為何放棄數據庫,Hive和Spark,偏偏選擇Flink?
技術選型: 為什么批處理我們卻選擇了 Flink?
最近接手了一個融合日志的服務. 經過梳理, 我認為當前服務的設計上存在缺陷. 與 Leader 開會討論后, 決定重新進行技術方案調研, 最終我們選擇使用 Flink 重構了該服務.
目前重構后的服務已成功經受了國慶節流量洪峰的考驗, 今日特來總結回顧, 和大家分享一下經驗.
業務需求及背景
首先我們要明確, 我們要解決什么問題以及目前的服務是如何解決的.
當前的業務邏輯還是比較清晰的:
- 采集同一時段不同數據源的日志.
- 對采集的數據進行處理.
- 將處理后的數據上傳到指定位置, 供客戶下載.
我們面臨的痛點和難點:
- 日志的量比較大, 每小時未壓縮日志在 50 多個 G 左右; 如果是節假日等特殊時間節點, 日志量一般都會翻倍.
- 目前服務使用單機進行處理, 速度比較慢, 擴容不方便.
- 目前服務處理數據時需要清洗字段, 按時間排序, 統計某字段的頻率等步驟. 這些步驟都屬于 ETL 中的常規操作, 但是目前是以代碼的形式實現的, 我們想以配置形式減少重復編碼, 盡量更加簡單, 通用.
方案1: 我們需要一個數據庫嗎?
針對以上業務需求, 有同學提出: "我們可以把所有原始數據放到數據庫中, 后續的 ETL 可以通過 SQL 實現".
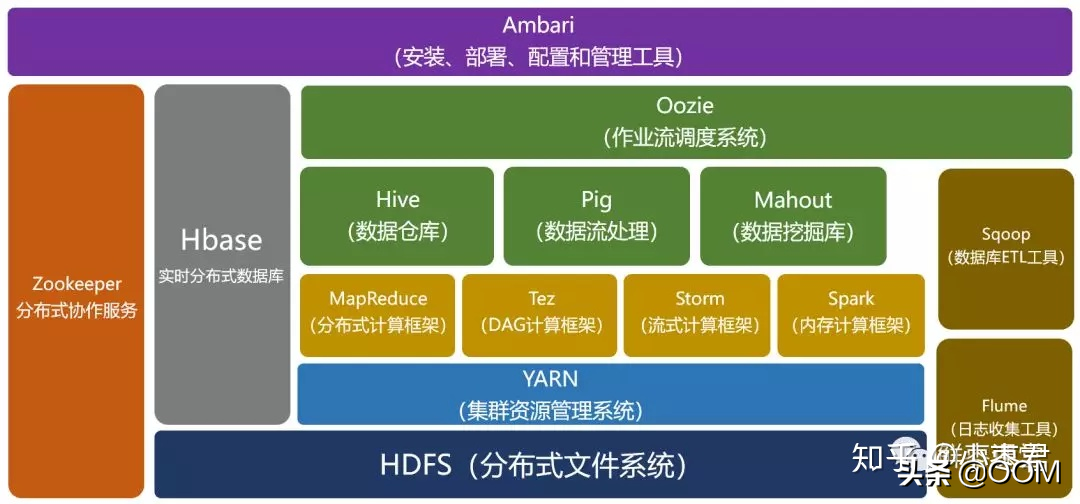
如果你一聽到"數據庫"想到的就是 Pg, Mysql, Oracle 等覺得這個方案不具有可行性, 那你就錯了. 如下圖所示, 數據庫的類型和維度是非常豐富的.
