。對于聚集的群體,可以針對每個群體設計特定的商業活動,這可能有助于吸引和留住客戶。
- 關聯(Association):給定一個數據集,關聯任務是發現樣本屬性之間隱藏的關聯模式。例如,樣本可以是客戶的購物車,其中樣本的每個屬性都是商品。通過查看購物車,人們可能會發現,買啤酒的顧客通常也會買尿布,也就是說,購物車里的啤酒和尿布之間有很強的聯系。有了這種學習而來的洞察力,超市可以將那些緊密相關的商品重新排列到相鄰近的角落,以促進這一種或那一種商品的銷售。
半監督學習
在數據集很大,但標記樣本很少的情況下,可以找到同時具備有監督和無監督學習的應用。我們可以將這樣的任務稱為半監督學習(semi-supervised learning)。
在許多情況下,收集大量標記的數據是非常耗時和昂貴的,這通常需要人工進行操作。斯坦福大學的一個研究團隊花了兩年半的時間來策劃著名的 “ImageNet”,它包含了數以百萬計的圖像帶有成千上萬個手動標記的類別。因此,更普遍的情況是,我們有大量的數據,但只有很少一部分被準確地 “標記”,例如視頻可能沒有類別甚至標題。
通過將有監督和無監督的學習結合在一個只有少量標記的數據集中,人們可以更好地利用數據集,并獲得比單獨應用它們更好的結果。
例如,人們想要預測圖像的分類,但只對圖像的 10% 進行了標記。通過有監督的學習,我們用有標記的數據訓練一個模型,然后用該模型來預測未標記的數據,但是我們很難相信這個模型是足夠普遍的,畢竟我們只用少量的數據就完成了學習。一種更好的策略是首先將圖像聚類成組(無監督學習),然后對每個組分別應用有監督的學習算法。第一階段的無監督學習可以幫助我們縮小學習的范圍,第二階段的有監督學習可以獲得更好的精度。
引用
[1]. Fisher,R.A. “The use of multiple measurements in taxonomic problems” Annual Eugenics, 7, Part II, 179-188 (1936)
分類 VS. 回歸
在前一節中,我們將機器學習模型定義為一個函數 FFF,它接受一定的輸入并生成一個輸出。通常我們會根據輸出值的類型將機器學習模型進一步劃分為分類(classification)和回歸(regression)。
如果機器學習模型的輸出是離散值(discrete values),例如布爾值,那么我們將其稱為分類模型。如果輸出是連續值(continuous values),那么我們將其稱為回歸模型。
分類模型
例如,說明照片中是否包含貓的模型可以被視為分類模型,因為我們可以用布爾值表示輸出。
更具體地說,輸入可以表示為矩陣M,尺寸為 H×W,其中 H 是照片的高度(像素),W 是照片的寬度。矩陣中的每個元素都是照片中每個像素的灰度值,即一個介于 [0,255]之間的整數,表示顏色的強度。模型的預期輸出為二進制值 [1∣0],用于指示照片是否顯示貓。綜上所述,我們的貓照片識別模型 F 可表述如下:
F(M[H][W])=1∣0,where M[i][j]∈[0,255],0<i<H,0<j<WF(M[H][W])
機器學習的目標是找出一個盡可能通用的函數,這個函數要盡可能對不可見數據給出正確的答案。
回歸模型
對于回歸模型,我們給出這樣一個例子,考慮一個用于估算房產價格的模型,其特征包括諸如面積、房產類型(例如住宅、公寓),當然還有地理位置。在這種情況下,我們可以將預期輸出看作是一個實數 p∈R,因此它是一個回歸模型。注意,在本例中,我們所擁有的原始數據并非全部是數字,其中某些數據是用于分類的,例如房地產類型。在現實世界中,情況往往就是這樣的。
對于每個正在考慮的房產,我們可以將其特征用元組 T 來表示,其中元組中的每個元素要么是數值,要么是表示其屬性之一的分類值。在許多情況下,這些元素也被稱為 “特征(features)”。綜上所述,我們可以建立如下的房產價格估算模型:
