













救火必備!問題排查與系統優化手冊
????軟件工程領域存在一個共識:維護代碼所花費的時間要遠多于寫代碼。而整個代碼維護過程中,最驚心動魄與扣人心弦的部分,莫過于問題排查(Trouble-shooting)了。特別是那些需要 7x24 小時不間斷維護在線業務的一線服務端程序員們,大大小小的問題排查線上救火早已成為家常便飯,一不小心可能就吃成了自助餐 —— 豎著進躺著出,吃不了也兜不住。本文分享作者在服務端問題排查方面的一些經驗,包括常見問題、排查流程、排查工具,結合實際項目中發生過的慘痛案例進行現身說法。
一 問題排查
1 常見問題
Know Your Enemy:知己知彼,百戰不殆。
日常遇到的大部分問題,大致可以歸到如下幾類:
- 邏輯缺陷:e.g. NPE、死循環、邊界情況未覆蓋。
- 性能瓶頸:e.g. 接口 RT 陡增、吞吐率上不去。
- 內存異常:e.g. GC 卡頓、頻繁 FGC、內存泄露、OOM
- 并發/分布式:e.g. 存在競爭條件、時鐘不同步。
- 數據問題:e.g. 出現臟數據、序列化失敗。
- 安全問題:e.g. DDoS 攻擊、數據泄露。
- 環境故障:e.g. 宿主機宕機、網絡不通、丟包。
- 操作失誤:e.g. 配置推錯、刪庫跑路(危險動作,請勿嘗試..)。
上述分類可能不太完備和嚴謹,想傳達的點是:你也可以積累一個這樣的 checklist,當遇到問題百思不得其解時,耐心過一遍,也許很快就能對號入座。
2 排查流程
醫生:小王你看,這個傷口的形狀,像不像一朵漂浮的白云?
病人:...再不給我包扎止血,就要變成火燒云了。
?? 
快速止血
問題排查的第一步,一定是先把血止住,及時止損。如何快速止血?常見方式包括:
- 發布期間開始報錯,且發布前一切正常?啥也別管,先回滾再說,恢復正常后再慢慢排查。
- 應用已經穩定運行很長一段時間,突然開始出現進程退出現象?很可能是內存泄露,默默上重啟大法吧。
- 只有少數固定機器報錯?試試隔離這部分機器(關閉流量入口)。
- 單用戶流量突增導致服務不穩定?如果不是惹不起的金主爸爸,請勇敢推送限流規則。
- 下游依賴掛了導致服務雪崩?還想什么呢,降級預案走起。
保留現場
血止住了?那么恭喜你,至少故障影響不會再擴大了。卸下鍋,先喘口氣再說。下一步,就是要根據線索找出問題元兇了。作為一名排查老手,你需要有盡量保留現場的意識,例如:
- 隔離一兩臺機器:將這部分機器入口流量關閉,讓它們靜靜等待你的檢閱。
- Dump 應用快照:常用的快照類型一般就是線程堆棧和堆內存映射。