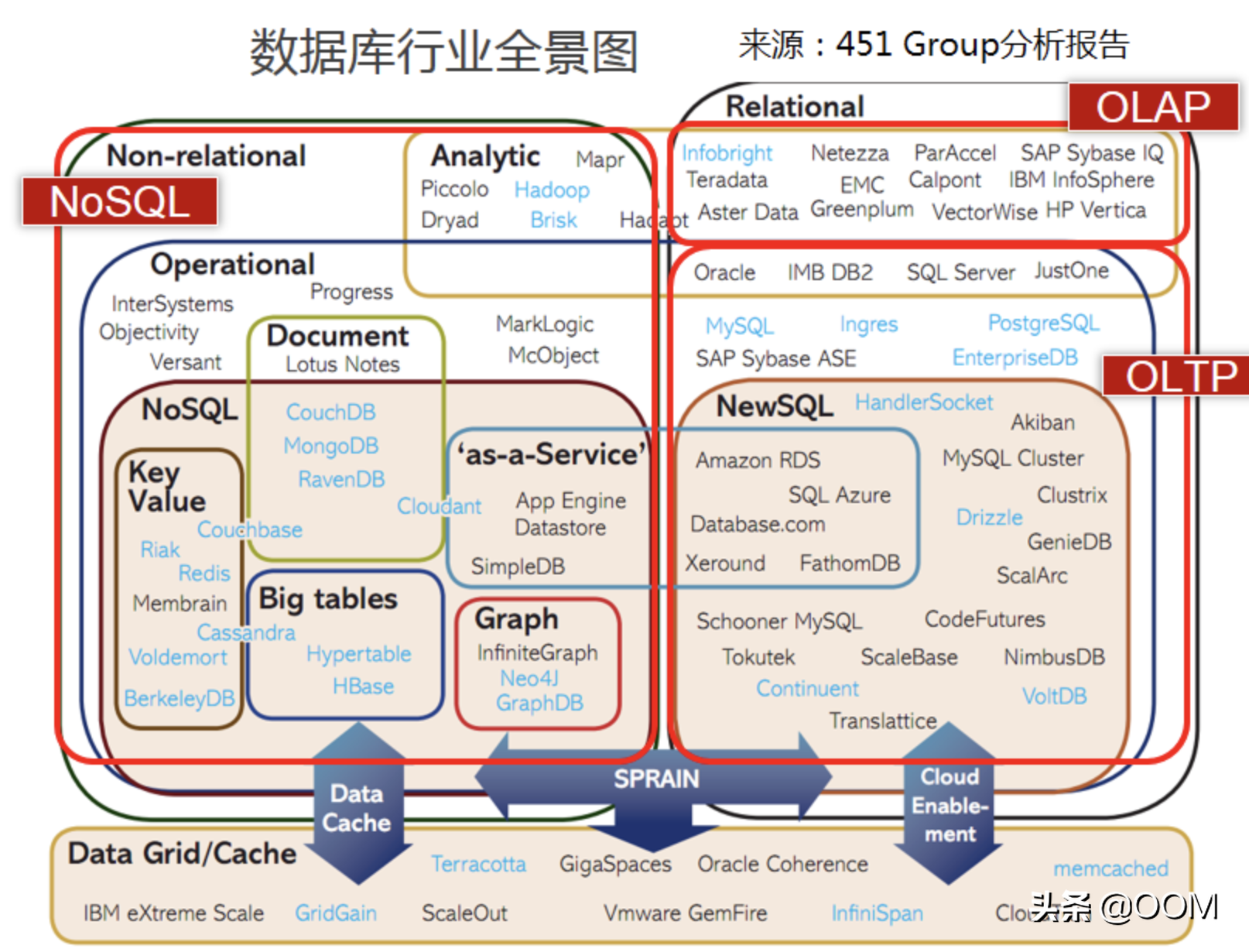
按業務負載特征,關系型數據庫可分為 OLTP 數據庫(交易型)和 OLAP數據庫(分析型) :
- OLTP, Online Transaction Processing. OLTP 數據庫最大的特點是支持事務, 增刪查改等功能強大, 適合需要被頻繁修改的"熱數據". 我們耳熟能詳的 Mysql, Pg 等都屬于這一類. 缺點就是由于支持事務, 插入時比較慢. 拿來實現我們的需求顯示是不合適的.
- OLAP, Online Analytical Processing, 數據分析為主. 不支持事務, 或對事務的支持有限. OLAP 的場景是: 大多數是讀請求, 數據總是以相當大的批(> 1000 rows)進行寫入, 不修改已添加的數據.
