Ceph萬(wàn)字總結(jié)|如何改善存儲(chǔ)性能以及提升存儲(chǔ)穩(wěn)定性
本文轉(zhuǎn)載自微信公眾號(hào)「新鈦云服」,作者祝祥 。轉(zhuǎn)載本文請(qǐng)聯(lián)系新鈦云服公眾號(hào)。
「Ceph – 簡(jiǎn)介」
Ceph是一個(gè)即讓人印象深刻又讓人畏懼的開(kāi)源存儲(chǔ)產(chǎn)品。通過(guò)本文,用戶(hù)能確定Ceph是否滿(mǎn)足自身的應(yīng)用需求。在本文中,我們將深入研究Ceph的起源,研究其功能和基礎(chǔ)技術(shù),并討論一些通用的部署方案和優(yōu)化與性能增強(qiáng)方案。同時(shí)本文也提供了一些故障場(chǎng)景以及對(duì)應(yīng)的解決思路。
背景
Ceph是一個(gè)開(kāi)源的分布式存儲(chǔ)解決方案,具有極大的靈活性和適應(yīng)性。Ceph項(xiàng)目最早起源于Sage就讀博士期間的論文(最早的成果于2004年發(fā)表),并隨后貢獻(xiàn)給開(kāi)源社區(qū)。在經(jīng)過(guò)了數(shù)年的發(fā)展之后,目前已得到眾多云計(jì)算廠(chǎng)商的支持并被廣泛應(yīng)用。RedHat及OpenStack都可與Ceph整合以支持虛擬機(jī)鏡像的后端存儲(chǔ)。
Ceph在2014年被RedHat收購(gòu)后,一直由RedHat負(fù)責(zé)維護(hù)。Ceph的命名和UCSC(Ceph 的誕生地)的吉祥物有關(guān),這個(gè)吉祥物是 “Sammy”,一個(gè)香蕉色的蛞蝓,就是頭足類(lèi)中無(wú)殼的軟體動(dòng)物。這些有多觸角的頭足類(lèi)動(dòng)物,是對(duì)一個(gè)分布式文件系統(tǒng)高度并行的形象比喻。自從2012年7月3日發(fā)布第一個(gè)版本的Argonaut以來(lái),隨著新技術(shù)的整合,Ceph經(jīng)歷了幾次開(kāi)發(fā)迭代。借助適用于Openstack和Proxmox的虛擬化平臺(tái),Ceph可支持直接將iSCSI存儲(chǔ)呈現(xiàn)給虛擬化平臺(tái)。同時(shí)Ceph也擁有功能強(qiáng)大的API。在世界上的各大公司都能發(fā)現(xiàn)Ceph的身影——提供塊存儲(chǔ),文件存儲(chǔ),對(duì)象存儲(chǔ)。
由于Ceph是目前唯一提供以下所有功能的存儲(chǔ)解決方案,因此Ceph越來(lái)越受歡迎,并吸引了許多大型企業(yè)的極大興趣:
- 「軟件定義」:軟件定義存儲(chǔ) (SDS) 是一種能將存儲(chǔ)軟件與硬件分隔開(kāi)的存儲(chǔ)架構(gòu)。不同于傳統(tǒng)的網(wǎng)絡(luò)附加存儲(chǔ) (NAS) 或存儲(chǔ)區(qū)域網(wǎng)絡(luò) (SAN) 系統(tǒng),SDS 一般都在行業(yè)標(biāo)準(zhǔn)系統(tǒng)或 x86 系統(tǒng)上運(yùn)行,從而消除了軟件對(duì)于專(zhuān)有硬件的依賴(lài)性。借助Ceph,還可以為諸如糾錯(cuò)碼,副本,精簡(jiǎn)配置,快照和備份之類(lèi)的功能提供策略管理。
- 「企業(yè)級(jí)」 :Ceph旨在滿(mǎn)足大型組織在可用性,兼容性,可靠性,可伸縮性,性能和安全性等方面的需求。它同時(shí)支持按比例伸縮,從而使其具有很高的靈活性,并且其可擴(kuò)展性潛力幾乎無(wú)限。
- 「統(tǒng)一存儲(chǔ)」:Ceph提供了塊+對(duì)象+文件存儲(chǔ),從而提供了更大的靈活性(大多數(shù)其他存儲(chǔ)產(chǎn)品都是僅塊,僅文件,僅對(duì)象或文件+塊;ceph提供的三種混合存儲(chǔ)是非常罕見(jiàn))。
- 「開(kāi)源」:開(kāi)源實(shí)現(xiàn)技術(shù)的敏捷性,通常提供多種解決問(wèn)題的方法。開(kāi)源通常也更具成本效益,并且可以更輕松地使組織開(kāi)始規(guī)模更小,規(guī)模更大。開(kāi)源解決方案背后的許多意識(shí)形態(tài)孕育了一個(gè)相互協(xié)作且參與度高的專(zhuān)業(yè)社區(qū),這些社區(qū)反應(yīng)靈敏且相互支持。更不用說(shuō)開(kāi)源是未來(lái)的方向。Web,移動(dòng)和云解決方案越來(lái)越多地建立在開(kāi)源基礎(chǔ)架構(gòu)上。
「為什么選擇Ceph?」
「Ceph 分布式核心組件」
集群文件系統(tǒng)最初始于1990年代末和2000年代初。Lustre是最早利用可伸縮文件系統(tǒng)實(shí)現(xiàn)產(chǎn)品化的產(chǎn)品之一。多年來(lái),出現(xiàn)了其他一些Lustre衍生產(chǎn)品,包括GlusterFS,GPFS,XtreemFS和OrangeFS等。這些文件系統(tǒng)都集中于為文件系統(tǒng)實(shí)現(xiàn)符合POSIX的掛載,并且缺乏通用的集成API。
Ceph的架構(gòu)并不需要考慮到需要與POSIX兼容的文件系統(tǒng)——這完全得益于云的時(shí)代。利用RADOS,Ceph可以擴(kuò)展不受元數(shù)據(jù)約束限制的塊設(shè)備。這極大地提高了存儲(chǔ)性能,但是卻使那些尋求基于Ceph的大型文件系統(tǒng)掛載方法的人們望而卻步。直到Ceph Jewel(10.2.0)版本發(fā)布為止,CephFS已經(jīng)是穩(wěn)定且可靠的文件系統(tǒng)——允許部署POSIX掛載的文件系統(tǒng)。
Ceph支持塊,對(duì)象和文件存儲(chǔ),并且具有橫向擴(kuò)展能力,這意味著多個(gè)Ceph存儲(chǔ)節(jié)點(diǎn)(服務(wù)器)共同提供了一個(gè)可快速處理上PB數(shù)據(jù)(1PB = 1,000 TB = 1,000,000 GB)的存儲(chǔ)系統(tǒng)。利用作為基礎(chǔ)的硬件組件,它還可以同時(shí)提高性能和容量。
Ceph具有許多基本的企業(yè)存儲(chǔ)功能,包括副本,糾錯(cuò)碼,快照,自動(dòng)精簡(jiǎn)配置,分層(在閃存和普通硬盤(pán)之間緩存數(shù)據(jù)的能力——即緩存)以及自我修復(fù)功能。為了做到這一點(diǎn),Ceph利用了下面將要探討的幾個(gè)組件。
從Ceph Nautilus(v14.2.0)開(kāi)始,現(xiàn)在有五個(gè)主要的守護(hù)程序或服務(wù),它們集成在一起以提供Ceph服務(wù)的正常運(yùn)行。這些是:
- 「ceph-mon」:Monitor確實(shí)提供了其名稱(chēng)所暗示的功能——監(jiān)視群集的運(yùn)行狀況。該監(jiān)視器還告訴OSD在replication期間將數(shù)據(jù)放置在何處,并保留主CRUSH Map。
- 「ceph-osd」:OSD是Ceph的基礎(chǔ)數(shù)據(jù)存儲(chǔ)單元,它利用XFS文件系統(tǒng)和物理磁盤(pán)來(lái)存儲(chǔ)從客戶(hù)端提供給它的塊數(shù)據(jù)。
- 「ceph-mds」:MDS守護(hù)程序提供了將Ceph塊數(shù)據(jù)轉(zhuǎn)換為存儲(chǔ)文件的POSIX兼容掛載點(diǎn)的功能,就像您使用傳統(tǒng)文件系統(tǒng)一樣。
- 「ceph-mgr」:MGR守護(hù)程序顯示有關(guān)群集狀態(tài)的監(jiān)視和管理信息。