- 所有機器都回滾了,咋辦?別慌,如果你的應用監控運維體系足夠健全,那么你還有多維度的歷史數據可以回溯:應用日志、中間件日志、GC 日志、內核日志、Metrics 指標等。
定位原因
OK,排查線索也有了,接下來該怎么定位具體原因?這個環節會綜合考驗你的技術深度、業務熟悉度和實操經驗,因為原因往往都千奇百怪,需要 case by case 的追蹤與分析。這里給出幾個排查方向上的建議:
- 關聯近期變更:90% 以上的線上問題都是由變更引發,這也是為什么集團安全生產的重點一直是在管控“變更”。所以,先不要急著否認(“肯定不是我剛加的那行代碼問題!”),相信統計學概率,好好 review 下近期的變更歷史(從近至遠)。
- 全鏈路追蹤分析:微服務和中臺化盛行的當下,一次業務請求不經過十個八個應用處理一遍,都不好意思說自己是寫 Java 的。所以,不要只盯著自己的應用不放,你需要把排查 scope 放大到全鏈路。
- 還原事件時間線:請把自己想象成福爾摩斯(柯南也行),擺在你面前的就是一個案發現場,你需要做的是把不同時間點的所有事件線索都串起來,重建和還原整個案發過程。要相信,時間戳是不會騙人的。
- 找到 Root Cause:排查問題多了你會發現,很多疑似原因往往只是另一個更深層次原因的表象結果之一。作為福爾摩斯,你最需要找到的是幕后兇手,而不是雇傭的殺人犯 —— 否則 TA 還會雇人再來一次。
- 嘗試復現問題:千辛萬苦推導出了根因,也不要就急著開始修 bug 了。如果可以,最好能把問題穩定復現出來,這樣才更有說服力。這里提醒一點:可千萬別在生產環境干這事(除非你真的 know what you're doing),否則搞不好就是二次傷害(你:哈哈哈,你看,這把刀當時就是從這個角度捅進去的,軌跡完全一樣。用戶:...)。
解決問題
最后,問題根因已經找到,如何完美解決收尾?幾個基本原則:
- 修復也是一種變更,需要經過完整的回歸測試、灰度發布;切忌火急火燎上線了 bugfix,結果引發更多的 bugs to fix。
- 修復發布后,一定要做線上驗證,并且保持觀察一段時間,確保是真的真的修復了。
- 最后,如果問題已經上升到了故障這個程度,那就拉上大伙好好做個故障復盤吧。整個處理過程一定還有提升空間,你的經驗教訓對其他同學來說也是一次很好的輸入和自查機會:幸福總是相似的,故障也是。
3 排查工具
手里只有錘子,那看什么都像釘子。作為工程師,你需要的是一整套工具箱。
?? 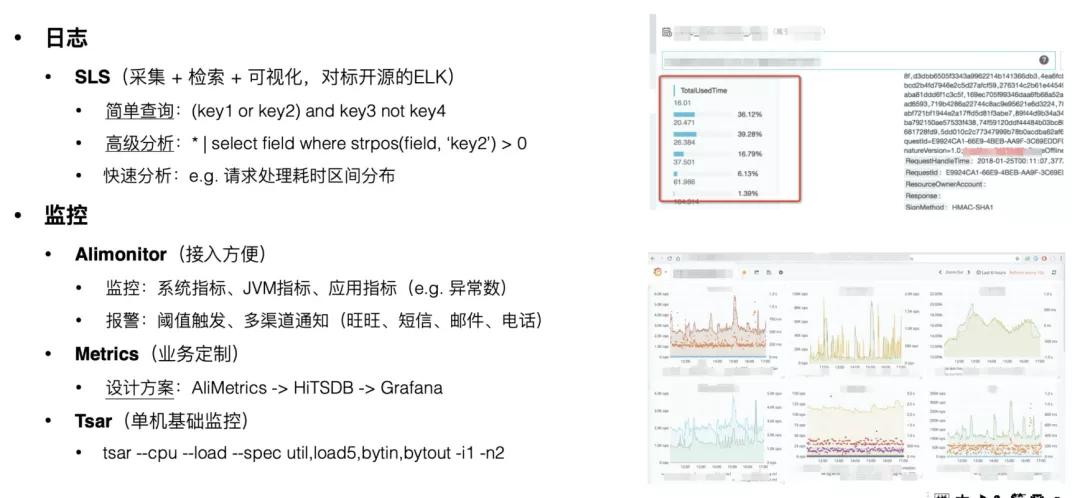
?? 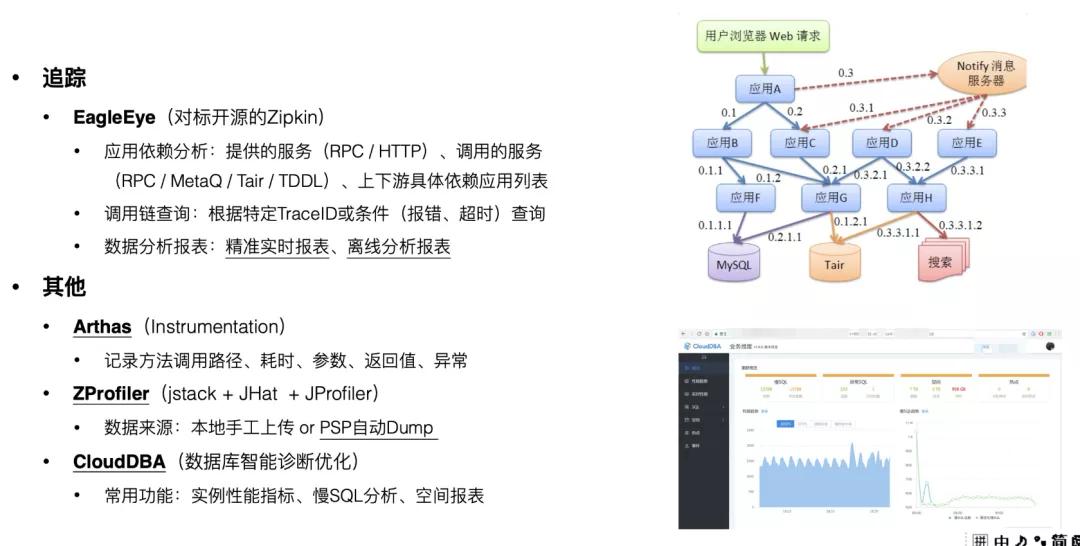