方案1小結
OLAP 的使用場景符合我們的需求, 為此我們還專門去調研了一下 ClickHouse. 但是有一個因素讓我們最終放棄了使用 OLAP. 請注意, 數據庫存儲的數據都是二維的, 有行和列兩個維度. 但是日志只有行一個維度. 如果說為了把日志存入數據庫把每行日志都切分, 那我們統計字段的需求也就順手實現了, 又何必存到數據呢?
所以, OLAP 使用場景隱含的一個特點是: 存入的數據需要被多維度反復分析的. 這樣才有把數據存入數據庫的動力, 像我們當前的需求對日志進行簡單的變形后仍舊以文本日志的形式輸出, 使用 OLAP 是不合適的.
方案2: Hive 為什么不行?
看到這, 熟悉大數據的同學可能會覺得我們水平很 Low, 因為業務需求歸根到底就是三個字: "批處理". (提煉一下我們的需求, 其實正是大數據的典型應用場景. 大數據處理流程, 見下圖) 那么我們為什么第一時間沒有考慮上大數據呢?
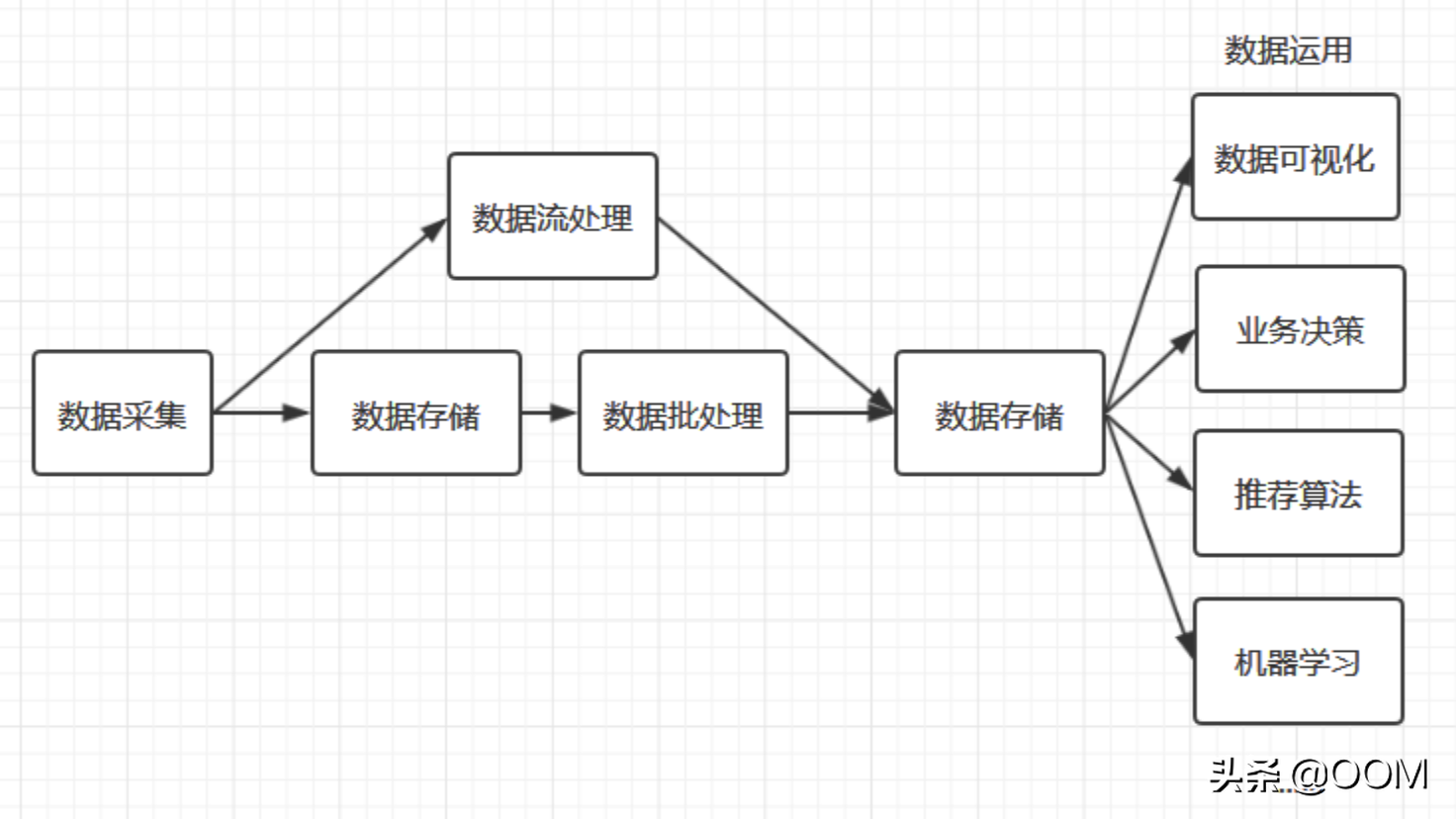
大數據確實如雷貫耳, 但是我們團隊日志處理這塊大部分都是用 Golang 實現的, 團隊內的其他業務用了 Python, Lua, C. 偏偏就是沒有用過到 Java. 而目前大數據都是基于 JVM 開發的. Golang 調用這些服務沒有一個好用的客戶端.
所以基于團隊目前的技術儲備, 大數據才沒有成為我們的首選. 但是目前的狀況, 看來上大數據是最優解了. 那么我們該選用大數據的什么組件實現我們的需求呢?
放棄使用數據庫直接使用 HDFS 存儲日志文件, 應該是毋庸置疑的.
我們需求是離線批處理數據, 對時效性沒有要求, MapReduce 和 Hive 都能滿足需求. 但是 MapReduce 與 Hive 相比, Hive 在 MapReduce 上做了一層封裝并且支持 SQL. 看起來 Hive 是非常合適的.
那我們為什么最終放棄了 Hive 呢?