F(T)=p,where p∈R
再具體一些,讓我們考慮一個具有以下特征的房產:
surface = 120 m^2 , type = ’ apartment’, location = ’ NY downtown’, year_of_construction = 2000
現在考慮到上述特征,如果我們的模型 F 給出了一個像 10,000$ 這樣的值,那么很可能我們的模型并不適合這個問題。
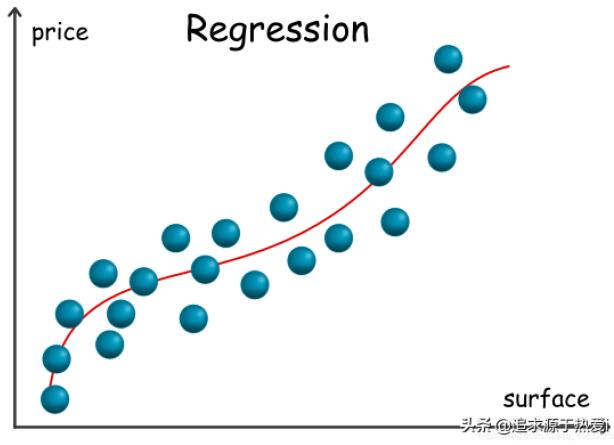
在下面的圖表中,我們展示了一個以地產面積為唯一變量,以地產價格為輸出的回歸模型樣例。
說起特征,還要提到的一點是,一些機器學習模型(例如決策樹)可以直接處理非數字特征,而更多時候人們必須以某種方式將這些非數字特征轉換(transform)為數字特征。
問題轉化
對于一個現實世界的問題,有時人們可以很容易地將其表述出來,并快速地將其歸結為一個分類問題或回歸問題。然而,有時這兩個模型之間的邊界并不清晰,人們可以將分類問題轉化為回歸問題,反之亦然。
在上述房產價格估算的例子中,似乎很難預測房產的確切價格。然而,如果我們將問題重新表述為預測房產的價格范圍,而不是單一的價格標簽,那么我們可以期望獲得一個更健壯的模型。因此,我們應該將問題轉化為分類問題,而不是回歸問題。
對于我們的貓照片識別模型,我們也可以將其從分類問題轉換為回歸問題。我們可以定義一個模型來給出一個介于 [0,100%] 之間概率值來判斷照片中是否有貓,而不是給出一個二進制值作為輸出。這樣,就可以比較兩個模型之間的細微差別,并進一步調整模型。例如,對于有貓的照片,模型 A 給出概率為 1%,而模型 B 對相同照片給出了 49%的概率。雖然這兩種模型都沒有給出正確的答案,但我們可以看出,模型 B 更接近于事實。在這種情況下,人們經常應用一種稱為邏輯回歸(Logistic Regression)的機器學習模型,這種模型將連續概率值作為輸出,但用于解決分類問題。
機器學習工作流
在前一節中,我們闡明了機器學習模型的概念,在這一部分中,我們將會討論一個用于構建機器學習模型的典型工作流(workflow)。
首先,我們不能一昧只談論機器學習,而將數據擱置在一旁。數據之于機器學習模型就如燃料之于火箭發動機一樣重要。
以數據為中心的工作流
構建機器學習模型的工作流是以數據為中心的。
毫不夸張地說,數據決定了機器學習模型的構建方式。在下圖中,我們展示了機器學習項目中涉及的典型工作流。
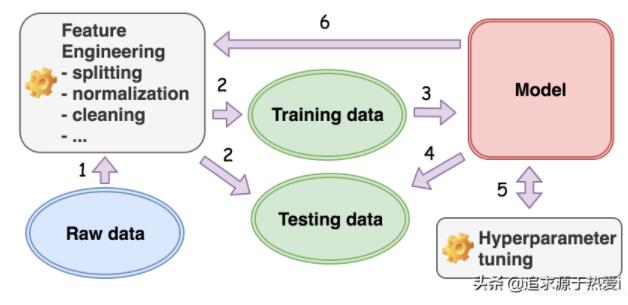
從數據出發,我們首先需要確定我們要解決的機器學習問題的類型,即有監督的學習問題還是無監督的機器學習問題。我們規定,如果數據中的一個屬性是所需的屬性,即目標屬性,那么該數據被標記。例如,在判斷照片上是否有貓的任務中,數據的目標屬性可以是布爾值 [Yes|No]。如果這個目標屬性存在,那么我們就說數據被標記了,這是一個簡單的學習問題。
對于有監督的機器學習算法,我們根據模型的預期輸出進一步確定生成模型的類型:分類或回歸,即分類模型的離散值和回歸模型的連續值。
一旦我們確定了想要從數據中構建的模型類型,我們就開始執行特征工程(feature engineering),這是一組將數據轉換為所需格式的活動。下面給出了幾個例子:
對于幾乎所有的情況,我們將數據分成兩組:訓練和測試。在訓練模型的過程中使用訓練數據集,然后使用測試數據集來測試或驗證我們構建的模型是否足夠通用,是否可以應用于不可見的數據。
原始數據集通常是不完整的,帶有缺失值。因此,可能需要用各種策略來填充這些缺失值,例如用平均值進行填充。