問題排查其實就是一次持續觀測應用行為的過程。為了確保不遺漏關鍵細節,你需要讓自己的應用變得更“可觀測(Observable)。
提升應用可觀測性有三大利器:日志(Logging)、監控(Metrics)、追蹤(Tracing)。在我之前所做的項目中,這三塊能力分別是由 SLS、Alimonitor / AliMetrics / Tsar、EagleEye 提供的,這里就不再展開描述了。
另外也很推薦 Arthas 這個工具,非常實用和順手,相信很多同學都已經用過。
二 系統優化
只學會了問題排查還遠遠不夠(當然技能必須點滿,shit always happen),再熟練也只是治標不治本。如果想從根源上規避問題,必須從系統本身出發:按照性能、穩定性和可維護性三個方向,持續優化你的系統實現,扼殺問題于搖籃之中,讓自己每天都能睡個安穩覺。
老板:既要快,又要穩,還要好。哦,工資的事你別擔心,下個月一定能發出來。
?? 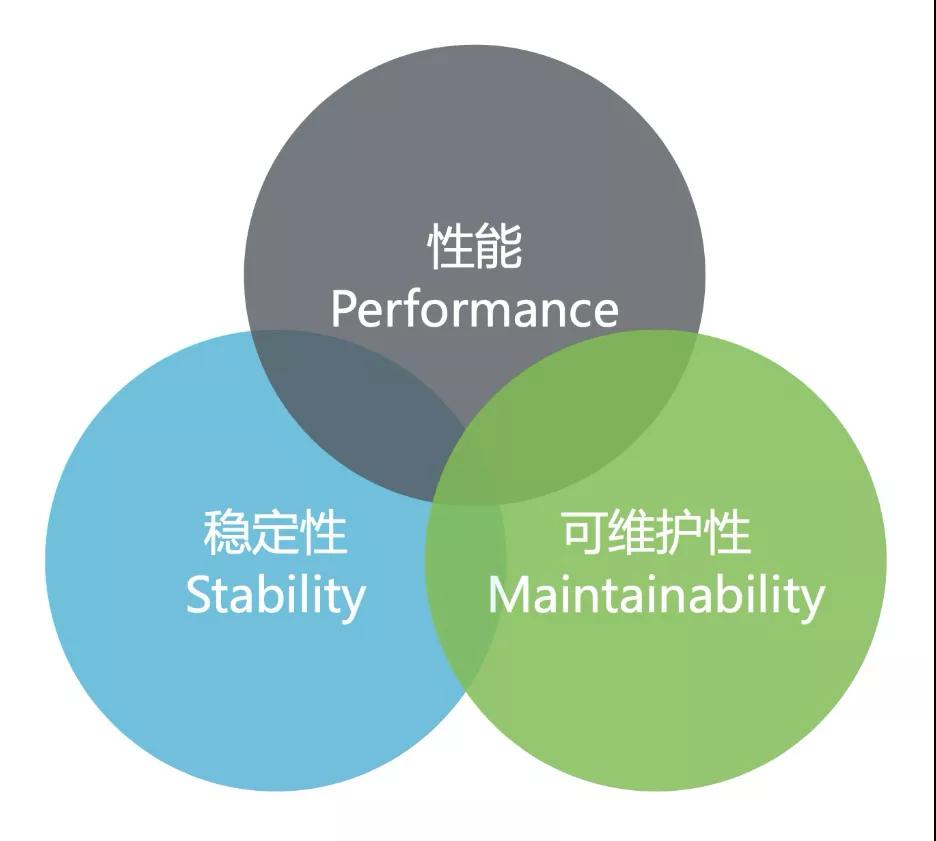
系統優化的三個基本方向:性能(Performance)、穩定性(Stability)、可維護性(Maintainability)。三者之間并不是完全獨立的,而是存在著復雜的相互作用關系,有時甚至會此消彼長。
最優秀的軟件系統,并非要把這三個方向都做到極致,而是會根據自己實際的業務需求和場景合理取舍,在這三者之間達到一個綜合最優的動態平衡狀態,讓各方面都能做到足夠好即可。
所以,優化不只是一門科學,也是一門藝術。
1 性能優化
問:要跑出最快的圈速,是車手重要,還是賽車重要?答:全都重要。
沒有哪個男人會不喜歡高性能跑車,也沒有哪個女人會希望在看李佳琦直播時突然卡頓。
性能,是各行各業工程師們共同追求的終極浪漫。
性能指標
指標(Indicators)是衡量一件事物好壞的科學量化手段。對于性能而言,一般會使用如下指標評估:
- 吞吐率(Throughput):系統單位時間內能處理的工作負載,例如:在線 Web 系統 - QPS/TPS,離線數據分析系統 - 每秒處理的數據量。
- 響應時間(Response Time):以 Web 請求處理為例,響應時間(RT)即請求從發出到收到的往返時間,一般會由網絡傳輸延遲、排隊延遲和實際處理耗時幾個部分共同組成。
- 可伸縮性(Scalability):系統通過增加機器資源(垂直/水平)來承載更多工作負載的能力;投入產出比越高(理想情況是線性伸縮),則說明系統的可伸縮性越好。
此外,同一個系統的吞吐率與響應時間,一般還會存在如下關聯關系:吞吐率小于某個臨界值時,響應時間幾乎不變;一旦超出這個臨界值,系統將進入超載狀態(overloaded),響應時間開始線性增長。對于一個有穩定性要求的系統,需要在做性能壓測和容量規劃時充分考慮這個臨界值的大小。
