百萬TPS高吞吐、秒級低延遲,阿里搜索離線平臺如何實現?
阿里主搜(淘寶天貓搜索)是搜索離線平臺非常重要的一個業務,具有數據量大、一對多的表很多、源表的總數多和熱點數據等特性。對于將主搜這種邏輯復雜的大數據量應用遷移到搜索離線平臺總是不缺少性能的挑戰,搜索離線平臺經過哪些優化最終實現全量高吞吐、增量低延遲的呢?
作者簡介:王偉駿,花名鴻歷,阿里巴巴搜索推薦事業部高級開發工程師。2016年碩士畢業于南京郵電大學。Apache Hadoop && Flink && Eagle Contributor。目前負責阿里巴巴搜索離線平臺Runtime層相關工作。
另外,陳華曦(昆侖)給了本文很多建議,文中部分圖由李國鼎(石及)貢獻。
前言
在阿里搜索工程體系中我們把搜索引擎、在線算分等ms級響應用戶請求的服務稱之為“在線”服務;與之相對應的,將各種來源數據轉換處理后送入搜索引擎等“在線”服務的系統統稱為“離線”系統。搜索離線平臺作為搜索引擎的數據提供方,是集團各業務接入搜索的必經之路,也是整個搜索鏈路上極為重要的一環,離線產出數據的質量和速度直接影響到下游業務的用戶體驗。
搜索離線平臺經過多年沉淀,不僅承載了集團內大量搜索業務,在云上也有不少彈外客戶,隨著平臺功能的豐富,Blink(阿里內部版本的Flink) 版本的領先。我們在2019年年初開始計劃把主搜(淘寶天貓搜索)遷移到搜索離線平臺上。
主搜在遷移搜索離線平臺之前的架構具有架構老化、Blink版本低、運維困難、計算框架不統一等不少缺點,隨著老主搜人員流失以及運維難度與日俱增,重構工作早已迫上眉睫。
對于將主搜這種邏輯復雜的X億數據量級應用遷移到搜索離線平臺總是不缺少性能的挑戰,業務特點與性能要求決定了主搜上平臺的過程中每一步都會很艱辛。為了讓性能達到要求,我們幾乎對每個Blink Job都進行了單獨調優,最初的理想與最后的結局都是美好的,但過程卻是極其曲折的,本文將主要介紹主搜在遷移搜索離線平臺過程中在性能調優方面具體做了哪些嘗試。
主搜遷移搜索離線平臺的完成對于平臺來說有里程碑式的意義,代表搜索離線平臺有能力承接超大型業務。
搜索離線平臺基本概念
搜索離線平臺處理一次主搜全增量主要由同步層和數據處理層組成,它們又分別包括全量和增量流程。為了讀者更好理解下文,先簡單介紹幾個關于搜索離線平臺的基本概念。
集團內支撐業務
目前搜索離線平臺在集團內支持了包括主搜,AE在內的幾百個業務。其中數據量最大的為淘寶天貓評價業務,數據量達到了X百億條,每條數據近上X個字段。
?? 
場景
處理用戶的數據源(mysql或odps)表,將數據經過一系列的離線處理流程,最終導入到Ha3在線搜索引擎或ES中。
?? 
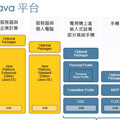
平臺相關技術棧
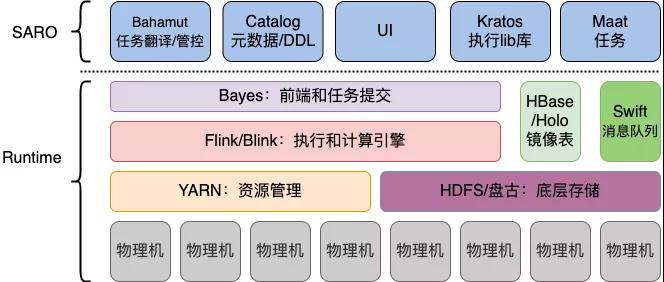
如下圖,搜索離線平臺目前數據存儲基于HDFS/盤古,資源調度依賴于YARN或Hippo,計算框架統一用Flink/Blink執行。
?? 