- 「ceph-rgw」:RGW守護(hù)程序是一個(gè)HTTP API守護(hù)程序,對(duì)象存儲(chǔ)網(wǎng)關(guān)實(shí)際上是調(diào)用librados的API來(lái)實(shí)現(xiàn)數(shù)據(jù)的存儲(chǔ)和讀取。而該網(wǎng)關(guān)同時(shí)提供了兼容AWS S3和OpenStack Swift的對(duì)象存儲(chǔ)訪(fǎng)問(wèn)接口(API)。
從術(shù)語(yǔ)的角度來(lái)看,Ceph需要了解一些重要的知識(shí)。
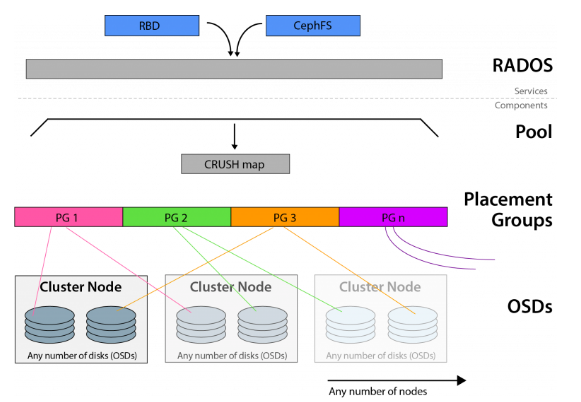
Ceph基于CRUSH算法構(gòu)建, 并支持多種訪(fǎng)問(wèn)方法(文件,塊,對(duì)象)。CRUSH算法確定對(duì)象在OSD上的位置,并且可以將這些相同的塊拉出以進(jìn)行訪(fǎng)問(wèn)請(qǐng)求。
Ceph利用了可靠,自治,分布式的對(duì)象存儲(chǔ)(或RADOS),該對(duì)象存儲(chǔ)由自我修復(fù),自我管理的存儲(chǔ)節(jié)點(diǎn)組成。前面討論的OSD守護(hù)程序是RADOS群集的一部分。
放置組(PG)的全稱(chēng)是placement group,是用于放置object的一個(gè)載體,所以群集中PG的數(shù)量決定了它的大小。pg的創(chuàng)建是在創(chuàng)建ceph存儲(chǔ)池的時(shí)候指定的,同時(shí)跟指定的副本數(shù)也有關(guān)系,比如是3副本的則會(huì)有3個(gè)相同的pg存在于3個(gè)不同的osd上,pg其實(shí)在osd的存在形式就是一個(gè)目錄。PG可以由管理員設(shè)置,新版本中也可以根據(jù)集群使用情況自動(dòng)縮放。
RBD即RADOS Block Device的簡(jiǎn)稱(chēng),RBD塊存儲(chǔ)是最穩(wěn)定且最常用的存儲(chǔ)類(lèi)型。RBD塊設(shè)備類(lèi)似磁盤(pán)可以被掛載。RBD塊設(shè)備具有快照、多副本、克隆和一致性等特性,數(shù)據(jù)以條帶化的方式存儲(chǔ)在Ceph集群的多個(gè)OSD中。可以在Ceph中用于創(chuàng)建用于虛擬化的鏡像塊設(shè)備,例如KVM和Xen。通過(guò)利用與RADOS兼容的API librados,VM的訪(fǎng)問(wèn)不是通過(guò)iSCSI或NFS,而是通過(guò)存儲(chǔ)API來(lái)實(shí)現(xiàn)的。
使用場(chǎng)景
正如我們已經(jīng)描述的那樣,Ceph是一個(gè)非常靈活和一致的存儲(chǔ)解決方案。對(duì)Ceph存儲(chǔ)對(duì)象的訪(fǎng)問(wèn)可以通過(guò)多種方式來(lái)完成,因此Ceph具有其他類(lèi)似產(chǎn)品所缺乏的大量生產(chǎn)用例。
可以將Ceph部署為S3/Swift對(duì)象存儲(chǔ)的替代品。通過(guò)它的RADOS網(wǎng)關(guān),可以使用http GET請(qǐng)求以及大量可用的Amazon S3 API工具箱訪(fǎng)問(wèn)存儲(chǔ)在Ceph中的對(duì)象。
也可以通過(guò)librados API或iSCSI/NFS在包括VMWare和其他專(zhuān)有虛擬化平臺(tái)在內(nèi)的虛擬化環(huán)境中直接使用Ceph。
可以部署CephFS為需要訪(fǎng)問(wèn)大型文件系統(tǒng)的操作系統(tǒng)提供POSIX兼容的掛載點(diǎn)。
根據(jù)以上的這些場(chǎng)景,我們可以利用單個(gè)存儲(chǔ)平臺(tái)來(lái)滿(mǎn)足各種計(jì)算和存儲(chǔ)需求。
「潛在的部署方案」
常用的Ceph部署工具主要有:ceph-deploy,ceph-ansible,基于kubernetns的Rook以及新版本基于容器的kubeadm等。當(dāng)然工具不僅僅是這些。每一種部署方案都有大量的生產(chǎn)實(shí)踐。以下簡(jiǎn)單介紹以下這幾種常用的部署方式:
「Ceph-deply」:該工具可用于簡(jiǎn)單、快速地部署 Ceph 集群,而無(wú)需涉及繁雜的手動(dòng)配置。它在管理節(jié)點(diǎn)上通過(guò) ssh 獲取其它 Ceph 節(jié)點(diǎn)的訪(fǎng)問(wèn)權(quán)、通過(guò) sudo 獲取其上的管理權(quán)限、通過(guò)底層 Python 腳本自動(dòng)化各節(jié)點(diǎn)上的 Ceph 安裝進(jìn)程。它簡(jiǎn)單到可以運(yùn)行在工作站上,不需要服務(wù)器、數(shù)據(jù)庫(kù)或任何其它的自動(dòng)化工具。使用ceph-deploy安裝和拆除集群非常簡(jiǎn)單。然而它不是通用部署工具,是專(zhuān)為想快速安裝、運(yùn)行 Ceph 的人們?cè)O(shè)計(jì)的專(zhuān)用工具,這樣的集群只包含必要的的初始配置選項(xiàng),就沒(méi)必要安裝像 Chef 、 Puppet 或 Juju 這樣的部署工具。
「Ceph-ansible」:用于部署Ceph分布式系統(tǒng)的ansible playbook,ceph-ansible是安裝和管理完整ceph集群的最靈活的方法,當(dāng)前大量的生產(chǎn)環(huán)境都會(huì)使用該安裝方式。
「Rook」:Rook 是一個(gè)編排器,能夠支持包括 Ceph 在內(nèi)的多種存儲(chǔ)方案。Rook 簡(jiǎn)化了 Ceph 在 Kubernetes 集群中的部署過(guò)程。Rook 是一個(gè)可以提供 Ceph 集群管理能力的 Operator。Rook 使用 CRD 一個(gè)控制器來(lái)對(duì) Ceph 之類(lèi)的資源進(jìn)行部署和管理。
「Cephadm」:較新的集群自動(dòng)化部署工具,支持通過(guò)圖形界面或者命令行界面添加節(jié)點(diǎn),目前不建議用于生產(chǎn)環(huán)境。cephadm的目標(biāo)是提供一個(gè)功能齊全、健壯且維護(hù)良好的安裝和管理層,可供不在Kubernetes中運(yùn)行Ceph的任何環(huán)境使用。Cephadm通過(guò)SSH從manager守護(hù)進(jìn)程連接到主機(jī)來(lái)部署和管理Ceph集群,以添加、刪除或更新Ceph守護(hù)進(jìn)程容器。它不依賴(lài)于外部配置或編排工具,如Ansible、Rook或Salt。
「結(jié)論」
Ceph的性能與功能不斷得到提升,存儲(chǔ)特性也不斷豐富,甚至可以與傳統(tǒng)專(zhuān)業(yè)存儲(chǔ)媲美,完備的存儲(chǔ)服務(wù)和低廉的投資成本,使得越來(lái)越多的企業(yè)和單位選用Ceph提供存儲(chǔ)服務(wù)。大量的生產(chǎn)最佳實(shí)踐也使得Ceph成為標(biāo)準(zhǔn)SDS的最優(yōu)解決方案之一。
Cephadm管理Ceph集群的整個(gè)生命周期,是官方以后力推的部署以及管理Ceph的解決方案。它首先在單個(gè)節(jié)點(diǎn)(一個(gè)監(jiān)視器和一個(gè)管理器)上引導(dǎo)一個(gè)很小的Ceph集群,然后使用編排接口擴(kuò)展集群以包括所有主機(jī)并提供所有Ceph守護(hù)進(jìn)程和服務(wù)。這可以通過(guò)Ceph命令行界面(CLI)或儀表板(GUI)來(lái)執(zhí)行。
Cephadm是Octopus發(fā)行版中的一個(gè)新功能,在生產(chǎn)中的使用有限。社區(qū)希望用戶(hù)嘗試cephadm,特別是對(duì)于新的集群,但請(qǐng)注意,有些功能仍然很粗糙。當(dāng)前社區(qū)持續(xù)在改進(jìn)以及相應(yīng)BUG修復(fù)中。