注:其實按更嚴謹的說法,性能就是單指一個系統有多“快”;上述部分指標并不純粹只代表系統快慢,但也都與快慢息息相關。
性能分析
古人有句老話,If you can't measure it, you can't improve It.
要優化一個系統的性能(例如Web請求響應時間),你必須首先準確地測量和分析出,當前系統的性能究竟差在哪:是請求解析不夠快,還是查詢 DB 太慢?如果是后者,那又是掃描數據條目階段太慢,還是返回結果集太慢?或者會不會只是應用與 DB 之間的網絡延遲太大?
任何復雜請求的處理過程,最終都可以拆解出一系列并行/串行的原子操作。如果只是逮住哪個就去優化哪個,顯然效率不會太高(除非你運氣爆棚)。更合理的做法,應該是堅持 2/8 原則:優先分析和優化系統瓶頸,即當前對系統性能影響最大的原子操作;他們很可能就是 ROI 最高的優化點。
具體該如何去量化分析性能?這里列出了一些工具參考:
- 系統層面:tsar、top、iostat、vmstat
- 網絡層面:iftop、tcpdump、wireshark
- 數據庫層面:SQL explain、CloudDBA
- 應用代碼層面:JProfiler、Arthas、jstack
其中很多工具也是問題排查時常用的診斷工具;畢竟,無論是性能分析還是診斷分析,目的都是去理解一個系統和他所處的環境,所需要做的事情都是相似的。
優化原則
你應該做的:上面已經提了很多,這里再補充一點:性能優化與做功能需求一樣,都是為業務服務的,因此優化時千萬不要忙著自嗨,一定要結合目標需求和應用場景 —— 也許這塊你想做的優化,壓根線上就碰不到;也許那塊很難做的優化,可以根據流量特征做非通用的定制優化。
你不應該做的:即老生常談的提前優化(Premature-optimization)與過度優化(Over-optimization) —— 通常而言(并不絕對),性能優化都不是免費的午餐,優化做的越多,往往可維護性也會越差。
優化手段
常用的性能優化手段有哪些?我這里總結了 8 個套路(最后 1 個是小霸王多合一匯總套路)。
1)簡化
有些事,你可以選擇不做。
- 業務層面:e.g. 流程精簡、需求簡化。
- 編碼層面:e.g. 循環內減少高開銷操作。
- 架構層面:e.g. 減少沒必要的抽象/分層。
- 數據層面:e.g. 數據清洗、提取、聚合。
2)并行
有些事,你可以找人一起做。
方式:單機并行(多線程)、多機并行(分布式)。
優點:充分利用機器資源(多核、集群)。
缺點:同步開銷、線程開銷、數據傾斜。
