如何拿下SQL面試?這些技巧和陷阱應(yīng)該要知道……
SQL是數(shù)據(jù)分析和處理最基本的編程語言之一,因此,無論是面試數(shù)據(jù)分析師、數(shù)據(jù)科學(xué)家、數(shù)據(jù)工程師,還是其他相關(guān)工作,都免不了要過這一關(guān)。
實(shí)戰(zhàn)技術(shù)和解決問題的能力是SQL面試中考察的重點(diǎn),應(yīng)聘者不僅要基于示例數(shù)據(jù)編寫正確的查詢,還要考慮各種場(chǎng)景和邊緣情況,就如同在處理實(shí)際數(shù)據(jù)集。
筆者曾經(jīng)幫助求職者設(shè)計(jì)過SQL面試問題,并模擬了面試,也多次親身參加了大型科技公司和初創(chuàng)企業(yè)SQL求職面試的實(shí)戰(zhàn)。本文將對(duì)SQL面試問題的常見模式進(jìn)行闡釋,分享在SQL查詢中靈活處理這些模式的技巧。
快掏出小本本開始學(xué)習(xí)吧~
提問
要拿下一場(chǎng)SQL面試,最重要的在于盡可能多地提問,以確保自己掌握了給定任務(wù)和數(shù)據(jù)樣本的所有細(xì)節(jié)。理解這些需求有助于節(jié)省迭代問題的時(shí)間,也有助于更好地處理邊緣情況。
許多應(yīng)聘者會(huì)在沒有深入理解SQL問題或數(shù)據(jù)集之前,直接開始解決問題。在筆者指出解決方案中的問題之后,他們不得不反復(fù)修改查詢,在迭代上浪費(fèi)了大量時(shí)間,甚至到最后都沒找到正確的解決方案。
筆者的建議是將SQL面試視為在與業(yè)務(wù)合作伙伴一起工作,保持這種心態(tài),面試者就會(huì)在提供解決方案之前努力收集數(shù)據(jù)請(qǐng)求的所有需求。
示例
從下表中找出薪資最高的三位職員。
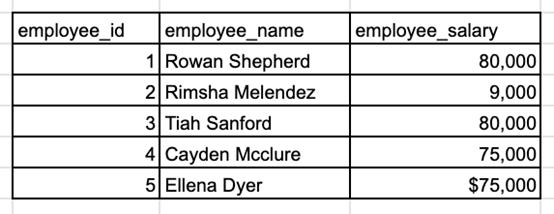
樣本:職員薪資表
面試者應(yīng)該讓面試官仔細(xì)闡述“前三名”的概念——結(jié)果中必須只有三名職員嗎?對(duì)于并列的處理有何要求?此外,面試者應(yīng)仔細(xì)查看示例職員的數(shù)據(jù)——薪資字段的數(shù)據(jù)類型是什么?需要在計(jì)算之前清除數(shù)據(jù)嗎?
何種連接
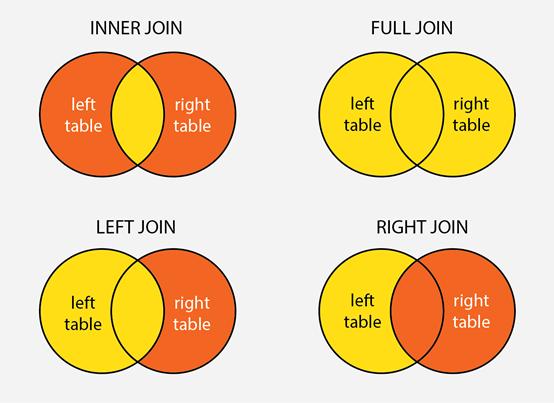
在SQL中,連接經(jīng)常用于組合來自多個(gè)表的信息。共有四種不同類型的連接,但是在大多數(shù)情況下,我們只使用自然連接、左連接和全連接,因?yàn)橛疫B接并不直觀,而且使用左連接很容易重寫。在SQL面試中,面試者需要根據(jù)給定問題的特定要求,選擇正確的連接。
示例
找出每位學(xué)生上課的總節(jié)數(shù)。(已知學(xué)生證、姓名和上課次數(shù)。)

樣本:學(xué)生名單和課程數(shù)據(jù)表
可以注意到,并非所有出現(xiàn)在課程數(shù)據(jù)表中的學(xué)生都存在于學(xué)生名單中,這可能是因?yàn)檫@些學(xué)生已經(jīng)畢業(yè)(這在事務(wù)數(shù)據(jù)庫(kù)中非常典型,數(shù)據(jù)不活躍時(shí)就會(huì)被刪除)。在了解清楚面試官是否希望將不活躍的學(xué)生包括在內(nèi)之后,可以根據(jù)情況使用左連接和自然連接兩種方式來合并表格。
- WITHclass_count AS (
- SELECT student_id, COUNT(*) ASnum_of_class
- FROM class_history
- GROUP BY student_id
- )
- SELECT
- c.student_id,
- s.student_name,
- c.num_of_class
- FROM class_count c
- -- CASE 1: include only active students
- JOIN student s ON c.student_id = s.student_id-- CASE 2: include all students
- -- LEFT JOIN student s ON c.student_id = s.student_id
GROUP BY
GROUP BY是SQL中最基本的函數(shù),廣泛用于數(shù)據(jù)聚合。如果在一個(gè)SQL問題中出現(xiàn)了sum、average、minimum或maximum等關(guān)鍵字,則極有可能應(yīng)該在查詢中使用GROUP BY。一個(gè)常見的陷阱是,在用GROUP BY過濾數(shù)據(jù)時(shí)將WHERE和HAVING混淆——許多人都犯過這個(gè)錯(cuò)誤。
