













從來沒有一個人能把Flink講的這么透徹
一、 Filnk簡介和編程模型
Flink使用java語言開發,提供了scala編程的接口。使用java或者scala開發Flink是需要使用jdk8版本,如果使用Maven,maven版本需要使用3.0.4及以上。
Dataflows:
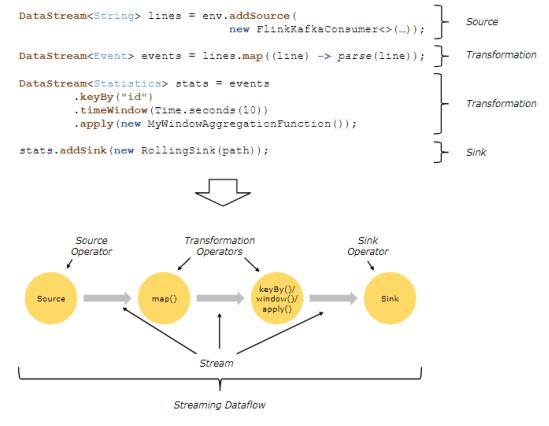
parallel Dataflows:
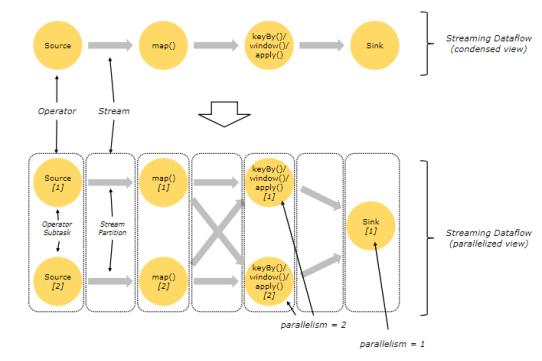
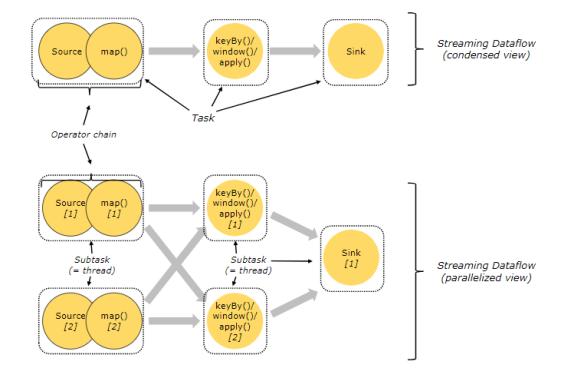
Task和算子鏈:
JobManager、TaskManager和clients:
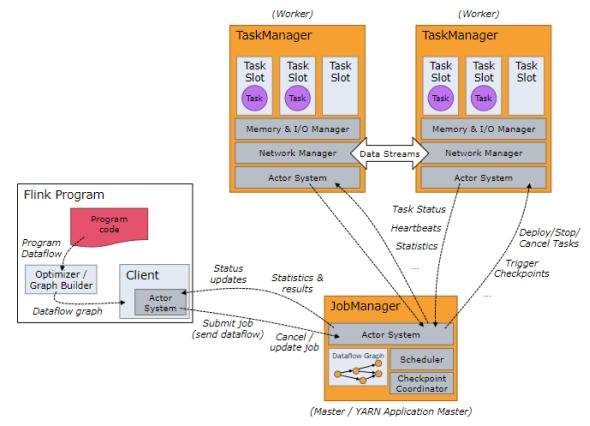
Flink運行時包含兩種類型的進程:
- JobManger:也叫作masters,協調分布式執行,調度task,協調checkpoint,協調故障恢復。在Flink程序中至少有一個JobManager,高可用可以設置多個JobManager,其中一個是Leader,其他都是standby狀態。
- TaskManager:也叫workers,執行dataflow生成的task,負責緩沖數據,及TaskManager之間的交換數據。Flink程序中必須有一個TaskManager.