- 同步優化:樂觀鎖、細粒度鎖、無鎖。
- 線程替代(如協程:Java WISP、Go routines、Kotlin coroutines)。
- 數據傾斜:負載均衡(Hash / RR / 動態)。
3)異步
有些事,你可以放手,不用死等。
方式:消息隊列 + 任務線程 + 通知機制。
優點:提升吞吐率、組件解耦、削峰填谷。
缺點:排隊延遲(隊列積壓)。
- 避免過度積壓:Back-pressure(Reactive思想)。
4)批量
有些事,你可以合起來一起做。
方式:多次單一操作 → 合并為單次批量操作。
案例:TCP Nagel 算法;DB 的批量讀寫接口。
優點:避免單次操作的固有開銷,均攤后總開銷更低。
缺點:等待延遲 + 聚合延遲。
- 減少等待延遲:Timeout 觸發提交,控制延遲上限。
5)時間空間互換
游戲的本質:要么有閑,要么有錢。
空間換時間:避免重復計算、拉近傳輸距離、分流減少壓力。
- 案例:緩存、CDN、索引、只讀副本(replication)。
時間換空間:有時候也能達到“更快”的效果(數據量減少 → 傳輸時間減少)。
- 案例:數據壓縮(HTTP/2 頭部壓縮、Bitmap)。
6)數據結構與算法優化
程序 = 數據結構 + 算法
- 多了解一些“冷門”的數據結構 :Skip list、Bloom filter、Time Wheel 等。
- 一些“簡單”的算法思想:遞歸、分治、貪心、動態規劃。
7)池化 & 局部化
共享經濟 & 小區超市
池化(Pooling):減少資源創建和銷毀開銷。
- 案例:線程池、內存池、DB 連接池、Socket 連接池。
局部化(Localization):避免共享資源競爭開銷。
- 案例:TLB(ThreadLocalBuffer)、多級緩存(本地局部緩存 -> 共享全局緩存)。
8)更多優化手段
- 升級紅利:內核、JRE、依賴庫、協議。
- 調參大師:配置、JVM、內核、網卡。
- SQL 優化:索引、SELECT *、LIMIT 1。
- 業務特征定制優化:e.g. 凌晨業務低峰期做日志輪轉。
- Hybrid 思想(優點結合):JDK sort() 實現、Weex/RN。
2 穩定性優化
穩住,我們能贏。—— by [0 殺 10 死] 正在等待復活的魯班七號
維持穩定性是我們程序員每天都要思考和討論的大事。
什么樣的系統才算穩定?我自己寫了個小工具,本地跑跑從來沒出過問題,算穩定嗎?淘寶網站幾千人維護,但雙十一零點還是經常下單失敗,所以它不穩定嘍?
穩定是相對的,業務規模越大、場景越復雜,系統越容易出現不穩定,且帶來的影響也越嚴重。
?? 