示例
計(jì)算每個(gè)學(xué)生每學(xué)年的必修課平均績(jī)點(diǎn),并找出每學(xué)期中績(jī)點(diǎn)≥3.5的學(xué)生。
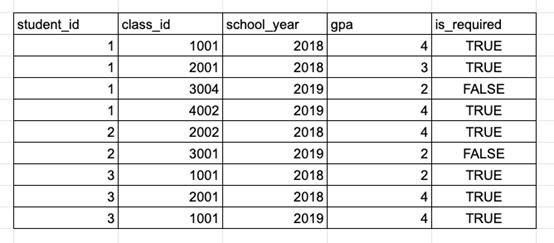
樣本:GPA數(shù)據(jù)表
在計(jì)算GPA時(shí)只考慮必修課,因此需要使用 WHERE is_required = TRUE來排除選修課。需要計(jì)算每個(gè)學(xué)生每學(xué)年的平均績(jī)點(diǎn),因此需要用GROUP BY命令按student_id 和school_year 兩列來進(jìn)行分組,并取gpa的平均值。最后,只保留平均GPA高于3.5的行,這可以通過HAVING實(shí)現(xiàn)。再將以上所得進(jìn)行結(jié)合:
- SELECT
- student_id,
- school_year,
- AVG(gpa) AS avg_gpa
- FROM gpa_history
- WHERE is_required = TRUE
- GROUP BY student_id, school_year
- HAVING AVG(gpa) >= 3.5
記住,無論何時(shí)在查詢中使用GROUP BY,都只能選擇要分組的列,然后進(jìn)行聚合,因?yàn)槠渌兄械男屑?jí)信息已被丟棄。
可能有人想知道WHERE和HAVING之間有什么區(qū)別,或者想知道為什么不直接用avg_gpa>= 3.5,而是指定函數(shù)。下一節(jié)將會(huì)給出詳細(xì)解釋。
SQL查詢語句執(zhí)行順序
在寫SQL查詢時(shí),大多數(shù)人是按照自上而下的順序,但他們可能并不知道SELECT是SQL引擎最后執(zhí)行的函數(shù)之一。以下是SQL查詢的執(zhí)行順序:
- FROM, JOIN
- WHERE
- GROUP BY
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- LIMIT, OFFSET
回頭再看前面的示例。因?yàn)樾枰谟?jì)算平均績(jī)點(diǎn)之前過濾掉選修課,所以可以用 WHERE is_required = TRUE來代替HAVING,因?yàn)閃HERE在GROUP BY和HAVING之前執(zhí)行。不用HAVINGavg_gpa >= 3.5的原因是avg_gpa被定義為SELECT的一部分,所以不能在SELECT之前執(zhí)行的步驟中引用。
圖源:unsplash
筆者建議在編寫查詢時(shí)按照?qǐng)?zhí)行順序編寫,這在編寫復(fù)雜查詢時(shí)非常有用。
窗口函數(shù)
窗口函數(shù)也經(jīng)常出現(xiàn)在SQL面試中。五種常見的窗口函數(shù)如下:
- RANK /DENSE_RANK /ROW_NUMBER:通過對(duì)特定列排序,為每行分配一個(gè)秩。如果給定了任何分區(qū)列,則行將在其所屬的分區(qū)組中排列。
- LAG /LEAD:根據(jù)指定的順序和分區(qū)組從前一行或后一行檢索列值。
在SQL面試中,面試者必須知道排名函數(shù)之間的差異,以及何時(shí)使用LAG/LEAD。
示例
找出每個(gè)部門中薪資最高的3名職員。
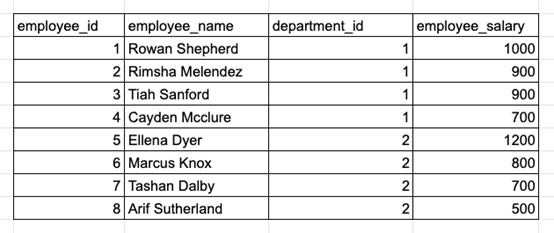
樣本:職員薪資表2
當(dāng)SQL問題要求找出“前N名”時(shí),可以使用ORDER BY或ranking函數(shù)來回答。但以上示例要求計(jì)算“每個(gè)Y中的前N 個(gè)X”,這代表著面試者應(yīng)該使用排ranking函數(shù),因?yàn)樾枰獙?duì)每個(gè)分區(qū)組中的行進(jìn)行排列。
下面的查詢能準(zhǔn)確找到3名薪資最高的職員,不考慮并列:
- WITH TAS (
- SELECT
- *,
- ROW_NUMBER() OVER (PARTITION BYdepartment_id ORDER BY employee_salary DESC) AS rank_in_dep
- FROM employee_salary)
- SELECT * FROM T
- WHERE rank_in_dep <= 3-- Note: When using ROW_NUMBER, each row will have aunique rank number and ranks for tied records are assigned randomly. Forexmaple, Rimsha and Tiah may be rank 2 or 3 in different query runs.