機器資源審批不下來. 公司其他團隊已經有一套 HDFS 的設施, 只用來做存儲, Hadoop 的 MapReduce 這個組件根本沒跑起來. 那套 HDFS 部署的機器資源比較緊張, 他們擔心我們使用 MapReduce 和 Hive 進行計算, 會影響他們現在 HDFS 的性能; 我們想審批一批新的機器, 重新使用 Ambari 搭建一套 Hadoop, 卻被告知沒那么多閑置的機器資源. 而且我們即便申請下來了機器, 只跑目前服務也跑不滿, 機器資源大部分也會被閑置, 也有浪費資源的嫌疑.
存儲分離是趨勢. 在調研中我們發現, 像 Hadoop 這樣把存儲和計算放到一起的已經比較"落伍"了. Hadoop 存儲分離, 需要修改源碼, 目前沒有開源實現, 只是云廠商和各個大數據公司有相關商業產品. 從這個角度講, 即便我們自己搞定了機器資源搭一套 Hadoop, 也只不過是拾人牙慧罷了.
方案 2 小結
再合適的技術方案不能落地也是空談. 但是技術方案想要落地時, 已經不是一個單純的技術問題了, 資源限制, 團隊限制等都需要考慮在內.
一個優秀的技術方案立足于解決當下的問題, 并且能放眼未來勾畫藍圖("大餅"), 這樣大家覺得 "有利可圖", 才愿意跟你一起折騰.
方案3: 為什么我們放棄了 Spark?
通用的計算引擎
雖然使用 HDFS 的團隊不贊成我們在他們的機器上跑 Hive, 但是我們把日志數據存到他們的 HDFS 上還是沒問題的. 在已知 "存儲和分離是趨勢" 是前提的基礎下, "我們到底需要什么" 這個問題已經有答案了.
我們需要的是一個通用的計算引擎. 存儲已經剝離給 HDFS 了, 所以我們只需要找一個工具, 幫我們處理 ETL 就可以了. Spark 和 Flink 正是這樣的場景.
Spark 與 Flink 初次交鋒
Spark 和 Flink 之間, 我們毫不猶豫地選擇了 Spark. 原因非常簡單:
- Spark 適合批處理. Spark 當初的設計目標就是用來替換 MapReduce. 而 Spark 流處理的能力是后來加上去的. 所以用 Spark 進行批處理, 可謂得心應手.
