













機器學習的中流砥柱:用于模型構建的基礎架構工具有哪些?
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
人工智能(AI)和機器學習(ML)已然“滲透”到了各行各業,企業們期待通過機器學習基礎架構平臺,以推動人工智能在業務中的利用。
理解各種平臺和產品算得上是一項挑戰。機器學習基礎架構空間擁擠、混亂又復雜。許多平臺和工具涵蓋了整個模型構建工作流程的多種功能。
為了理解其生態,我們可將機器學習工作流程大致分為三個階段:數據準備,模型構建和生產。了解工作流各個階段的目標和挑戰有助于人們正確地選出最適合企業業務需求的機器學習基礎架構平臺。

機器學習基礎架構平臺圖
機器學習工作流程的每個主要階段都具有許多垂直功能。其中一些功能是較大的端到端平臺的一部分內容,還有一些功能則是某些平臺的主要關注點。
本文將帶你走進機器學習的第二階段——模型構建。
什么是模型構建?
模型構建的第一步從了解業務需求開始。模型需要處理哪些業務需求?
這一步驟在機器學習工作流程的計劃和構想階段展開。在此階段,與軟件開發生命周期類似,數據科學家收集需求,考慮可行性,并為數據準備、模型構建和生產制定計劃。他們還使用數據來探索各種模型構建實驗,這些實驗是在計劃階段所考慮的。
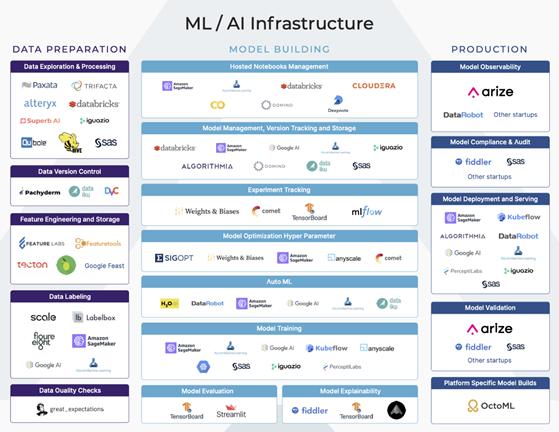
機器學習基礎架構平臺圖
特征探索和選擇
數據科學家探索各種數據輸入選項以選擇特征,是該實驗過程的一部分。特征選擇是為機器學習模型查找特征輸入的過程。
對于新模型,理解可用的數據輸入、輸入的重要性以及不同特征之間的關系可能是一個漫長的過程。在這里,可以對更易解釋的模型、更短的訓練時間、特征獲取的成本以及過度擬合的減輕做出許多決策。找出正確且合適的特征是一個連續不斷的迭代過程。
- 在特征提取方面的機器學習基礎架構公司有:Alteryx/ Feature實驗室、Paxata(DataRobot)。
模型管理
數據科學家可以嘗試多種建模方法。對于某些任務,一些類型的模型比其他模型更適用(例如,基于樹的模型解釋性更佳)。
作為構思階段的一部分,該模型是監督、無監督、分類或回歸等都是顯而易見的。但建模方法、超參數以及特征的選擇取決于實驗。
一些自動機器學習(AutoML)平臺會嘗試附帶各種參數的不同模型,這有助于建立基線方法。即使手動完成,探索各種選項也可以為模型構建者提供有關模型可解釋性的見解。
實驗跟蹤
盡管各種類型的模型之間有許多優點和折衷點,但通常來說,此階段涉及許多實驗。許多平臺可以跟蹤這些實驗、建模依賴和模型存儲。這些功能可被大致歸為模型管理。
一些平臺主要關注實驗跟蹤。其他一些具有訓練或服務組件的公司擁有模型管理組件,用于比較各種模型的性能,跟蹤訓練/測試數據集,調整和優化超參數,存儲評估指標以及實現詳細的沿襲和版本控制。
與用于軟件的Github相似,這些模型管理平臺應能實現版本控制、歷史沿襲和可重復性。
各種模型管理平臺之間的折衷在于集成成本。一些更輕量級的平臺雖然僅提供實驗跟蹤,但可以輕松地與當前環境集成,并導入到數據科學notebook中。其他一些平臺則需要進行更繁重的集成,并且需要模型構建者轉移至其平臺上,以便進行集中的模型管理。
在機器學習工作流程的這一階段,數據科學家通常要花時間在notebook中建立、訓練模型,將模型權重存儲在模型庫中,然后在驗證集上評估模型結果。
這一階段有許多平臺提供訓練所需的計算資源。根據團隊存儲模型對象的不同方式,模型還具備許多存儲選項。