另外,根據(jù)面試官對(duì)并列情況處理的要求,面試者也可選擇不同的ranking函數(shù)。再次提醒大家,細(xì)節(jié)很重要!
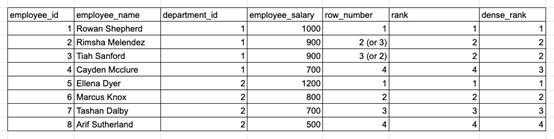
ROW_NUMBER、RANK和 DENSE_RANK 三種函數(shù)的對(duì)比。
重復(fù)項(xiàng)
SQL面試中的另一個(gè)常見陷阱是忽略重復(fù)項(xiàng)。盡管有些列在示例數(shù)據(jù)中似乎具有不同的值,但面試者還是應(yīng)該考慮所有可能的情況,就像在處理真實(shí)的數(shù)據(jù)集一樣。例如,在上例的員工薪資表中,不同職員可能出現(xiàn)同名情況。
想要避免重復(fù)項(xiàng)引起的潛在問題,一個(gè)簡(jiǎn)單的方法是始終使用ID列來標(biāo)識(shí)不同的記錄,避免重復(fù)。
示例
根據(jù)職員薪資表,找出所有部門每個(gè)職員的總工資。
正確的解決方案是按employee_id 來分組,使用SUM(employee_salary)來計(jì)算總薪資。如果需要員工姓名,可在末尾加入職員表格來檢索職員的姓名信息。
用employee_name來分組是錯(cuò)誤的。
NULL
在SQL中,任何謂詞都可能產(chǎn)生以下三個(gè)值之一:true、false和NULL。NULL這一關(guān)鍵詞用于指代未知或空缺數(shù)據(jù)。處理NULL可能會(huì)非常棘手。在SQL面試中,面試官會(huì)特別注意面試者在解決過程中是否處理了NULL。在一些情況下,很明顯某列數(shù)據(jù)不能為空值(例如ID列),但大多數(shù)其他的列很可能會(huì)出現(xiàn)NULL。
筆者建議面試者確認(rèn)示例數(shù)據(jù)中的關(guān)鍵列是否可以為空值,如果可以,則可以使用IS (NOT) NULL、IFNULL和COALESCE 等函數(shù)來覆蓋這些邊緣情況。
溝通
另外很重要的一點(diǎn)在于——在面試過程中保證流暢的溝通。
在筆者面試過的求職者中的很多人,除非真的有問題,否則幾乎不說話。如果他們能在最后給出完美的解決方案,那倒也沒什么大問題,但在技術(shù)面試中保持與面試者的溝通通常會(huì)有所助益。例如,面試者可以談?wù)撟约簩?duì)問題和數(shù)據(jù)的理解、自己是如何計(jì)劃解決問題的、使用這個(gè)函數(shù)而不是另外一個(gè)的原因、或者正在考慮的邊緣情況。
總結(jié)
- 先提問,收集所需的詳細(xì)信息。
- 謹(jǐn)慎選擇連接方式——自然連接,左連接還是全連接。
- 使用GROUP BY聚合數(shù)據(jù),合理使用WHERE和HAVING。
- 了解三個(gè)ranking函數(shù)之間的差異。
- 了解何時(shí)使用LAG/LEAD窗口功能。
- 如果需要?jiǎng)?chuàng)建的查詢太過復(fù)雜,嘗試按照SQL執(zhí)行順序編寫。
- 考慮潛在的數(shù)據(jù)問題,如重復(fù)項(xiàng)和空值。
- 與面試官溝通思維過程。
面試順利沖鴨!