馬蜂窩大數據架構詳解:小白都能懂的數據倉庫與數據中臺
一、馬蜂窩數據倉庫與數據中臺
最近幾年,數據中臺概念的熱度一直不減。2018 年起,馬蜂窩也開始了自己的數據中臺探索之路。
數據中臺到底是什么?要不要建?和數據倉庫有什么本質的區別?相信很多企業都在關注這些問題。
我認為數據中臺的概念非常接近傳統數據倉庫+大數據平臺的結合體。它是在企業的數據建設經歷了數據中心、數據倉庫等積累之后,借助平臺化的思路,將數據更好地進行整合與統一。
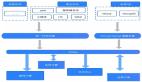
所以,數據中臺更多的是體現一種管理思路和架構組織上的變革。在這樣的思想下,我們結合自身業務特點建設了馬蜂窩的數據中臺,核心架構如下:
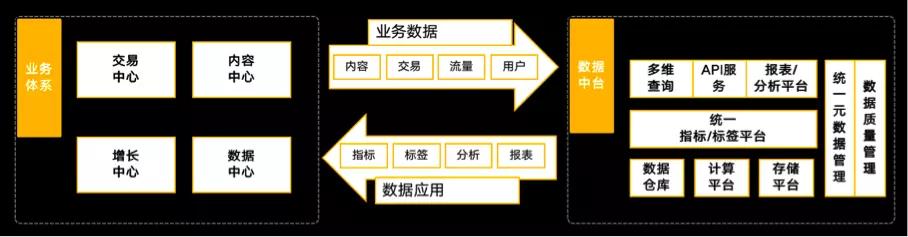
在中臺建設之前,馬蜂窩已經建立了自己的大數據平臺,并積累了一些通用、組件化的工具,這些可以支撐數據中臺的快速搭建。作為中臺的另一大核心部分,馬蜂窩數據倉庫主要承擔數據統一化建設的工作,包括統一數據模型,統一指標體系等。下面介紹馬蜂窩在數據倉庫建設方面的具體實踐。
二、數據倉庫核心架構
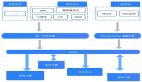
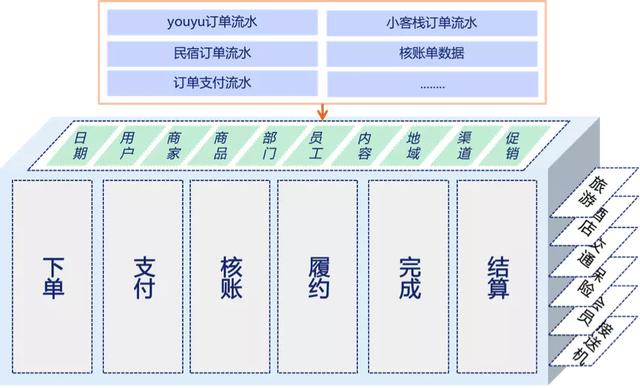
馬蜂窩數據倉庫遵循標準的三層架構,對數據分層的定位主要采取維度模型設計,不會對數據進行抽象打散處理,更多注重業務過程數據整合。現有數倉主要以離線為主,整體架構如下:
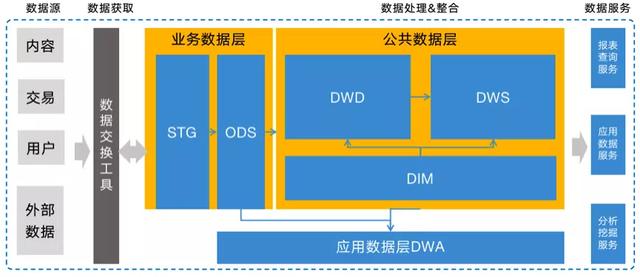
如圖所示,共分為 3 層:業務數據層、公共數據層與應用數據層,每層定位、目標以及建設原則各不相同。
三、數據模型設計
3.1 方法選擇
數據模型是對現實世界數據特征的抽象,數據模型的設計方法就是對數據進行歸納和概括的方法。目前業界主要的模型設計方法論有兩種,一是數據倉庫之父 Bill Inmon 提出的范式建模方法,又叫 ER 建模,主張站在企業角度自上而下進行數據模型構建;二是 Ralph Kimball 大師倡導的維度建模方法,主張從業務需求出發自下而上構建數據模型。