Flink程序可以運行在standalone集群,Yarn或者Mesos資源調度框架中。
clients不是Flink程序運行時的一部分,作用是向JobManager準備和發送dataflow,之后,客戶端可以斷開連接或者保持連接。
TaskSlots 任務槽:
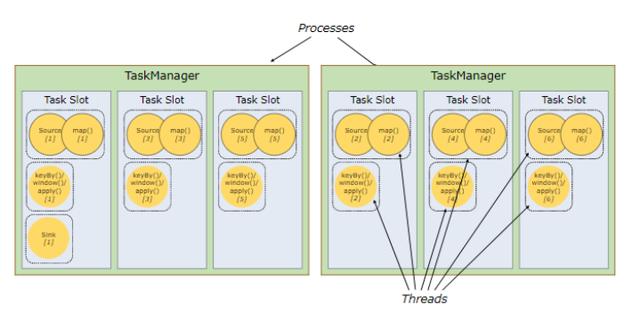
每個Worker(TaskManager)是一個JVM進程,可以執行一個或者多個task,這些task可以運行在任務槽上,每個worker上至少有一個任務槽。每個任務槽都有固定的資源,例如:TaskManager有三個TaskSlots,那么每個TaskSlot會將TaskMananger中的內存均分,即每個任務槽的內存是總內存的1/3。任務槽的作用就是分離任務的托管內存,不會發生cpu隔離。
通過調整任務槽的數據量,用戶可以指定每個TaskManager有多少任務槽,更多的任務槽意味著更多的task可以共享同一個JVM,同一個JVM中的task共享TCP連接和心跳信息,共享數據集和數據結構,從而減少TaskManager中的task開銷。
總結:task slot的個數代表TaskManager可以并行執行的task數。
二、 Flink 批處理
批處理WordCount:
- ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
- DataSource<String> ds = env.readTextFile("./data/words");
- FlatMapOperator<String, String> flatMap = ds.flatMap(new FlatMapFunction<String, String>() {
- @Override
- public void flatMap(String s, Collector<String> collector) throws Exception {
- String[] ssplit = s.split(" ");
- for (String cs : split) {
- collector.collect(cs);
- }
- }
- });
- MapOperator<String, Tuple2<String, Integer>> map = flatMap.map(new MapFunction<String, Tuple2<String, Integer>>() {
- @Override
- public Tuple2<String, Integer> map(String s) throws Exception {
- return new Tuple2<String, Integer>(s, 1);
- }
- });
- UnsortedGrouping<Tuple2<String, Integer>> groupBy = map.groupBy(0);
- AggregateOperator<Tuple2<String, Integer>> sum = groupBy.sum(1);
- // sum.print();//可以觸發算子執行
- //排序,目前不支持全局排序
- SortPartitionOperator<Tuple2<String, Integer>> sort = sum.sortPartition(1, Order.DESCENDING).setParallelism(1);
- sort.writeAsText("./TempResult/result").setParallelism(1);
- env.execute("my-wordcount");
三、 Flink 執行流程
數據源分為有界和無界之分,有界數據源可以編寫批處理程序,無界數據源可以編寫流式程序。DataSet API用于批處理,DataStream API用于流式處理。
批處理使用ExecutionEnvironment和DataSet,流式處理使用StreamingExecutionEnvironment和DataStream。
DataSet和DataStream是Flink中表示數據的特殊類,DataSet處理的數據是有界的,DataStream處理的數據是無界的,這兩個類都是不可變的,一旦創建出來就無法添加或者刪除數據元。
Flink程序的執行過程:
- 獲取flink的執行環境(execution environment)
- 加載數據-- soure
- 對加載的數據進行轉換 -- transformation
- 對結果進行保存或者打印 --sink
- 觸發flink程序的執行(execute(),count(),collect(),print()),例如:調用ExecutionEnvironment或者StreamExecutionEnvironment的execute()方法。
四、 Flink standalone集群搭建
Flink可以在Linux和window中運行,Flink集群需要有一個Master節點和一個或者多個Worker節點組成。
安裝Flink集群之前需要準備:1.每臺幾點需要配置jdk8環境變量。2.需要每臺節點有ssh服務,且有免密通信。
步驟:
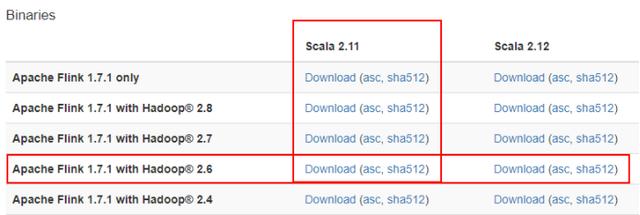
1. 進入https://flink.apache.org/downloads.html 下載flink.