5種最常見(jiàn)的CEPH失敗方案
Ceph是一種廣泛使用的存儲(chǔ)解決方案,可在整個(gè)分布式集群中實(shí)現(xiàn)對(duì)象級(jí),塊級(jí)和文件級(jí)存儲(chǔ)。Ceph是創(chuàng)建不圍繞單個(gè)故障點(diǎn)進(jìn)行擴(kuò)展的高效存儲(chǔ)系統(tǒng)的理想選擇。但是,如果管理不當(dāng),Ceph可能很容易成為失敗場(chǎng)景的雷區(qū),這可能是一件難以完全避免的事情。本處,我們將探討最常見(jiàn)的五種Ceph失敗方案。
「Monitor數(shù)目不正確」
在最新版本的Ceph中,至少需要三臺(tái)運(yùn)行Ceph Mon守護(hù)程序的服務(wù)器。這些可以是物理服務(wù)器(理想情況下)或者也可以是虛擬機(jī)。但是,如果您超出了Mon服務(wù)器的最小數(shù)量,則在Ceph構(gòu)建中始終保持運(yùn)行奇數(shù)個(gè)守護(hù)程序非常重要。這個(gè)奇數(shù)很重要,因?yàn)樗试S系統(tǒng)正確地建立一個(gè)主機(jī)來(lái)控制CRUSH Map。在確定主服務(wù)器時(shí),每臺(tái)服務(wù)器都會(huì)“投票”認(rèn)為最適合維護(hù)crush map的服務(wù)器。維護(hù)奇數(shù)個(gè)Ceph守護(hù)程序可確保永遠(yuǎn)不會(huì)出現(xiàn)投票平局的現(xiàn)象,并且始終會(huì)建立一個(gè)主服務(wù)器。如果沒(méi)有維護(hù)奇數(shù)個(gè)守護(hù)程序,則可能會(huì)導(dǎo)致不穩(wěn)定,并最終導(dǎo)致Ceph崩潰。
「OSD數(shù)目不正確」
根據(jù)在Ceph集群中所設(shè)置的副本數(shù),您將需要足夠數(shù)量的硬盤(pán)(OSD——對(duì)象存儲(chǔ)設(shè)備)。當(dāng)您計(jì)劃購(gòu)買(mǎi)或升級(jí)當(dāng)前Ceph中的OSD前,最重要的是要根據(jù)當(dāng)前狀況進(jìn)行數(shù)據(jù)量預(yù)測(cè),以匹配未來(lái)生產(chǎn)的數(shù)據(jù)量。通常,最好至少提前6到12個(gè)月進(jìn)行估算,并將此存儲(chǔ)量乘以所需的對(duì)象冗余量(即32TB數(shù)據(jù)* 3(副本數(shù))= 96TB所需的存儲(chǔ)空間)。通過(guò)適當(dāng)?shù)念A(yù)測(cè),您可以避免OSD過(guò)載,并保持CEPH環(huán)境正常運(yùn)行。
「RADOS網(wǎng)關(guān)冗余不足」
RADOS (「Reliable, Autonomic Distributed Object Store」) 是Ceph的核心之一,作為Ceph分布式文件系統(tǒng)的一個(gè)子項(xiàng)目,特別為Ceph的需求設(shè)計(jì),能夠在動(dòng)態(tài)變化和異質(zhì)結(jié)構(gòu)的存儲(chǔ)設(shè)備集群之上提供一種穩(wěn)定、可擴(kuò)展、高性能的單一邏輯對(duì)象(Object)存儲(chǔ)接口和能夠?qū)崿F(xiàn)節(jié)點(diǎn)的自適應(yīng)和自管理的存儲(chǔ)系統(tǒng)。RADOS構(gòu)成了Ceph集群的核心,并且與Ceph CRUSH Map結(jié)合使用時(shí),可以使您在服務(wù)器的集群中保持?jǐn)?shù)據(jù)一致且可安全的進(jìn)行數(shù)據(jù)同步與復(fù)制。可以以多種不同方式訪(fǎng)問(wèn)Ceph數(shù)據(jù)。其中之一是通過(guò)稱(chēng)為RADOS網(wǎng)關(guān)的HTTP API前端進(jìn)行的。RADOS網(wǎng)關(guān)公開(kāi)了一個(gè)存儲(chǔ)API,供外部人員調(diào)用。
如果通過(guò)RADOS網(wǎng)關(guān)訪(fǎng)問(wèn)您的Ceph集群,那么促進(jìn)API訪(fǎng)問(wèn)的前端服務(wù)器必須冗余且能夠負(fù)載均衡,這一點(diǎn)非常重要。在理想的配置中,多個(gè)RADOS服務(wù)器將可用于接受請(qǐng)求,并且所有請(qǐng)求都應(yīng)由一個(gè)冗余的負(fù)載均衡器進(jìn)行管理。如果未進(jìn)行正確配置,則非冗余RADOS網(wǎng)關(guān)服務(wù)器的故障將導(dǎo)致您完全失去對(duì)CEPH群集的API訪(fǎng)問(wèn)權(quán)限。您可以使用混合的解決方案,該混合解決方案會(huì)利用本地RADOS網(wǎng)關(guān),當(dāng)發(fā)生故障時(shí)則會(huì)回退到基于云的冗余網(wǎng)關(guān)上。這可以最大程度地減少額外的不必要轉(zhuǎn)換,同時(shí)保持對(duì)存儲(chǔ)解決方案的冗余和可靠訪(fǎng)問(wèn)。
「硬件配置不足」
為CEPH集群維護(hù)硬件時(shí),最重要的是要確保硬件配置滿(mǎn)足實(shí)際需求,具體需要考慮的如下:
- 「電源」:確保主機(jī)的電源模塊至少是雙路冗余。還要確保每臺(tái)CEPH服務(wù)器都有一個(gè)備用電源,該備用電源的功率足以完全滿(mǎn)足服務(wù)器的需求。沒(méi)有適當(dāng)?shù)娜哂啵鷮⒚媾R不可挽回的數(shù)據(jù)丟失的風(fēng)險(xiǎn)。
- 「CPU」:最佳實(shí)踐要求在所有CEPH服務(wù)器上使用相同型號(hào)相同配置的CPU。這有助于在整個(gè)ceph集群中保持一致性以及穩(wěn)定性。
- 「內(nèi)存」:與CPU相似,您使用的內(nèi)存應(yīng)在CEPH服務(wù)器之間平均分配。理想情況下,存儲(chǔ)服務(wù)器的品牌和規(guī)格應(yīng)該相同。此外,在發(fā)生硬件故障時(shí),還應(yīng)具有大量可用的冗余內(nèi)存(備件)。
- 「硬盤(pán)」:建議將SAS磁盤(pán)用于OSD。如果有可能的話(huà),使用故障率低于SAS盤(pán)的NVMe磁盤(pán)則會(huì)更為理想。
- 「其他」:如果有可能的話(huà),可以提供一些冷備機(jī)器。當(dāng)存儲(chǔ)節(jié)點(diǎn)存現(xiàn)故障的時(shí)候,極端情況下可以直接進(jìn)行備機(jī)更換(保留物理磁盤(pán))。
「CEPH專(zhuān)業(yè)知識(shí)」
通常,CEPH失敗的原因是由于缺乏CEPH相關(guān)的專(zhuān)業(yè)知識(shí)。例如,所有CEPH群集中OSD節(jié)點(diǎn)都將利用硬盤(pán)直通模式來(lái)確保性能和可靠性。但是,如果改用RAID的話(huà),則不僅是不推薦的,而且還會(huì)因?yàn)榇疟P(pán)陣列故障而導(dǎo)致出現(xiàn)單點(diǎn)故障,最終可能引起大量數(shù)據(jù)丟失。這種錯(cuò)誤很簡(jiǎn)單,但從長(zhǎng)遠(yuǎn)來(lái)看,這樣的錯(cuò)誤代價(jià)高昂,并且可能需要更高級(jí)的ceph專(zhuān)家去解決相應(yīng)的問(wèn)題。
Ceph常規(guī)排障
如果Ceph集群崩潰該怎么辦