全量
全量是指將搜索業務數據全部重新處理生成,并傳送給在線引擎,一般是每天一次。
這么做有兩個原因:有業務數據是Daily更新;引擎需要全量數據來高效的進行索引整理和預處理,提高在線服務效率。全量主要分為同步層與數據處理層。
?? 
增量
增量是指將上游數據源實時發生的數據變化更新到在線引擎中。
這也就意味著在我們的場景中對于增量數據不需要保證Exactly Once語義,只需要保證At Least Once語義。基于該背景,我們才能用全鏈路異步化的思維來解一對多問題(下文會詳細講解)。
與全量一樣,增量也分為同步層與數據處理層。
?? 
一對多
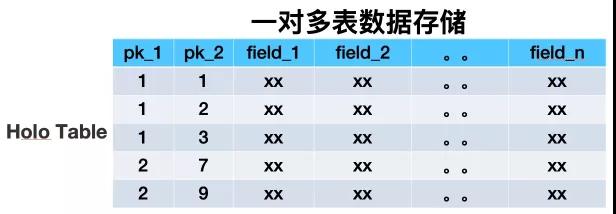
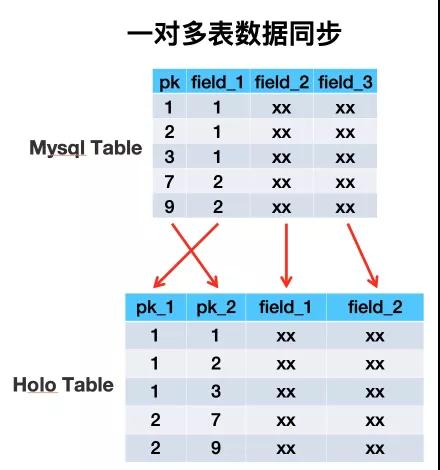
在搜索這個領域某些業務數據需要用一對多的形式來描述,比如商品寶貝和SKU的關系即是個典型的一對多數據的例子。在搜索離線基于Hologres(阿里巴巴自研分布式數據庫)存儲的架構中,一對多的數據存儲在單獨的一張雙pk的HoloTable中,第一、二主鍵分別的寶貝ID與SKU_ID。
有了上面這些概念之后,在后續的段落中我們會看到搜索離線平臺針對主搜各Blink Job的性能調優,先簡要概括下主搜業務特點與性能要求。
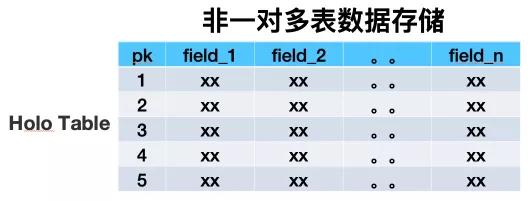
數據存儲方式
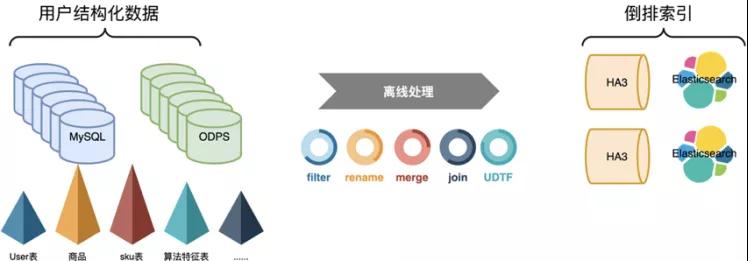
搜索離線平臺以前用HBase做鏡像表時,是用一張多列族大寬表來存儲業務單維度所有數據。經過詳細調研之后,我們決定用Hologres替換HBase,所以需要對存儲架構做全面的重構。用多表來模擬HBase中的多列族,單HoloTable中包括很多業務數據源表的數據。重構后的數據存儲方式大致如下:
?? 
?? 