下載Flink版本,這里選擇了基于Scala2.11和Hadoop2.6的1.7.1版本.
2. 下載好Flink之后上傳到Master(node1)節點上解壓:
![]()
3. 進入../conf/flink-conf.yaml中配置:
- jobmanager.rpc.address: node1 設置Master節點地址
- jobmanager.heap.size: 1024m 設置Master使用的最大內存,單位是MB
- taskmanager.heap.size: 1024m 設置Worker使用的最大內存,單位是MB
4. 配置../conf/slaves ,配置Worker節點列表
![]()
5. 將配置好的Flink發送到其他worker節點(node2,node3)上。
![]()
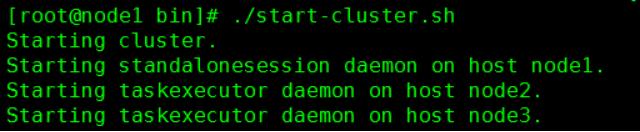
6. 啟動Flink集群,訪問webui
在Master節點上,../bin/start-cluster.sh 啟動集群。訪問webui:http:node1:8081
7. 停止集群:在Master節點中../bin/stop-cluster.sh
五、 將Flink任務提交到standalone集群運行
將以上FlinkSocketWordCount 案例打包提交到集群中運行,無論在Master節點還是在Worker節點提交都可以。
首先需要在node5節點中啟動socket 9999端口:
- nc –lk 9999
提交命令如下:
- ./flink run /root/test/MyFlink-1.0-SNAPSHOT-jar-with-dependencies.jar --port 9999
在node5節點上輸入數據后在webUI中查看日志:
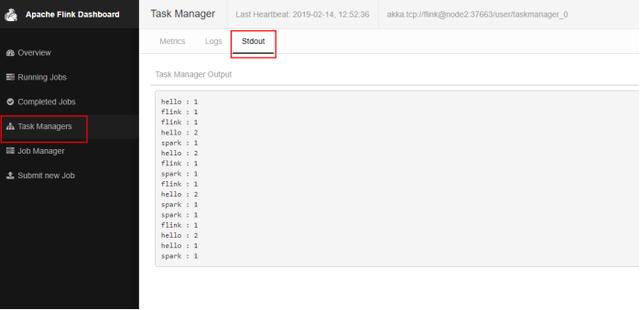
六、 Flink流處理
1. 讀取Socket數據統計WordCount
- public class SocketWindowWordCount {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment.getExecutionEnvironment();
- DataStreamSource<String> socketStream = env.socketTextStream("node5", 9999);
- SingleOutputStreamOperator<Tuple2<String, Integer>> pairWords =
- socketStream.flatMap(new Splitter());
- KeyedStream<Tuple2<String, Integer>, Tuple> keyBy = pairWords.keyBy(0);
- WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowStream =
- keyBy.timeWindow(Time.seconds(5));
- DataStream<Tuple2<String, Integer>> dataStream = windowStream.sum(1);
- dataStream.print();
- env.execute("socket wordcount");
- }
- //Splitter 實現了 FlatMapFunction ,將輸入的一行數據按照空格進行切分,返回tuple<word,1>
- public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
- @Override
- public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
- for (String word: sentence.split(" ")) {
- out.collect(new Tuple2<String, Integer>(word, 1));
- }
- }
- }
- }
2. 數據源Source
Source 是Flink獲取數據的地方。以下source中和批處理的source類似,但是以下源作為dataStream流處理時,是一條條處理,最終得到的不是一個總結果,而是每次處理后都會得到一個結果。
- socketTextStream – 讀取Socket數據流
- readTextFile() -- 逐行讀取文本文件獲取數據流,每行都返回字符串。
- fromCollection() – 從集合中創建數據流。
- fromElements – 從給定的數據對象創建數據流,所有數據類型要一致。
- addSource – 添加新的源函數,例如從kafka中讀取數據,參見讀取kafka數據案例。
3. 數據寫出 Sink
- writeAsText() – 以字符串的形式逐行寫入文件,調用每個元素的toString()得到寫入的字符串。
- writeAsCsv() – 將元組寫出以逗號分隔的csv文件。注意:只能作用到元組數據上。
- print() – 控制臺直接輸出結果,調用對象的toString()方法得到輸出結果。
- addSink() – 自定義接收函數。例如將結果保存到kafka中,參見kafka案例。
七、 Flink讀取Socket數據WordCount案例
1. 創建maven項目
2. 導入maven依賴
flink1.7.1 使用jdk1.8,scala2.11或者2.12.這里使用的scala2.11.如果只是使用java開發flink,Scala的版本選擇多少都可以。如果使用Scala開發那么就必須使用Scala對應的版本。
- <properties>
- <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
- <maven.compiler.source>1.8</maven.compiler.source>
- <maven.compiler.target>1.8</maven.compiler.target>
- <flink.version>1.7.1</flink.version>
- </properties>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-java</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-java_2.11</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-clients_2.11</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-wikiedits_2.11</artifactId>
