













老大問我:“建表為啥還設置個自增 id ?用流水號當主鍵不正好么?”
前言
" 又要開始新項目了,一頓操作猛如虎,梳理流程加畫圖。這不,開始對流程及表結構了。
我:吧啦吧啦吧啦 ……
老大:這個建表為啥還設置個自增 id ?直接用流水號(用戶號/產品號)當主鍵不就行了?
我:這個是 DBA 規定的,創建表 id、create_time、update_time 這三個字段都要有。《Java 開發規范》也是這么規定的。
小伙伴:(附和)是的,規定的是這樣的!
老大:流水號在你這是唯一索引吧?設置成主鍵,這樣就不用 id 了,還減少一次回表查詢?
我:…… (說的好像很有道理,咱也不敢說話。)
老大:既然他們規定了,那你回去查一下為什么要設計個自增 id ?
我:掏出小本本(回去查資料~)。"
1.建表規約

Java 開發手冊-嵩山版
在工作中,創建表的時候,DBA 也會審核一下建表 SQL,檢查是否符合規范以及常用字段是否設置索引。
- CREATE TABLE `xxxx` (
- `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主鍵',
- `create_time` datetime(3) NOT NULL DEFAULT current_timestamp(3) COMMENT '創建時間',
- `update_time` datetime(3) NOT NULL DEFAULT current_timestamp(3) ON UPDATE current_timestamp(3) COMMENT '更新時間',
- PRIMARY KEY (`id`) USING BTREE,
- KEY `idx_create_time` (`create_time`) USING BTREE,
- KEY `idx_update_time` (`update_time`) USING BTREE
- ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COMMENT='表注釋';
所以在我使用的過程中,流水號都是單獨設置了一個字段,比如叫 trans_no,但是這次就遇到了疑問:trans_no 既然是唯一的,那為什么不直接用 trans_no 當做 id 呢?
下面開始通過查閱相關資料,一步一步的了解是為什么?
2.主鍵
什么是主鍵?

MySQL primary key
這段定義咱們主要關注最后一句:
" When choosing primary key values, consider using arbitrary values (a synthetic key) rather than relying on values derived from some other source (a natural key). "
意思是創建主鍵的時候盡量使用 MySQL 自增主鍵而不是使用業務生成的值當做主鍵。
主鍵的特征