衡量指標
不同業務所提供的服務類型千差萬別,如何用一致的指標去衡量系統穩定性?標準做法是定義服務的可用性(Availability):只要對用戶而言服務“可用”,那就認為系統當前是穩定的;否則就是不穩定。用這樣的方式,采集和匯總后就能得到服務總的可用/不可用比例(服務時長 or 服務次數),以此來監測和量化一個系統的穩定性。
可是,通過什么來定義某個服務當前是否可用呢?這一點確實跟業務相關,但大部分同類業務都可以用類似的方式去定義。例如,對于一般的 Web 網站,我們可以按如下方式去定義服務是否可用:API 請求都返回成功,且頁面總加載時間 < 3 秒。
對于阿里云對外提供的云產品而言,服務可用性是一個更加需要格外重視并持續提升的指標:阿里云上的很多用戶會同時使用多款云產品,其中任何一款產品出現可用性問題,都會直接被用戶的用戶感知和放大。所以,越是底層的基礎設施,可用性要求就越高。關于可用性的更多細節指標和概念(SLI / SLO / SLA),可進一步參考云智能 SLA 了解。
可用性測量
有了上述可用性指標定義后,接下來該如何去準確測量系統的可用性表現?一般有如下兩種方式。
1)探針模擬
從客戶端側,模擬用戶的調用行為。
- 優點:數據真實(客戶端角度)
- 缺點:數據不全面(單一客戶數據)
2)服務端采集
從服務端側,直接分析日志和數據。
優點:覆蓋所有調用數據。
缺點:缺失客戶端鏈路數據。
對可用性數據要求較高的系統,也可以同時運用上述兩種方式,建議結合你的業務場景綜合評估選擇。
優化原則
你應該做的:關注 RT 的數據分布(如:p50/p99/p999 分位點),而不是平均值(mean) —— 平均值并沒有太大意義,更應該去關注你那 1%、0.1% 用戶的準確感受。
你不應該做的:不要嘗試承諾和優化可用性到 100% —— 一方面是無法實現,存在太多客觀不可控因素;另一方面也沒有意義,客戶幾乎關注不到 0.001% 的可用性差別。
優化手段
常用的穩定性優化手段有哪些?這里也總結了 8 個套路:
1)避免單點
父母:一個人在外漂了這么多年,也該找個人穩定下來了。
如何避免?
- 集群部署
- 數據副本
- 多機房容災
只堆量不夠,還需要具備故障轉移能力(Failover)。
- 接入層:DNS、VipServer、SLB。
- 服務層:服務發現 + 健康檢查 + 剔除機制。
- 應用層:無狀態設計(Stateless),便于隨時和快速切換。
2)流控/限流
計劃生育、上學調劑、車牌限號、景區限行... 人生處處被流控。
- 類型:QPS 流控、并發度流控。
- 工具:RateLimiter、信號量、Sentinel。
- 粒度:全局、用戶級、接口級。
- 熱點流控:避免意料之外的突增流量。
3)熔斷
上午買的股票熔斷,晚上家里保險絲熔斷... 淡定,及時止損而已。
- 目的:防止連鎖故障(雪崩效應)。
- 工具:Hystrix、Failsafe、Resilience4j。
- 功能:自動繞開異常服務并檢測恢復狀態。
- 流程:關閉 → 打開 → 半開。
4)降級
沒時間做飯了,今天就吃外賣吧... 對于健康問題,還是得少一點降級。
觸發原因:流控、熔斷、負載過高。
常見降級方式:
- 關閉非核心功能:停止應用日志打印
- 犧牲數據時效性:返回緩存中舊數據
- 犧牲數據精確性:降低數據采樣頻率
5)超時/重試
釘釘不回怎么辦?每 10 分鐘 ping 一次,超過 1 小時打電話。
- 超時:避免調用端陷入永久阻塞。
- 超時時間設置:全鏈路自上而下規劃
Timeout vs. Deadline:使用絕對時間會更好
重試:確保可重試操作的冪等性。
- 消息去重
- 異步重試
- 指數退避
6)資源設限
雙 11 如何避免女友敗家?提前把自己信用卡額度調低。
- 目的:防止資源被異常流量耗盡
- 資源類型:線程、隊列、DB 連接
- 設限方式:資源池化、有界隊列
- 超限處理:返回 ServiceUnavailable / QuotaExceeded
7)資源隔離
雙 12 女友還是要敗家?得嘞刷你自個的卡吧,別動我的。
- 目的:防止資源被部分異常流量耗盡;為 VIP 客戶提供服務質量保證(QoS)。