由于Ceph在軟件層就內(nèi)置了所有可用的冗余和故障保護(hù)功能,因此簡(jiǎn)單的故障不太可能造成災(zāi)難性的后果,并且一般的故障相對(duì)都是比較容易恢復(fù)的。但問(wèn)題是,當(dāng)遇到一系列意外事件導(dǎo)致集群停止響應(yīng)存儲(chǔ)請(qǐng)求或使所有VM虛擬機(jī)脫機(jī)時(shí),那又該怎么辦?
「保持冷靜」
Ceph非常強(qiáng)大,其Crush算法可確保數(shù)據(jù)的完整性和可用性。記住這一關(guān)鍵事實(shí)將有助于您確定中斷的原因。
最常見(jiàn)的災(zāi)難性故障場(chǎng)景之一是群集丟失的OSD超過(guò)維護(hù)所需的冗余級(jí)別所需的OSD。在這種情況下,快速識(shí)別并更換有問(wèn)題的OSD將使您的群集恢復(fù)工作狀態(tài)。同時(shí)也讓我們確定其他潛在故障觸發(fā)因素。
「記錄和狀態(tài)」
Ceph在mon(monitor)節(jié)點(diǎn)和osd(object storage daemon)節(jié)點(diǎn)上提供了多個(gè)日志和狀態(tài)查看命令,您應(yīng)該首先利用Ceph相關(guān)命令行來(lái)查看群集的運(yùn)行狀況。
要評(píng)估Ceph集群的當(dāng)前狀態(tài),請(qǐng)輸入:
- # ceph status
或者使用:
- # ceph -s
兩次命令的結(jié)果都應(yīng)輸出類(lèi)似于以下內(nèi)容:
- cluster b370a29d-9287-4ca3-ab57-3d824f65e339
- health HEALTH_OK
- monmap e1: 1 mons at {ceph1=10.0.0.8:6789/0}, election epoch 2, quorum 0 ceph1
- osdmap e63: 2 osds: 2 up, 2 in
- pgmap v41332: 952 pgs, 20 pools, 17130 MB data, 2199 objects
- 115 GB used, 167 GB / 297 GB avail
- 1 active+clean+scrubbing+deep
- 951 active+clean
如果您看到健康狀況為“HEALTH_OK”,那就說(shuō)明集群狀態(tài)健康。
在某些情況下,尤其是與OSD相關(guān)的情況下,將返回HEALTH_WARN或HEALTH_ERR。這可能是由于一些不影響群集整體性能的因素所致,例如OSD重新均衡或存儲(chǔ)池的PG的深度清理。這些都可以安全地忽略。
在某些情況下,Ceph的命令行界面可能根本不響應(yīng)這兩個(gè)命令。如果您的Ceph的身份驗(yàn)證有問(wèn)題,或者運(yùn)行Monitor服務(wù)的節(jié)點(diǎn)硬件有問(wèn)題,通常會(huì)發(fā)生這種情況。在第二種情況下,則需要診斷Monitor節(jié)點(diǎn)服務(wù)器本身的硬件問(wèn)題。
「mon(Monitor)調(diào)試」
當(dāng)使用多個(gè)Ceph Mon運(yùn)行時(shí),Ceph則需要仲裁(Quorum)。仲裁是確保一致性的可靠方法,因?yàn)槿杭枰钌俚?ldquo;投票”數(shù)才能繼續(xù)進(jìn)行replication。
可以使用以下幾個(gè)命令來(lái)確定Ceph Mon的狀態(tài)。
- # ceph mon stat
上述命令將輸出集群中所有mon的當(dāng)前狀態(tài),例如:
- e3: 3 mons at {pve1=10.103.6.109:6789/0,pve2=10.103.6.110:6789/0,pve3=10.103.6.111:6789/0}, election epoch 30, leader 0 pve1, quorum 0,1,2 pve1,pve2,pve3
上面表示有三個(gè)Ceph Mon已經(jīng)啟動(dòng)并成功運(yùn)行。其中有一個(gè)仲裁節(jié)點(diǎn),狀態(tài)顯示集群運(yùn)行正常。您會(huì)注意到ceph mon stat的輸出中有幾條重要的信息,包括選舉之間的時(shí)間間隔(以秒為單位)。選舉在這些時(shí)間間隔內(nèi)發(fā)生,以確定哪個(gè)監(jiān)視器應(yīng)該是集群的“leader”。
與使用仲裁作為確保一致性的方法的非技術(shù)機(jī)構(gòu)一樣,每個(gè)節(jié)點(diǎn)都有一票表決權(quán)。在Ceph中,最佳實(shí)踐堅(jiān)持我們利用大于或等于3的奇數(shù)個(gè)Ceph Mon節(jié)點(diǎn)。這確保了我們的群集在失去一個(gè)或者兩個(gè)仲裁節(jié)點(diǎn)的小概率事件中維持仲裁能力和一定程度的冗余。
如果我們真的失去了法定人數(shù)(quorum),或者沒(méi)有贏(yíng)得法定人數(shù)的投票。那么,由于監(jiān)視器在其Ceph運(yùn)行中所起的重要作用,則會(huì)導(dǎo)致Ceph群集將完全無(wú)法響應(yīng)。從跟蹤數(shù)據(jù)存放位置到維護(hù)OSD的實(shí)時(shí)Map。Ceph Mon節(jié)點(diǎn)還提供用于返回“Ceph health”和“Ceph -s”輸出功能。如果沒(méi)有一個(gè)正常工作的Ceph Mon仲裁,則所有命令都不會(huì)有任何返回值。
檢查監(jiān)視器狀態(tài)的其他有用命令包括:
- #dumping the mon map
- # ceph mon dump
- dumped monmap epoch 3
- epoch 3
- fsid 4a1dc77a-37f8-4b5b-9476-853f7cace716
- last_changed 2020-8-18 10:50:36.846268
- created 2020-8-18 10:50:25.571368
- 0: 10.103.6.109:6789/0 mon.pve1
- 1: 10.103.6.110:6789/0 mon.pve2
- 2: 10.103.6.111:6789/0 mon.pve3
- # ceph quorum_status --format json-pretty #looking at quorum status
- {
- "election_epoch": 30,
- "quorum": [
- 0,
- 1,
- 2
- ],
- "quorum_names": [
- "pve1",
- "pve2",
- "pve3"
- ],
- "quorum_leader_name": "pve1",
- "monmap": {
- "epoch": 3,
- "fsid": "4a1dc77a-37f8-4b5b-9476-853f7cace716",
- "modified": "2020-8-18 10:50:36.846268",
- "created": "2020-8-18 10:50:25.571368",
- "features": {
- "persistent": [
- "kraken",
- "luminous"
- ],
- "optional": []
- },
- "mons": [
- {
- "rank": 0,
- "name": "pve1",
- "addr": "10.103.6.109:6789/0",
- "public_addr": "10.103.6.109:6789/0"
- },
- {
- "rank": 1,
- "name": "pve2",
- "addr": "10.103.6.110:6789/0",
- "public_addr": "10.103.6.110:6789/0"
- },
- {
- "rank": 2,
- "name": "pve3",