- 機器學習基礎架構AutoML:H20、SageMaker、DataRobot、Google Cloud ML、MicrosoftML
- 模型管理方面的機器學習基礎架構公司:Domino Data Labs、SageMaker
- 超參數選項方面的機器學習基礎架構公司:Sigopt、Weightsand Biases、SageMaker
- 實驗跟蹤方面的機器學習基礎架構公司:權重和偏差、Comet ML、MLFlow、Domino、Tensorboard
模型評估
一旦實驗模型在具有選定特征的訓練數據集上經過訓練,就可以在測試集上進行評估了。
在這一階段,數據科學家試圖了解模型的性能以及需要改進的地方。一些更高級的機器學習團隊擁有自動回測框架,可供其利用歷史數據來評估模型性能。
每個實驗都試圖擊敗或超越基準模型的性能,并考慮如何對計算成本、可解釋性和歸納能力做出權衡。在一些更規范的行業中,此評估過程還可以包括外部審核員執行的合規性和審核,以確保模型的可重復性、性能和需求。
- 用于模型評估的機器學習基礎工具/架構:Fiddler AI、Tensorboard、Stealth Startups
- 用于試生產驗證的機器學習基礎架構:Fiddler AI、ArizeAI
管理以上所有任務的平臺
許多以AutoML或模型構建為中心的公司只選定一個平臺,用以處理一切事物。因此許多平臺爭相成為公司在數據準備、模型構建和生產中使用的唯一人工智能平臺,這樣的公司有DataRobot、H20、SageMaker等。
該集合分為低代碼解決方案和以開發人員為中心的解決方案。Datarobot公司似乎專注于無代碼/低代碼選項,該選項允許商務智能(businessintelligence, BI)或財務(Finance)團隊從事數據科學項目。
這與SageMaker和H20公司形成鮮明對比,它們似乎迎合了當今更為常見的數據科學組織——數據科學家或開發者第一團隊。
這兩種情況下的市場都很大,并且可以共存,但值得注意的是,并非所有的機器學習基礎架構公司都向相同的人或團隊出售產品。
近期,該領域中的許多新成員可以被視為機器學習基礎架構食物鏈中特定部分的優秀解決方案。比較好的模擬將是軟件工程領域,其軟件解決方案GitHub、集成開發環境(IDE)以及生產監控并非都是相同的端到端系統。
它們是不同的軟件,這一點并非空穴來風,它們提供了迥然不同的功能,并且具有明顯的區別。
挑戰
與軟件開發并行不同的是,由于缺乏對模型所訓練數據的版本控制,模型的可重復性通常被視為一個挑戰。
在理解模型的性能方面存在許多挑戰。如何比較實驗并確定哪種模型版本是性能和折衷的優質平衡?稍差的模型是一種折衷方案,但它更易于解釋。一些數據科學家使用內置的模型可解釋性特征或使用SHAP/ LIME,來探索特征的重要性。
另一性能挑戰是不知道實驗階段的模型性能如何轉化到現實世界中。
通過確保訓練數據集中的數據是模型在生產中可能看到的數據的代表性分布,以防止過度擬合訓練數據集,可以很大程度地緩解這種情況。這是交叉驗證和回測框架發揮作用之處。
接下來發生了什么?
對數據科學家來說,確定何時將模型投入生產的標準是很重要的。如果生產環境中已部署了預先存在的模型,則可能是新版本的性能更高的時候。無論如何,設置標準對于將實驗轉移至實際環境中至關重要。
一旦模型受過訓練,模型圖像/權重將存儲在模型庫中。這時,負責將模型部署到生產中的數據科學家或工程師通常可以獲取模型并用于服務。
在一些平臺上,該部署甚至可以更簡單,并且可以使用外部服務能調用的RESTAPI來配置已部署的模型。



