數據集通常包含分類屬性,如國家、性別等,通常情況下,由于算法的限制,需要將這些分類字符串值編碼為數值。例如,線性回歸算法只能處理輸入的實值向量。
特征工程的過程無法一蹴而就。通常,在工作流的稍后階段,您需要反復地回到特征工程上來。
一旦數據準備好,我們就選擇一個機器學習算法,并開始向算法輸入準備好的訓練數據(training data)。這就是我們所說的訓練過程(training process)。
一旦我們在訓練過程結束后獲得了機器學習模型,就需要用保留的測試數據(testing data)對模型進行測試。這就是我們所說的測試過程(testing process)。
初次訓練的模型往往無法令人感到滿意。此后,我們將再一次回到訓練過程,并調整由我們選擇的模型公開的一些參數。這就是我們所說的超參數調優(hyper-parameter tuning)。之所以突出 “超(hyper)”,是因為我們調優的參數是我們與模型交互的最外層接口,而這最終會對模型的底層參數造成影響。例如,對于決策樹模型,其超參數之一是樹的最大高度。一旦在訓練之前進行手動設置,它將限制決策樹在結束時可以生長的分支和葉的數量,而這些正是決策樹模型所包含的基本參數。
可以看到,機器學習工作流所涉及的幾個階段形成了一個以數據為中心的循環過程。
數據,數據,數據!
機器學習工作流的最終目標是建立機器學習模型。我們從數據中得到模型。因此,模型所能達到的性能上限是由數據決定的。有許多模型可以擬合特定的數據。我們所能做到最好的,就是找到一個可以最接近于數據所設置的上限的模型。我們不能期望一個模型能夠從數據的范圍之內學到其他東西。
經驗法則: 若輸入錯誤數據,則輸出亦為錯誤數據。
用盲人摸象的寓言來說明這一觀點也許是較為恰當的。故事是這樣的,一群從來沒有遇到過大象的盲人,他們試圖通過觸摸大象來了解和概念化大象是什么樣子。每個人都可以觸摸大象身體的一部分,如腿、象牙或尾巴等。雖然他們每個人都有接觸到一部分真實情形,但沒有一個人能獲知大象的全貌。因此,他們中沒有一個人可以真正了解大象的真實形象。

現在,回到我們的機器學習任務,我們得到的訓練數據可能是來自象腿或象牙的圖像,而在測試過程中,我們得到的測試數據是大象的完整肖像。不出所料,我們的訓練模型在這種情況下表現不佳,因為我們沒有更切合實際的高質量訓練數據。
有人可能會想,如果這些數據真的很重要,那么為什么不將大象的完整肖像等 “高質量” 數據輸入到算法中,而偏偏要輸入大象身體某些部分的概況呢?這是因為,在面對一個問題時,無論是我們還是機器,就像 “盲人” 一樣,或者是由于技術問題(例如數據隱私),或者僅僅是因為我們沒有以正確的方式認識到問題,常常很難收集到能夠描繪問題本質特征的數據,
現實世界中,在有利的情況下,我們得到的數據可能反映了現實的一部分,而在不利的情況下就可能是一些干擾判斷的噪音,在最糟糕的情況下,甚至會與現實相矛盾。不管機器學習算法如何,人們都無法從包含太多噪音或與現實不符的數據中學到任何東西。
欠擬合 VS. 過擬合
對于有監督學習算法,例如分類和回歸,通常有兩種情況下生成的模型不能很好地擬合數據:欠擬合(underfitting)和過擬合(overfitting)。
有監督學習算法的一個重要度量是泛化,它衡量從訓練數據導出的模型對不可見數據的期望屬性的預測能力。當我們說一個模型是欠擬合或過擬合時,它意味著該模型沒有很好地推廣到不可見數據。
一個與訓練數據相擬合的模型并不一定意味著它能很好地概括不可見數據。有以下幾點原因:1). 訓練數據只是我們從現實世界中收集的樣本,只代表了現實的一部分。這可能是因為訓練數據根本不具有代表性,因此即使模型完全符合訓練數據,也不能很好的擬合不可見數據。2). 我們收集的數據不可避免地含有噪音和誤差。即便該模型與數據完全吻合,也會錯誤地捕捉到不期望的噪音和誤差,最終導致對不可見數據的預測存在偏差和誤差。