- <version>${flink.version}</version>
- </dependency>
3. 創建StreamExecutionEnvironment 或者ExecutionEnvironment(批處理作業)。用于設置執行參數并創建從外部系統讀取的源。
代碼如下:
- public class FlinkSocketWordCount {
- public static void main(String[] args) throws Exception {
- final int port ;
- try{
- final ParameterTool params = ParameterTool.fromArgs(args);
- port = params.getInt("port");
- }catch (Exception e){
- System.err.println("No port specified. Please run 'FlinkSocketWordCount --port <port>'");
- return;
- }
- //獲取執行環境
- final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- //從socket中獲取數據。
- DataStreamSource<String> text = env.socketTextStream("node5", port);
- SingleOutputStreamOperator<WordWithCount> wordWithCountInfos = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
- @Override
- public void flatMap(String line, Collector<WordWithCount> collector) throws Exception {
- for (String word : line.split(" ")) {
- collector.collect(new WordWithCount(word, 1L));
- }
- }
- });
- //keyBy中所寫的字段必須是類WordWithCount中的字段,WordWithCount中如果重寫構造必須寫上無參構造
- KeyedStream<WordWithCount, Tuple> keyedInfos = wordWithCountInfos.keyBy("word");
- WindowedStream<WordWithCount, Tuple, TimeWindow> windowedInfo = keyedInfos.timeWindow(Time.seconds(5), Time.seconds(1));
- SingleOutputStreamOperator<WordWithCount> windowCounts = windowedInfo.reduce(new ReduceFunction<WordWithCount>() {
- @Override
- public WordWithCount reduce(WordWithCount w1, WordWithCount w2) throws Exception {
- return new WordWithCount(w1.getWord(), w1.getCount() + w2.getCount());
- }
- });
- windowCounts.print();
- env.execute("Socket Window WordCount");
- }
- public static class WordWithCount {
- public String word;
- public Long count;
- public WordWithCount() { }
- public WordWithCount(String word, Long count) {
- this.word = word;
- this.count = count;
- }
- public String getWord() {
- return word;
- }
- public void setWord(String word) {
- this.word = word;
- }
- public Long getCount() {
- return count;
- }
- public void setCount(Long count) {
- this.count = count;
- }
- @Override
- public String toString() {
- return word + " : " + count;
- }
- }
- }
八、 如何指定keys
比如某些算子(join,coGroup,keyBy,groupB y)要求在數據元上定義key。另外有些算子操作(reduce,groupReduce,Aggregate,Windows)允許數據在處理之前根據key進行分組。在Flink中數據模型不是基于Key,Value格式處理的,因此不需將數據處理成鍵值對的格式,key是“虛擬的”,可以人為的來指定,實際數據處理過程中根據指定的key來對數據進行分組,DataSet中使用groupBy來指定key,DataStream中使用keyBy來指定key。如何指定keys?
1. 使用Tuples來指定key
定義元組來指定key可以指定tuple中的第幾個元素當做key,或者指定tuple中的聯合元素當做key。需要使用org.apache.flink.api.java.tuple.TupleXX包下的tuple,最多支持25個元素且Tuple必須new創建。如果Tuple是嵌套的格式,例如:DataStream
2. 使用Field Expression來指定key
可以使用Field Expression來指定key,一般作用的對象可以是類對象,或者嵌套的Tuple格式的數據。
使用注意點:
(1) 對于類對象可以使用類中的字段來指定key。
類對象定義需要注意:
- 類的訪問級別必須是public
- 必須寫出默認的空的構造函數
- 類中所有的字段必須是public的或者必須有getter,setter方法。例如類中有個字段是foo,那么這個字段的getter,setter方法為:getFoo() 和 setFoo().
