如何為應用程序選擇合適的數據庫
致力于新項目總是超級令人興奮 - 我們有自由設計和建立任何我們想要的東西的東西。但是,這個規劃,當沒有正確完成時,將來會導致我們很多痛苦。
選擇您的應用程序數據庫是您必須制作的重要決策之一,并且隨著本文,我打算向您介紹各種數據庫選項 - 以及列出一些優點和缺點,以幫助您制作更明智的數據庫決策。
內存數據庫 Redis
我們的數據庫的結構就像一個JSON對象-每個鍵都是唯一的,每個鍵都指向某個值。
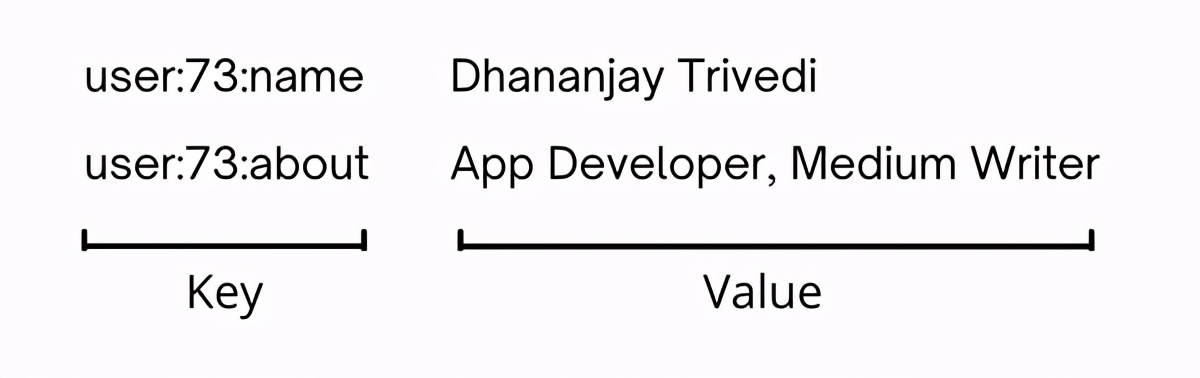
它保留了內存中的數據,這非常快,但具有容量限制,因此您無法存儲大量數據。并且由于沒有涉及的磁盤,一切都快速燃燒。
無需查詢或聯接,因此無需擔心太多數據建模。由于沒有架構,因此開發人員始終可以根據自己的需要靈活地更改數據。

何時使用這種技術
- 該技術主要用作緩存機制,用于某些時候非常頻繁地獲取和觀察部分數據
- 因此,關鍵值技術與其他數據庫一起廣泛使用作為緩存機制
寬列數據庫 Cassandra
這就像鑰匙值,但在類固醇上。修改該值以存儲一組列,而不是簡單數據。

通過引入列,您現在可以對相關數據進行分組,但是仍然沒有標準架構。因此,每個鍵都可以指向不同的分組數據。
由于沒有模式,它可以處理非結構化數據,并附上一個名為CQL的查詢語言,這類似于SQL,但方法不那么強大。
數據源源不斷,例如來自IoT設備,股票市場,金融交易或Netflix的觀看歷史記錄。

何時使用此技術
- 經常寫
- 少更新或讀取
這仍然不是通用的。因此,它可以用于存儲來自我們所有不同應用程序的歷史數據。
文檔數據庫
這是我們使用的最受歡迎的數據庫技巧之一。這顯然由文檔組成,每個文檔都是一組鍵值對。它們是非結構化,不需要模式。

文檔將組合成集合,并且這些集合可以構造成邏輯層次結構。
這種邏輯集合允許您以更邏輯的方式對相關數據進行分組,這似乎類似于關系數據庫。

由于我們的數據庫無法運行聯接查詢,我們該如何立即獲取所有相關數據?