- "addr": "10.103.6.111:6789/0",
- "public_addr": "10.103.6.111:6789/0"
- }
- ]
- }
- }
「守護(hù)進(jìn)程套接字(「Daemon Socket」)」
Ceph管理套接字(daemon socket)允許您直接連接到所有正在運(yùn)行的Ceph守護(hù)進(jìn)程。從OSD到Mon和MGR,Ceph守護(hù)程序管理套接字可以提供診斷功能,這些功能在Ceph Mon發(fā)生故障并且Ceph客戶(hù)端停止響應(yīng)時(shí)可能會(huì)變得不可用。
以下命令可直接連接到Ceph守護(hù)程序,根據(jù)需求進(jìn)行狀態(tài)查看。
- # ceph daemon {daemon-name} ##OR
- # ceph daemon {path-to-socket-file} ##For Example
- # ceph daemon osd.0 help
- {
- "calc_objectstore_db_histogram": "Generate key value histogram of kvdb(rocksdb) which used by bluestore",
- "compact": "Commpact object store's omap. WARNING: Compaction probably slows your requests",
- "config diff": "dump diff of current config and default config",
- "config diff get": "dump diff get : dump diff of current and default config setting ",
- "config get": "config get : get the config value",
- "config help": "get config setting schema and descriptions",
- "config set": "config set [ ...]: set a config variable",
- "config show": "dump current config settings",
- "dump_blacklist": "dump blacklisted clients and times",
- "dump_blocked_ops": "show the blocked ops currently in flight",
- "dump_historic_ops": "show recent ops",
- "dump_historic_ops_by_duration": "show slowest recent ops, sorted by duration",
- "dump_historic_slow_ops": "show slowest recent ops",
- "dump_mempools": "get mempool stats",
- "dump_objectstore_kv_stats": "print statistics of kvdb which used by bluestore",
- "dump_op_pq_state": "dump op priority queue state",
- "dump_ops_in_flight": "show the ops currently in flight",
- "dump_pgstate_history": "show recent state history",
- "dump_reservations": "show recovery reservations",
- "dump_scrubs": "print scheduled scrubs",
- "dump_watchers": "show clients which have active watches, and on which objects",
- "flush_journal": "flush the journal to permanent store",
- "flush_store_cache": "Flush bluestore internal cache",
- "get_command_descriptions": "list available commands",
- "get_heap_property": "get malloc extension heap property",
- "get_latest_osdmap": "force osd to update the latest map from the mon",
- "getomap": "output entire object map",
- "git_version": "get git sha1",
- "heap": "show heap usage info (available only if compiled with tcmalloc)",
- "help": "list available commands",
- "injectdataerr": "inject data error to an object",
- "injectfull": "Inject a full disk (optional count times)",
- "injectmdataerr": "inject metadata error to an object",
- "log dump": "dump recent log entries to log file",
- "log flush": "flush log entries to log file",
- "log reopen": "reopen log file",
- "objecter_requests": "show in-progress osd requests",
- "ops": "show the ops currently in flight",
- "perf dump": "dump perfcounters value",
- "perf histogram dump": "dump perf histogram values",
- "perf histogram schema": "dump perf histogram schema",
- "perf reset": "perf reset : perf reset all or one perfcounter name",
- "perf schema": "dump perfcounters schema",
- "rmomapkey": "remove omap key",
- "set_heap_property": "update malloc extension heap property",
- "set_recovery_delay": "Delay osd recovery by specified seconds",
- "setomapheader": "set omap header",
- "setomapval": "set omap key",
- "status": "high-level status of OSD",
- "trigger_scrub": "Trigger a scheduled scrub ",
- "truncobj": "truncate object to length",
- "version": "get ceph version"