- Flink必須支持字段的類型。一般類型都支持
(2) 對于嵌套的Tuple類型的Tuple數據可以使用”xx.f0”表示嵌套tuple中第一個元素,也可以直接使用”xx.0”來表示第一個元素,參照案例GroupByUseFieldExpressions。
3. 使用Key Selector Functions來指定key
使用key Selector這種方式選擇key,非常方便,可以從數據類型中指定想要的key.
九、 累加器(Accumulator)和計數器(Counter)
Accumulator即累加器,可以在分布式統計數據,只有在任務結束之后才能獲取累加器的最終結果。計數器是累加器的具體實現,有:IntCounter,LongCounter和DoubleCounter。
累加器注意事項:
- 需要在算子內部創建累加器對象
- 通常在Rich函數中的open方法中注冊累加器,指定累加器的名稱
- 在當前算子內任意位置可以使用累加器
- 必須當任務執行結束后,通過env.execute(xxx)執行后的JobExecutionResult對象獲取累加器的值。
IntCounter舉例:
- ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
- DataSource<String> dataSource = env.fromElements("a", "b", "c", "d", "e", "f");
- MapOperator<String, String> map = dataSource.map(new RichMapFunction<String, String>() {
- //1.創建累加器,在算子中創建累加器對象
- private IntCounter numLines = new IntCounter();
- //2.注冊累加器對象,通常在Rich函數的open方法中使用
- // getRuntimeContext().addAccumulator("num-lines", this.numLines);注冊累加器
- public void open(Configuration parameters) throws Exception {
- getRuntimeContext().addAccumulator("num-lines", this.numLines);
- }
- @Override
- public String map(String s) throws Exception {
- //3.使用累加器 ,可以在任意操作中使用,包括在open或者close方法中
- this.numLines.add(1);
- return s;
- }
- }).setParallelism(8);
- map.writeAsText("./TempResult/result",FileSystem.WriteMode.OVERWRITE);
- JobExecutionResult myJobExecutionResult = env.execute("IntCounterTest");
- //4.當作業執行完成之后,在JobExecutionResult對象中獲取累加器的值。
- int accumulatorResult = myJobExecutionResult.getAccumulatorResult("num-lines");
- System.out.println("accumulator value = "+accumulatorResult);
十、 Flink + kafka 整合使用
1. 在pom.xml中添加Flink Kafka連接器的依賴,如果添加了不要重復添加
- <!-- Flink Kafka連接器的依賴-->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-kafka-0.11_2.11</artifactId>
- <version>1.7.1</version>
- </dependency>
2. 從kafka中讀取數據處理,并將結果打印到控制臺
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- Properties props = new Properties();
- props.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
- props.setProperty("group.id", "flink-group");
- /**
- * 第一個參數是topic
- * 第二個參數是value的反序列化格式
- * 第三個參數是kafka配置
- */
- FlinkKafkaConsumer011<String> consumer011 = new FlinkKafkaConsumer011<>("FlinkTopic", new SimpleStringSchema(), props);