- Spark 成熟度高. Spark 目前已經發布到 3.0, 而 Flink 尚在 Flink 1.x 階段. Flink 向來以流處理聞名, 雖然被國內某云收購后開始鼓吹 "流批一體", 但是線上效果還是有待檢驗的.
- Scala 的加持. Spark 大部分是用 Scala 實現的. Scala 是一門多范式的編程語言, 并且與 Haskell 有很深的淵源. Haskell 是一門大名鼎鼎的函數式編程語言. 對于函數式編程語言, 想必大多數程序員都有一種 "雖不能至,然心向往之" 的情結. 現在使用 Spark 能捎帶著耍一耍函數式編程語言 Scala, 豈不妙哉?

揮淚斬 Spark
前文已經交代過了, 我們否決掉 Hive 的一個重要因素是我們沒有足夠的機器資源. 所以我們把 Spark 直接部署到云平臺上.
對于我司的云平臺要補充一些細節.
它是基于 K8S 二次開發的, 通常我們使用時都是上傳 Docker 鏡像然后啟動 Docker 實例. 它暫不支持像阿里云 "容器服務 ACK" 這樣的功能. 所以 "Spark on K8S" 的運行模式我們用不了. 在這樣的條件下, 我們采用了 "Spark Standalone" 的模式. Standalone 模式, 也就是Master Slaver 模式, 類似于 Nginx 那樣的架構, Master 節點負責接收分發任務, Slaver 節點負責"干活".
等到我們在云平臺上以 "Spark Standalone" 模式部署好了, 跑了幾個測試 Case 發現問題又來了. 我們的云平臺與辦公網絡是隔離的, 如果辦公網絡想訪問云平臺的某個 Docker 容器, 需要配置域名. 而 Spark 的管理頁面上很多 URL 的 domain 是所在機器的 IP, 而容器的 IP 虛擬 IP, 容器重啟后虛擬 IP 就改變了. 具體如圖:
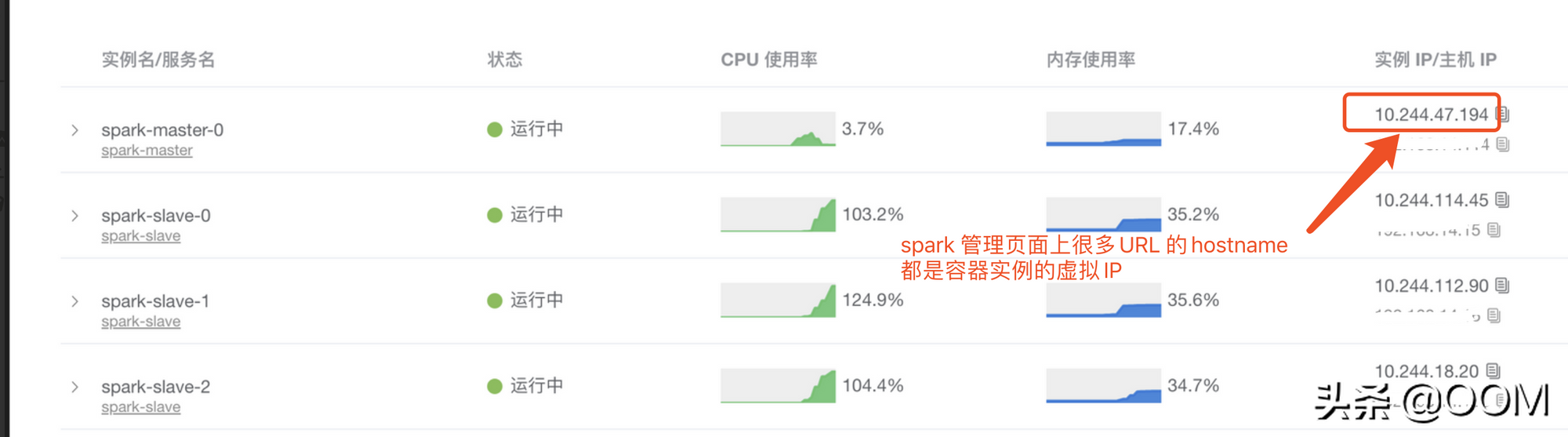
Spark 的管理平臺非常重要, 因為能從這上面看到當前各個節點運行情況, 任務的異常信息等, 現在很多鏈接不能訪問, 不利于我們對 Spark 任務進行問題排查和調優. 基于這個原因, 我們最終放棄了 Spark.
