如何優化前端性能?
隨著前端的范疇逐漸擴大,深度逐漸下沉,富前端必然帶來的一個問題就是性能。特別是在大型復雜項目中,重前端業務可能因為一個小小的數據依賴,導致整個頁面卡頓甚至崩潰。本文基于Quick BI(數據可視化分析平臺)歷年架構變遷中性能的排查、解決和總結出的“個性”問題,嘗試總結整個前端層面相對“共性”的問題,提供一些前端性能解決思路。
一 引發性能問題原因?
引發性能問題的原因通常不是單方面緣由,特別是大型系統迭代多年后,長期積勞成疾造成,所以我們要必要分析找到癥結所在,并按瓶頸優先級逐個擊破,拿我們項目為例,大概分幾個方面:
1 資源包過大
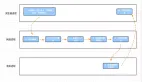
通過Chrome DevTools的Network標簽,我們可以拿到頁面實際拉取的資源大小(如下圖):

經過前端高速發展,近幾年項目更新迭代,前端構建產物也在急劇增大,因為要業務先行,很多同學引入庫和編碼過程并沒有考慮性能問題,導致構建的包增至幾十MB,這樣帶來兩個顯著的問題:
- 弱(普通)網絡下,首屏資源下載耗時長
- 資源解壓解析執行慢
對于第一個問題,基本上會影響所有移動端用戶,并且會耗費大量不必要的用戶帶寬,對客戶是一個經濟上的隱式損失和體驗損失。
對于第二個問題,會影響所有用戶,用戶可能因為等待時間過長而放棄使用。
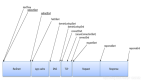
下圖展示了延遲與用戶反應:

2 代碼耗時長
在代碼執行層面,項目迭代中引發的性能問題普遍是因為開發人員編碼質量導致,大概以下幾個緣由:
不必要的數據流監聽
此場景在hooks+redux的場景下會更容易出現,如下代碼:
- const FooComponent = () => {
- const data = useSelector(state => state.fullData);
- return <Bar baz={data.bar.baz} />;
- };
假設fullData是頻繁變更的大對象,雖然FooComponent僅依賴其.bar.baz屬性,fullData每次變更也會導致Foo重新渲染。
雙刃劍cloneDeep
相信很多同學在項目中都有cloneDeep的經歷,或多或少,特別是迭代多年的項目,其中難免有mutable型數據處理邏輯或業務層面依賴,需要用到cloneDeep,但此方法本身存在很大性能陷阱,如下:
- // a.tsx
- export const a = {
- name: 'a',
- };
- // b.tsx
- import { a } = b;
- saveData(_.cloneDeep(a)); // 假設需要克隆后落庫到后端數據庫
上方代碼正常迭代中是沒有問題的,但假設哪天 a 需要擴展一個屬性,保存一個ReactNode的引用,那么執行到b.tsx時,瀏覽器可能直接崩潰!
Hooks之Memo
hooks的發布,給react開發帶來了更高的自由度,同時也帶來了容易忽略的質量問題,由于不再有類中明碼標價的生命周期概念,組件狀態需要開發人員自由控制,所以開發過程中務必懂得react對hooks組件的渲染機制,如下代碼可優化的地方:
- const Foo = () => { // 1. Foo可用React.memo,避免無props變更時渲染
- const result = calc(); // 2. 組件內不可使用直接執行的邏輯,需要用useEffect等封裝