- DataStreamSource<String> stringDataStreamSource = env.addSource(consumer011);
- SingleOutputStreamOperator<String> flatMap = stringDataStreamSource.flatMap(new FlatMapFunction<String, String>() {
- @Override
- public void flatMap(String s, Collector<String> outCollector) throws Exception {
- String[] ssplit = s.split(" ");
- for (String currentOne : split) {
- outCollector.collect(currentOne);
- }
- }
- });
- //注意這里的tuple2需要使用org.apache.flink.api.java.tuple.Tuple2 這個包下的tuple2
- SingleOutputStreamOperator<Tuple2<String, Integer>> map = flatMap.map(new MapFunction<String, Tuple2<String, Integer>>() {
- @Override
- public Tuple2<String, Integer> map(String word) throws Exception {
- return new Tuple2<>(word, 1);
- }
- });
- //keyby 將數據根據key 進行分區,保證相同的key分到一起,默認是按照hash 分區
- KeyedStream<Tuple2<String, Integer>, Tuple> keyByResult = map.keyBy(0);
- WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowResult = keyByResult.timeWindow(Time.seconds(5));
- SingleOutputStreamOperator<Tuple2<String, Integer>> endResult = windowResult.sum(1);
- //sink 直接控制臺打印
- //執行flink程序,設置任務名稱。console 控制臺每行前面的數字代表當前數據是哪個并行線程計算得到的結果
- endResult.print();
- //最后要調用execute方法啟動flink程序
- env.execute("kafka word count");
3. 將結果寫入kafka
- //sink 將結果存入kafka topic中,存入kafka中的是String類型,所有endResult需要做進一步的轉換
- FlinkKafkaProducer011<String> producer = new FlinkKafkaProducer011<>("node1:9092,node2:9092,node3:9092","FlinkResult",new SimpleStringSchema());
- //將tuple2格式數據轉換成String格式
- endResult.map(new MapFunction<Tuple2<String,Integer>, String>() {
- @Override
- public String map(Tuple2<String, Integer> tp2) throws Exception {
- return tp2.f0+"-"+tp2.f1;
- }
- }).addSink(producer);
4. 將結果寫入文件
- //sink 將結果存入文件,FileSystem.WriteMode.OVERWRITE 文件目錄存在就覆蓋
- endResult.writeAsText("./result/kafkaresult",FileSystem.WriteMode.OVERWRITE);
- // endResult.writeAsText("./result/kafkaresult",FileSystem.WriteMode.NO_OVERWRITE);
十一、 Flink + Kafka 整合數據一致性保證
1. Flink消費kafka數據起始offset配置
Flink讀取Kafka數據確定開始位置有以下幾種設置方式:
(1) flinkKafkaConsumer.setStartFromEarliest()
從topic的最早offset位置開始處理數據,如果kafka中保存有消費者組的消費位置將被忽略。
(2) flinkKafkaConsumer.setStartFromLatest()
從topic的最新offset位置開始處理數據,如果kafka中保存有消費者組的消費位置將被忽略。
(3) flinkKafkaConsumer.setStartFromTimestamp(…)