我們將它全部存儲在一起!我們鼓勵數據庫的非規范化,數據復制/不一致是一種折衷,我們已準備好。
讀取速度確實很快,但是在確保數據一致性的同時寫入和更新數據可能會有些困難。
文檔數據庫非常適合通用應用程序,并且可能適合大多數應用程序,游戲和IoT。
如果您真的不確定數據庫架構,那么文檔數據庫是最佳啟動方式。
流行的文檔類型數據庫

當您有大量數據時,文檔風格的數據庫就不夠用了,它們可能直接或間接地相互關聯。
對于這些情況,您將必須運行多個復雜查詢,然后在前端應用程序中合并所有接收到的數據,或者可以使用關系數據庫,其中這些復雜查詢由數據庫管理。
關系型數據庫
我們都聽說過這些數據庫,最受歡迎的是MySQL,Postgres和SQL Server。他們在這里一直在這里,仍然是許多應用程序的熱門選擇。
我們使用結構化查詢語言(SQL)。
“關系”的意義
想象一下一家汽車工廠,那里有制造汽車零件的不同輪轂。
假設門是在一個地方制造的,而輪子,車身和內飾都是在各自不同的位置制造的。
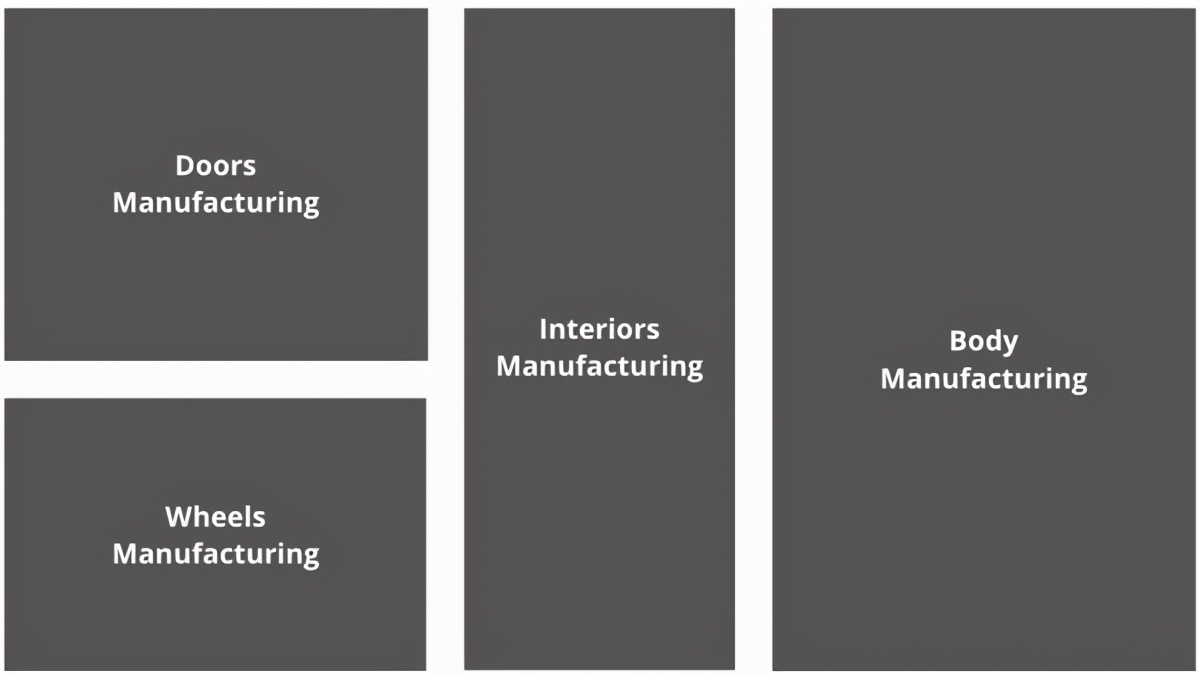
> Imaginary car-factory blueprint
每個制造的零件都有一個唯一的ID分配給它。
因此,一旦必須組裝汽車,您就可以從所有這些不同的位置提取所有零件并組裝汽車。
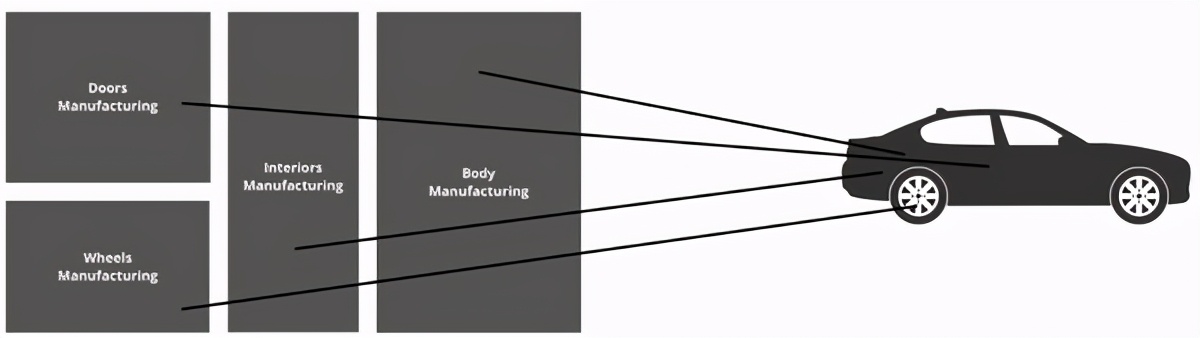