- return <Bar result={result} />; // 3.render處可用React.useMemo,僅對必要的數據依賴作渲染
- };
Immutable Deep Set
在使用數據流的過程中,很大程度我們會依賴lodash/fp的函數來實現immutable變更,但fp.defaultsDeep系列函數有個弊端,其實現邏輯相當于對原對象作深度克隆后執行fp.set,可能帶來一些性能問題,并且導致原對象所有層級屬性都被變更,如下:
- const a = { b: { c: { d: 123 }, c2: { d2: 321 } } };
- const merged = fp.defaultsDeep({ b: { c3: 3 } }, a);
- console.log(merged.b.c === a.b.c); // 打印 false
3 排查路徑
對于這些問題來源,通過Chrome DevTools的Performance火焰圖,我們可以很清晰地了解整個頁面加載和渲染流程各個環節的耗時和卡頓點(如下圖):

當我們鎖定一個耗時較長的環節,就可以再通過矩陣樹圖往下深入(下圖),找到具體耗時較長的函數。
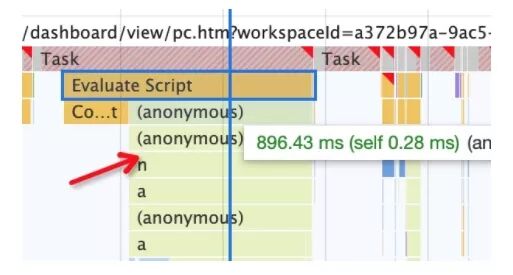
誠然,通常我們不會直接找到某個單點函數占用耗時非常長,而基本是每個N毫秒函數疊加執行成百上千次導致卡頓。所以這塊結合react調試插件的Profile可以很好地幫助定位渲染問題所在:
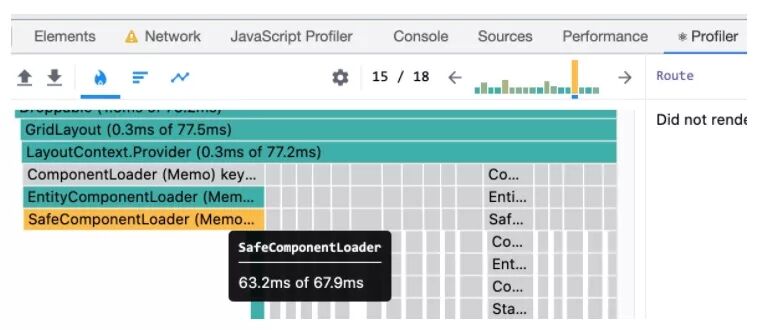
如圖react組件被渲染的次數以及其渲染時長一目了然。
二 如何解決性能問題?
1 資源包分析
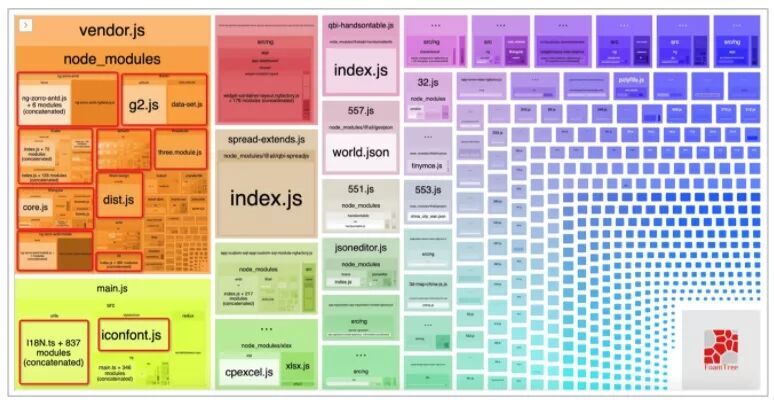
作為一名有性能sense的開發者,有必要對自己構建的產物內容保持敏感,這里我們使用到webpack提供的stats來作產物分析。
首先執行 webpack --profile --json > ./build/stats.json 得到 webpack的包依賴分析數據,接著使用 webpack-bundle-analyzer ./build/stats.json 即可在瀏覽器看到一張構建大圖(不同項目產物不同,下圖僅作舉例):
當然,還有一種直觀的方式,可以采用Chrome的Coverage功能來輔助判定哪些代碼被使用(如下圖):
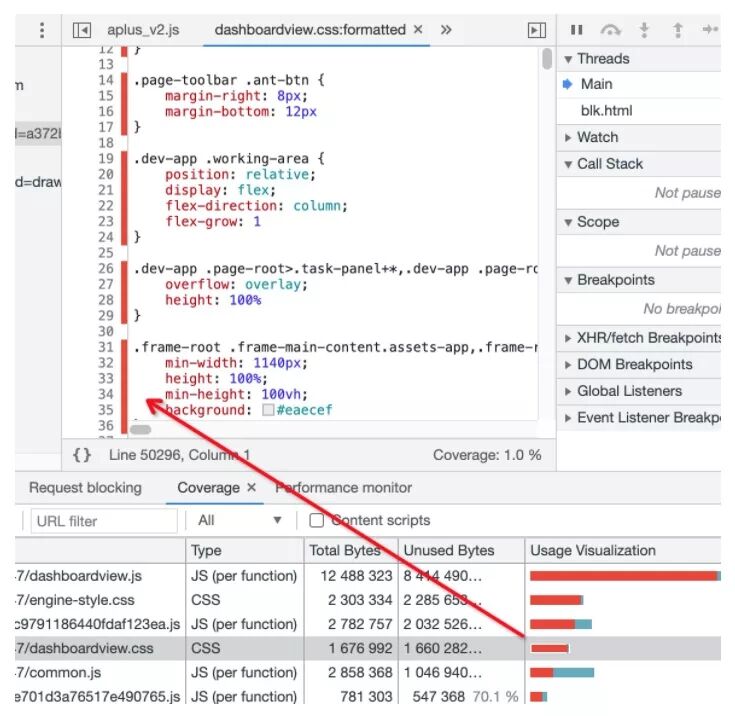
紅色表示未執行過的代碼
最佳構建方式
通常來講,我們組織構建包的基本思路是:
- 按entry入口構建。
- 一個或多個共享包供多entry使用。
而基于復雜業務場景的思路是:
- entry入口輕量化。
- 共享代碼以chunk方式自動生成,并建立依賴關系。
- 大資源包動態導入(異步import)。
webpack 4中提供了新的插件 splitChunks 來解決代碼分離優化的問題,它的默認配置如下:
- module.exports = {
- //...
- optimization: {
- splitChunks: {
- chunks: 'async',
- minSize: 20000,
- minRemainingSize: 0,
- maxSize: 0,
- minChunks: 1,
- maxAsyncRequests: 30,
- maxInitialRequests: 30,
- automaticNameDelimiter: '~',