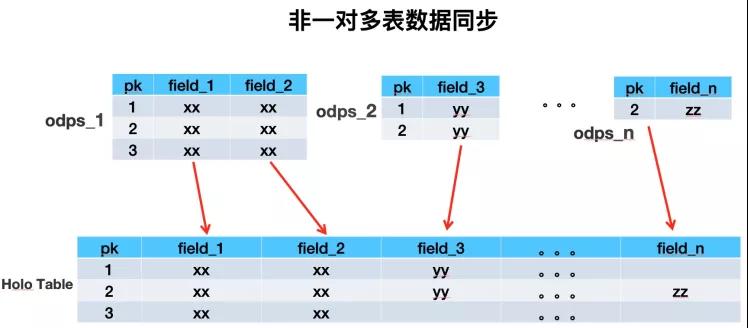
同步層
所謂同步層,一般是將上游數據源的數據同步到鏡像表,供數據處理層高效處理。由于業務方單維度的數據有很多Mysql表或odps表組成,少則X張,多則像主搜這樣X張。所以將同緯度數據聚合到一張Holo表中時,如果多張表兩兩join的話會產生大量shuffle,所以我們采取異步upsert方式,不同數據源表的數據寫Holo表中不同的列來解決海量數據導入問題。
?? 
?? 
數據處理層
所謂數據處理層,是指將同步層得到的各鏡像表(HBase/Holo)的數據進行計算,一般包括多表Join、UDTF等,以方便搜索業務的開發和接入。
主搜業務特點與性能要求
下面首先介紹下主搜業務特點與性能要求,再詳細介紹我們進行了怎樣的調優才達到了性能的要求。
主搜業務特點
- 數據量大
主搜有X億(有效的X億)個商品,也就是主維度有X億條數據,相比于平臺其他業務(除淘寶評價業務)多出X個數量級。這么多數據我們能否在X個多小時完成全量?如何實現高吞吐?挑戰非常大。
- 一對多的表很多
主搜業務有很多一對多的表需要Join,例如一個商品對應多個SKU,部分商品對應了接近X個SKU信息。這些信息如何能夠高性能的轉換為商品維度,并與商品信息關聯?
- 源表的總數多
主搜有X多張表(包括一對多的表),平臺其他業務的源表個數一般都在個位數。源表數量多會導致一系列的問題,比如讀取ODPS數據時如何避免觸發ODPS的限制?拉取大表數據時如何做到高吞吐?這些問題都需要我們一一解決。
- 熱點數據
主搜有一些大賣家(餓了么,盒馬等)對應了很多商品,導致在數據處理層出現非常嚴重的數據傾斜等問題。如何解決大數據處理方向經常出現的SKEW?
主搜性能要求
- 全量(同步層 + 數據處理層)高吞吐!
全量要求每天一次,在有限的資源情況下每次處理X億的商品,這么大的數據量,如何實現高吞吐,挑戰非常大!
- 增量(同步層 + 數據處理層)低延遲!
增量要在Tps為X W的情況下達到秒級低延遲,并且雙11期間有部分表(例如XX表)的Tps能達到X W,增量如何保證穩定的低延遲?值得思考!
下面一一描述我們是如何解決這些問題來達到性能要求的。
Blink Job性能調優詳解
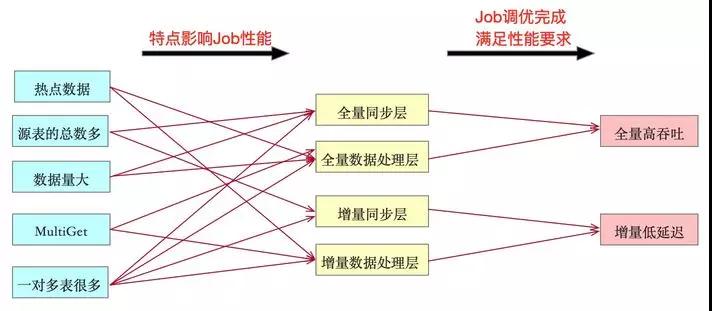
根據上述主搜業務特點與性能要求羅列出下圖,左邊與中間兩列表示主搜哪些特點導致某階段任務性能差。所以我們要對相應階段Blink Job進行調優,調優完成也就代表著平臺能滿足圖中最右邊一列主搜所需要的全量高吞吐與增量低延遲的性能要求。
?? 