在深入欠擬合和過擬合的定義之前,我們將會展示一些能夠反映欠擬合和過擬合模型在分類任務中真實情形的示例。
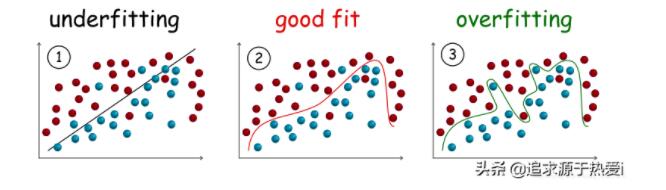
欠擬合
欠擬合模型是指不能很好地擬合訓練數據的模型,即顯著偏離真實值的模型。
欠擬合的原因之一可能是模型對數據而言過于簡化,因此無法捕獲數據中隱藏的關系。從上圖**(1)**可以看出,在分離樣本(即分類)的過程中,一個簡單的線性模型(一條直線)不能清晰地畫出不同類別樣本之間的邊界,從而導致嚴重的分類錯誤。
為了避免上述欠擬合的原因,我們需要選擇一種能夠從訓練數據集生成更復雜模型的替代算法。
過擬合
過擬合模型是與訓練數據擬合較好的模型,即誤差很小或沒有誤差,但不能很好地推廣到不可見數據。
與欠擬合相反,過擬合往往是一個能夠適應每一位數據的超復雜模型,但卻可能會陷入噪音和誤差的陷阱。從上面的圖**(3)**可以看出,雖然模型在訓練數據中的分類錯誤少了,但在不可見數據上更可能出錯。
類似地于欠擬合的情況,為了避免過擬合,可以嘗試另一種從訓練數據集生成更簡單的模型的算法。或者更常見的情況是,使用生成過擬合模型的原始算法,但在算法中增加添加了正則化(regularization)項,即對過于復雜的模型進行附加處理,從而引導算法在擬合數據的同時生成一個不太復雜的模型。
為什么要機器學習
在閱讀前面的章節之后,我們應該能夠大致地說出機器學習(ML)算法是什么,并且應該對如何在項目中應用 ML 有一個簡要的想法。
現在,在這一章中,我們正應該思考這個問題:為什么我們需要 ML 算法?
首先,我們需要承認,目前(2018 年),在我們生活中的許多方面,確實需要 ML 算法。值得注意的是,它在互聯網服務中(如社交網絡、搜索引擎等)無處不在,而我們每天都在使用這些工具。事實上,正如 Facebook 最近發表的一篇論文所揭示的那樣,ML 算法變得如此重要,以至于 Facebook 開始從硬件到軟件重新設計數據中心,以更好地滿足應用 ML 算法的要求。
“在 Facebook 上,機器學習提供了驅動用戶體驗幾乎所有方面的關鍵功能……機器學習廣泛應用于幾乎所有的服務。”
以下是關于 ML 如何在 Facebook 中應用的幾個示例:
- 新聞提要中的事件排序是通過 ML 進行的。
- 顯示廣告的時間、地點和對象由 ML 確定。
- 各種搜索引擎(如照片、視頻、人物)都是由ML支持的。
在我們現在使用的服務(例如谷歌搜索引擎、亞馬遜電子商務平臺)中,可以很容易地識別出許多其他應用 ML 的場景。ML 算法的普遍存在已經成為現代生活中的一種規范,這就證明了至少在現在和不久的將來都有其存在的合理性。
為什么要機器學習?
ML 算法之所以存在,是因為它們能夠解決非 ML 算法無法解決的問題,而且還提供了非 ML 算法所不具備的優勢。
區分 ML 算法與非 ML 算法的最重要特征之一是,它將模型與數據分離,以便 ML 算法能夠適應不同的業務場景或相同的業務案例,但具有不同的上下文。例如,可以應用分類算法來判斷照片上是否顯示了人臉。它還可以用來預測用戶是否會點擊廣告。在人臉檢測的情況下,同樣的分類算法可以訓練一個模型來判斷照片上是否出現了人臉,也可以訓練另一個模型來確認照片上出現的是誰。
通過分離模型與數據,ML 算法可以一種更靈活、更通用、更自治的方式來解決許多問題,也就是說,它更像是一個人。ML 算法似乎能夠從環境(即數據)中學習知識,并相應地調整其行為(即模型),以解決特定的問題。在不對 ML 算法中的規則(即模型)進行顯式編碼的情況下,我們構造了一種元算法,它能夠以有監督或無監督的方式從數據中學習規則/模式。
機器學習真的無所不能嗎?