大數據環境下,業務系統數據體系龐雜,數據結構多樣、變更頻繁,并且需要快速響應各種復雜的業務需求,以上兩種傳統的理論都已無法滿足互聯網數倉需求。
在此背景下,馬蜂窩數據倉庫采取了「以需求驅動為主、數據驅動為輔」的混合模型設計方式,來根據不同的數據層次選擇模型。

3.2 設計流程
馬蜂窩數倉模型設計的整體流程涉及需求調研、模型設計、開發測試、模型上線四個主要環節,且規范設計了每個階段的輸出與輸入文檔。
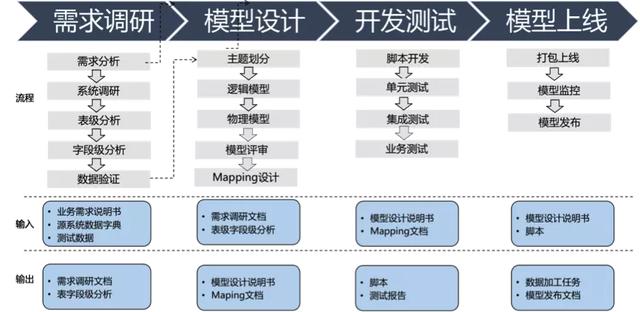
3.3 主題分類
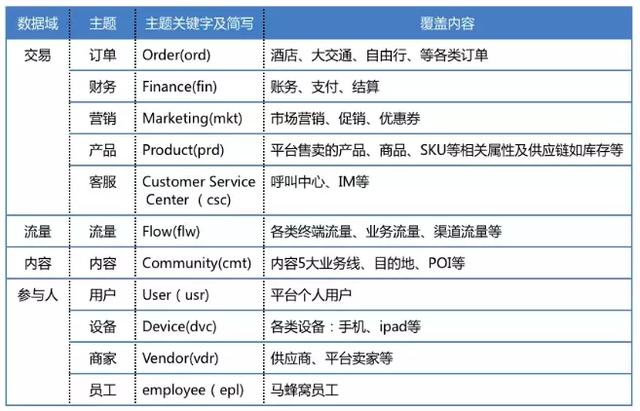
基于對目前各個部門和業務系統的梳理,馬蜂窩數據倉庫共設計了 4 個大數據域(交易、流量、內容、參與人),細分為 11 個主題:
以馬蜂窩訂單交易模型的建設為例,基于業務生產總線的設計是常見的模式,即首先調研訂單交易的完整過程,定位過程中的關鍵節點,確認各節點上發生的核心事實信息。模型是數據的載體,我們要做的就是通過模型(或者說模型體系)歸納生產總線中各個節點發生的事實信息。
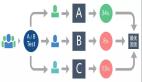
訂單生產總線:
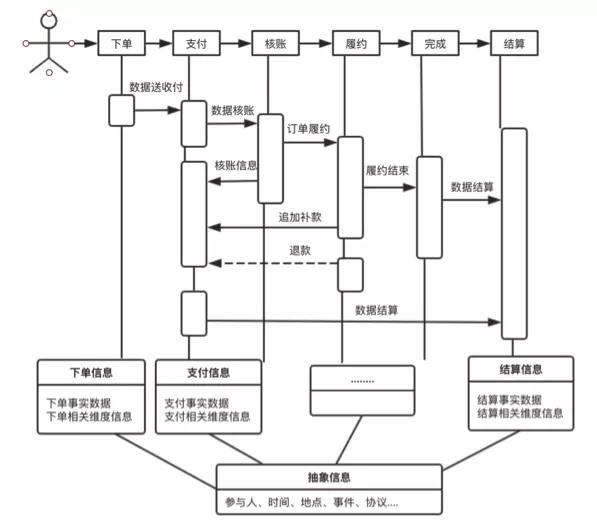
如上圖所示,我們需要提煉各節點的核心信息,為了避免遺漏關鍵信息,一般情況下抽象認為節點的參與人、發生時間、發生事件、發生協議屬于節點的核心信息,需要重點獲取。以下單節點為例,參與人包括下單用戶、服務商家、平臺運營人員等;發生時間包括用戶的下單時間、商家的確認時間等;發生的事件即用戶購買了商品,需要記錄圍繞這一事件產生的相關信息;發生協議即產生的訂單,訂單金額、約定內容等都是我們需要記錄的協議信息。
在這樣的思路下,總線架構可以在模型中不斷添加各個節點的核心信息,使模型支撐的應用范圍逐步擴展、趨于完善。因此,對業務流程的理解程度將直接影響產出模型的質量。
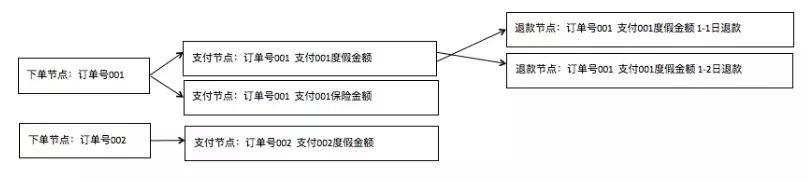
鑒于上述情況,在模型實現過程中,我們不能把各節點不同粒度的數據信息都堆砌在一起,那樣會產生大量的冗余信息,也會使模型本身的定位不清晰,影響使用。