下面按照全量,增量,解一對多問題的脈絡來給大家介紹我們是如何解決上述五個問題之后達到全量高吞吐以及增量低延遲的性能要求的。
全量高吞吐性能調優
全量主要包括同步層與數據處理層,必須實現高吞吐才能讓全量在X個多小時之內完成。同步層在短時間內要同步約X張表中的上X億全量數據,且不影響同時在運行的增量時效性是一個巨大的挑戰。數據處理層要在短時間內處理X多億條數據,Join很多張鏡像表,以及UDTF處理,MultiGet等,最后產生全量HDFS文件,優化過程一度讓人頻臨放棄。這里重點介紹數據處理層的性能調優歷程。
該Job的調優歷時較長,嘗試方案較多,下面按照時間順序講解。
- 初始形態
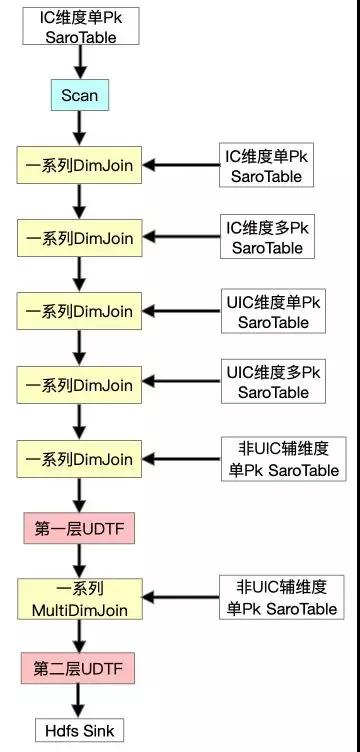
首先提一下IC維度為商品維度,UIC維度為賣家維度,并且最開始我們的方案是沒有FullDynamicNestedAggregation和IncDynamicNestedAggregation的(后文會詳細提到這兩個Job)。Scan IC維度單Pk表之后做一系列的DImJoin、UDTF、MultiJoin。在測試過程中發現DimJoin多pk表(一對多表)的數據時,性能非常低下,全鏈路Async的流程退化成了Sync,原因是我們一對多的數據存在單獨的一個SaroTable(對多個HoloTable的邏輯抽象)中,對指定第一pk來取對應所有數據用的是Partial Scan,這是完全Sync的,每Get一次都要創建一個Scanner,雖然我們不但對于DimJoin加了Cache,并且對于主搜特有的MultiGet也加了對于SubKey的精準Cache。但是測試下來發現,性能還是完全得不到滿足,所以嘗試繼續優化。
?? 
- 引入LocalJoin與SortMergeJoin
由于性能瓶頸是在DimJoin多pk的SaroTable這里,所以我們想辦法把這部分去掉。由于一對多的SaroTable只有兩個維度具有,所以我們嘗試先分別將IC維度與UIC維度的所有表(包括單pk與多pk)進行LocalJoin,結果再進行SortMergeJoin,然后繼續別的流程。
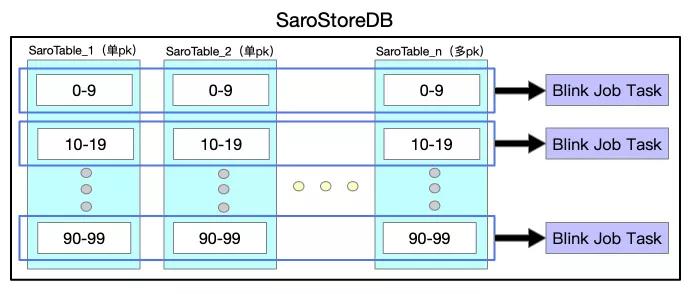
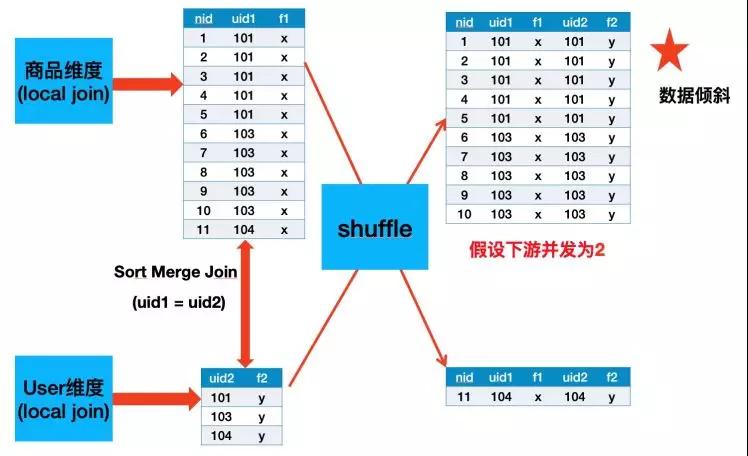
首先介紹下Local Join。由于HoloStore保證相同DB中所有表都是按照相同的Partition策略,并且都是按照主鍵字典序排好序的,所以我們可以將同緯度同Partition的數據拉取到一個進程中進行Join,避免了Shuffle,如下圖所示。
?? 