對于這樣一個工廠建立建立,我們會為這樣的工廠創建藍圖,這使得制造汽車的整體過程非常有效和最佳。當它在數據庫中使用時,此藍圖稱為模式。
因此,我們需要規劃數據庫的模式,以確保我們的數據庫對應用程序的數據需求非常有效。
不足之處
- 就像如何隨著時間的推移,改變汽車工廠的布局與改變要求一致,將花費汽車公司一大堆時間和金錢,這是一個類似的情況,當大規模的應用程序必須這樣做時。當您的要求清晰時,請務必使用關系數據庫。
- 此外,一旦您每月建造一個具有制造30輛汽車的工廠,您就無法輕易擴展您的工廠,每月制造90輛汽車。同樣,我們的關系數據庫可能更加努力,但蟑螂DB和PostgreSQL有一些例外,旨在以比例為準。
好的方面
- SQL數據庫符合ACID標準,這意味著即使讀寫操作之間可能會失敗,我們的數據有效性和完整性也不會受到損害-這使其非常適合與銀行/金融相關的數據
- 有一個模式到位后,可以放心,存儲的數據將始終存儲在一組驗證之后的固定結構中,您將在架構中定義
最適合您的是什么?
- 如果您的要求很明確,并且確定您不需要對要求進行任何大的更改,請繼續執行此操作
- 如果您不太確定需求并處于實驗階段,最好使用NoSQL數據庫
但是,如果我們不需要創建架構并可以將關系直接存儲為數據怎么辦?
圖數據庫
這里我們的數據存儲在節點中,并且關系定義為邊。非常漂亮!讓我們看看如何。