一旦人們開始學習各種機器學習(ML)算法,并了解到這些算法在處理諸如圖像識別和語言翻譯等具有挑戰性的任務時的多才多藝,人們可能會沉溺于將 ML 應用于他們所面臨的每一個問題,無論它是否真的合適。因為通常情況下,如果你的工具有一把錘子,你會認為任何問題都是釘子。
因此,在這一節中,我們想要強調一些看上去消極的事項。和所有其他的解決方案一樣,ML 并不是什么萬應良方。
和人類一樣,ML 模型也會犯錯。
例如,有人可能會注意到,Facebook 有時無法從照片中標記出一張臉。不幸的是,人們似乎接受了這種情形,即目前最先進的 ML 算法通常無法達到 100% 精確。人們甚至會為 ML 算法辯護,因為 ML 所處理的問題即便對人類來說也確實很難解決,例如圖像識別。然而,它與過去普遍的認知形成了對比,即機器不會犯任何錯,或者至少比人類更少犯錯。有一段時間(2012年之前),人們可以很容易地宣稱以 75% 精度的模型獲得 ImageNet 挑戰的冠軍。應該注意的一點是,該挑戰往往被認為是圖像識別領域的奧林匹克賽事。因此,人們可以將 ImageNet 挑戰的結果視為領域中最先進的研究成果,但到目前為止(2018年),仍然沒有模型能夠達到 100% 的精度。一般來說,可以達到 ~80% 精度的ML模型被認為具有良好的性能。因此,在算法精度至關重要的情況下,人們應該慎重考量他們采用 ML 算法的決定。
很難(在不是不可能的情形下)以逐例的方式糾正 ML 所犯的錯誤。
有人可能會想,如果我們把 ML 模型所犯的每一個錯誤都看作是軟件中的一個缺陷,難道我們就不能一個接一個地糾正它們,從而一步一步地提高準確性嗎?答案是否定的。究其原因有兩個方面:1). 一般來說,我們通常無法顯式地操作一個 ML 模型,而是用給定的數據結合 ML 算法來共同生成模型。為了改進一個模型,我們要么改進算法,要么提高數據質量,而不是直接修改模型。2). 即使我們可以在隨后操作生成的 ML 模型,由于無法直觀看到改進造成的影響,在某些 “錯誤” 情況下,如何在不影響其他正確情況的情況下更改 ML 模型的輸出又成為了一個新的難題。例如,對于決策樹模型,模型的輸出是每個節點的分支條件的結合,遵循從根到葉的路徑。我們可以更改節點中的某些分支條件,以更改在錯誤情況下的決定。但是,這種更改也會影響通過修改的節點傳遞的每種情況的輸出。總之,人們不能簡單地將 ML 模型所犯的錯誤等同于軟件中的缺陷。需要一種整體的方法來改進模型,而不是逐例修補模型。
對于某些 ML 模型,很難(如果不是不可能的話)進行推理。
到目前為止,人們已經了解到 ML 模型存在錯誤,而且很難逐例糾正錯誤。也許事情并沒有那么糟糕,因為至少我們可以解釋它為什么會出錯,比如決策樹模型。然而,在某些情況下,特別是對于帶有神經網絡的 ML 模型,我們不能真正對這些模型進行推理,也就是說,很難對模型作出解釋,從而識別模型中的關鍵參數。例如,有一個叫做 ResNet 的最先進的神經網絡模型,它在 ImageNetChallenge 中實現了高達 96.43% 的精度。ResNet-50 模型由 50 層神經元組成,包括 2560 萬個參數。每個參數都有助于模型的最終輸出。無論輸出是否正確,都是模型背后的數百萬個參數共同作用的結果。很難將任何邏輯單獨歸于每個參數。因此,在偏重模型可解釋性的場景中,應該仔細考量應用基于神經網絡的 ML 模型的決定。
因此,概括地說,ML不是靈丹妙藥,因為它常常無法達到 100%100 %100% 精確,而且我們不能逐例更正 ML 模型,在某些情況下,我們甚至無法對 ML 模型進行推理。
拓展閱讀
[1]. ResNet: Deep Residual Learning for Image Recognition. He et al.CVPR 2016 Las Vegas, NV, USA.
[2]. LIME: Explaining the Predictions of Any Classifier. Ribeiro et al. KDD 2016 San Francisco, CA, USA.
