例如,當(dāng)多個(gè)Ceph monitor守護(hù)進(jìn)程同時(shí)失敗時(shí),Ceph守護(hù)程序可用于更新mon map。這將使您可以將新的mon map更新并導(dǎo)入到無(wú)法運(yùn)行的Ceph Mon節(jié)點(diǎn)中,這也是Ceph中非常常見(jiàn)的一個(gè)故障解決方案。
「規(guī)避風(fēng)險(xiǎn)」
用戶(hù)應(yīng)該盡量熟悉這兩種從Ceph群集崩潰或意外中斷中恢復(fù)的重要方法。這些工具功能強(qiáng)大,學(xué)習(xí)如何利用它們則能盡量減少數(shù)據(jù)丟失的風(fēng)險(xiǎn),同時(shí)也能夠最快,最全的恢復(fù)Ceph集群。
當(dāng)然,每一個(gè)故障場(chǎng)景都不同,本處僅僅是提供了一些常規(guī)的集群崩潰故障以及對(duì)應(yīng)的解決方案。但更復(fù)雜的場(chǎng)景需要用戶(hù)根據(jù)自身所遇到的場(chǎng)景進(jìn)行更加具體的分析以及處理。
Ceph — OSD Flapping(抖動(dòng))調(diào)試和恢復(fù)
下面我們將特別討論如果當(dāng)您發(fā)現(xiàn)Ceph OSD因意外而進(jìn)行peering,出現(xiàn)scrubbing或集群連接斷斷續(xù)續(xù)的情況時(shí)候該如何進(jìn)行排查以及解決問(wèn)題。其實(shí),上述的這些行為也可以稱(chēng)之為抖動(dòng)(flapping),而且這因多種原因而引起的故障會(huì)損害群集的性能和持久性以及穩(wěn)定性。
「故障」
當(dāng)一個(gè)OSD或多個(gè)OSD開(kāi)始抖動(dòng)(flapping)時(shí),您可能首先會(huì)注意到讀寫(xiě)速度明顯下降。這是出于多種原因。當(dāng)OSD在不停的抖動(dòng)(flapping)期間停止時(shí),您實(shí)際上已經(jīng)失去了正在抖動(dòng)(flapping)的所有OSD的總吞吐量,也就是說(shuō)這些抖動(dòng)(flapping) OSD不僅不能提供正常的存儲(chǔ)能力,還影響了整個(gè)集群的性能。尤其是在一個(gè)擁有數(shù)萬(wàn)IOPS讀寫(xiě)的大型集群上,這可能是災(zāi)難性的。
OSD服務(wù)正常后,群集要做的第一件事就是嘗試進(jìn)行恢復(fù)。恢復(fù)并不是一個(gè)非常簡(jiǎn)單的過(guò)程,其中需要對(duì)在多個(gè)不同主機(jī)上的多個(gè)OSD中副本的塊進(jìn)行校驗(yàn)和驗(yàn)證,以確保完整性。如果校驗(yàn)和不匹配,則需要重新復(fù)制該塊。
此校驗(yàn)和驗(yàn)證和文件重新傳輸過(guò)程會(huì)引起Ceph集群的大量硬件資源消耗。最直接的體現(xiàn)是:服務(wù)器設(shè)備耗電量會(huì)大幅度增加,群集網(wǎng)絡(luò)上的網(wǎng)絡(luò)流量也會(huì)急劇增加。如果當(dāng)前Ceph集群已經(jīng)處于一個(gè)高負(fù)載的環(huán)境,這種額外的不必要的負(fù)載可能會(huì)導(dǎo)致性能進(jìn)一步下降,甚至導(dǎo)致集群停止響應(yīng),極端情況會(huì)引起Ceph集群的一連串的崩潰。
那么,如何查看Ceph集群的癥狀,以查看性能問(wèn)題是否與OSD的抖動(dòng)(flapping)相關(guān)?第一種也是最簡(jiǎn)單的方法是簡(jiǎn)單地檢查群集的運(yùn)行狀況。這可以通過(guò)使用Luminous及更高版本中提供的Ceph儀表板來(lái)完成。可通過(guò)“http://IPCEPHNODE:7000” (7000為訪(fǎng)問(wèn)端口,在初始化的時(shí)候可以根據(jù)需求進(jìn)行自定義)。您還可以在任何啟用了ceph-admin的主機(jī)上通過(guò)命令行查看Ceph群集的狀態(tài)。可以使用“ ceph -s”命令,該命令將輸出集群的當(dāng)前運(yùn)行狀況。如果正在進(jìn)行修復(fù)或OSD當(dāng)前被標(biāo)記為down,該命令將向您發(fā)出輸出警報(bào)。
「原因和解決方法」
通常,導(dǎo)致OSD抖動(dòng)(flapping)的原因與導(dǎo)致OSD失敗的原因相似。不良的硬件狀況,過(guò)多的發(fā)熱,網(wǎng)絡(luò)問(wèn)題以及整個(gè)系統(tǒng)的負(fù)載都可能導(dǎo)致OSD抖動(dòng)(flapping)。
從硬件的角度來(lái)看,底層的存儲(chǔ)磁盤(pán)可能出現(xiàn)物理故障。所有硬盤(pán)都可通過(guò)SMART屬性監(jiān)視其當(dāng)前狀態(tài)。這些值提供有關(guān)硬盤(pán)各種參數(shù)的信息,并可提供有關(guān)磁盤(pán)剩余壽命或任何可能的錯(cuò)誤的信息。此外,可以執(zhí)行各種SMART測(cè)試,以確定磁盤(pán)上的任何硬件問(wèn)題。因此,可以利用Smartctl來(lái)確定當(dāng)前環(huán)境中的SAS或者SATA磁盤(pán)是否處于不健康狀態(tài)——這可能導(dǎo)致OSD故障并不停重啟。通過(guò)登錄到可能受影響的主機(jī)并輸入“ smartctl -a /dev/sdX”(其中X是設(shè)備ID)來(lái)定位物理設(shè)備,從而檢查硬盤(pán)驅(qū)動(dòng)器的SMART狀態(tài)。同時(shí)還可以通過(guò)grep正則匹配去過(guò)濾所需要的參數(shù)。通過(guò)該方式,不僅將輸出硬盤(pán)當(dāng)前的狀態(tài),同時(shí)會(huì)顯示即將發(fā)生故障。如果可以的話(huà),請(qǐng)及時(shí)更換有故障的硬盤(pán)!
OSD抖動(dòng)(flapping)的另一個(gè)原因可能很簡(jiǎn)單,比如您的Ceph存儲(chǔ)網(wǎng)絡(luò)接口上的MTU不匹配。MTU或Maximum Transmission Unit,用來(lái)通知對(duì)方所能接受數(shù)據(jù)服務(wù)單元的最大尺寸,說(shuō)明發(fā)送方能夠接受的有效載荷大小,也就是允許接口發(fā)送的最大數(shù)據(jù)包大小——有效地將數(shù)據(jù)包拆分為較小的塊,以適合系統(tǒng)指定的MTU。因?yàn)镃eph是一種處理大型數(shù)據(jù)塊的存儲(chǔ)技術(shù),所以MTU越大,代表系統(tǒng)以最少的工作量就可以獲得更多的吞吐量。
如果整個(gè)集群中的任何地方的MTU不匹配,即一臺(tái)服務(wù)器的MTU設(shè)置為9000,另一臺(tái)服務(wù)器的MTU設(shè)置為1500,你最終會(huì)遇到這樣的情況:數(shù)據(jù)傳輸卡頓,并且Ceph集群的復(fù)制也會(huì)基本停止。這也可能是Ceph OSD抖動(dòng)(flapping)的另外一個(gè)原因(健康檢查與低MTU的競(jìng)爭(zhēng)帶寬)。
要檢查接口的MTU,請(qǐng)?jiān)诿钚猩湘I入“ ifconfig”或“ ip addr”。將MTU與接口匹配,并比較群集中所有主機(jī)接口的MTU配置是否一致。
「結(jié)論」
Ceph OSD的抖動(dòng)是存儲(chǔ)使用過(guò)程中最常見(jiàn)的一種故障,該故障不一定會(huì)致命,但往往會(huì)對(duì)集群性能產(chǎn)生嚴(yán)重的影響。及時(shí)發(fā)現(xiàn)OSD抖動(dòng),合理解決問(wèn)題,盡量避免對(duì)集群產(chǎn)生過(guò)多的影響。
「Ceph性能優(yōu)化與增強(qiáng)」