如果您必須在SQL數據庫中找出所有學習計算機科學的學生,您需要一個查找/中間商表,該表將所有學生的記錄分開地存儲了學習計算機科學的所有學生。
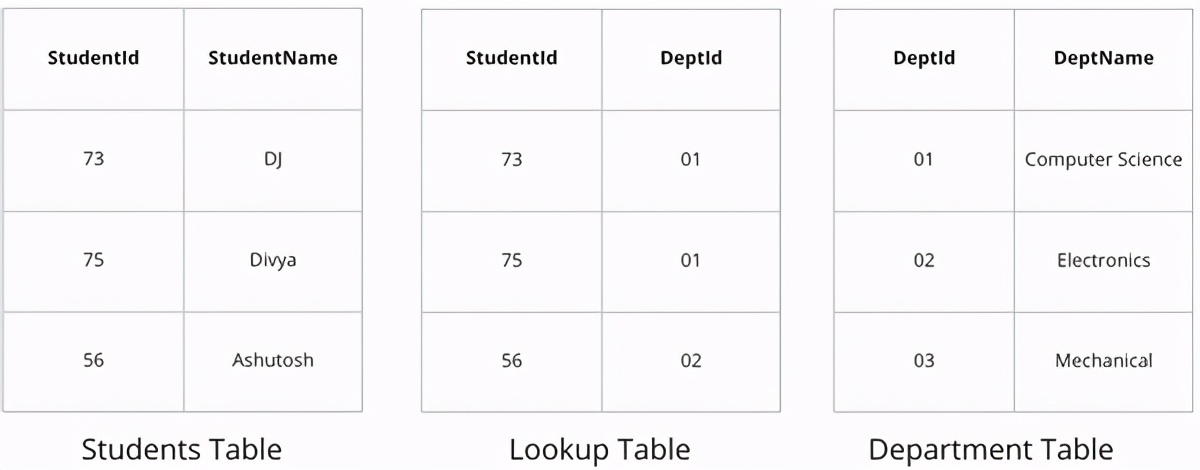
在圖形中,這將更加簡單明了,因為我們不必分別存儲數據中的關系部分,而它本能地是這種新樣式。
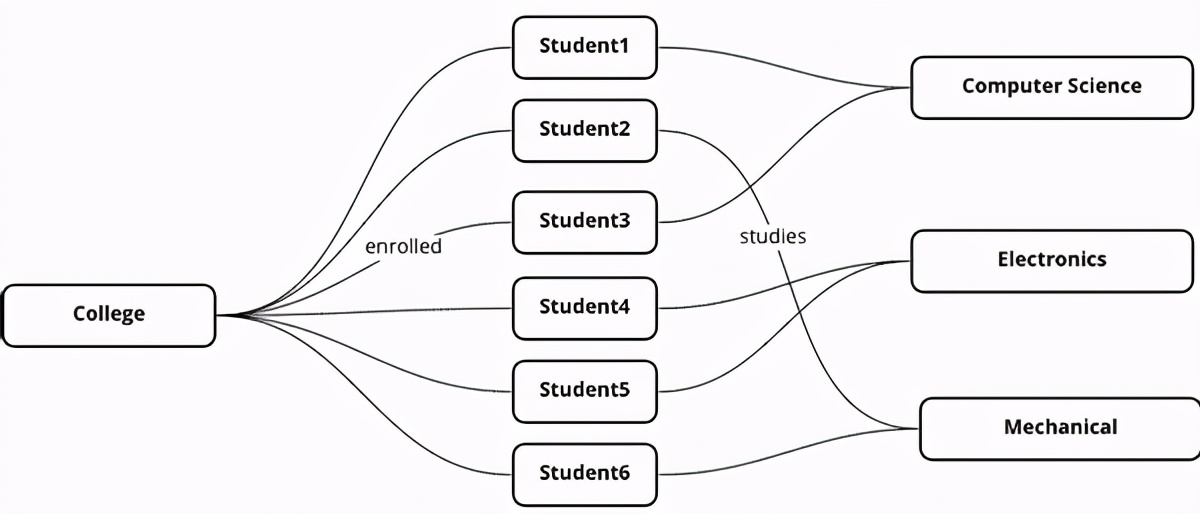
> Relationships are easier to record and maintain in graphs
通過這種直接顯示兩個節點之間關系的新方法,我們復雜的聯接查詢變得更加簡單,與SQL相比,極大地提高了數據庫的性能。
因此,當您依賴于大量加入操作時使用此類數據庫,并且由于該依賴于性能劣化。
搜索數據庫
如果您要構建Google之類的應用程序,那么在小字符串查詢搜索中,您必須快速返回所有匹配的記錄-您所說的是全文搜索引擎。
這些數據庫基于1999年開始的Apache Lucene項目。
Algolia和Meilisearch是全文搜索引擎。
它們看起來類似于文檔類型的數據庫。我們有一個索引,并向其中添加了數據對象。搜索數據庫引擎將分析文檔中的所有文本,并創建稱為反向索引的內容。
當您查詢某些內容時,數據庫只會去檢查反向索引,這使整個過程看起來很快,即使對于大型數據庫也是如此。