所以拓撲大概變為:
?? 
經過測試,由于業務上面存在大賣家(一個賣家有很多商品),導致SortMergeJoin之后會有很嚴重的長尾,如下圖所示,Uid為101與103的數據都是落到同一個并發中,我曾經嘗試再這個基礎之上再加一層PartitionBy nid打散,發現無濟于事,因為SortMergeJoin的Sort階段以及External Shuflle對于大數據量的Task需要多次進行Disk File Merge,所以該長尾Task還是需要很長時間才能Finish。
?? 
- 加鹽打散大賣家
所以我們需要繼續調優。經過組內討論我們決定對大賣家進行加鹽打散,從ODPS源表中找出Top X的大賣家ID,然后分別在主輔維度Scan + Local Join之后分別加上UDF與UDTF,具體流程圖與原理示例見下面兩幅圖:
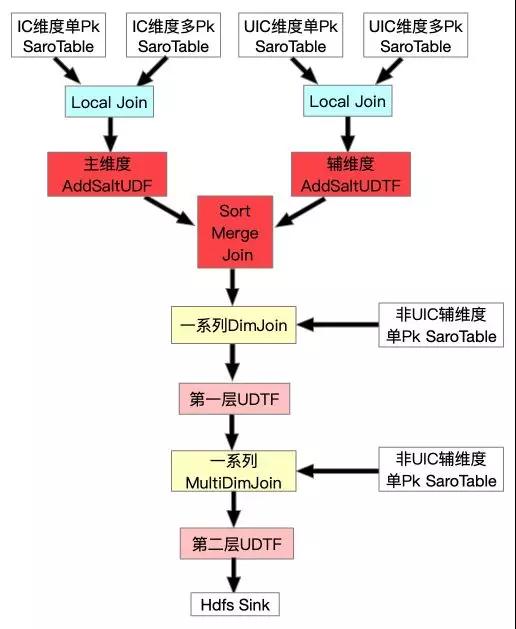
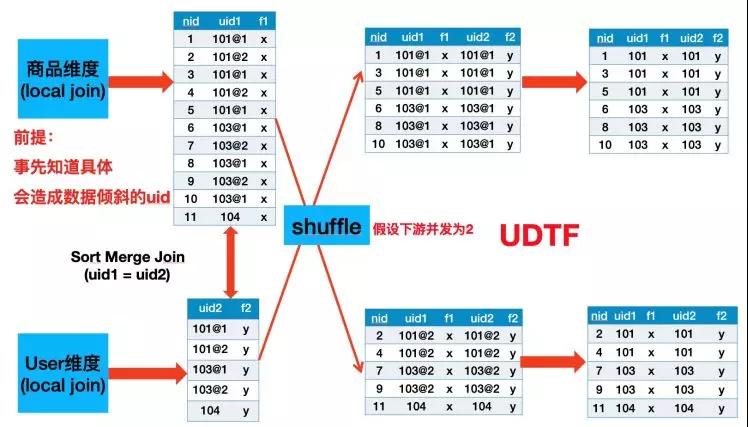
如上圖所示,Uid為101與103的數據被打散到多個并發中了,并且因為我們在SortMergeJoin之后加了UDTF把加的Salt去掉,所以最終數據不會有任何影響。
- 最終形態
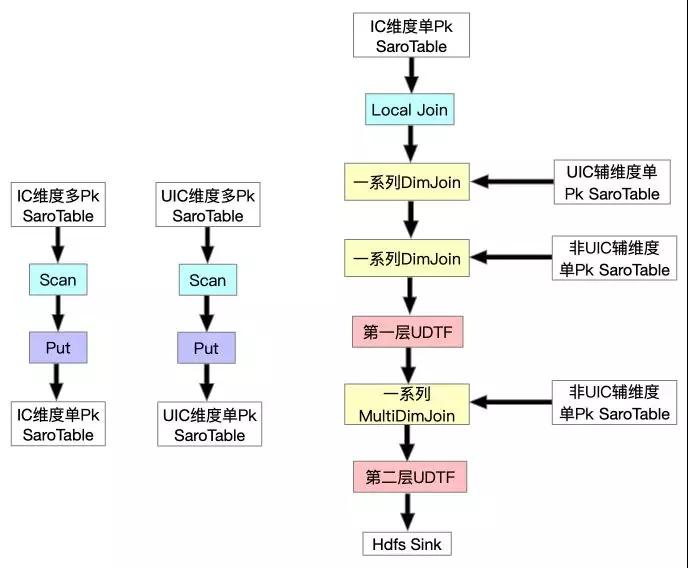