上文介紹了Ceph的入門(mén)背景,討論了Ceph在云計(jì)算和對(duì)象存儲(chǔ)中的功能和主要組件,并簡(jiǎn)要概述了其部署工具以及常規(guī)的故障現(xiàn)象以及對(duì)應(yīng)的解決思路。下文,我們將研究Ceph的強(qiáng)大的功能,并探索最優(yōu)的方法來(lái)提高存儲(chǔ)性能。
Ceph是一個(gè)非常復(fù)雜的存儲(chǔ)系統(tǒng),它具有幾種我們可以用來(lái)提高性能的方式。幸運(yùn)的是,Ceph的開(kāi)箱即用非常好,許多性能設(shè)置幾乎利用了自動(dòng)調(diào)整和縮放功能。在探索一些性能增強(qiáng)時(shí),了解您的工作負(fù)載很重要,這樣您就可以選擇最適合您的選項(xiàng)。
「配置說(shuō)明」
Ceph有幾種部署方案,其中最常見(jiàn)的是針對(duì)虛擬化環(huán)境,符合POSIX的文件系統(tǒng)和塊存儲(chǔ)的組合。這些場(chǎng)景中的每一個(gè)都有明顯不同的配置要求。例如,在CephFS提出的POSIX文件系統(tǒng)中,將文件系統(tǒng)元數(shù)據(jù)存儲(chǔ)在高速SSD或NVMe驅(qū)動(dòng)器上是非常重要。對(duì)于虛擬化環(huán)境中使用RBD場(chǎng)景,Ceph的caching tier功能可以使用SSD或NVMe為后端普通廉價(jià)的存儲(chǔ)提供高速緩存的功能。
「通用硬件」
「Hyper-Threading(HT)」基本做云平臺(tái)的,VT和HT打開(kāi)都是必須的,超線(xiàn)程技術(shù)(HT)就是利用特殊的硬件指令,把兩個(gè)邏輯內(nèi)核模擬成兩個(gè)物理芯片,讓單個(gè)處理器都能使用線(xiàn)程級(jí)并行計(jì)算,進(jìn)而兼容多線(xiàn)程操作系統(tǒng)和軟件,減少了CPU的閑置時(shí)間,提高的CPU的運(yùn)行效率。
「關(guān)閉節(jié)能」關(guān)閉節(jié)能后,對(duì)性能還是有所提升的,所以堅(jiān)決調(diào)整成性能型(Performance)。當(dāng)然也可以在操作系統(tǒng)級(jí)別進(jìn)行調(diào)整,詳細(xì)的調(diào)整過(guò)程請(qǐng)參考鏈接,但是不知道是不是由于BIOS已經(jīng)調(diào)整的緣故,所以在CentOS 6.6上并沒(méi)有發(fā)現(xiàn)相關(guān)的設(shè)置。
- for CPUFREQ in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do [ -f <span class="katex math inline">CPUFREQ ] || continue; echo -n performance></span>CPUFREQ; done
「NUMA」簡(jiǎn)單來(lái)說(shuō),NUMA思路就是將內(nèi)存和CPU分割為多個(gè)區(qū)域,每個(gè)區(qū)域叫做NODE,然后將NODE高速互聯(lián)。node內(nèi)cpu與內(nèi)存訪(fǎng)問(wèn)速度快于訪(fǎng)問(wèn)其他node的內(nèi)存,NUMA可能會(huì)在某些情況下影響ceph-osd。解決的方案,一種是通過(guò)BIOS關(guān)閉NUMA,另外一種就是通過(guò)cgroup將ceph-osd進(jìn)程與某一個(gè)CPU Core以及同一NODE下的內(nèi)存進(jìn)行綁定。但是第二種看起來(lái)更麻煩,所以一般部署的時(shí)候可以在系統(tǒng)層面關(guān)閉NUMA。CentOS系統(tǒng)下,通過(guò)修改/etc/grub.conf文件,添加numa=off來(lái)關(guān)閉NUMA。
- kernel /vmlinuz-2.6.32-504.12.2.el6.x86_64 ro root=UUID=870d47f8-0357-4a32-909f-74173a9f0633 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM biosdevname=0 numa=off
「RAM」
為Ceph選擇的主機(jī)及其基礎(chǔ)服務(wù)應(yīng)具有足夠的CPU線(xiàn)程,內(nèi)存和網(wǎng)絡(luò)設(shè)備,以處理群集的預(yù)期吞吐量。Ceph建議每1TB OSD原始磁盤(pán)空間使用1GB RAM。如果主機(jī)具有96TB的原始磁盤(pán)空間,則應(yīng)計(jì)劃至少需要96GB的RAM。我們建議每個(gè)OSD至少使用1個(gè)CPU內(nèi)核。OSD可以定期消耗整個(gè)CPU來(lái)執(zhí)行重新平衡操作。
「避免使用超融合!」
不建議以超融合方式在Ceph節(jié)點(diǎn)上運(yùn)行其他應(yīng)用程序,因?yàn)樵谟捎诖疟P(pán)故障而導(dǎo)致的群集重建過(guò)程中,每個(gè)OSD的OSD RAM使用量可能遠(yuǎn)遠(yuǎn)超過(guò)建議的1GB。如果其他應(yīng)用程序爭(zhēng)奪RAM,則重建性能以及隨后的Ceph群集本身的讀寫(xiě)性能都會(huì)受到嚴(yán)重影響。
「不要使用硬件RAID控制器!」
讓Ceph為您完成數(shù)據(jù)處理。使用硬件RAID控制器可能導(dǎo)致Ceph在RAID重建期間未意識(shí)到的不一致和性能下降。SAS HBA的價(jià)格為$100-$200,高性能的僅占很小的溢價(jià)。這將是確保Ceph集群性能的最佳配置。
「基礎(chǔ)存儲(chǔ)OSD」
當(dāng)構(gòu)建一個(gè)新的Ceph群集時(shí),其中一個(gè)主要的工作是對(duì)象存儲(chǔ)守護(hù)程序(OSD)的底層存儲(chǔ)的選擇。容量需求可能決定了該解決方案所需要的底層存儲(chǔ)。預(yù)算可能允許購(gòu)買(mǎi)大容量的SSD驅(qū)動(dòng)器或NVMe。無(wú)論選擇了什么樣的底層存儲(chǔ),累計(jì)底層存儲(chǔ)的性能都將直接影響Ceph集群的性能(OSD性能越佳,則Ceph集群性能也越佳)。
在需要使多個(gè)10G萬(wàn)兆網(wǎng)絡(luò)接口的環(huán)境中,或者對(duì)于讀寫(xiě)時(shí)延極低的應(yīng)用程序,選擇SSD或NVMe磁盤(pán)可能更有意義。這些將為OSD提供企業(yè)級(jí)磁盤(pán)的完整吞吐量,包括在整個(gè)群集中的組合IOPS。
SATA和SAS類(lèi)型磁盤(pán)確實(shí)提供了比SSD和NVMe更大的標(biāo)準(zhǔn)存儲(chǔ)容量,但是IOPS與吞吐量有限(受限于OSD所使用的存儲(chǔ)介質(zhì))。因此,群集中將需要更大的磁盤(pán)陣列,以提供與更快的磁盤(pán)相似的甚至遠(yuǎn)超的性能。
「緩存層」
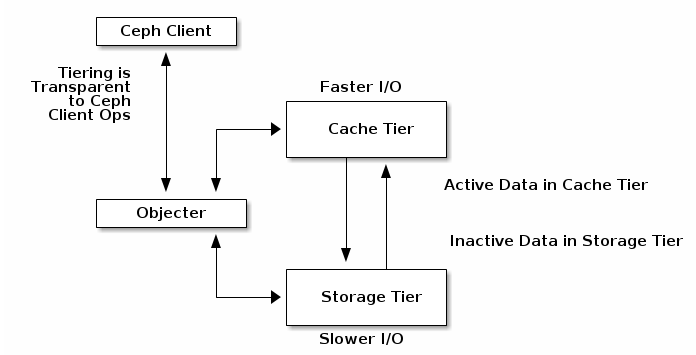
Ceph Luminous中的新增功能,對(duì)于出于預(yù)算原因或使用大容量磁盤(pán)的項(xiàng)目,可以充分提前預(yù)估存儲(chǔ)容量的用戶(hù)而言,緩存層(Cache Tier)是一項(xiàng)極佳的性能增強(qiáng)解決方案。構(gòu)建緩存層(Cache Tier)需要為每個(gè)Ceph存儲(chǔ)節(jié)點(diǎn)提供少數(shù)量的SSD或NVMe磁盤(pán),并修改Crush Map映射以創(chuàng)建單獨(dú)的存儲(chǔ)類(lèi)。