從指定的時間戳(毫秒)開始消費數據,Kafka中每個分區中數據大于等于設置的時間戳的數據位置將被當做開始消費的位置。如果kafka中保存有消費者組的消費位置將被忽略。
(4) flinkKafkaConsumer.setStartFromGroupOffsets()
默認的設置。根據代碼中設置的group.id設置的消費者組,去kafka中或者zookeeper中找到對應的消費者offset位置消費數據。如果沒有找到對應的消費者組的位置,那么將按照auto.offset.reset設置的策略讀取offset。
- FlinkKafkaConsumer011<String> consumer011 = new FlinkKafkaConsumer011<>("FlinkTopic", new SimpleStringSchema(), props);
- // consumer011.setStartFromEarliest();
- // consumer011.setStartFromLatest();
- // consumer011.setStartFromGroupOffsets();
- // consumer011.setStartFromTimestamp(111111);
- DataStreamSource<String> dateSource = env.addSource(consumer011);
- dateSource… …
2. Flink消費kafka數據,消費者offset提交配置
Flink提供了消費kafka數據的offset如何提交給Kafka或者zookeeper(kafka0.8之前)的配置。注意,Flink并不依賴提交給Kafka或者zookeeper中的offset來保證容錯。提交的offset只是為了外部來查詢監視kafka數據消費的情況。
配置offset的提交方式取決于是否為job設置開啟checkpoint。可以使用env.enableCheckpointing(5000)來設置開啟checkpoint。
(1) 關閉checkpoint:
如何禁用了checkpoint,那么offset位置的提交取決于Flink讀取kafka客戶端的配置,enable.auto.commit ( auto.commit.enable【Kafka 0.8】)配置是否開啟自動提交offset, auto.commit.interval.ms決定自動提交offset的周期。
(2) 開啟checkpoint:
如果開啟了checkpoint,那么當checkpoint保存狀態完成后,將checkpoint中保存的offset位置提交到kafka。這樣保證了Kafka中保存的offset和checkpoint中保存的offset一致,可以通過配置setCommitOffsetsOnCheckpoints(boolean)來配置是否將checkpoint中的offset提交到kafka中(默認是true)。如果使用這種方式,那么properties中配置的kafka offset自動提交參數enable.auto.commit和周期提交參數auto.commit.interval.ms參數將被忽略。
3. 使用checkpoint + 兩階段提交來保證僅一次消費kafka中的數據
當談及“exactly-once semantics”僅一次處理數據時,指的是每條數據只會影響最終結果一次。Flink可以保證當機器出現故障或者程序出現錯誤時,也沒有重復的數據或者未被處理的數據出現,實現僅一次處理的語義。Flink開發出了checkpointing機制,這種機制是在Flink應用內部實現僅一次處理數據的基礎。
checkpoint中包含:
- 當前應用的狀態
- 當前消費流數據的位置
在Flink1.4版本之前,Flink僅一次處理數據只限于Flink應用內部(可以使用checkpoint機制實現僅一次數據數據語義),當Flink處理完的數據需要寫入外部系統時,不保證僅一次處理數據。為了提供端到端的僅一次處理數據,在將數據寫入外部系統時也要保證僅一次處理數據,這些外部系統必須提供一種手段來允許程序提交或者回滾寫入操作,同時還要保證與Flink的checkpoint機制協調使用。
在分布式系統中協調提交和回滾的常見方法就是兩階段提交協議。下面給出一個實例了解Flink如何使用兩階段提交協議來實現數據僅一次處理語義。
該實例是從kafka中讀取數據,經過處理數據之后將結果再寫回kafka。kafka0.11版本之后支持事務,這也是Flink與kafka交互時僅一次處理的必要條件。【注意:當Flink處理完的數據寫入kafka時,即當sink為kafka時,自動封裝了兩階段提交協議】。Flink支持僅一次處理數據不僅僅限于和Kafka的結合,只要sink提供了必要的兩階段協調實現,可以對任何sink都能實現僅一次處理數據語義。
其原理如下:
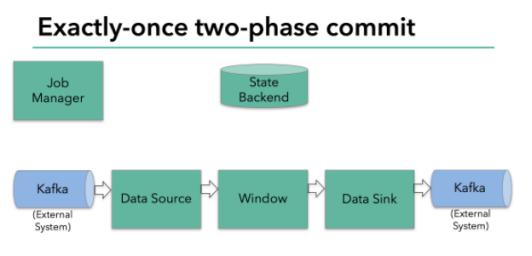
上圖Flink程序包含以下組件:
- 一個從kafka中讀取數據的source
- 一個窗口聚合操作
- 一個將結果寫往kafka的sink。