方案 3 小結
Spark 你真的很優秀, 你擅長批處理, 你如此成熟, 你還有函數式的基因 ... 這些優點早讓我傾心不已.
Spark 你真的是個好人, 如果不是云平臺的限制, 我一定選擇你.
Spark, 對不起.
方案4: Flink, 真香!
給 Spark 發完好人卡后, 我們看一看新歡 Flink. 不客氣的說, Flink 初期時很多實現都是抄的 Spark, 所以二者的很多概念相似. 所以 Flink 同樣有 Standard 模式, 我們部署階段沒遇到任何問題.
在跑了幾個 Flink 測試 Case 后, 我們由衷的感嘆 Flink 真香!
放棄 Spark 時我們的痛點在于 "部署在云平臺上的 Spark 服務的管理界面很多功能無法使用", 而 Flink 的管理平臺完全沒有這個問題! 除此之外, Flink 管理平臺的 "顏值" 和功能都是 Spark 無法比擬的.
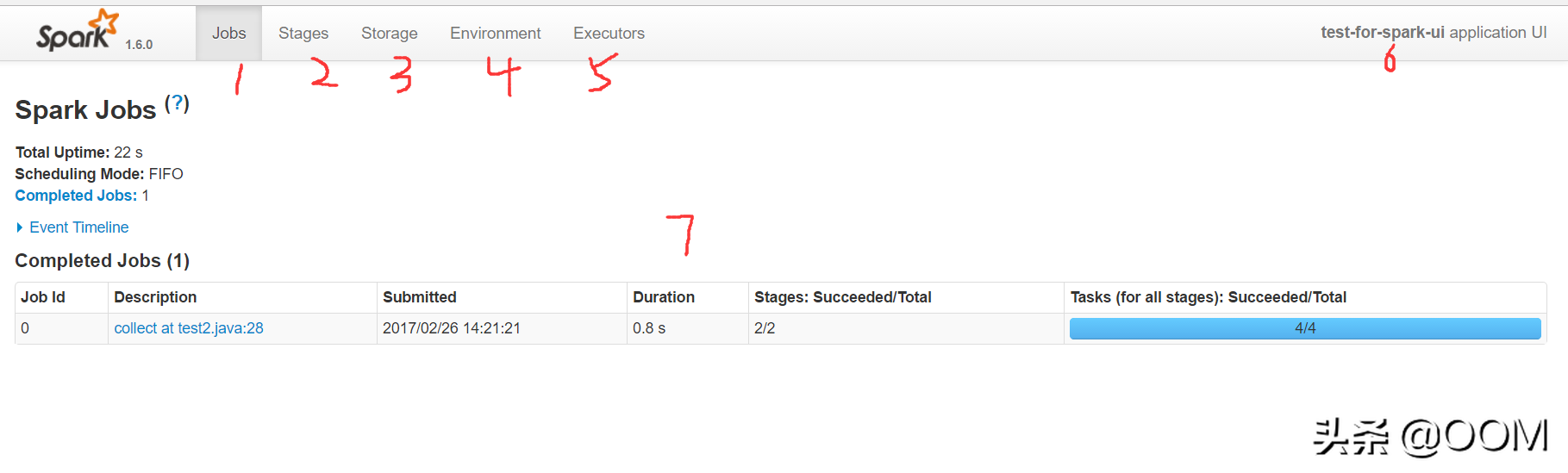
管理平臺顏值對比
Spark管理平臺頁面(網絡圖片):
Flink管理平臺頁面:
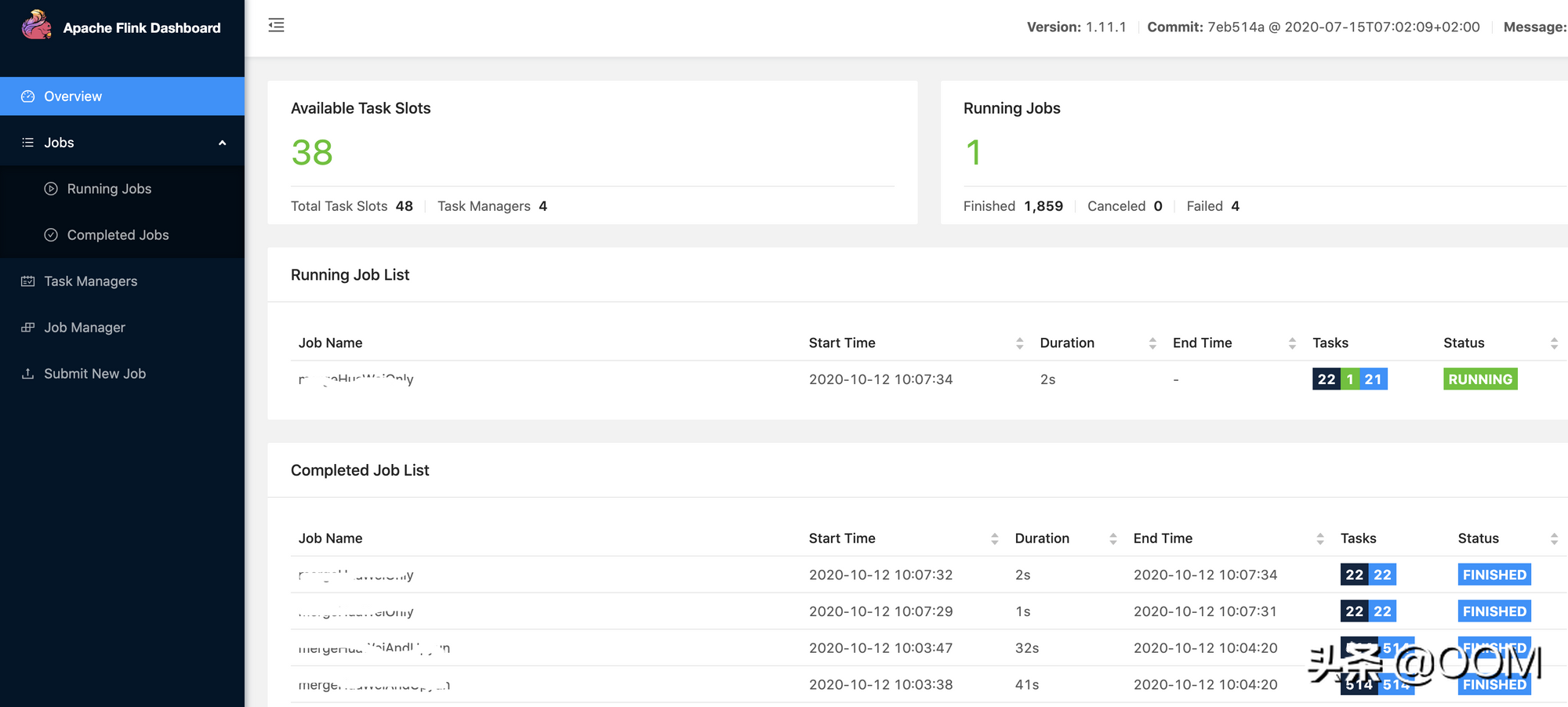
對比之下, Spark 的頁面完全是個"黃臉婆".
Flink 管理平臺功能
由于 Spark 的功能很多不能使用, 所以就不重點和 Flink 做比較了. 這里只說 Flink 幾個讓人眼前一亮的功能.
完善的 Restful API
部署了 Flink 或 Spark 服務后, 該如何下發計算任務呢? 一般是通過 bin 目錄下的一個名稱中包含 submit 的可執行程序. 那如果我們想把 Flink 或 Spark 做成微服務, 通過 http 接口去下發任務呢?