- 隔離方式:隊列劃分、獨立集群;注意處理優先級和資源分配比例。
8 )安全生產
女友哭著說再讓我最后剁一次手吧?安全第一,寧愿心疼也不要肉疼。
程序動態性:開關、配置、熱升級。
- Switch:類型安全;侵入性小。
審核機制:代碼 Review、發布審批。
灰度發布;分批部署;回滾預案。
- DUCT:自動/手動調整 HSF 節點權重。
3 可維護性優化
前人栽樹,后人乘涼。
前人挖坑,后人涼涼。
維護的英文是 maintain,也能翻譯成:維持、供給。所以軟件維護能有多重要?它就是軟件系統的呼吸機和食物管道,維持軟件生命的必要供給。
系統開發完成上線,不過只是把它“生”下來而已。軟件真正能發揮多大價值,看的是交付后持續的價值兌現過程 —— 是不斷茁壯成長,為用戶發光發熱?還是慢慢墮落,逐漸被用戶所遺忘?這并不是取決于它當下瞬時是否足夠優秀(性能)和靠譜(穩定),而是取決于未來 —— 能否在不斷變化的市場環境、客戶需求和人為因素中,始終保持足夠優秀和靠譜,并且能越來越好。
相比性能和穩定性而言,可維護性所體現的價值往往是最長遠、但也最難在短期內可兌現的,因此很多軟件項目都選擇了在前期犧牲可維護性。這樣決策帶來的后果,就跟架構設計一樣,是幾乎無法(或者需要非常高的成本)去彌補和挽回的。太多的軟件項目,就是因為越來越不可維護(代碼改不動、bug 修不完、feature 加不上),最后只能慢慢淪落為一個誰都不想碰的遺留項目。
衡量指標
相比性能和穩定性而言,可維護性確實不太好量化(藝術成分 > 科學成分)。這里我選取了幾個偏定性分析的指標:
1)復雜度(Complexity):是否復雜度可控?
- 編碼:簡潔度、命名一致性、代碼行數等。
- 架構:組件耦合度、層次清晰度、職責單一性等。
2)可擴展性(Extensibility):是否易于變更?
- 需要變更代碼或配置時,是否簡單優雅、不易出錯。
3)可運維性(Operability):是否方便運維?
- 日志、監控是否完善;部署、擴容是否容易。
重要性
這里給了幾個觀點,進一步強調可維護性的重要性。
- 軟件生命周期:維護周期 >> 開發周期。
- 破窗效應、熵增定律:可維護性會趨向于越來越差。
- 遺留系統的危害:理解難度,修改成本,變更風險;陷入不斷踩坑、填坑、又挖坑的循環。
優化原則
你應該做的:遵循 KISS 原則、DRY 原則、各種代碼可讀性和架構設計原則等。
你不應該做的:引入過多臨時性、Hack 代碼;功能 Work 就 OK,欠一堆技術債(出來混總是要還的)。
優化手段
常用的可維護性優化手段有哪些?這里我總結了 4 個套路:
1)編碼規范
無規矩,不成方圓。
- 編碼:推薦《Java 開發手冊》,另外也推薦 The Art of Readable Code 這本書。
- 日志:無盲點、無冗余、TraceID。
- 測試:代碼覆蓋度、自動化回歸。
2)代碼重構
別灰心,代碼還有救。
何時重構:任何時候代碼中嗅到壞味道(bad smell)。
重構節奏:小步迭代、回歸驗證。
重構 vs. 重寫:需要綜合考慮成本、風險、并行版本維護等因素。
推薦閱讀:Refactoring: Improving the Design of Existing Code。
3)數據驅動
相信數據的力量。
- 系統數據:監控覆蓋、Metrics 采集等,對于理解系統、排查問題至關重要。
- 業務數據:一致性校驗、舊數據清理等;要相信,數據往往比代碼要活得更久。
4)技術演進
技術是第一生產力。
- 死守陣地 or 緊跟潮流? 需要綜合評估風險、生產力、學習成本。
- 當前方向:微服務化、容器化。
三 結語
Truth lies underneath the skin - 真理永遠暗藏在表象底下。
對,就在這句話底下。
歡迎各位技術同路人加入阿里云云原生應用研發平臺 EMAS 團隊,我們專注于廣泛的云原生技術(Backend as a Service、Serverless、DevOps、低代碼平臺等),致力于為企業、開發者提供一站式的應用研發管理服務,內推直達:pengqun.pq # alibaba-inc.com,有信必回。