這樣全量FullJoin總算完成了,并且性能也勉強達標,所以我們開始調整增量流程(IncJoin),這時發現IncJoin跟FullJoin的初始形態存在一樣的問題,追增量非常慢,永遠追不上,所以組內討論之后決定在同步層針對全量新增一個FullDynamicNestedAggregation Job(下文會詳細提到),這是一個Blink Batch Job它將各維度一對多的SaroTable數據寫到對應維度的主表中,然后在FullJoin最開始Scan時一起Scan出來,這樣就避免了DimJoin多pk的SaroTable。最終達到了全量高吞吐的要求,全量FullJoin最終形態如下:
?? 
增量低延遲性能調優
增量性能主要受困于數據處理層IncJoin,該Job最開始是一個Blink Stream Job,主要是從SwiftQueue中讀出增量消息再關聯各個鏡像表中的數據來補全字段,以及對數據進行UDTF處理等,最后將增量消息發往在線引擎SwiftQueue中。
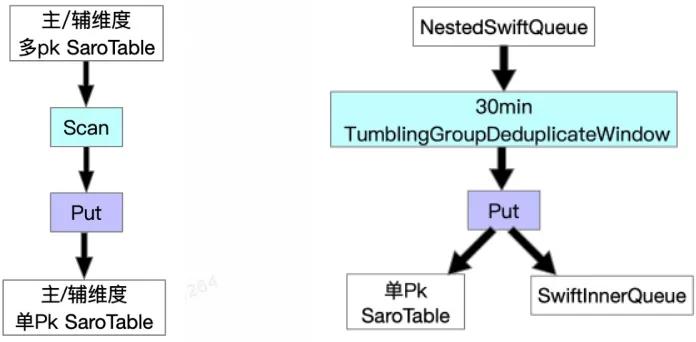
基于“流批一體”的思想,經過一系列嘗試,我們增量數據處理層Job的最終形態如下。與全量不同的是由于增量是實時更新的,所以更新記錄不僅要寫到Swift Queue中,還要寫入SaroTable中。另外,我們根據業務特點給各個Job分別加了按pk對記錄去重的window。
?? 