因此,需要輸出不同粒度的模型來滿足各類應用需求。例如既會存在訂單粒度的數據模型,也會存在分析各個訂單在不同時間節點狀態信息的數據模型。
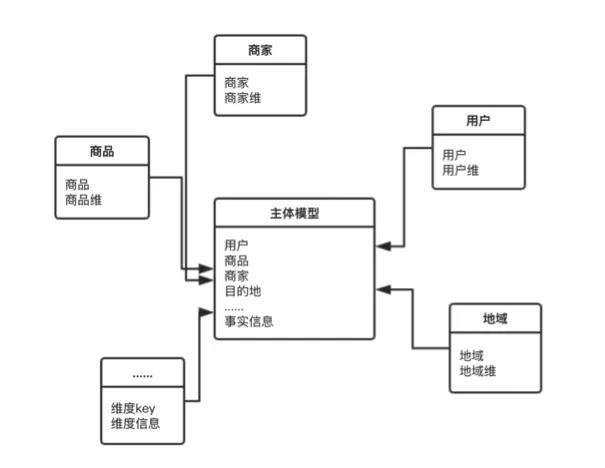
基于維度建模的思路,在模型整合生產總線各節點核心信息之后,會根據這些節點信息進一步擴展常用的分析維度,以減少應用層面頻繁關聯相關分析維度帶來的資源消耗,模型會反范式冗余相關維度信息,以獲取應用層的使用便捷。最終建立一個整合旅游、交通、酒店等各業務線與各業務節點信息的馬蜂窩全流程訂單模型。
四、數據倉庫工具鏈建設
為提升數據生產力,馬蜂窩數據倉庫建立了一套工具鏈,來實現采集、研發、管理流程的自動化。現階段比較重要的有以下三大工具:
1. 數據同步工具
同步工具主要解決兩個問題:
- 從源系統同步數據到數據倉庫
- 將數據倉庫的數據同步至其他環境
下面重點介紹從源系統同步數據到數據倉庫。
馬蜂窩的數據同步設計支撐靈活的數據接入方式,可以選擇抽取方式以及加工方式。抽取方式主要包括增量抽取或者全量抽取,加工方式面向數據的存儲方式,是需要對數據進行拉鏈式保存,或者以流水日志的方式進行存儲。
接入時,只需要填寫數據表信息配置以及具體的字段配置信息,數據就可以自動接入到數據倉庫,形成數倉的 ODS 層數據模型,如下:

2. 任務調度平臺
我們使用 Airflow 配合自研的任務調度系統,不僅能支持常規的任務調度,還可以支持任務調度系統各類數據重跑,歷史補數等需求。
別小看數據重跑、歷史補數,這兩項功能是在選擇調度工具中重要的參考項。做數據的人都清楚,在實際數據處理過程中會面臨諸多的數據口徑變化、數據異常等,需要進行數據重跑、刷新、補數等操作。
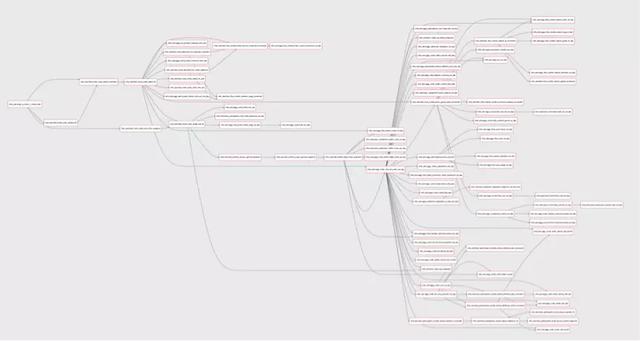
我們設計的「一鍵重跑」功能,可以將相關任務依賴的后置任務全部帶出,并支持選擇性地刪除或虛擬執行任意節點的任務:
- 如果選擇刪除,這該任務之后所依賴的任務均不執行
- 如果選擇虛擬執行,則會忽略(空跑)掉該任務,后置的所有依賴任務還是會正常執行。
如下是基于某一個任務重跑下游所有任務所列出的關系圖,選中具體的執行節點,就可以執行忽略或者刪除。