要使sink支持僅一次處理數據語義,必須以事務的方式將數據寫往kafka,將兩次checkpoint之間的操作當做一個事務提交,確保出現故障時操作能夠被回滾。假設出現故障,在分布式多并發執行sink的應用程序中,僅僅執行單次提交或回滾事務是不夠的,因為分布式中的各個sink程序都必須對這些提交或者回滾達成共識,這樣才能保證兩次checkpoint之間的數據得到一個一致性的結果。Flink使用兩階段提交協議(pre-commit+commit)來實現這個問題。
Filnk checkpointing開始時就進入到pre-commit階段,具體來說,一旦checkpoint開始,Flink的JobManager向輸入流中寫入一個checkpoint barrier將流中所有消息分隔成屬于本次checkpoint的消息以及屬于下次checkpoint的消息,barrier也會在操作算子間流轉,對于每個operator來說,該barrier會觸發operator的State Backend來為當前的operator來打快照。如下圖示:
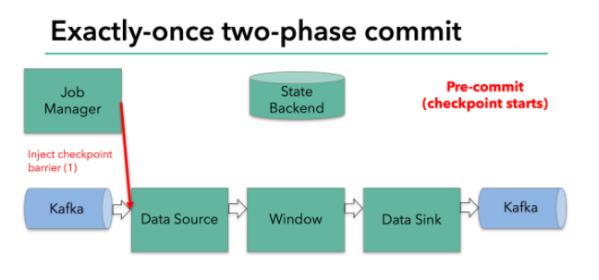
Flink DataSource中存儲著Kafka消費的offset,當完成快照保存后,將chechkpoint barrier傳遞給下一個operator。這種方式只有在Flink內部狀態的場景是可行的,內部狀態指的是由Flink的State Backend管理狀態,例如上面的window的狀態就是內部狀態管理。只有當內部狀態時,pre-commit階段無需執行額外的操作,僅僅是寫入一些定義好的狀態變量即可,checkpoint成功時Flink負責提交這些狀態寫入,否則就不寫入當前狀態。
但是,一旦operator操作包含外部狀態,事情就不一樣了。我們不能像處理內部狀態一樣處理外部狀態,因為外部狀態涉及到與外部系統的交互。這種情況下,外部系統必須要支持可以與兩階段提交協議綁定的事務才能保證僅一次處理數據。
本例中的data sink是將數據寫往kafka,因為寫往kafka是有外部狀態的,這種情況下,pre-commit階段下data sink 在保存狀態到State Backend的同時,還必須pre-commit外部的事務。如下圖:
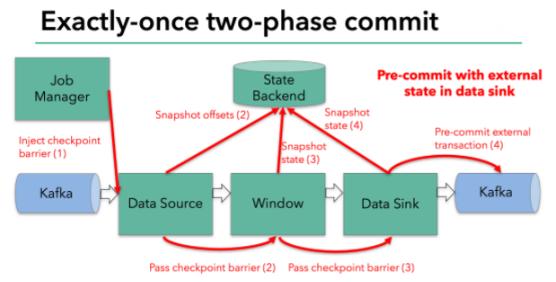
當checkpoint barrier在所有的operator都傳遞一遍切對應的快照都成功完成之后,pre-commit階段才算完成。這個過程中所有創建的快照都被視為checkpoint的一部分,checkpoint中保存著整個應用的全局狀態,當然也包含pre-commit階段提交的外部狀態。當程序出現崩潰時,我們可以回滾狀態到最新已經完成快照的時間點。
下一步就是通知所有的operator,告訴它們checkpoint已經完成,這便是兩階段提交的第二個階段:commit階段。這個階段中JobManager會為應用中的每個operator發起checkpoint已經完成的回調邏輯。本例中,DataSource和Winow操作都沒有外部狀態,因此在該階段,這兩個operator無需執行任何邏輯,但是Data Sink是有外部狀態的,因此此時我們需要提交外部事務。如下圖示:
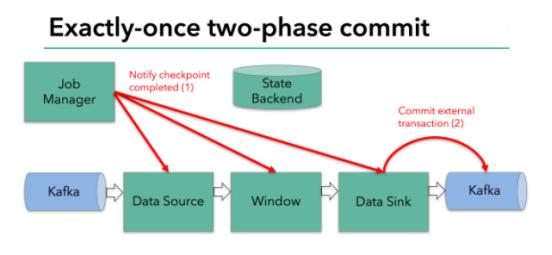
匯總以上信息,總結得出:
(1) 一旦所有的operator完成各自的pre-commit,他們會發起一個commit操作。
(2) 如果一個operator的pre-commit失敗,所有其他的operator 的pre-commit必須被終止,并且Flink會回滾到最近成功完成的checkpoint位置。
(3) 一旦pre-commit完成,必須要確保commit也要成功,內部的operator和外部的系統都要對此進行保證。假設commit失敗【網絡故障原因】,Flink程序就會崩潰,然后根據用戶重啟策略執行重啟邏輯,重啟之后會再次commit。
因此,所有的operator必須對checkpoint最終結果達成共識,即所有的operator都必須認定數據提交要么成功執行,要么被終止然后回滾。
(4) Flink中外部狀態實現兩階段提交
Flink外部狀態實現兩階段提交將邏輯封裝到TwoPhaseComitSinkFunction類中,下面擴展TwoPhaseCommitSinkFunction來實現就文件的sink。若要實現支持exactly-once語義的文件sink,需要實現以下4個方法:
- beginTransaction:開啟一個事務,創建一個臨時文件,將數據寫入到臨時文件中
- preCommit:在pre-commit階段,flush緩存數據到磁盤,然后關閉這個文件,確保不會有新的數據寫入到這個文件,同時開啟一個新事務執行屬于下一個checkpoint的寫入操作
- commit:在commit階段,我們以原子性的方式將上一階段的文件寫入真正的文件目錄下。【注意:數據有延時,不是實時的】
- abort:一旦異常終止事務,程序如何處理。這里要清除臨時文件。

