解一對多問題
主搜有很多一對多的表,在數據處理層如何高效的將數據Get出來轉換為主維度之后進行字段補全,困擾我們很久。
為了提升效率我們必須想辦法提升Cpu利用率。所以Get記錄改為全鏈路異步來實現,由于我們一對多數據存在多pk的HoloTable中,指定第一pk去獲取相關數據在Holo服務端是以Scan來實現的。這樣由于異步編程的傳染性,全鏈路異步會退化為同步,性能完全不達標。
- 解決方法
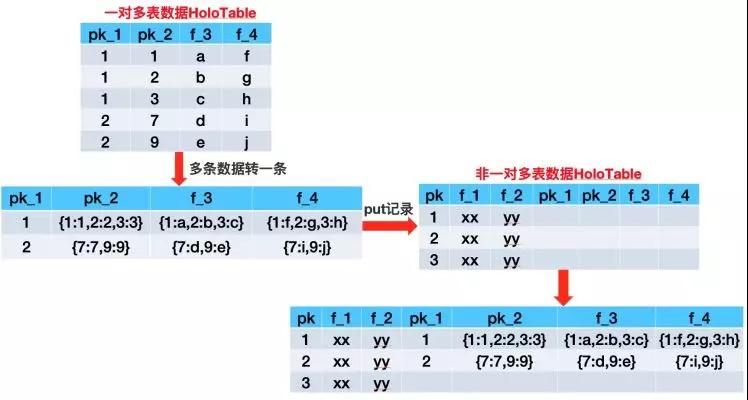
為了將“偽異步”變成真正的全鏈路異步,經過多次討論與實踐之后,我們決定將一對多表中相同第一pk的多條數據Scan出來GroupBy為一條數據,將每個字段轉化為Json之后再Put進主表中,主要步驟如下圖所示。
?? 
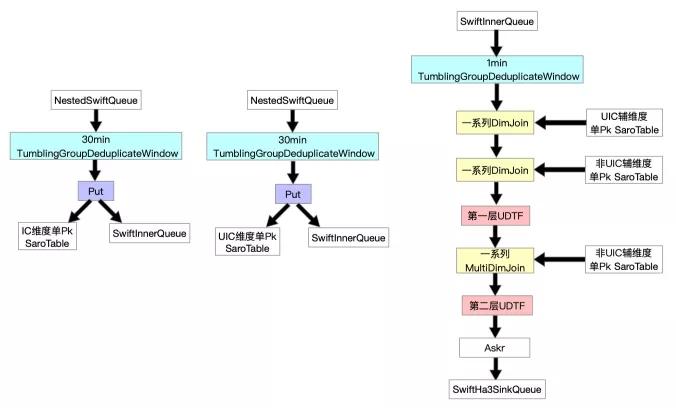
我們針對全量與增量在同步層加Job來解決,分別為FullDynamicNestedAggregation(Blink Batch Job)與IncDynamicNestedAggregation(Blink Stream Job),這兩個Job大致流程為如下圖所示。
?? 
值得一提的是,正如前文介紹增量時提到的背景,我們的場景中對于增量數據不需要保證Exactly Once語義,只需要保證At Least Once語義。所以基于該背景,我們能夠將數據處理層增量Job拆分為兩個Job執行,一對多的問題得以解決。
這樣我們在數據處理層就不需要去Scan HoloTable了,從而可以用全鏈路異步化的方式來提升增量整體性能。
- 截斷優化
為了避免將多條數據轉為一條數據之后由于數據量過大導致FullGC的“大行”問題。基于業務的特性,我們對于每個一對多表在Scan時支持截斷功能,對于相同的第一pk記錄,只Scan一定條數的記錄出來組裝為Json,并且可以針對不同的表實現白名單配置。
- 加過濾Window優化
針對業務的特點,一對多的很多表雖然可以接受一定時間的延遲,但是為了避免對離線系統以及在線BuildService造成太大的沖擊,所以更新不能太多,所以我們加了30min的去重窗口,這個窗口作用非常大,平均去重率高達X%以上。
結語
經過一系列優化,主搜不僅在資源上相對于老架構有不少的節省,而且同時實現全量高吞吐與增量低延遲,并且在2019年度雙11 0點應對突增流量時表現的游刃有余。
對系統進行性能調優是極其復雜且較精細的工作,非常具有技術挑戰性。不僅需要對所選用技術工具(Flink/Blink)熟悉,而且對于業務也必須了解。加window,截斷優化,加鹽打散大賣家等正是因為業務場景能容忍這些方法所帶來的相應缺點才能做的。
除了本文提到的調優經驗,我們對同步層全增量Job與MultiGet也進行了不少調優,篇幅原因與二八原則這里就不詳細介紹了。