簡而言之:
非空、唯一、少更改或不更改 。
如何添加主鍵

可以在 create 創建表的時候指定,也可以使用 alter 語句后面添加主鍵,不過官方建議在創建表時就指定。
為什么要添加主鍵
- 主鍵可以唯一標識這一行數據,從而保證在刪除更新操作時,只是操作這一行數據。
- 索引需要,每個 InnoDB 表又有一個特殊的索引,即聚簇索引,用來存儲行數據。通常,聚簇索引和主鍵同義。
- 聲明主鍵,InnoDB 會將主鍵作為聚簇索引。
- 未聲明時,會在 UNIQUE 所有鍵列所在位置找到第一個索引,NOT NULL 并將其作為聚簇索引
- 未聲明且找不到合適的 UNIQUE 索引,則內部生成一個隱藏的聚簇索引 GEN_CLUST_INDEX,這個隱藏的行 ID 是 6 字節且單調增加。
3.索引
這里僅介紹 InnoDB 引擎,具體可以參考官方文檔,并且介紹的相對比較簡單。
索引的分類
聚簇索引:表存儲是根據主鍵列的值組織的,以加快涉及主鍵列的查詢和排序。在介紹主鍵時也對聚簇索引進行了介紹。
二級索引:也可以叫輔助索引,在輔助索引中會記錄對應的主鍵列以及輔助索引列。根據輔助索引進行搜索的時候,會先根據輔助索引獲取到對應的主鍵列,然后再根據主鍵去聚簇索引里面搜索。一般不建議主鍵很長,因為主鍵很長輔助索引就會使用更多的空間。
" 補充:
回表:先在二級索引查詢到對應的主鍵值,然后根據主鍵再去聚簇索引里面取查詢。
索引覆蓋:二級索引記錄了主鍵列和二級索引列,如果我只查詢主鍵列的值和二級索引列的值,那就不需要回表了。 "
索引的物理結構
InnoDB 使用的 B+ 數數據結構,根據聚簇索引值(主鍵/UNQIUE/或者自己生成)構建一顆 B+ 樹,葉子節點中存放行記錄數據,所以每個葉子節點也可以叫數據頁。每個數據頁大小默認為 16k,支持自定義。
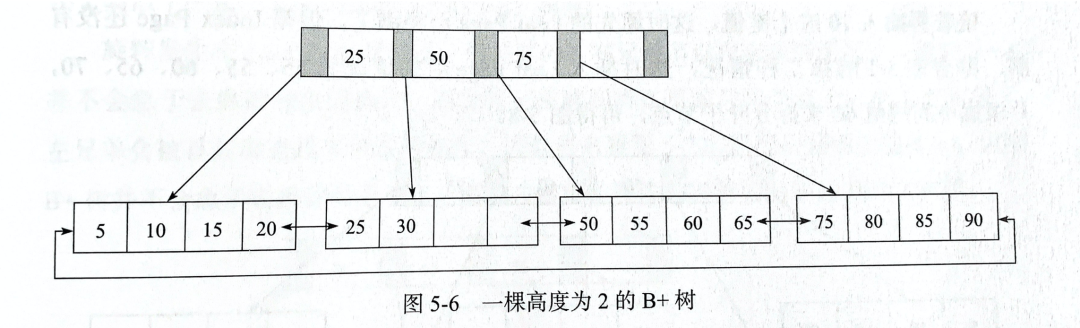
圖:《MySQL 技術內幕 InnoDB 存儲引擎》
數據的插入
當數據插入時,InnoDB 會使頁面 1/16 空閑,以備將來插入和更新索引記錄。
- 順序插入(升序或降序):會將索引頁剩余的大約 15/16 裝滿
- 隨機插入:只會使用容量的 1/2 到 15/16
在隨機插入中,會頻繁的移動、分頁,從而造成大量的碎片,并且使索引樹不夠緊湊。而使用順序插入的方式,則數據比較緊湊,有更高的空間利用率。
4.總結
Q&A
Q: 什么是回表和索引覆蓋?
A:
回表:先在二級索引查詢到對應的主鍵值,然后根據主鍵再去聚簇索引里面取查詢。
索引覆蓋:二級索引記錄了主鍵列和二級索引列,如果我只查詢主鍵列的值和二級索引列的值,那就不需要回表了。
Q: 為什么要設置自增主鍵 id ?
A:
可以唯一標識一行數據,在 InnoDB 構建索引樹的時候會使用主鍵。
自增 id 是順序的,可以保證索引樹上的數據比較緊湊,有更高的空間利用率以及減少數據頁的分裂合并等操作,提高效率。
一般使用手機號、身份證號作為主鍵等并不能保證順序性。
流水號一般相對較長,比如 28 位,32 位等,過長的話會二級索引占用空間較多。同時為了業務需求,流水號具有一定的隨機性。
結束語
本文主要通過查閱資料,了解為什么要設置一個和業務無關的自增 id 用來當做主鍵,很多內容比較淺顯,比如 InnoDB 的 B+ 樹,頁分裂及頁合并,插入過程等都沒有進行深入研究,有興趣的小伙伴可以更深入的研究下。
同時在建表時除了要設置一個自增 id 用來當做主鍵,小伙伴們在業務開發過程中是否也會遇到一種情況:用戶的注銷,數據的刪除等都是進行的邏輯刪除,而不是物理刪除。
本篇文章介紹比較簡陋,不足之處,希望大家多多指正。
相關資料
[1] MySQL 官方文檔:
https://dev.mysql.com/doc/refman/8.0/en/
[2] 《MySQL 技術內幕 InnoDB 存儲引擎》第二版
本文轉載自微信公眾號「劉志航」,可以通過以下二維碼關注。轉載本文請聯系劉志航公眾號。