最佳實(shí)踐表明,除非您能夠準(zhǔn)確預(yù)測(cè)實(shí)際數(shù)據(jù)量,否則緩存應(yīng)不小于活動(dòng)存儲(chǔ)池的1/10到1/8的容量。因此,如果您有100TB的數(shù)據(jù)池,則應(yīng)計(jì)劃為您的緩存層提供大約10TB的存儲(chǔ)空間。
「Crush Map」
CRUSH 算法通過(guò)計(jì)算數(shù)據(jù)存儲(chǔ)位置來(lái)確定如何存儲(chǔ)和檢索。CRUSH 授權(quán) Ceph 客戶(hù)端直接連接 OSD ,而非通過(guò)一個(gè)集中服務(wù)器或代理。數(shù)據(jù)存儲(chǔ)、檢索算法的使用,使 Ceph 避免了單點(diǎn)故障、性能瓶頸、和伸縮的物理限制。
CRUSH 需要一張集群的 Map,且使用 CRUSH Map 把數(shù)據(jù)偽隨機(jī)地、盡量平均地分布到整個(gè)集群的 OSD 里。CRUSH Map 包含 OSD 列表、把設(shè)備匯聚為物理位置的“桶”列表、和指示 CRUSH 如何復(fù)制存儲(chǔ)池里的數(shù)據(jù)的規(guī)則列表。
CRUSH Map負(fù)責(zé)確保數(shù)據(jù)最終到達(dá)群集中應(yīng)有的位置,并在將IO請(qǐng)求轉(zhuǎn)換為磁盤(pán)位置以進(jìn)行數(shù)據(jù)檢索中發(fā)揮作用。正確的CRUSH Map將考慮設(shè)備的適當(dāng)權(quán)重,通常由磁盤(pán)大小決定,盡管您可以根據(jù)磁盤(pán)IOPS等其他因素來(lái)修改權(quán)重(一般不建議這樣做)。
「系統(tǒng)調(diào)整」
一個(gè)經(jīng)過(guò)適當(dāng)調(diào)優(yōu)的系統(tǒng)將是實(shí)現(xiàn)Ceph預(yù)期性能的關(guān)鍵。請(qǐng)?zhí)貏e關(guān)注網(wǎng)絡(luò)和sysctl優(yōu)化。一些關(guān)鍵參數(shù)包括:
- 「系統(tǒng)MTU」 :將其設(shè)置為9000以允許大幀。眾所周知,存儲(chǔ)流量在TCP堆棧上非常頻繁,應(yīng)允許其盡可能多地傳輸數(shù)據(jù)而不會(huì)造成碎片,以確保您能夠充分使用存儲(chǔ)網(wǎng)絡(luò)。
- 「Swappiness」 :通常,使用swap分區(qū)是不太好的。每當(dāng)您從內(nèi)存切換到磁盤(pán)時(shí),操作系統(tǒng)就會(huì)用完執(zhí)行基本功能所需的內(nèi)存,并且不得不將其中的某些內(nèi)存強(qiáng)制降低到速度慢得多的磁盤(pán)上。在查看性能時(shí),不能忽略Ceph群集的RAM分配的正確大小。可以在linux系統(tǒng)中配置Sysctl相應(yīng)的參數(shù),以強(qiáng)制linux停止使用交換分區(qū)。我們建議值為1,默認(rèn)值通常可以在20到40之間。數(shù)字越大,內(nèi)核嘗試交換的頻率就越高。
- 「“ noatime”」 :在大多數(shù)已掛載的文件系統(tǒng)上使用此選項(xiàng),以跟蹤磁盤(pán)上文件的上次訪(fǎng)問(wèn)時(shí)間。由于這是由OSD自己?jiǎn)为?dú)處理的,因此在速度較慢的磁盤(pán)上禁用noatime可以提高性能。
「Ceph架構(gòu)調(diào)整」
關(guān)于Ceph的配置以及優(yōu)化的思路整體涉及如下:
- Mon節(jié)點(diǎn)對(duì)于群集的正常運(yùn)行至關(guān)重要。嘗試并使用獨(dú)立的Mon節(jié)點(diǎn),請(qǐng)確保資源獨(dú)享;或者,如果它們?cè)诠蚕憝h(huán)境中運(yùn)行,則需要隔離Mon進(jìn)程。為了實(shí)現(xiàn)冗余,請(qǐng)?jiān)贑eph集群中將Mon節(jié)點(diǎn)盡量均勻分布。
- Journal日志因雙寫(xiě)緣故,對(duì)影響影響較大。理想情況下,您應(yīng)該在單獨(dú)的物理磁盤(pán)上運(yùn)行操作系統(tǒng),OSD數(shù)據(jù)和OSD日志,以最佳的方式提高整體吞吐量。可以考慮將SSD用作Journal分區(qū)來(lái)提供讀寫(xiě)吞吐量。
- 如果使用的是bluestore而非filestore的話(huà),也請(qǐng)考慮rocksdb與wal的存儲(chǔ)使用SSD分區(qū)。
- 糾錯(cuò)碼是對(duì)象存儲(chǔ)的一種數(shù)據(jù)持久性特性。當(dāng)存儲(chǔ)大量一次寫(xiě)入、不經(jīng)常讀取的數(shù)據(jù)時(shí),請(qǐng)使用糾錯(cuò)碼。但是請(qǐng)記住,這是一個(gè)折衷方案:糾錯(cuò)碼可以大大降低每GB的成本,但與副本相比,其IOPS性能較低。
- 支持dentry和inode緩存可以提高性能,尤其是在具有許多較小對(duì)象的群集上。
- 使用緩存分層,可以根據(jù)需求在熱層和冷層之間自動(dòng)遷移數(shù)據(jù),從而提高群集的性能。為了獲得最佳性能,請(qǐng)將SSD用于高速緩存池,并將存儲(chǔ)池托管在具有較低延遲的服務(wù)器上。
- 部署奇數(shù)個(gè)Mon節(jié)點(diǎn)(3個(gè)或5個(gè))以進(jìn)行法定投票。添加更多的Mon可使您的群集更持久。但是,這有時(shí)會(huì)降低性能,因?yàn)镸on之間還有更多數(shù)據(jù)要保持同步。
- 排查群集中的性能問(wèn)題時(shí),請(qǐng)始終從最低級(jí)別(磁盤(pán),網(wǎng)絡(luò)或其他硬件)開(kāi)始,然后逐步升級(jí)至更高級(jí)別(塊設(shè)備和對(duì)象網(wǎng)關(guān))。
- PG和PGP數(shù)量一定要根據(jù)OSD的數(shù)量進(jìn)行調(diào)整,不合理的PG數(shù)目會(huì)導(dǎo)致數(shù)據(jù)分布不均衡。
- Ceph OSD存在木桶原理,單個(gè)OSD的性能下降可能會(huì)影響整個(gè)集群的性能,所以要及時(shí)發(fā)現(xiàn)低性能的OSD,然后更換或者直接踢出集群。
「結(jié)論」
根據(jù)以上幾種方法可以正確實(shí)現(xiàn)Ceph以提供您期望的性能。利用磁盤(pán)緩存,緩存分層和適當(dāng)配置的系統(tǒng),可以確保磁盤(pán)性能不會(huì)成為基礎(chǔ)架構(gòu)的瓶頸。
寫(xiě)在最后
雖然開(kāi)源存儲(chǔ)對(duì)于希望減少集中式商業(yè)存儲(chǔ)上的用戶(hù)而言來(lái)說(shuō)是一個(gè)福音,但文檔和支持可能會(huì)受到限制。在沒(méi)有商業(yè)支持的前提下,除了靠社區(qū)的支持外,剩下的就靠用戶(hù)對(duì)軟件本身的熟悉程度。只有不斷的嘗試,不斷的優(yōu)化,不斷的回饋社區(qū),才能使開(kāi)源軟件發(fā)展的更好。
參考:
https://ceph.readthedocs.io
http://www.slideshare.net/Inktank_Ceph/dell-ceph-22nd-london-v5
http://ceph.com/docs/master/start/hardware-recommendations/
http://www.inktank.com/inktank-ceph-enterprise/inktank-ceph-enterprise-1-2-arrives-with-erasure-coding-and-cache-tiering