3. 元數據管理工具
元數據范疇包括技術元數據、業務元數據、管理元數據,在概念上不做過多闡述了。元數據管理在數據建設起著舉足輕重的作用,這部分在數倉應用中主要有 2 個點:
(1)血緣管理
- 血緣管理可以追溯數據加工整體鏈路,解析表的來龍去脈,用于支撐各類場景,如:
- 支持上游變更對下游影響的分析與調整
- 監控各節點、各鏈路任務運行成本,效率
- 監控數據模型的依賴數量,確認哪些是重點模型
如下是某一個數據模型中的血緣圖,上下游以不同顏色進行呈現:
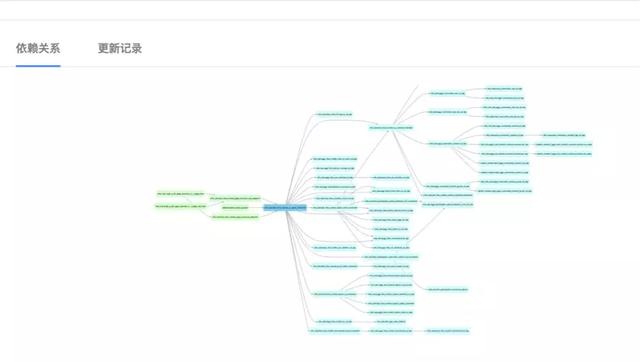
(2)數據知識管理
通過對技術、業務元數據進行清晰、詳盡地描述,形成數據知識,給數據人員提供更好的使用向導。我們的數據知識主要包括實體說明與屬性說明,具體如下:


五、總結
企業的數據建設需要經歷幾個大的步驟:
- 第一步,業務數據化:顧名思義,一切業務都能通過數據反映,主要指的是將傳統線下流程線上化;
- 第二步,數據智能化:光有數據還不行,還需要足夠的智能,如何通過智能化的數據支撐運營、營銷及各類業務,這是數據中臺當前解決的主要問題;
- 第三步,數據業務化:也就是我們常說的數據驅動業務,數據不能只是數據,數據價值最大化在于可以驅動新的業務創新,帶動企業增長。
目前大部企業目前都停留在第二個階段,因為這一步需要足夠夯實,才能為第三步打好基礎,這也是為什么各大企業要投入很大成本到大數據平臺、數據倉庫乃至數據中臺的建設中。
馬蜂窩數據中臺的建設才剛剛起步。我們認為,理想的數據中臺需要具備數據標準化、工具組件化、組織清晰化這三個核心前提。為了向這一目標邁進,我們將建立統一、標準化的數據倉庫作為當下數據中臺的重點工作之一。
數據來源于業務,最終也將應用于業務。只有對數據足夠重視,與業務充分銜接,才能實現數據價值的最大化。在馬蜂窩,從管理層,到公司研發、產品、運營、銷售等各角色,對數據非常重視,數據產品的使用人數占公司員工比例高達 75%。
大量用戶的使用,驅動著我們在數據中臺建設的路上不斷前進。如何將新興技術能力應用到數據倉庫的建設,如何以有限的成本高效解決企業在數據建設中面臨的問題,將是馬蜂窩數倉建設一直的思考。