Spark1.0 的時候支持 http, 2.0 的時候這個功能基本上廢掉了很多參數不支持了, 把 http 這個功能交由 jobService 一個第三方開源組件去實現. 這個 jobService 的開源組件對云平臺的支持也非常不友好. 所以在我們看來, Spark 通過 Http 下發任務的路子基本被堵死了.
反觀 Flink, 管理平臺的接口是 Restful 的, 不僅支持 Http 下發計算任務, 還可以通過相關接口查看任務狀態和獲取異常或返回值.
強大的任務分析能力
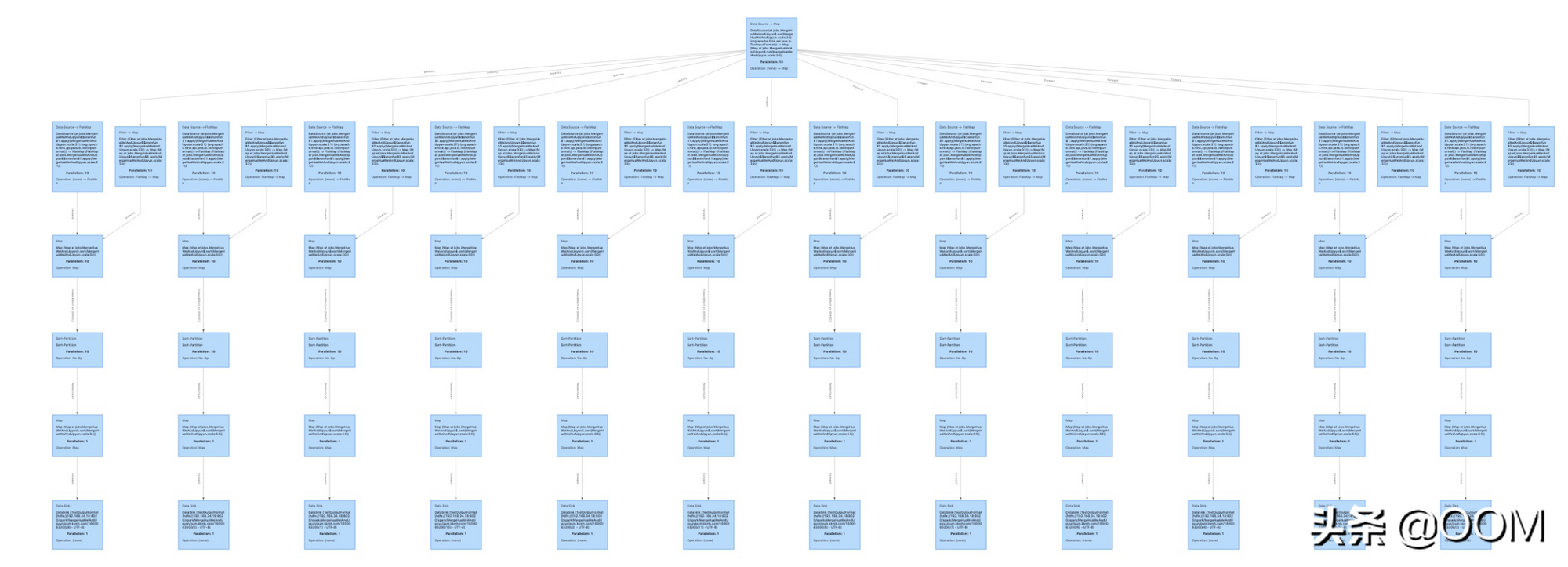
Flink 的任務分為幾個不同的階段, 每個不同的階段有不同的顏色. 這樣僅從顏色就可以判斷出當前 Flink 任務執行的大致情況. 如下圖:
在任務詳情頁面, 會有任務分解圖和任務執行耗時表格, 這兩個結合起來能夠知道當然 Flink 任務是如何分解的, 是否出現數據傾斜的情況, 哪個步驟耗時最多, 是否有優化的空間 ...