我把最激動人心的一個保存下來。
多模型數據庫
那里有多種選擇,但最受歡迎的選擇似乎是動物區系。
作為應用程序開發,我們通常只關心JSON,我們可以在我們的應用程序的前端中消耗。
通過Fauna,我們不必擔心數據建模,架構,縮放,復制或歸一化,并且只需獲取我們的JSON數據。我們定義了如何使用GraphQL訪問我們的數據。
讓我們拍攝類似instagram的應用程序的示例。我們將使用JSON定義我們的規則,用于用戶,帖子和查詢。

我們剛上傳了我們的GraphQL架構 - 它會自動創建一個存儲數據和索引來查詢數據的集合。
在幕后,它是如何利用基于您提供的GraphQL模式的關系,圖形和文檔等不同的范例。
我們只是以與文檔數據庫中的相同方式添加我們的數據,并且我們并不遇到數據建模的局限性。
最好的部分 - 這是符合酸性的,非常快。
您無需擔心基礎架構。只需定義您如何需要數據,云將為您處理其余的工作。
缺點
顯然,定價是不利的。偉大的事物不是免費的,但是對于想要學習的開發人員以及小型創業公司,它們確實提供了慷慨的計劃/開源選項。

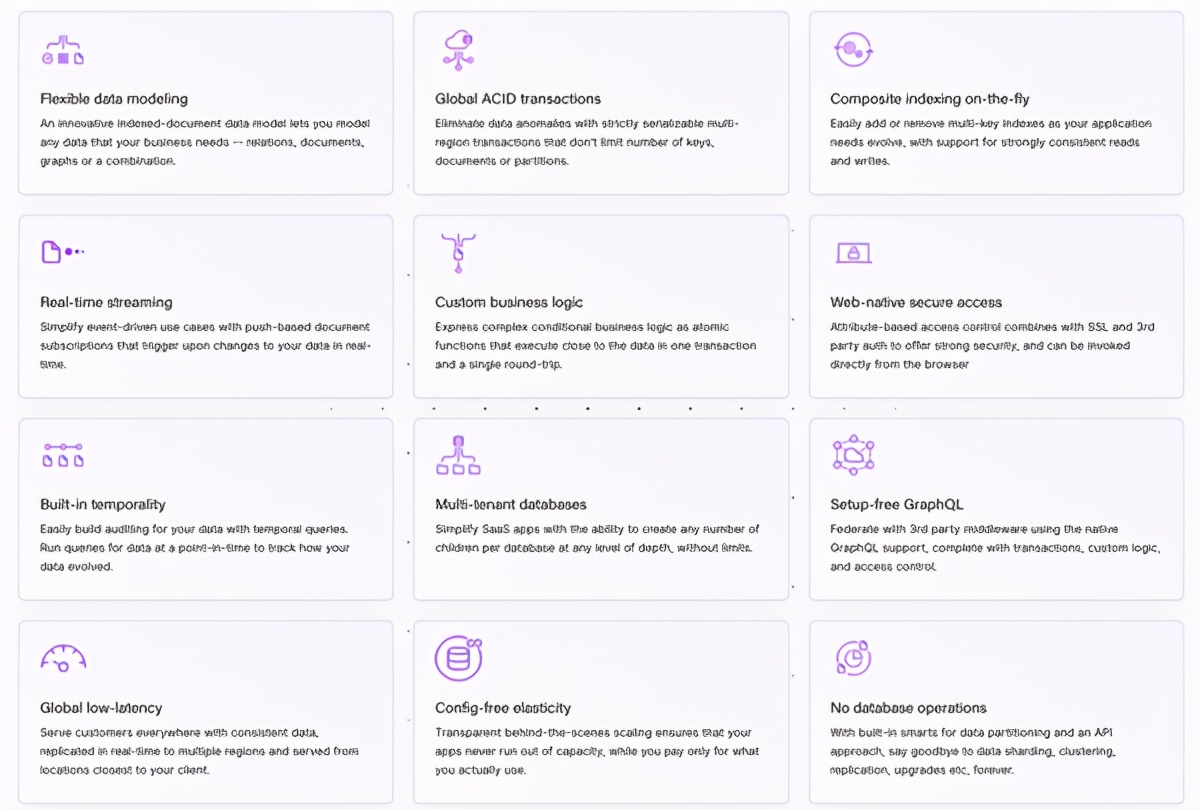
以下是Fauna列出的一些重要功能:
我們還沒有完成!有很多東西可以學習不同的數據庫,但是我希望這是對我們開發人員可以在我們的應用程序中使用的各種選項的很好的介紹。