- enforceSizeThreshold: 50000,
- cacheGroups: {
- defaultVendors: {
- test: /[\\/]node_modules[\\/]/,
- priority: -10
- },
- default: {
- minChunks: 2,
- priority: -20,
- reuseExistingChunk: true
- }
- }
- }
- }
- };
根據上述配置,其分離chunk的依據有以下幾點:
- 模塊被共享或模塊來自于node_modules。
- chunk必須大于20kb。
- 同一時間并行加載的chunk或初始包不得超過30。
理論上webpack默認的代碼分離配置已經是最佳方式,但如果項目復雜或耦合程度較深,仍然需要我們根據實際構建產物大圖情況,調整我們的chunk split配置。
解決TreeShaking失效
“你項目中有60%以上的代碼并沒有被使用到!”
treeshaking的初衷便是解決上面一句話中的問題,將未使用的代碼移除。
webpack默認生產模式下會開啟treeshaking,通過上述的構建配置,理論上應該達到一種效果“沒有被使用到的代碼不應該被打入包中”,而現實是“你認為沒有被使用的代碼,全部被打入Initial包中”,這個問題通常會在復雜項目中出現,其緣由就是代碼副作用(code effects)。由于webpack無法判定某些代碼是否“需要產生副作用”,所以會將此類代碼打入包中(如下圖):
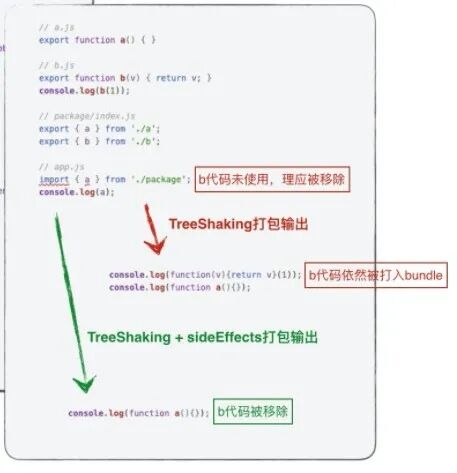
所以,你需要明確知道你的代碼是否有副作用,通過這句話判定:“關于‘副作用’的定義是,在導入時會執行特殊行為的代碼(修改全局對象、立即執行的代碼等),而不是僅僅暴露一個 export 或多個 export。舉例說明,例如 polyfill,它影響全局作用域,并且通常不提供 export。”
對此,解決方法就是告訴webpack我的代碼沒有副作用,沒有被引入的情況下可以直接移除,告知的方式即:
- 在package.json中標記sideEffects為false。
- 或 在webpack配置中 module.rules 添加sideEffects過濾。
模塊規范
由此,要使得構建產物達到最佳效果,我們在編碼過程中約定了以下幾點模塊規范:
- [必須] 模塊務必es6 module化(即export 和 import)。
- [必須] 三方包或數據文件(如地圖數據、demo數據)超過 400KB 必須動態按需加載(異步import)。
- [禁止] 禁止使用export * as方式輸出(可能導致tree-shaking失效并且難以追溯)。
- [推薦] 盡可能引入包中具體文件,避免直接引入整個包(如:import { Toolbar } from '@alife/foo/bar')。
- [必須] 依賴的三方包必須在package.json中標記為sideEffects: false(或在webpack配置中標記)。
2 Mutable數據
基本上通過Performance和React插件提供的調試能力,我們基本可以定位問題所在。但對于mutable型的數據變更,我這里也結合實踐給出一些非標準調試方式:
凍結定位法
眾所周知,數據流思想的產生緣由之一就是避免mutable數據無法追溯的問題(因為你無法知道是哪段代碼改了數據),而很多項目中避免不了mutable數據更改,此方法就是為了解決一個棘手的mutable數據變更問題而想出的方法,這里我暫時命名為“凍結定位法”,因為原理就是使用凍結方式定位mutable變更問題,使用相當tricky:
- constob j= {
- prop: 42
- };
- Object.freeze(obj);
- obj.prop=33; // Throws an error in strict mode
Mutable追溯
此方法也是為了解決mutable變更引發數據不確定性變更問題,用于實現排查的幾個目的:
- 屬性在什么地方被讀取。
- 屬性在什么地方被變更。
- 屬性對應的訪問鏈路是什么。
如下示例,對于一個對象的深度變更或訪問,使用 watchObject 之后,不管在哪里設置其屬性的任何層級,都可以輸出變更相關的信息(stack內容、變更內容等):
- const a = { b: { c: { d: 123 } } };
- watchObject(a);
- const c =a.b.c;
- c.d =0; // Print: Modify: "a.b.c.d"
watchObject 的原理即對一個對象進行深度 Proxy 封裝,從而攔截get/set權限,詳細可參考: https://gist.github.com/wilsoncook/68d0b540a0fea24495d83fc284da9f4b
避免Mutable
通常像react這種技術棧,都會配套使用相應的數據流方案,其與mutable是天然對立的,所以在編碼過程中應該盡可能避免mutable數據,或者將兩者從設計上分離(不同store),否則出現不可預料問題且難以調試
3 計算&渲染
最小化數據依賴
在項目組件爆炸式增長的情況下,數據流store內容層級也逐漸變深,很多組件依賴某個屬性觸發渲染,這個依賴項需要盡可能在設計時遵循最小化原則,避免像上方所述,依賴一個大的屬性導致頻繁渲染。
合理利用緩存
(1)計算結果
在一些必要的cpu密集型計算邏輯中,務必采用 WeakMap 等緩存機制,存儲當前計算終態結果或中間狀態。
(2)組件狀態
對于像hooks型組件,有必要遵循以下兩個原則:
- 盡可能memo耗時邏輯。
- 無多余memo依賴項。
避免cpu密集型函數
某些工具類函數,其復雜度跟隨入參的量級上升,而另外一些本身就會耗費大量cpu時間。針對這類型的工具,要盡量避免使用,若無法避免,也可通過 “控制入參內容(白名單)” 及 “異步線程(webworker等)”方式做到嚴控。
比如針對 _.cloneDeep ,若無法避免,則要控制其入參屬性中不得有引用之類的大型數據。
另外像最上面描述的immutable數據深度merge的問題,也應該盡可能控制入參,或者也可參考使用自研的immutable實現:https://gist.github.com/wilsoncook/fcc830e5fa87afbf876696bf7a7f6bb1
- const a = { b: { c: { d: 123 }, c2: { d2: 321 } } };
- const merged = immutableDefaultsDeep(a, { b: { c3: 3 } });
- console.log(merged === a); // 打印 false
- console.log(merged.b.c === a.b.c); // 打印 true
三 寫在最后
以上,總結了Quick BI性能優化過程中的部分心得和經驗,性能是每個開發者不可繞過的話題,我們的每段代碼,都對標著產品的健康度。